Vectorize ist unser brandneues Vektordatenbank-Angebot, mit dem Sie KI-gestützte Full-Stack-Anwendungen komplett auf dem globalen Netzwerk von Cloudflare erstellen können: und Sie können sofort damit beginnen. Vectorize befindet sich in der Open Beta-Phase und steht jedem Entwickler zur Verfügung, der Cloudflare Workers verwendet.
Sie können Vectorize mit Workers AI verwenden, um Anwendungsfälle der semantischen Suche, Klassifizierung, Empfehlung und Anomalieerkennung direkt mit Workers zu unterstützen, die Genauigkeit und den Kontext von Antworten aus LLMs (Large Language Models) zu verbessern und/oder eigene Einbettungen von beliebten Plattformen, einschließlich OpenAI und Cohere, einzubringen.
Besuchen Sie die Entwicklerdokumentation von Vectorize, um loszulegen, oder lesen Sie weiter, wenn Sie besser verstehen möchten, was Vektordatenbanken machen und worin sich Vectorize unterscheidet.
Warum benötige ich eine Vektordatenbank?
Machine Learning-Modelle können sich nichts merken: nur das, worauf sie trainiert wurden.
Vektordatenbanken wurden entwickelt, um dieses Problem zu lösen, indem sie erfassen, wie ein ML-Modell Daten repräsentiert – einschließlich strukturierter und unstrukturierter Texte, Bilder und Audiodaten – und sie so speichern, dass sie mit zukünftigen Eingaben verglichen werden können. Dadurch können wir die Leistung bestehender Machine Learning-Modelle und LLMs (Large Language Models) für Inhalte nutzen, für die sie nicht trainiert wurden: was sich angesichts der enormen Kosten für das Training von Modellen als äußerst leistungsstark erweist.
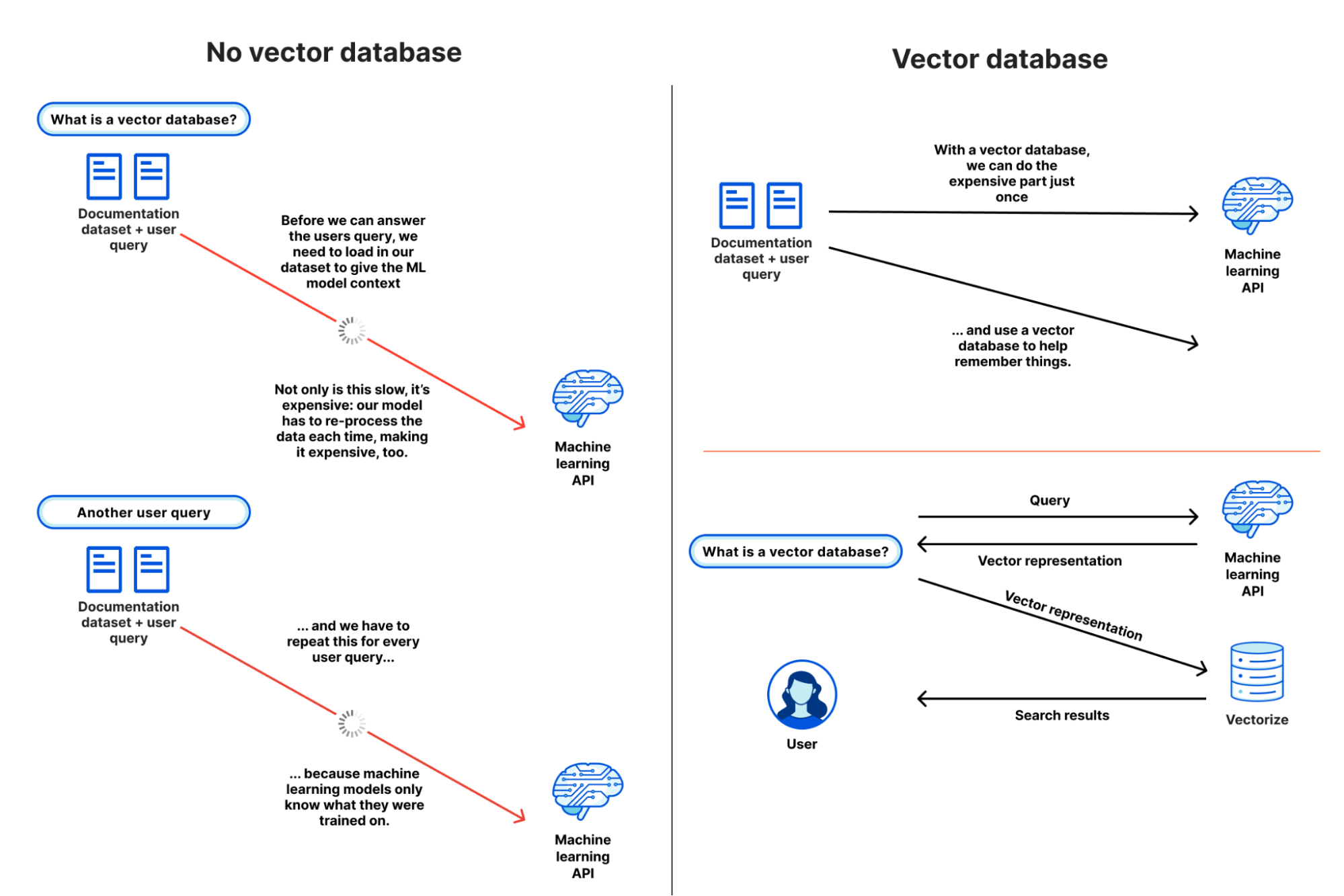
Um besser zu veranschaulichen, warum eine Vektordatenbank wie Vectorize nützlich ist, stellen wir uns vor, es gäbe sie nicht, und betrachten, wie mühsam es ist, einem ML-Modell oder LLM für eine semantische Such- oder Empfehlungsaufgabe Kontext zu geben.Unser Ziel ist es, herauszufinden, welche Inhalte unserer Abfrage ähnlich sind, und diese auszugeben: auf der Grundlage unseres eigenen Datensatzes.
- Die folgende Nutzerabfrage geht ein: Sie suchen nach „Wie schreibt man von Cloudflare Workers auf R2“
