


Wir freuen uns, heute ankündigen zu können, dass wir Mistral-7B-v0.1-instruct zu Workers AI hinzugefügt haben. Mistral 7B ist ein 7,3 Milliarden Parameter-umfassendes Sprachmodell mit einer Reihe von einzigartigen Vorteilen. Mit Hilfe der Gründer von Mistral AI werden wir uns einige der Highlights des Mistral 7B-Modells ansehen und die Gelegenheit nutzen, um tiefer in das Thema „Attention“ (Aufmerksamkeit) und seine Variationen wie Multi-Query-Attention und Grouped-Query-Attention einzutauchen.
Kurz erklärt: Was ist Mistral 7B?
Mistral 7B ist ein 7,3 Milliarden Parameter-umfassendes KI-Modell, das bei Benchmarks beeindruckende Zahlen liefert. Das Modell:
- übertrifft Llama 2 13B bei allen Benchmarks
- übertrifft Llama 1 34B bei vielen Benchmarks,
- erreicht bei Programmieraufgaben fast die Performance von CodeLlama 7B, während es bei Englisch-Aufgaben noch immer gut abschneidet
- Die optimierte, auf Chat-Dialog ausgerichtete Version, die wir eingesetzt haben, übertrifft Llama 2 13B Chat in den von Mistral durchgeführten Benchmarks.
Es folgt ein Beispiel für das Streamen mit der REST-API:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
Und hier sehen Sie ein Beispiel für die Verwendung eines Worker-Skripts:
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral nutzt die sogenannte Grouped-Query Attention für schnellere Inferenz. Diese kürzlich entwickelte Technik verbessert die Geschwindigkeit der Inferenz, ohne die Qualität der Ergebnisse zu beeinträchtigen. Bei Modellen mit 7 Milliarden Parametern können wir dank der Grouped-Query Attention mit Mistral fast 4x so viele Token pro Sekunde generieren wie mit Llama.
Sie benötigen natürlich keine weiteren Informationen als diese, um Mistral-7B zu nutzen. Sie können es noch heute testen unter ai.cloudflare.com. Wenn Sie mehr über Attention und Grouped-Query-Attention erfahren möchten, lesen Sie einfach weiter!
Was bedeutet „Attention“, also Aufmerksamkeit, eigentlich im Bereich der KI?
Der grundlegende Attention-Mechanismus, insbesondere die „Scaled Dot-Product Attention“, wie sie in der bahnbrechenden Forschungsarbeit „Attention Is All You Need“, vorgestellt wurde, ist recht einfach:
Wir nennen unsere spezielle Aufmerksamkeit „Scale Dot-Product Attention“. Der Input besteht aus der Abfrage und den Schlüsseln der Dimension d_k und den Werten der Dimension d_v. Wir berechnen die Dot-Produkte der Abfrage mit allen Schlüsseln, teilen jedes durch sqrt(d_k) und wenden eine Softmax-Funktion an, um die Gewichtung der Werte zu erhalten.
