


Als wir D1 im Mai dieses Jahres ankündigten, wussten wir, dass es der Beginn von etwas Neuem sein würde – unsere erste SQL-Datenbank mit Cloudflare Workers. Vor D1 haben wir Speicheroptionen wie KV (Schlüssel-Werte-Speicher), Durable Objects (strikt einheitlicher Datenspeicher an einem Ort) und R2 (Blob-Speicher) angekündigt. Eine Frage blieb jedoch stets unbeantwortet: „Wie kann ich relationale Daten speichern und mit einer einfachen API, ganz ohne Latenzprobleme abfragen?“
Die lang erwartete „Cloudflare-Datenbank“ war das fehlende Element. Nun können Sie Ihre Anwendung zur Gänze auf dem globalen Netzwerk von Cloudflare entwickeln und in Sekundenschnelle von einfachem VSCode zu einer Full-Stack-Anwendung übergehen. D1 ist mit der beliebten SQLite-API kompatibel und ermöglicht es Entwicklern, ihre Datenbanken zu entwickeln, ohne sich in der Komplexität zu verzetteln und jede darunter liegende Schicht verwalten zu müssen.
Seit der Ankündigung unserer Markteinführung im Mai und der Private Beta im Juni haben wir große Fortschritte bei der Verwirklichung unserer Vision einer serverlosen Datenbank gemacht. D1 befindet sich noch in der Private Beta aber eine Open Beta steht kurz bevor. Wir freuen uns darauf, über unseren Fortschritt bei der Entwicklung von D1 zu berichten und zu zeigen, was noch kommen wird.
Das D1-Erlebnis
Wir wussten aus dem Feedback zu Cloudflare Workers, dass viele Entwickler lieber Wrangler für das Erstellen und Bereitstellen von Anwendungen nutzen. Deshalb haben wir, als Wrangler 2.0 im vergangenen Mai zusammen mit D1 angekündigt wurde, die Vorteile der neuen und verbesserten CLI für jeden Teil der Erfahrung genutzt, von der Datenerstellung bis hin zu jedem Update und jeder Iteration. Werfen wir einen kurzen Blick darauf, wie man die Einrichtung in wenigen einfachen Schritten durchführen kann.
Erstellen Sie Ihre Datenbank
Wenn Sie die neueste Version von Wrangler installiert haben, können Sie eine initialisierte leere Datenbank mit einem einfachen