- Wir laden unseren gesamten Dokumentationsdatensatz – ein glücklicherweise „kleiner“ Datensatz mit etwa 65.000 Sätzen oder 2,1 GB – und stellen ihn zusammen mit der Abfrage unseres Nutzers bereit.Dadurch erhält das Modell den erforderlichen Kontext – basierend auf unseren Daten.
- Wir warten.
- (Sehr lange)
- Wir erhalten unsere Ähnlichkeitsbewertungen zurück, mit den Sätzen, die der Abfrage des Nutzers am ähnlichsten sind, und arbeiten dann daran, diese wieder auf URLs zu verweisen, bevor wir unsere Suchergebnisse zurückgeben.
... und dann kommt eine weitere Abfrage, und wir müssen wieder von vorne anfangen.
In der Praxis ist dies nicht wirklich möglich: Wir können den meisten Machine-Learning-Modellen nicht so viel Kontext in einem API-Aufruf (Prompt) übergeben, und selbst wenn wir es könnten, würde es enormen Speicherplatz und viel Zeit in Anspruch nehmen, unseren Datensatz immer wieder zu verarbeiten.
Mit einer Vektordatenbank müssen wir Schritt 2 nicht wiederholen: Wir führen ihn einmal durch, oder wenn unser Datensatz aktualisiert wird, und verwenden unsere Vektordatenbank, um eine Art Langzeitgedächtnis für unser Machine Learning-Modell zu schaffen.Unser Arbeitsablauf sieht in etwa so aus:
- Wir laden unseren gesamten Dokumentationsdatensatz, lassen ihn durch unser Modell laufen und speichern die resultierenden Vektoreinbettungen in unserer Vektordatenbank (nur einmal).
- Für jede Abfrage eines Nutzers (und nur für die Abfrage) fragen wir das gleiche Modell ab und erhalten eine Vektordarstellung.
- Wir fragen unsere Vektordatenbank mit diesem Abfragevektor ab, die die Vektoren zurückgibt, die unserem Abfragevektor am nächsten liegen.
Wenn wir diese beiden Abläufe nebeneinander betrachten, können wir schnell erkennen, wie ineffizient und unpraktisch es ist, unseren eigenen Datensatz mit einem bestehenden Modell ohne Vektordatenbank zu verwenden:
Anhand dieses einfachen Beispiels wird es wahrscheinlich allmählich verständlich: Sie fragen sich aber vielleicht auch, warum Sie eine Vektordatenbank und nicht nur eine normale Datenbank benötigen.
