
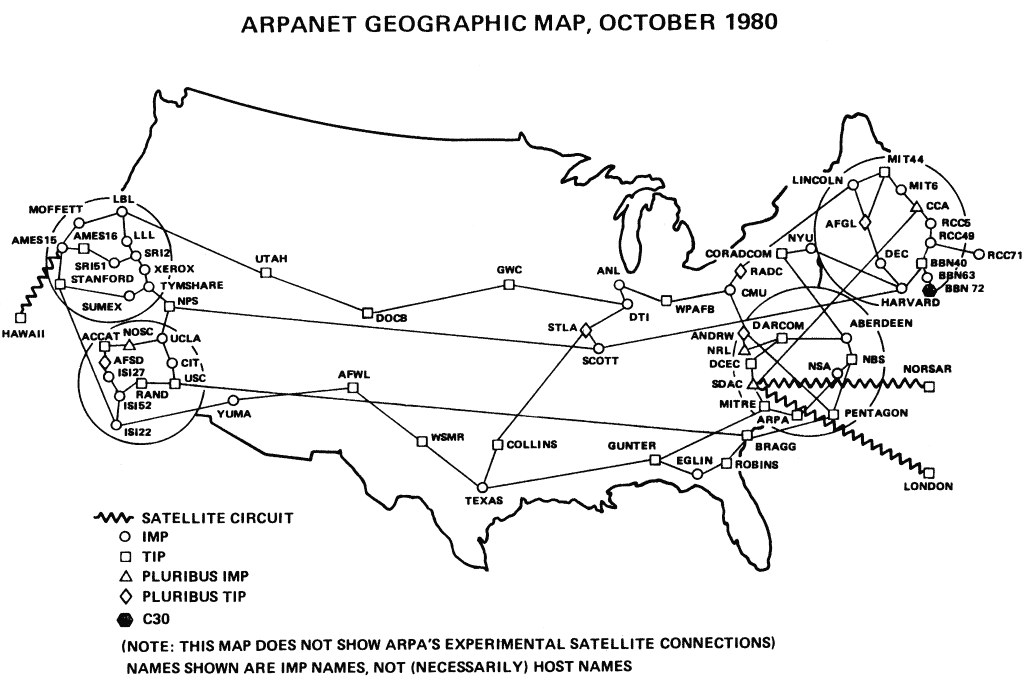
Am 11. Januar 1982 kamen zweiundzwanzig Computerwissenschaftler zusammen, um ein Problem mit der „Computerpost“ (heute E-Mail genannt) zu besprechen. Unter den Teilnehmern waren der spätere Gründer von Sun Microsystems, der Entwickler von Zork, der Erfinder des NTP und der Mann, der die Regierung überredete, Unix zu finanzieren. Das Problem ließ sich leicht auf den Punkt bringen: Es gab 455 Hosts im ARPANET und die Situation geriet allmählich außer Kontrolle.

Dass es gerade zu diesem Zeitpunkt akut wurde, hing mit der anstehenden Umstellung des ARPANET vom ursprünglich verwendeten NCP-Protokoll auf das TCP/IP-Protokoll zusammen – auf dasjenige Protokoll also, auf dem auch unser heutiges Internet basiert. Diese Umstellung würde dazu führen, dass plötzlich eine Vielzahl von Netzwerken miteinander in Verbindung stehen (also gewissermaßen ein „Inter-Netz“ entsteht). Und dafür brauchte man ein stärker „hierarchisch“ aufgebautes Domainsystem, in dem das ARPANET und die anderen Netzwerke ihre jeweils eigenen Domains auflösen konnten.
Andere Netzwerke dieser Zeit trugen tolle Namen wie „COMSAT“, „CHAOSNET“, „UCLNET“ oder „INTELPOSTNET“. Sie wurden von Universitäts- und Firmengruppen in den ganzen USA betrieben, die miteinander kommunizieren wollten und es sich leisten konnten, sowohl die 56k-Leitungen von der Telefongesellschaft anzumieten als auch die erforderlichen PDP-11-Computer zu erwerben, die für das Routing zuständig waren.