npx wrangler d1 create my_database_name
erstellen, um Ihre Datenbank zum Laufen zu bringen! Jetzt ist es an der Zeit, Ihre Daten hinzuzufügen.
Auf geht's – mit Bootstrapping
Es wäre nicht typisch Cloudflare, wenn Sie für die Einrichtung einen quälend langen Prozess durchlaufen müssten. Deshalb haben wir es einfach und mühelos gemacht, Ihre bestehenden Daten aus einer alten Datenbank zu übernehmen und Ihre neue D1-Datenbank zu booten. Sie können
wrangler d1 execute my_database-name --file ./filename.sql
ausführen und eine vorhandene SQLite-.sql-Datei Ihrer Wahl durchreichen. Ihre Datenbank ist nun einsatzbereit.
Entwickeln und testen Sie lokal
Wir haben eine Vielzahl von Verbesserungen an Wrangler vorgenommen, seitdem vor ein paar Monaten Version 2 auf den Markt kam. Nun freuen wir uns, berichten zu können, dass D1 jetzt sowohl mit reinem Remote-Support und lokalem Entwicklungssuport verfügbar ist:
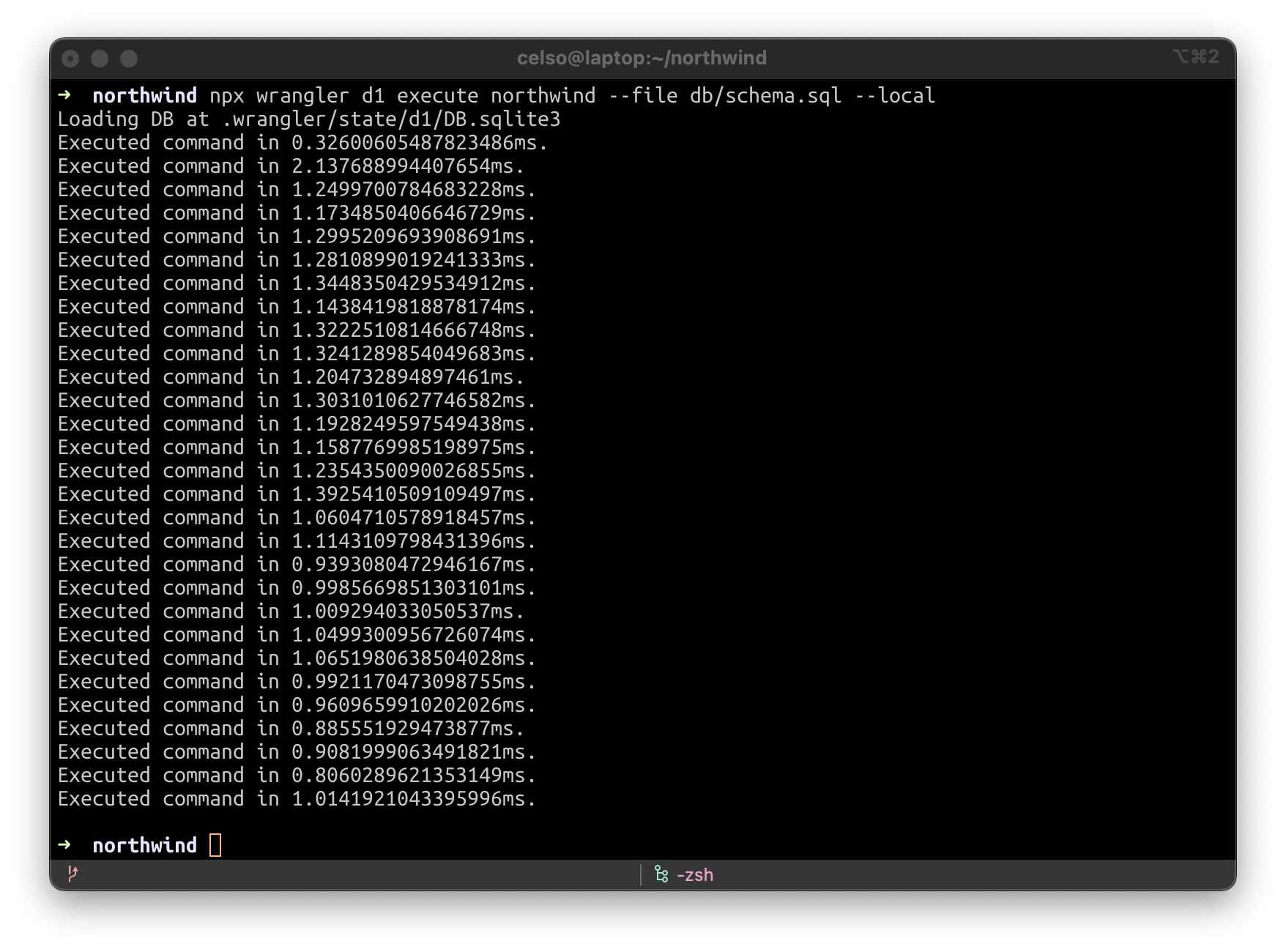
Wenn Sie wrangler dev -–local -–persist, ausführen, wird eine SQLite-Datei in .wrangler/state erstellt. Sie können dann ein lokales GUI-Programm zur Verwaltung dieser Datei verwenden, z. B. SQLiteFlow (https://www.sqliteflow.com/) oder Beekeeper (https://www.beekeeperstudio.io/).
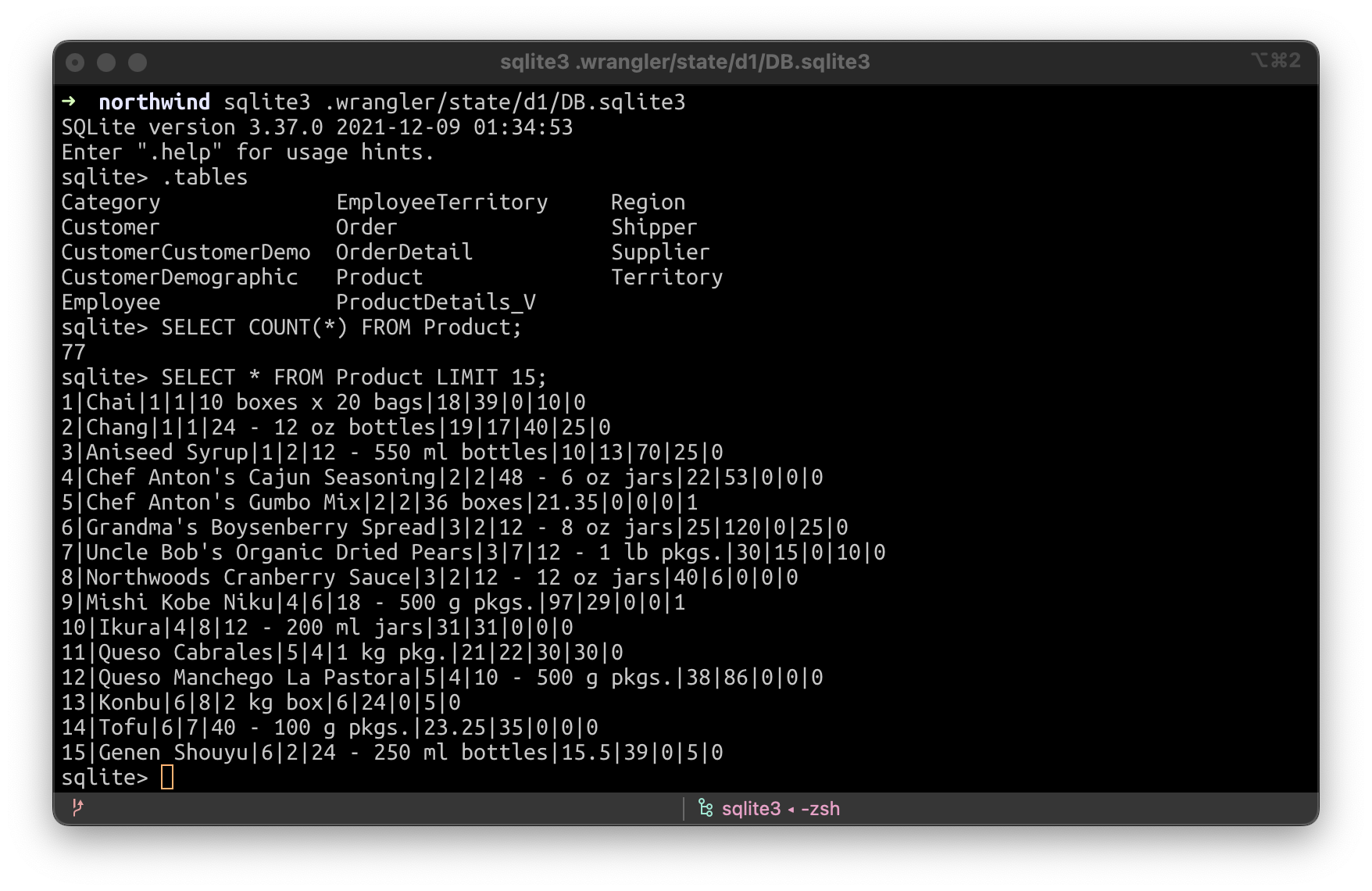
Oder Sie können SQLite direkt mit der SQLite-Kommandozeile verwenden, indem Sie sqlite3 .wrangler/state/d1/DB.sqlite3 ausführen:
Automatische Backups und Wiederherstellung mit einem Klick
Egal, wie sehr Sie Ihre Änderungen testen, manchmal laufen die Dinge nicht nach Plan. Aber mit Wrangler können Sie ein Backup Ihrer Daten erstellen, die Liste Ihrer Backups einsehen oder Ihre Datenbank aus einem bestehenden Backup wiederherstellen. Während der Beta-Phase erstellen wir stündlich automatisch Sicherungskopien Ihrer Daten und speichern diese in R2, so dass Sie bei Bedarf Dateiänderungen rückgängig machen können.