Vektoren sind die Repräsentation eines Inputs durch das Modell: die Art und Weise, wie es diesen Input auf seine interne Struktur oder „Features“ abbildet.Allgemein gilt: Je ähnlicher die Vektoren sind, desto mehr Ähnlichkeit vermutet das Modell zwischen diesen Eingaben auf der Grundlage der Art und Weise, wie es Merkmale aus einer Eingabe extrahiert.
Dies ist scheinbar einfach, wenn wir uns Beispielvektoren mit nur einer Handvoll Dimensionen ansehen. Bei realen Ergebnissen ist die Suche in 10.000 bis 250.000 Vektoren, von denen jeder potenziell 1.536 Dimensionen umfasst, jedoch nicht trivial. Hier kommen Vektordatenbanken ins Spiel: Damit die Suche im großen Maßstab funktioniert, verwenden Vektordatenbanken eine bestimmte Klasse von Algorithmen, wie z. B. „k-nearest neighbors“- (kNN) oder andere „approximate nearest neighbor“- (ANN) Algorithmen, um die Vektorähnlichkeit zu bestimmen.
Und obwohl Vektordatenbanken bei der Entwicklung von KI- und Machine-Learning-gestützten Anwendungen äußerst nützlich sind, eignen sie sich nicht nur für diese Anwendungsfälle: Sie können für eine Vielzahl von Klassifizierungs- und Anomalieerkennungsaufgaben verwendet werden. Zu wissen, ob eine Abfrageeingabe anderen Eingaben ähnlich – oder potenziell unähnlich – ist, kann auch für die Moderation von Inhalten („Stimmt diese mit bekannten schlechten Inhalten überein?“) und für Sicherheitswarnungen („Habe ich das schon einmal gesehen?“) verwendet werden.
Entwicklung einer Recommendation Engine (Empfehlungsmaschine) mit Vektorsuche
Wir haben Vectorize als leistungsstarken Partner für Workers AI: Damit können Sie Vektorsuchaufgaben so nah wie möglich an den Nutzern durchführen, ohne sich um die Skalierung für die Produktion kümmern zu müssen.
Wir nehmen ein Beispiel aus der Praxis – die Entwicklung einer (Produkt-)Empfehlungsmaschine für einen E-Commerce-Store – und vereinfachen ein paar Dinge.
Unser Ziel ist es, auf jeder Produktseite eine Liste "relevanter Produkte" anzuzeigen: ein perfekter Anwendungsfall für die Vektorsuche. Unsere Eingabevektoren im Beispiel sind Platzhalter, aber in einer realen Anwendung würden wir sie auf der Grundlage von Produktbeschreibungen und/oder Warenkorbdaten generieren, indem wir sie durch ein Satzähnlichkeitsmodell (wie das Texteinbettungsmodel; Text Embedding Model von Workers AI) leiten.
Jeder Vektor steht für ein Produkt in unserem Shop, und wir verknüpfen die URL des Produkts mit diesem. Wir könnten auch die ID jedes Vektors auf die Produkt-ID setzen: beide Ansätze sind gültig. Unsere Abfrage – die Vektorsuche – stellt die Produktbeschreibung und den Inhalt des Produkts dar, das der Nutzer gerade betrachtet.
Lassen Sie uns Schritt für Schritt durchgehen, wie dies im Code aussieht: Dieses Beispiel stammt direkt aus unserer Entwicklerdokumentation:
export interface Env {
// This makes our vector index methods available on env.MY_VECTOR_INDEX.*
// e.g. env.MY_VECTOR_INDEX.insert() or .query()
TUTORIAL_INDEX: VectorizeIndex;
}
// Sample vectors: 3 dimensions wide.
//
// Vectors from a machine-learning model are typically ~100 to 1536 dimensions
// wide (or wider still).
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (new URL(request.url).pathname !== '/') {
return new Response('', { status: 404 });
}
// Insert some sample vectors into our index
// In a real application, these vectors would be the output of a machine learning (ML) model,
// such as Workers AI, OpenAI, or Cohere.
let inserted = await env.TUTORIAL_INDEX.insert(sampleVectors);
// Log the number of IDs we successfully inserted
console.info(`inserted ${inserted.count} vectors into the index`);
// In a real application, we would take a user query - e.g. "durable
// objects" - and transform it into a vector emebedding first.