Konkret sieht das folgendermaßen aus:
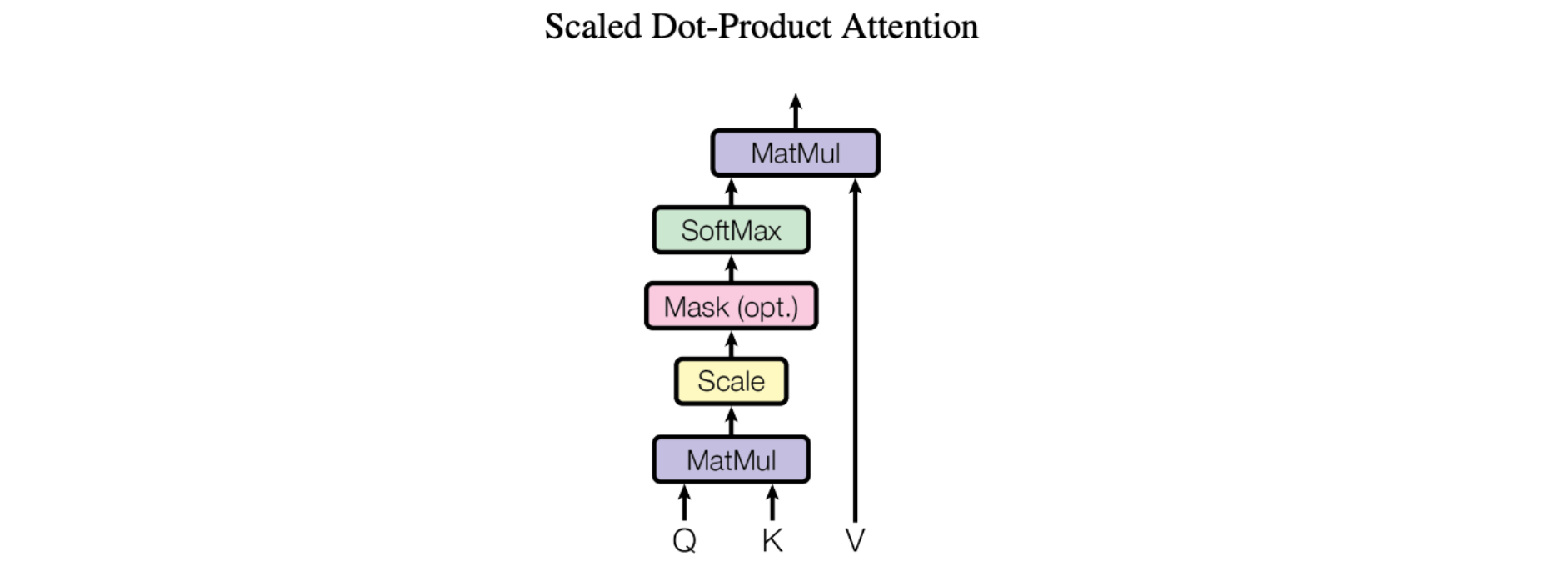
Vereinfacht ausgedrückt, können sich die Modelle so auf wichtige Teile des Inputs konzentrieren. Stellen Sie sich vor, Sie lesen einen Satz und versuchen, ihn zu verstehen. Scaled Dot-Product-Attention ermöglicht es Ihnen, bestimmten Wörtern auf der Grundlage ihrer Relevanz mehr Aufmerksamkeit zu schenken. Dabei wird die Ähnlichkeit zwischen jedem Wort (K) im Satz und einer Abfrage (Q) berechnet. Anschließend werden die Ähnlichkeitswerte durch die Quadratwurzel der Dimension der Abfrage geteilt. Diese Skalierung hilft, sehr kleine oder sehr große Werte zu vermeiden. Anhand dieser skalierten Ähnlichkeitswerte können wir schließlich bestimmen, wie viel Aufmerksamkeit oder Bedeutung jedes Wort erhalten sollte. Dieser Aufmerksamkeitsmechanismus hilft den Modellen, wichtige Informationen (V) zu erkennen und ihre Verständnis- und Übersetzungsfähigkeiten zu verbessern.
Eigentlich ganz einfach, oder? Um von diesem einfachen Mechanismus zu einer KI zu gelangen, der man komplexe Schreibaufträge erteilen kann wie z. B. „Schreibe eine Seinfeld-Folge, in der Jerry den Bubble-Sort-Algorithmus erlernt“, müssen wir ihn jedoch noch komplexer machen. (Tatsächlich hat alles, was wir gerade behandelt haben, nicht einmal gelernte Parameter – konstante Werte, die während des Trainierens des Modells gelernt werden und die die Ausgabe des Attention-Blocks anpassen!)
Attention-Blöcke im Stile von „Attention is All You Need“ führen hauptsächlich drei Arten von Komplexität ein:
Gelernte Parameter
Gelernte Parameter beziehen sich auf Werte oder Gewichte, die während des Trainingsprozesses eines Modells angepasst werden, um dessen Performance zu verbessern. Diese Parameter werden verwendet, um den Informationsfluss oder die Aufmerksamkeit innerhalb des Modells zu steuern, damit es sich auf die wichtigsten Teile der Inputdaten konzentrieren kann. Einfacher ausgedrückt: Gelernte Parameter sind wie einstellbare Knöpfe an einer Maschine, an denen man drehen kann, um ihren Betrieb zu optimieren.