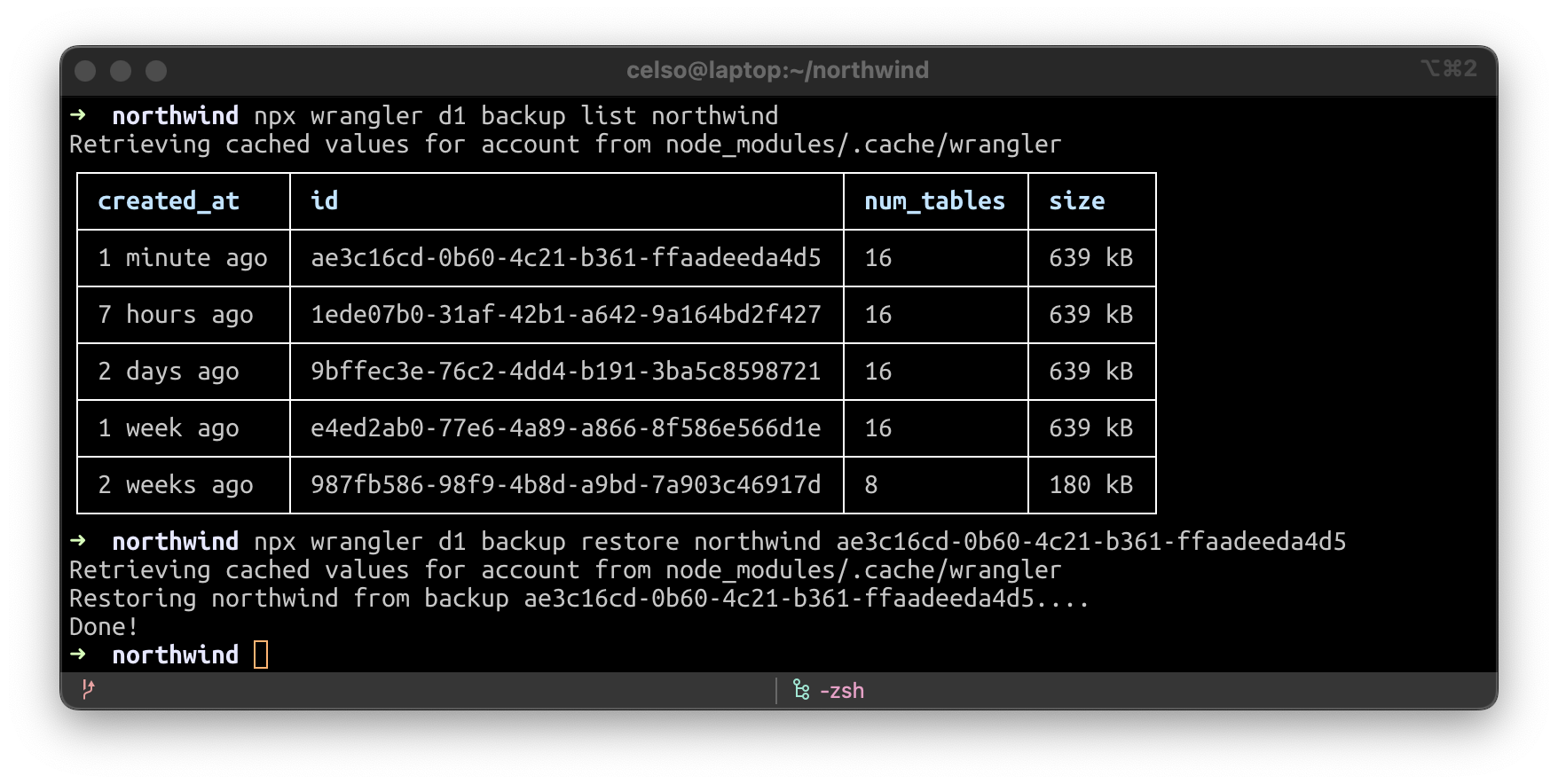
Und das Beste daran: Wenn Sie einen Momentaufnahme aus der Produktions für die lokale Entwicklung oder zur Reproduktion eines Fehlers verwenden wollen, kopieren Sie ihn einfach in das Verzeichnis .wrangler/state und wrangler dev –-local –-persist wird ihn aufnehmen!