//
// In our example, we're going to construct a simple vector that should
// match vector id #5
let queryVector: Array<number> = [54.8, 5.5, 3.1];
// Query our index and return the three (topK = 3) most similar vector
// IDs with their similarity score.
//
// By default, vector values are not returned, as in many cases the
// vectorId and scores are sufficient to map the vector back to the
// original content it represents.
let matches = await env.TUTORIAL_INDEX.query(queryVector, { topK: 3, returnVectors: true });
// We map over our results to find the most similar vector result.
//
// Since our index uses the 'cosine' distance metric, scores will range
// from 1 to -1. A value of '1' means the vector is the same; the
// closer to 1, the more similar. Values of -1 (least similar) and 0 (no
// match).
// let closestScore = 0;
// let mostSimilarId = '';
// matches.matches.map((match) => {
// if (match.score > closestScore) {
// closestScore = match.score;
// mostSimilarId = match.vectorId;
// }
// });
return Response.json({
// This will return the closest vectors: we'll see that the vector
// with id = 5 has the highest score (closest to 1.0) as the
// distance between it and our query vector is the smallest.
// Return the full set of matches so we can see the possible scores.
matches: matches,
});
},
};
Der obige Code ist absichtlich einfach gehalten, veranschaulicht aber die Vektorsuche im Kern: Wir fügen Vektoren in unsere Datenbank ein und fragen sie nach Vektoren mit dem kleinsten Abstand zu unserem Abfragevektor ab.Hier sind die Ergebnisse, einschließlich der Werte, sodass wir visuell feststellen können, dass unser Abfragevektor [54.8, 5.5, 3.1] unserem Suchergebnis mit der höchsten Übereinstimmung ähnelt: [58.799, 6.699, 3.400], die von unserer Suche zurückgegeben wurde. Dieser Index verwendet die Cosinus-Ähnlichkeit, um den Abstand zwischen den Vektoren zu berechnen, d. h. je näher die Punktzahl bei 1 liegt, desto ähnlicher ist eine Übereinstimmung mit unserem Abfragevektor.
{
"matches": {
"count": 3,
"matches": [
{
"score": 0.999909,
"vectorId": "5",
"vector": {
"id": "5",
"values": [
58.79999923706055,
6.699999809265137,
3.4000000953674316
],
"metadata": {
"url": "/products/sku/55519183"
}
}
},
{
"score": 0.789848,
"vectorId": "4",
"vector": {
"id": "4",
"values": [
75.0999984741211,
67.0999984741211,
29.899999618530273
],
"metadata": {
"url": "/products/sku/418313"
}
}
},
{
"score": 0.611976,
"vectorId": "2",
"vector": {
"id": "2",
"values": [
15.100000381469727,
19.200000762939453,
15.800000190734863
],
"metadata": {
"url": "/products/sku/10148191"
}
}
}
]
}
}
In einer realen Anwendung könnten wir nun schnell Produktempfehlungs-URLs auf der Grundlage der ähnlichsten Produkte zurückgeben, sie nach ihrer Punktzahl (höchste bis niedrigste) sortieren und den topK-Wert erhöhen, wenn wir mehr anzeigen möchten. Die neben jedem Vektor gespeicherten Metadaten könnten auch einen Pfad zu einem R2-Objekt, eine UUID für eine Zeile in einer D1 Datenbank, oder ein Schlüssel-Wert-Paar aus Workers KV einbetten.
Workers AI + Vectorize: Full-Stack-Vektorsuche auf Cloudflare
In einer realen Anwendung benötigen wir ein Machine Learning-Modell, das sowohl Vektoreinbettungen aus unserem Originaldatensatz generieren (um unsere Datenbank zu füllen) als auch Nutzeranfragen schnell in Vektoreinbettungen umwandeln kann. Diese müssen aus demselben Modell stammen, da jedes Modell Merkmale anders darstellt.
Hier ist ein kompaktes Beispiel für den Aufbau einer kompletten End-to-End-Vektorsuch-Pipeline auf Cloudflare:
import { Ai } from '@cloudflare/ai';
export interface Env {
TEXT_EMBEDDINGS: VectorizeIndex;
AI: any;
}
interface EmbeddingResponse {
shape: number[];
data: number[][];
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const ai = new Ai(env.AI);
let path = new URL(request.url).pathname;
if (path.startsWith('/favicon')) {
return new Response('', { status: 404 });
}
// We only need to generate vector embeddings just the once (or as our
// data changes), not on every request
if (path === '/insert') {
// In a real-world application, we could read in content from R2 or
// a SQL database (like D1) and pass it to Workers AI
const stories = ['This is a story about an orange cloud', 'This is a story about a llama', 'This is a story about a hugging emoji'];
const modelResp: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: stories,
});
// We need to convert the vector embeddings into a format Vectorize can accept.