„Vertikale“ Stapelung – übereinandergelagerte Attention-Blöcke
Bei der vertikalen Stapelung werden mehrere Aufmerksamkeitsmechanismen übereinander gestapelt, wobei jede Schicht auf dem Ergebnis der vorherigen Schicht aufbaut. Dadurch kann sich das Modell auf verschiedene Teile der Inputdaten auf unterschiedlichen Abstraktionsebenen konzentrieren, was zu einer besseren Performance bei bestimmten Aufgaben führen kann.
Horizontale Stapelung – auch bekannt als „Multi-Head-Attention“
Die Abbildung aus der Arbeit zeigt das vollständige Multi-Head-Attention-Modul. Mehrere Attention-Operationen werden parallel durchgeführt, wobei das Q-K-V-Input für jede durch eine eindeutige lineare Projektion der gleichen Input-Daten (definiert durch einen eindeutigen Satz gelernter Parameter) erzeugt wird. Diese parallelen Attention-Blöcke werden als „Attention-Heads“ bezeichnet. Die gewichteten Summen-Outputs aller Attention-Heads werden zu einem einzigen Vektor verkettet und durch eine weitere parametrisierte lineare Transformation geleitet, um das endgültige Output zu erhalten.
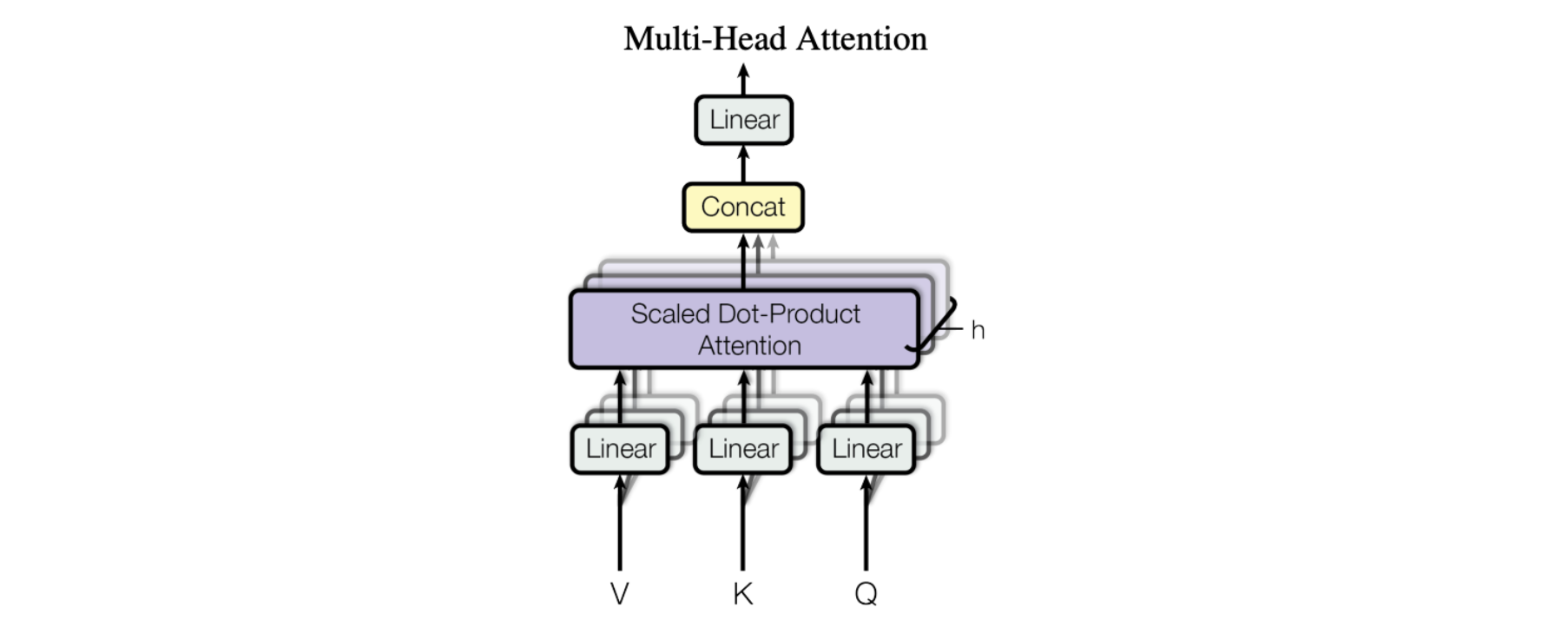
Dieser Mechanismus ermöglicht es einem Modell, sich gleichzeitig auf verschiedene Teile der Inputdaten zu konzentrieren. Stellen Sie sich vor, Sie versuchen, eine komplexe Information zu verstehen, etwa einen Satz oder einen Absatz. Um diesen zu verstehen, müssen Sie gleichzeitig auf verschiedene Teile achten. So müssen Sie beispielsweise gleichzeitig auf das Subjekt des Satzes, das Verb und das Objekt achten, um die Bedeutung des Satzes zu begreifen. Die Multi-Headed-Attention funktioniert sehr ähnlich. Sie ermöglicht es einem Modell, gleichzeitig auf verschiedene Teile der Inputdaten zu achten, indem es mehrere „Bereiche“ der Aufmerksamkeit („Heads of Attention“) verwendet. Jeder Aufmerksamkeitsbereich konzentriert sich auf einen anderen Aspekt der Inputdaten, und die Ergebnisse aller Bereiche werden kombiniert, um das endgültige Ergebnis des Modells zu erhalten.