Laden wir ein D1-Backup auf unsere lokale Festplatte herunter. Sie ist mit SQLite kompatibel.
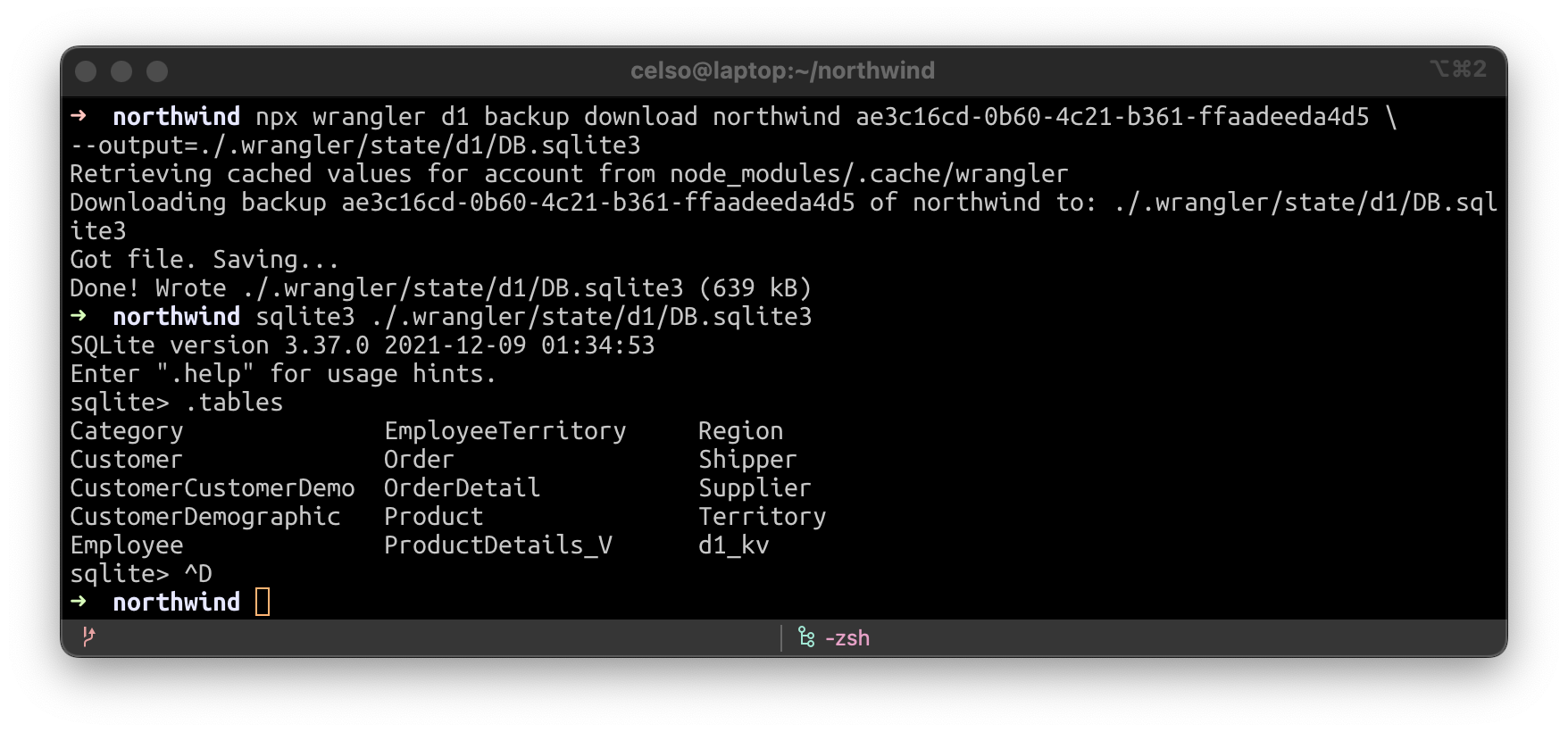
Nun starten wir unseren D1-Worker lokal vom Backup aus.