// Each vector needs an id, a value (the vector) and optional metadata.
// In a real app, our ID would typicaly be bound to the ID of the source
// document.
let vectors: VectorizeVector[] = [];
let id = 1;
modelResp.data.forEach((vector) => {
vectors.push({ id: `${id}`, values: vector });
id++;
});
await env.TEXT_EMBEDDINGS.upsert(vectors);
}
// Our query: we expect this to match vector id: 1 in this simple example
let userQuery = 'orange cloud';
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let matches = await env.TEXT_EMBEDDINGS.query(queryVector.data[0], { topK: 1 });
return Response.json({
// We expect vector id: 1 to be our top match with a score of
// ~0.896888444
// We are using a cosine distance metric, where the closer to one,
// the more similar.
matches: matches,
});
},
};
Der obige Code bewirkt vier Dinge:
- Er übergibt die drei Sätze an das Texteinbettungsmodell von Workers AI (@cf/baai/bge-base-en-v1.5) und ermittelt ihre Vektoreinbettungen.
- Er fügt diese Vektoren in unseren Vectorize-Index ein.
- Er nimmt die Anfrage des Nutzers auf und wandelt sie mit Hilfe desselben Workers AI-Modells in eine Vektoreinbettung um.
- Es fragt unseren Vectorize-Index nach Übereinstimmungen ab.
Dieses Beispiel sieht vielleicht „zu“ einfach aus, aber in einer Produktionsanwendung müssten wir nur zwei Dinge ändern: Wir müssten unsere Vektoren nur einmal einfügen (oder regelmäßig über Cron-Trigger) und unsere drei Beispielsätze durch echte Daten ersetzen, die in R2, einer D1-Datenbank oder einem anderen Speicheranbieter gespeichert sind.
Tatsächlich ist dies der Art und Weise, wie wir Cursor betreiben, den KI-Assistenten, der Fragen zu Cloudflare Worker beantworten kann, sehr ähnlich: Wir haben Cursor so migriert, dass er auf Workers AI und Vectorize läuft. Wir generieren Texteinbettungen aus unserer Entwicklerdokumentation mithilfe des integrierten Texteinbettungsmodells, fügen sie in einen Vectorize-Index ein und transformieren Nutzeranfragen in Echtzeit über dasselbe Modell.
BYO-Einbettungen von Ihrer bevorzugten KI-API
Vectorize ist jedoch nicht nur auf Workers AI beschränkt: Es ist eine vollwertige, eigenständige Vektordatenbank.
Wenn Sie bereits die Embeddings-API von OpenAI, das mehrsprachige Modell von Cohere, oder eine andere Einbettungs-API verwenden, dann können Sie ganz einfach Ihre eigenen Vektoren in Vectorize einbringen.
Es funktioniert genauso: Sie generieren Ihre Einbettungen, fügen sie in Vectorize ein und leiten Ihre Abfragen durch das Modell, bevor Sie Ihren Index abfragen. Vectorize enthält ein paar Abkürzungen für einige der beliebtesten Einbettungsmodelle.
# Vectorize has ready-to-go presets that set the dimensions and distance metric for popular embeddings models
$ wrangler vectorize create openai-index-example --preset=openai-text-embedding-ada-002
Dies kann besonders nützlich sein, wenn Sie bereits einen bestehenden Arbeitsablauf rund um eine bestehende Einbettungs-API haben und/oder ein bestimmtes multimodales oder mehrsprachiges Einbettungsmodell für Ihren Anwendungsfall validiert haben.
KI-Kosten vorhersehbar machen
Die Begeisterung für KI und ML ist groß, aber es gibt auch eine große Sorge: dass es zu teuer ist, damit zu experimentieren, und dass es schwer ist, Vorhersagen im großen Stil zu treffen.
Mit Vectorize wollten wir ein einfacheres Preismodell für Vektordatenbanken anbieten. Sie haben eine Idee für ein Proof-of-Concept im Einsatz? Das sollte im Rahmen unserer kostenlosen Preisstufe sein. Sie skalieren und optimieren Ihre Einbettungsdimensionen im Hinblick auf Performance vs. Genauigkeit? Das sollte kein Vermögen kosten.