Arten von Attention
Es gibt drei gängige Anordnungen von Attention-Blöcken, die von LLMs verwendet werden, die in den letzten Jahren entwickelt wurden: Multi-Head-Attention, Grouped-Query-Attention und Multi-Query-Attention. Sie unterscheiden sich durch die Anzahl der K- und V-Vektoren im Verhältnis zur Anzahl der Abfragevektoren. Multi-Head-Attention verwendet die gleiche Anzahl von K- und V-Vektoren wie Q-Vektoren, in der folgenden Tabelle mit „N“ bezeichnet. Multi-Query-Attention verwendet nur einen einzigen K- und V-Vektor. Grouped-Query-Attention, die Art, die im Mistral 7B-Modell verwendet wird, teilt die Q-Vektoren gleichmäßig in Gruppen mit jeweils „G“ Vektoren auf und verwendet dann einen einzelnen K- und V-Vektor für jede Gruppe, so dass insgesamt N durch G Gruppen von K- und V-Vektoren geteilt werden. Soweit zu den Unterschieden. Wir werden uns weiter unten mit den Auswirkungen dieser Unterschiede befassen.
|
Anzahl der Schlüssel/Wert-Blöcke |
Qualität |
Speicher-verbrauch |
|
|
Multi-head attention (MHA) |
N |
Beste |
Am meisten |
|
Grouped-query attention (GQA) |
N / G |
Besser |
Weniger |
|
Multi-query attention (MQA) |
1 |
Gutartiger |
Am wenigsten |
Zusammenfassung der Attention-Stile
Diese Abbildung verdeutlicht den Unterschied zwischen den drei Stilen:
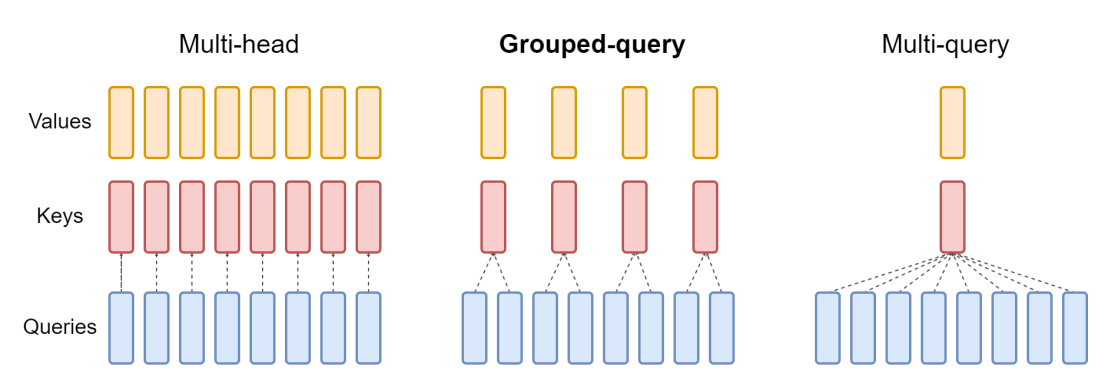
Multi-Query-Attention
Multi-Query Attention wurde 2019 in einer Arbeit von Google beschrieben: „Fast Transformer Decoding: One Write-Head is All You Need“. Die Idee besteht darin, dass für jeden Q-Vektor im Attention-Mechanismus keine separaten K- und V-Einträge erstellt werden, wie bei der obigen Multi-Head-Attention, sondern nur ein einziger K- und V-Vektor für den gesamten Satz von Q-Vektoren verwendet wird. Daher der Name: mehrere Abfragen kombiniert in einem einzigen Attention-Mechanismus. In der Arbeit wurde dies an einer Übersetzungsaufgabe getestet und zeigte die gleiche Performance wie die Multi-Head-Attention bei der Benchmark-Aufgabe.