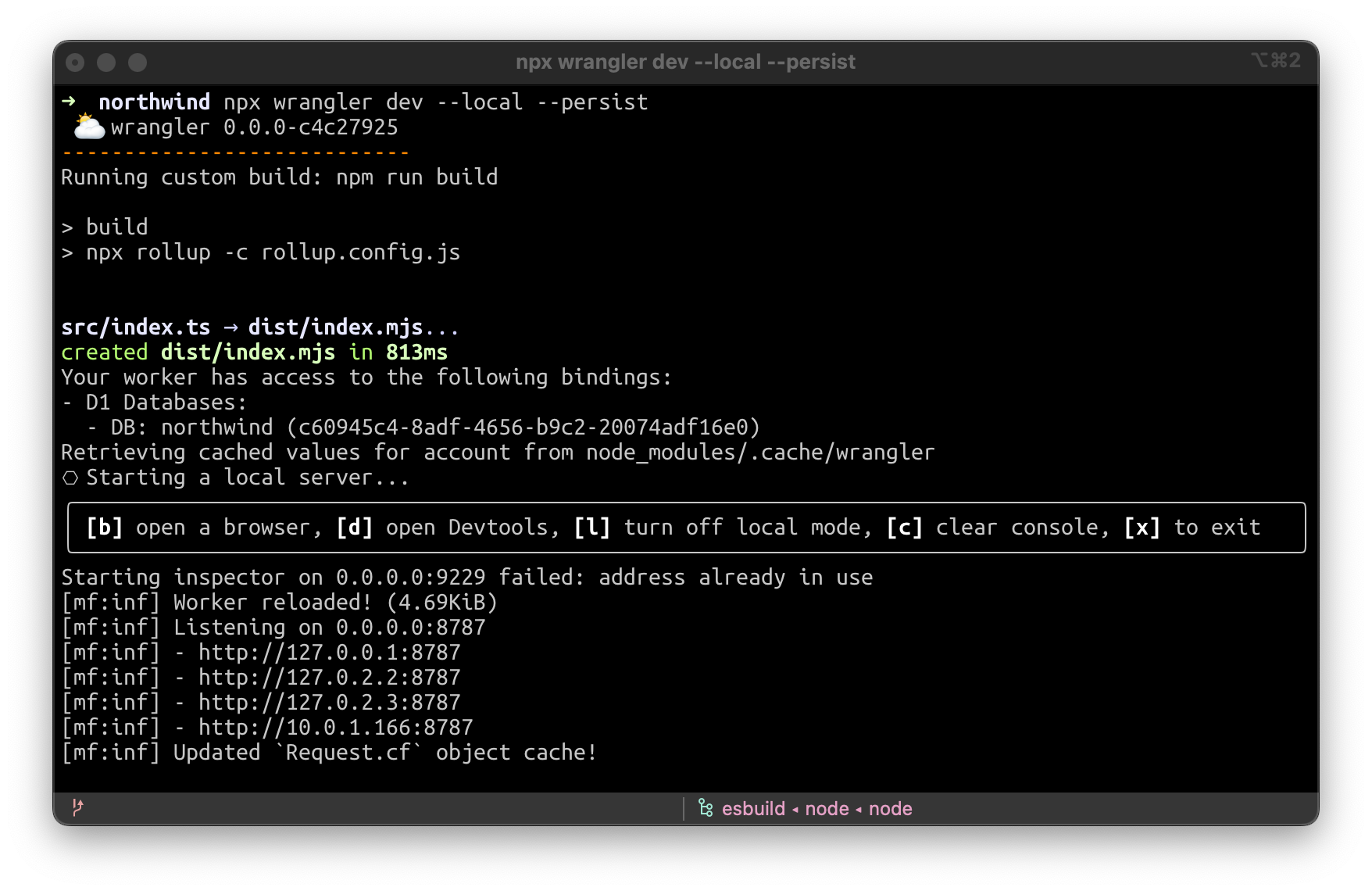
Erstellen und Verwalten über das Dashboard
Wir sind uns jedoch bewusst, dass CLIs nicht jedermanns Sache sind. Wir sind der Meinung, dass Datenbanken für jede Art von Entwickler zugänglich sein sollten – auch für solche ohne viel Datenbankerfahrung! D1 ist direkt über das Cloudflare-Dashboard verfügbar, so dass Sie mit wenigen Klicks nahezu eine völlige Übereinstimmung von Befehlen (Command Parity) mit Wrangler erreichen. Bootstrapping Ihrer Datenbank, Erstellen von Tabellen, Aktualisieren Ihrer Datenbank, Anzeigen von Tabellen und Auslösen von Backups sind alle auf Knopfdruck verfügbar.
In der Benutzeroberfläche vorgenommene Änderungen sind sofort für Ihre Mitarbeiter verfügbar – keine Bereitstellung erforderlich!
Wir haben Ihnen bereits von einigen der Verbesserungen berichtet, die wir seit der ersten Ankündigung von D1 eingeführt haben. Nun möchten wir Ihnen wie immer einen kleinen Vorgeschmack (mit einigen technischen Details) auf das geben, was noch kommen wird. Eine wirklich wichtige Funktion einer Datenbank sind Transaktionen – etwas, ohne das D1 nicht vollständig wäre.
Exklusive Vorschau: Wie wir JavaScript-Transaktionen in D1 einführen
Mit D1 bemühen wir uns, eine drastisch vereinfachte Schnittstelle für die Erstellung und Abfrage relationaler Daten zu bieten, was größtenteils eine gute Sache ist. Die Vereinfachung führt jedoch gelegentlich zu Nachteilen, wenn ein Anwendungsfall nicht mehr ohne die Einführung neuer Konzepte unterstützt werden kann. D1-Transaktionen sind ein Beispiel dafür.
Transaktionen sind eine einzigartige Herausforderung
Sie müssen nicht angeben, wo ein Cloudflare Worker oder eine D1-Datenbank ausgeführt wird – sie werden einfach dort ausgeführt, wo sie benötigt werden. Für Workers ist das so nah wie möglich an den Nutzern, die in diesem Moment auf Ihre Website zugreifen. Bei D1 versuchen wir heute nicht, an jedem Ort der Welt eine Kopie auszuführen, sondern verwalten die Anzahl und den Ort der schreibgeschützten Replikate dynamisch, je nachdem, wie viele Abfragen Ihre Datenbank erhält und von woher diese stammen. Bei Abfragen, die Änderungen an einer Datenbank vornehmen (die wir im Allgemeinen kurz als „Schreibvorgänge“ bezeichnen), müssen jedoch alle Abfragen zu der einzigen primären D1-Instanz zurückkehren, um ihre Funktion zu erfüllen und Einheitlichkeit zu gewährleisten.
Was aber, wenn Sie eine Reihe von Aktualisierungen auf einmal vornehmen müssen? Sie können zwar mehrere SQL-Abfragen mit .batch() senden (wobei tatsächlich Datenbanktransaktionen verwendet werden). Es ist jedoch wahrscheinlich, dass Sie irgendwann Datenbankabfragen und JS-Code in einer einzigen Arbeitseinheit verschachteln möchten.