Wichtig ist, dass Vectorize maximale Vorhersehbarkeit bieten soll: Sie müssen den CPU- und Speicherverbrauch nicht abschätzen, was schwierig sein kann, wenn Sie gerade erst anfangen, und noch schwieriger wird, wenn Sie versuchen, für einen brandneuen Anwendungsfall zu planen, ob Sie zu Spitzenzeiten oder zu Zeiten außerhalb der Spitzenzeiten im Einsatz sind. Stattdessen wird Ihnen die Gesamtzahl der von Ihnen gespeicherten Vektordimensionen und die Anzahl der monatlichen Abfragen in Rechnung gestellt. Wir kümmern uns um die Skalierung, um Ihren Abfragemustern gerecht zu werden.
Hier sind die Preise für Vectorize – und wenn Sie jetzt einen bezahlten Workers-Tarif haben, können Sie Vectorize bis 2024 völlig kostenlos nutzen:
| Workers Free (demnächst verfügbar) | Workers Paid (5 $/Monat) | |
|---|---|---|
| Abgefragte Vektordimensionen inklusive | Insgesamt 30 Mio. abgefragte Dimensionen / Monat | Insgesamt 50 Mio. abgefragte Dimensionen / Monat |
| Gespeicherte Vektordimensionen inklusive | Insgesamt 5 Mio. gespeicherte Dimensionen / Monat | Insgesamt 10 Mio. gespeicherte Dimensionen / Monat |
| Zusätzliche Kosten | 0,04 $ / 1 Mio. abgefragter oder gespeicherter Vektordimensionen | 0,04 $ / 1 Mio. abgefragter oder gespeicherter Vektordimensionen |
Die Preisgestaltung basiert ausschließlich auf dem, was Sie speichern und abfragen: (insgesamt abgefragte + gespeicherte Vektordimensionen) * Dimensionen_pro_Vektor * Preis. Mehr abfragen? Einfach vorhersehbar. Optimierung für kleinere Dimensionen pro Vektor, um die Geschwindigkeit zu erhöhen und die Gesamtlatenzzeit zu verringern? Die Kosten sinken. Sie haben ein paar Indizes für Prototypen oder zum Experimentieren mit neuen Anwendungsfällen? Wir berechnen keine Kosten pro Index.
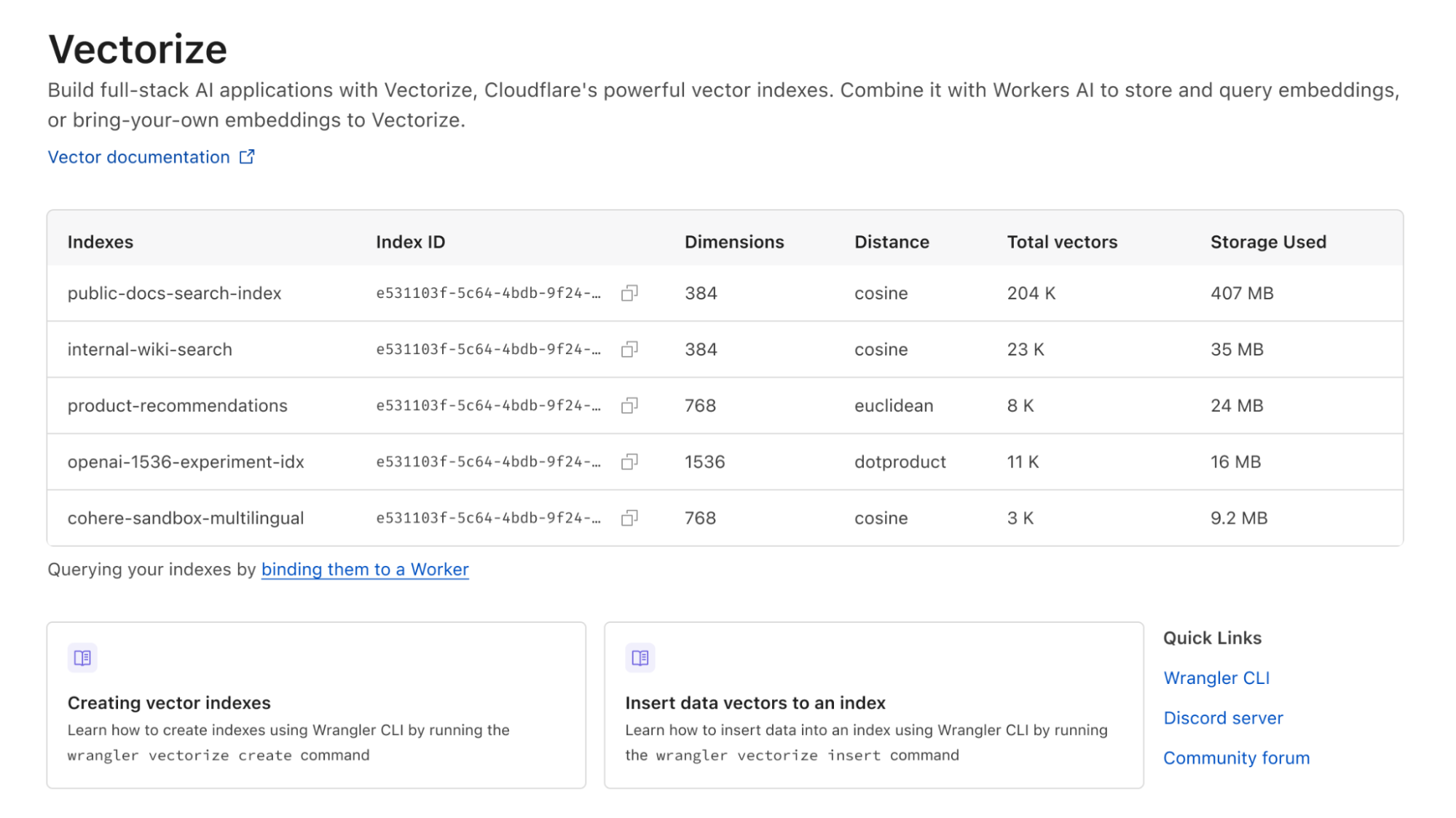