Ursprünglich war die Idee, die Gesamtgröße des Speichers zu reduzieren, auf den bei der Durchführung der Inferenz für das Modell zugegriffen wird. Seitdem haben sich verallgemeinerte Modelle herausgebildet und die Anzahl der Parameter ist gestiegen. Der benötigte GPU-Speicher ist oft der Engpass. Hier zeigt sich die Stärke der Multi-Query-Attention, da sie von den drei Attention-Arten den geringsten Beschleunigungsspeicher benötigt. Mit zunehmender Größe und Allgemeingültigkeit der Modelle nahm die Performance der Multi-Query-Attention im Vergleich zur Multi-Head-Attention jedoch ab.
Grouped-Query-Attention
Der neueste – und der von Mistral verwendete Ansatz – ist die Grouped-Query-Attention, wie sie in der im Mai 2023 auf arxiv.org veröffentlichten Arbeit GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints beschrieben wurde. Grouped-Query-Attention kombiniert das Beste beider Ansätze: die Qualität von Multi-Head-Attention mit der Geschwindigkeit und dem geringen Speicherbedarf von Multi-Query-Attention. Anstelle eines einzigen Satzes von K- und V-Vektoren oder eines Satzes für jeden Q-Vektor wird ein festes Verhältnis von einem Satz von K- und V-Vektoren für jeden Q-Vektor verwendet, was die Speichernutzung reduziert, aber eine hohe Performance bei vielen Aufgaben sichert.
Bei der Auswahl eines für den laufenden Betrieb zu implementierenden Modells geht es oft nicht nur darum, das beste verfügbare Modell auszuwählen, denn wir müssen Kompromisse zwischen Performance, Speichernutzung, Batch-Größe und verfügbarer Hardware (oder Cloud-Kosten) berücksichtigen. Das Wissen um diese drei Arten der Attention (Aufmerksamkeit) kann uns helfen, diese Entscheidungen zu treffen und zu verstehen, wann wir unter den jeweiligen Umständen ein bestimmtes Modell wählen sollten.
Hier kommt Mistral ins Spiel – testen Sie es noch heute
Als eines der ersten Large-Language-Modelle, das die Grouped-Query-Attention nutzt und sie mit der Sliding-Window-Attention kombiniert, scheint Mistral die perfekte Lösung gefunden zu haben – niedrige Latenz, hoher Durchsatz und eine sehr gute Performance bei Benchmarks, selbst im Vergleich zu größeren Modellen (13B). Alles, was ich sagen will, ist, dass es für seine Größe sehr viel zu bieten hat, und wir freuen uns sehr, es heute allen Entwicklern über Workers AI zur Verfügung stellen zu können.
Schauen Sie sich unsere Entwicklerdokumente an, um loszulegen, und wenn Sie Hilfe benötigen, Feedback geben oder Ihre Arbeit mit anderen teilen möchten, besuchen Sie einfach unseren Developer Discord!
Das Workers AI-Team wächst und stellt neue Mitarbeitende ein. Schauen Sie auf unserer Karriere-Seite nach offenen Stellen, wenn Sie sich für KI-Engineering begeistern und uns beim Aufbau und der Weiterentwicklung unserer globalen, serverlosen GPU-gestützten Inferenzplattform unterstützen möchten.