Genau dafür wurden Datenbanktransaktionen erfunden, aber wenn Sie versuchen, BEGIN TRANSACTION in D1 auszuführen, erhalten Sie eine Fehlermeldung. Sehen wir uns nun näher an, warum das so ist.
Warum native Transaktionen nicht funktionieren
Das Problem entsteht dadurch, dass SQL-Anweisungen und JavaScript-Code an völlig unterschiedlichen Orten ausgeführt werden – Ihr SQL wird innerhalb Ihrer D1-Datenbank ausgeführt (primäre D1-Instanz für Schreibvorgänge, nächstgelegene Kopie für Lesevorgänge), aber Ihr Worker läuft in der Nähe des Nutzers, der sich auf der anderen Seite der Welt befinden kann. Und da D1 auf SQLite aufbaut, kann nur eine Schreibtransaktion gleichzeitig geöffnet sein. Das bedeutet, dass, wenn wir BEGIN TRANSACTION zulassen, eine einzige Worker-Anfrage irgendwo auf der Welt Ihre gesamte Datenbank blockieren könnte! Dies zuzulassen ist ziemlich gefährlich:
- Ein Worker könnte eine Transaktion starten und dann aufgrund eines Softwarefehlers abstürzen, ohne
ROLLBACKaufzurufen. Die primäre D1-Instanz wäre blockiert und würde auf weitere Befehle von einem Worker warten, die nie kommen würden (wahrscheinlich bis zu einem Timeout). - Selbst ohne Fehler (Bugs) oder Abstürze können Transaktionen, die mehrere Roundtrips zwischen JavaScript und SQL erfordern, Ihr gesamtes System für mehrere Sekunden blockieren. Dies schränkt die Skalierbarkeit einer mit Workers & D1 erstellten Anwendung drastisch ein.
Aber die Möglichkeit, Transaktionen zu definieren, die sowohl SQL als auch JavaScript kombinieren, macht die Erstellung von Anwendungen mit Workers & D1 so viel flexibler und leistungsfähiger. Wir brauchen eine neue Lösung (oder, in unserem Fall, eine neue Version einer alten Lösung).
Ein möglicher Lösungsansatz: gespeicherte Prozeduren
Gespeicherte Prozeduren (stored procedures) sind Codeschnipsel, die in die Datenbank hochgeladen werden, um direkt neben den Daten ausgeführt zu werden. Das klingt im ersten Moment genau nach dem, was wir wollen.
In der Praxis ist die Arbeit mit gespeicherten Prozeduren in herkömmlichen Datenbanken jedoch bekanntermaßen frustrierend, wie Ihnen jeder bestätigen kann, der ein System entwickelt hat, in dem diese Verfahren häufig zum Einsatz kommen:
- Sie sind oft in einer anderen Sprache geschrieben als der Rest Ihrer Anwendung. Sie sind in der Regel in (einem bestimmten Dialekt von) SQL oder einer eingebetteten Sprache wie Tcl/Perl/Python geschrieben. Und obwohl es technisch möglich ist, sie in JavaScript zu schreiben (unter Verwendung einer eingebetteten V8-Engine), werden sie in einer Umgebung ausgeführt, die sich so sehr von der Ihres Anwendungscodes unterscheidet, dass ihre Wartung einen enormen Kontextwechsel erforderlich macht.
- Die Tatsache, dass sowohl Anwendungs- als auch Datenbankcode vorhanden sind, wirkt sich auf jeden Teil des Entwicklungslebenszyklus aus, von der Erstellung über das Testen, die Bereitstellung bis hin zu Rollbacks und Debugging. Da gespeicherte Prozeduren jedoch in der Regel zur Lösung eines bestimmten Problems und nicht als allgemeine Anwendungsschicht eingeführt werden, werden sie häufig vollständig manuell verwaltet. Das kann dazu führen, dass sie einmal geschrieben, in die Datenbank aufgenommen und dann nicht mehr geändert werden, weil man befürchtet, etwas kaputt zu machen.
Mit D1 können wir es besser machen.
Der Sinn einer gespeicherten Prozedur bestand darin, direkt neben den Daten ausgeführt zu werden. Das Hochladen des Codes und die Ausführung in der Datenbank waren lediglich ein Mittel zum Zweck. Aber wir verwenden Workers, eine globale JavaScript-Ausführungsplattform. Können wir sie nutzen, um dieses Problem zu lösen?
Wie sich herausstellt: Ja, absolut! Hier gibt es aber einige Möglichkeiten, wie man es umsetzen kann. Darum arbeiten wir mit unseren Private Beta-Nutzern daran, die richtige API zu finden. In diesem Abschnitt möchte ich Ihnen unseren derzeit bevorzugten Vorschlag vorstellen und Sie alle auffordern, uns Ihr Feedback zu geben.