Ein Beispiel: Wenn Sie 10.000 Workers AI-Vektoren (mit jeweils 384 Dimensionen) laden und jeden Tag 5.000 Abfragen gegen Ihren Index durchführen, ergibt das insgesamt 49 Millionen abgefragte Vektordimensionen und passt immer noch in den Rahmen des kostenpflichtigen Workers-Tarifs (5 USD/Monat). Noch besser: Wir löschen Ihre Indizes nicht aufgrund von Inaktivität.
Beachten Sie, dass diese Preise zwar nicht endgültig sind, wir erwarten für die Zukunft aber nur geringfügige Änderungen. Wir wollen das Überraschungsmoment vermeiden: Es gibt nichts Schlimmeres, als mit der Entwicklung einer Plattform zu beginnen und festzustellen, dass die Preise unhaltbar sind, nachdem man Zeit in das Schreiben von Code, Tests und das Erlernen der Feinheiten einer Technologie investiert hat.
Vectorize!
Jeder Workers-Entwickler mit einem kostenpflichtigen Tarif kann Vectorize sofort nutzen: die Open Beta ist jetzt verfügbar, und Sie können einen Blick auf unsere Entwicklerdokumentation werfen, um loszulegen.
Auch für uns bei Cloudflare ist dies erst der Anfang der Entwicklungen im Bereich der Vektorendatenbanken. In den nächsten Wochen und Monaten wollen wir eine neue Abfrage-Engine auf den Markt bringen, die die Abfrage-Performance weiter verbessern, noch größere Indizes unterstützen, Filterfunktionen für Sub-Indizes, höhere Metadaten-Limits und Analysen pro Index einführen soll.
Sie benötigen Inspirationen für Ihre eigene Entwicklertätigkeit? Sehen Sie sich das Tutorial zur semantischen Suchean, das Workers AI und Vectorize für die Dokumentensuche kombiniert und vollständig auf Cloudflare läuft. Oder ein Beispiel für die Kombination von OpenAI und Vectorize, um einem LLM mehr Kontext zu geben und die Genauigkeit ihrer Antworten drastisch zu verbessern.
Und wenn Sie unseren Produkt- und Entwicklungsteams Fragen zur Verwendung von Vectorize stellen oder einfach nur Ideen mit anderen Entwicklern austauschen möchten, die auf Workers AI aufbauen, treten Sie den Kanälen #vectorize und #workers-ai auf unserem https://discord.cloudflare.com/Discord-Kanal für Entwickler bei.