Wenn Sie ein Worker-Projekt mit einer D1-Datenbank verbinden, fügen Sie einen Abschnitt wie den folgenden in Ihre wrangler.toml ein:
[[ d1_databases ]]
# What binding name to use (e.g. env.DB):
binding = "DB"
# The name of the DB (used for wrangler d1 commands):
database_name = "my-d1-database"
# The D1's ID for deployment:
database_id = "48a4224e-...3b09"
# Which D1 to use for `wrangler dev`:
# (can be the same as the previous line)
preview_database_id = "48a4224e-...3b09"
# NEW: adding "procedures", pointing to a new JS file:
procedures = "./src/db/procedures.js"
Diese D1-Prozeduren-Datei würde Folgendes enthalten (beachten Sie die neue db.transaction() API, die nur innerhalb einer solchen Datei verfügbar ist):
export default class Procedures {
constructor(db, env, ctx) {
this.db = db
}
// any methods you define here are available on env.DB.Procedures
// inside your Worker
async Checkout(cartId: number) {
// Inside a Procedure, we have a new db.transaction() API
const result = await this.db.transaction(async (txn) => {
// Transaction has begun: we know the user can't add anything to
// their cart while these actions are in progress.
const [cart, user] = Helpers.loadCartAndUser(cartId)
// We can update the DB first, knowing that if any of the later steps
// fail, all these changes will be undone.
await this.db
.prepare(`UPDATE cart SET status = ?1 WHERE cart_id = ?2`)
.bind('purchased', cartId)
.run()
const newBalance = user.balance - cart.total_cost
await this.db
.prepare(`UPDATE user SET balance = ?1 WHERE user_id = ?2`)
// Note: the DB may have a CHECK to guarantee 'user.balance' can not
// be negative. In that case, this statement may fail, an exception
// will be thrown, and the transaction will be rolled back.
.bind(newBalance, cart.user_id)
.run()
// Once all the DB changes have been applied, attempt the payment:
const { ok, details } = await PaymentAPI.processPayment(
user.payment_method_id,
cart.total_cost
)
if (!ok) {
// If we throw an Exception, the transaction will be rolled back
// and result.error will be populated:
// throw new PaymentFailedError(details)
// Alternatively, we can do both of those steps explicitly
await txn.rollback()
// The transaction is rolled back, our DB is now as it was when we
// started. We can either move on and try something new, or just exit.
return { error: new PaymentFailedError(details) }
}
// This is implicitly called when the .transaction() block finishes,
// but you can explicitly call it too (potentially committing multiple
// times in a single db.transaction() block).
await txn.commit()
// Anything we return here will be returned by the
// db.transaction() block
return {
amount_charged: cart.total_cost,
remaining_balance: newBalance,
}
})
if (result.error) {
// Our db.transaction block returned an error or threw an exception.
}
// We're still in the Procedure, but the Transaction is complete and
// the DB is available for other writes. We can either do more work
// here (start another transaction?) or return a response to our Worker.
return result
}
}
Und in Ihrem Worker hat Ihre DB-Bindung jetzt eine Eigenschaft „Prozeduren“, in der Ihre Funktionsnamen bereitstehen:
const { error, amount_charged, remaining_balance } =
await env.DB.Procedures.Checkout(params.cartId)
if (error) {
// Something went wrong, `error` has details
} else {
// Display `amount_charged` and `remaining_balance` to the user.
}
Es können mehrere Prozeduren gleichzeitig ausgelöst werden, aber es kann nur eine db.transaction()-Funktion gleichzeitig aktiv sein: Alle anderen Schreibabfragen oder andere Transaktionsblöcke werden in eine Warteschlange gestellt, aber alle Leseabfragen werden weiterhin auf lokale Kopien zugreifen und wie gewohnt ausgeführt. Diese API gibt Ihnen die Möglichkeit, Einheitlichkeit zu gewährleisten, wenn es notwendig ist, allerdings mit nur minimalen Auswirkungen auf die Gesamtperformance weltweit.
Bitte um Feedback
Wie bei allen unseren Produkten bestimmen die Rückmeldungen unserer Nutzer die Roadmap und die Entwicklung. Die D1-API befindet sich derzeit im Betatest, aber wir sind immer noch auf der Suche nach Feedback zu den einzelnen Funktionen. Wir freuen uns jedoch, dass damit sowohl die D1-spezifischen Probleme mit Transaktionen als auch die zuvor beschriebenen Probleme mit gespeicherten Prozeduren gelöst werden:
- Der Code wird so nah wie möglich an der Datenbank ausgeführt, so dass keine Netzwerklatenz entsteht, während eine Transaktion geöffnet ist.
- Alle Ausnahmen oder Abbrüche einer Transaktion führen zu einem sofortigen Rollback – es gibt keine Möglichkeit, versehentlich eine Transaktion offen zu lassen und die gesamte D1-Instanz zu blockieren.
- Der Code ist in der gleichen Sprache wie der übrige Code Ihres Workers, in genau dem gleichen Dialekt (z. B. dieselbe TypeScript-Konfiguration, da sie Teil desselben Builds ist).
- Er wird nahtlos als Teil Ihres Workers bereitgestellt. Wenn zwei Worker an dieselbe D1-Instanz gebunden sind, aber unterschiedliche Prozeduren definieren, sehen sie nur ihren eigenen Code. Wenn Sie Code zwischen Projekten oder Datenbanken austauschen möchten, extrahieren Sie eine Bibliothek wie bei jedem anderen gemeinsam genutzten Code.
- Beim lokalen Entwickeln und Testen funktioniert die Prozedur genauso wie in der Produktion, jedoch ohne den Netzwerkaufruf, so dass ein nahtloses Testen und Debuggen möglich ist, als wäre es eine lokale Funktion.
- Da Prozeduren und die Worker, die sie definieren, als eine Einheit behandelt werden, führt ein Zurücksetzen auf eine frühere Version nie zu einer Verschiebung zwischen dem Code in der Datenbank und dem Code im Worker.
Das D1-Ökosystem: Beiträge aus der Community
Wir haben Ihnen bereits berichtet, was wir bisher gemacht haben und was vor uns liegt, aber das Einzigartige an diesem Projekt sind die vielen Beiträge unserer Nutzer. Was uns an Private Beta-Tests besonders gefällt, ist nicht nur, dass wir Feedback und Funktionswünsche erhalten, sondern auch zu sehen, welche Ideen und Projekte verwirklicht werden. Manchmal handelt es sich dabei um persönliche Projekte, aber bei D1 sehen wir einige unglaubliche Beiträge zum D1-Ökosystem. Natürlich wurde die Arbeit an D1 nicht nur vom D1-Team vorangetrieben, sondern auch von der breiteren Community und anderen Entwicklern bei Cloudflare. Nutzer haben ihre D1-Erweiterungen in unserem Discord-Kanal für die Private Beta vorgestellt und anderen die Möglichkeit gegeben, sie ebenfalls zu nutzen. Wir möchten sie hier kurz vorstellen.
workers-qb
Der Umgang mit roher SQL-Syntax ist zwar gewaltig (und mit der D1 .bind()-API sicher vor SQL-Injections), aber er kann etwas umständlich sein. Andererseits setzen die meisten existierenden Query Builder einen direkten Zugriff auf die zugrundeliegende DB voraus und sind daher nicht für die Verwendung mit D1 geeignet. Deshalb hat Cloudflare-Entwickler Gabriel Massadas einen kleinen, abhängigkeitsfreien Query Builder namens workers-qb entwickelt:
import { D1QB } from 'workers-qb'
const qb = new D1QB(env.DB)
const fetched = await qb.fetchOne({
tableName: "employees",
fields: "count(*) as count",
where: {
conditions: "active = ?1",
params: [true]
},
})
Weitere Informationen finden Sie auf der Projekthomepage: https://workers-qb.massadas.com/.
D1 console
Obwohl Sie mit D1 sowohl über Wrangler als auch über das Dashboard interagieren können, hat Cloudflare-Community-Champion Isaac McFadyen die allererste D1-Konsole entwickelt, mit der Sie schnell eine Reihe von Abfragen direkt über Ihr Terminal ausführen können. Mit der D1-Konsole brauchen Sie keine Zeit mit dem Schreiben der verschiedenen Wrangler-Befehle zu verbringen, die wir erstellt haben – Sie führen einfach Ihre Abfragen aus.
Sie enthält alle Extras, die Sie von einer modernen Datenbankkonsole erwarten, einschließlich mehrzeiliger Eingaben, Befehlshistorie, Validierung für bislang von D1 noch nicht unterstützte Funktionen und die Möglichkeit, Ihre Cloudflare-Zugangsdaten zur späteren Verwendung zu speichern.
Weitere Informationen über das gesamte Projekt finden Sie auf GitHub oder NPM.
Miniflare Test-Integration
Das Miniflare-Projekt, das die lokale Entwicklungserfahrung von Wrangler ermöglicht, bietet auch vollwertige Testumgebungen für die beliebten JavaScript-Test-Runner, Jest und Vitest. Damit einher geht das Konzept der isolierten Speicherung (Isolated Storage), das es jedem Test ermöglicht, unabhängig voneinander zu laufen, so dass sich Änderungen in einem Test nicht auf die anderen auswirken. Brendan Coll, der Erfinder von Miniflare, hat die Implementierung des D1-Tests so gestaltet, dass er dieselben Vorteile bietet:
import Worker from ‘../src/index.ts’
const { DB } = getMiniflareBindings();
beforeAll(async () => {
// Your D1 starts completely empty, so first you must create tables
// or restore from a schema.sql file.
await DB.exec(`CREATE TABLE entries (id INTEGER PRIMARY KEY, value TEXT)`);
});
// Each describe block & each test gets its own view of the data.
describe(‘with an empty DB’, () => {
it(‘should report 0 entries’, async () => {
await Worker.fetch(...)
})
it(‘should allow new entries’, async () => {
await Worker.fetch(...)
})
])
// Use beforeAll & beforeEach inside describe blocks to set up particular DB states for a set of tests
describe(‘with two entries in the DB’, () => {
beforeEach(async () => {
await DB.prepare(`INSERT INTO entries (value) VALUES (?), (?)`)
.bind(‘aaa’, ‘bbb’)
.run()
})
// Now, all tests will run with a DB with those two values
it(‘should report 2 entries’, async () => {
await Worker.fetch(...)
})
it(‘should not allow duplicate entries’, async () => {
await Worker.fetch(...)
})
])
Alle Datenbanken für die Tests werden im Arbeitsspeicher ausgeführt, so dass sie blitzschnell sind. Schnelle und zuverlässige Tests sind ein wichtiger Bestandteil bei der Entwicklung von wartungsfreundlichen Anwendungen, daher freuen wir uns, dass wir diese Möglichkeit auf D1 ausweiten können.
Möchten Sie an der Private Beta teilnehmen?
Sie wurden inspiriert?
Wir lieben es zu sehen, was unsere Nutzer in der Beta-Phase entwickeln oder entwickeln wollen, besonders wenn sich unsere Produkte noch in einem frühen Stadium befinden. Nun, da wir uns der Open Beta-Phase nähern, sind wir besonders auf Ihr Feedback angewiesen. Wir lassen langsam immer mehr Leute in die Beta-Phase, aber wenn Sie noch kein „goldenes Ticket“ für den Zugang erhalten haben, melden Sie sich hier an! Sobald Sie eingeladen worden sind, erhalten Sie eine offizielle Willkommens-E-Mail.
Wie immer: Viel Spaß beim Entwickeln!