Ursprünglich war das ARPANET so gestaltet, dass in einem zentralen Network Information Center (NIC) eine Datei mit einer Liste aller Hosts des Netzwerks geführt wurde. Diese Datei hieß HOSTS.TXT und ähnelte der Datei /etc/hosts auf einem Linux- oder OS-X-System von heute. Bei jeder Änderung des Netzwerks musste das NIC die Datei per FTP (einem 1971 erfundenen Protokoll) an jeden Host des Netzwerks übertragen, was die Infrastruktur spürbar belastete.
Eine einzige Datei, die sämtliche Hosts des Internets enthält, wäre natürlich nicht beliebig skalierbar gewesen. Aber zu diesem Zeitpunkt hatte E-Mail oberste Priorität, weil es in Bezug auf Adressierung die vorrangige Herausforderung darstellte. Letzten Endes wurde beschlossen, eine hierarchische Lösung aufzubauen, bei der man über ein externes System die benötigte Domain oder Gruppe von Domains abfragen konnte– oder in den Worten der Beteiligten: „Man beschloss in dieser Sache, die aktuelle Mailboxkennung, die dem Schema ‚user@host‘ folgte, auf ‚[email protected]‘ zu erweitern. Dabei konnte ‚domain‘ auch eine Hierarchie von Domains sein.“ Das war die Geburtsstunde der Domain.
Man sollte sich aber auf keinen Fall der Illusion hingeben, diese Entscheidungen seien in weiser Voraussicht getroffen worden, weil man um die zukünftige Bedeutung des Domainnamens wusste. Vielmehr ging es bei der gewählten Lösung vor allem darum, dass sie „den vorhandenen Systemen die wenigsten Probleme bereitete“. Ein anderer Vorschlag für das Format von E-Mail-Adressen war beispielsweise <user>.<host>@<domain> gewesen. Aber das musste verworfen werden, weil in den E-Mail-Nutzernamen damals bereits Punkte vorkamen. Sonst würden Sie mich heute vielleicht über die E-Mail-Adresse ‚zack.cloudflare@com‘ erreichen.
Was ist Cloudflare?
Mit Cloudflare können Sie Caching, Lastverteilung, Rate Limiting und sogar Netzwerk-Firewalls und Codeausführung innerhalb von Millisekunden von praktisch jedem Internetbenutzer aus Ihrer Infrastruktur an unsere Points of Presence verschieben.
Fallstudie lesen Vertrieb kontaktierenUUCP und die Bang-Adressierung
Man sagt, dass die Hauptfunktion eines Betriebssystems darin besteht, für ein und dasselbe Objekt mehrere verschiedene Namen zu definieren, damit sich das System dann damit beschäftigen kann, die Beziehungen zwischen all den verschiedenen Namen nachzuverfolgen. Bei Netzwerkprotokollen scheint es ganz ähnlich zu sein.
– David D. Clark, 1982
Ein weiterer Vorschlag, der sich nicht durchsetzen konnte, bestand darin, das Ausrufezeichen (!) als Trennzeichen für Domainkomponenten zu verwenden. Der Pfad zum Host ISIA im ARPANET lautete demnach !ARPA!ISIA. Bei dieser Lösung konnte man auch Platzhalterzeichen für die Abfrage von Hosts nutzen: !ARPA!* lieferte jeden Host im ARPANET.
Diese Adressierungsmethode war keine wilde Abweichung vom Standard, sondern der Versuch, ihn zu erhalten. Das Verfahren, Hosts durch Ausrufezeichen zu trennen, geht auf ein Datenübertragungstool namens UUCP zurück, das 1976 entstanden war. Wenn Sie dies auf einem Computer mit OS X oder Linux lesen, ist uucp dort wahrscheinlich immer noch installiert und über das Terminal aufrufbar.
Das 1969 eingeführte ARPANET entwickelte sich schnell zu einem leistungsfähigen Kommunikationswerkzeug … allerdings nur für eine Handvoll Universitäten und Behörden, die Zugang dazu hatten. Das Internet nach heutigem Muster wurde erst 1991 außerhalb von Forschungseinrichtungen öffentlich zugänglich, also über zwanzig Jahre später. Aber Computerbenutzer kommunizierten natürlich trotzdem schon miteinander.

In der Zeit vor dem Internet bestand die gängige Kommunikationsmethode zwischen Computern in einer direkten DFÜ-Verbindung von einem Rechner zum anderen. Wenn Sie mir beispielsweise eine Datei senden wollten, musste Ihr Modem mein Modem anrufen, dann konnten wir die Datei übertragen. UUCP entstand, um aus dieser Methode eine Art Netzwerk zu machen.
Bei diesem System gibt es auf jedem Computer eine Datei mit einer Liste der ihm bekannten Hosts, zusammen mit der jeweiligen Telefonnummer sowie dem Benutzernamen und dem Kennwort für diesen Host. Damit erstellt man einen „Pfad“ vom eigenen Rechner zum Ziel. Jeder Host entlang dieses Pfads muss „wissen“, wie er die Verbindung zum nächsten herstellen kann:
sw-hosts!digital-lobby!zack

Mit dieser Adresse konnte man mir nicht nur Dateien senden oder sich direkt mit meinem Computer verbinden – sie war gleichzeitig auch meine E-Mail-Adresse. Als es noch keine „Mailserver“ gab, konnten Sie mir keine E-Mail senden, wenn mein Computer ausgeschaltet war.
Während das ARPANET nur von den Top-Universitäten genutzt werden konnte, entstand mit UUCP ein improvisiertes Internet für die Allgemeinheit. Es bildete die Grundlage für das Usenet und das BBS-System.
DNS
1983 wurde schließlich das DNS-System vorgeschlagen, das wir auch heute noch nutzen. Wenn Sie eine DNS-Abfrage durchführen, zum Beispiel mit dem Tool dig, wird Ihnen heute wahrscheinlich ungefähr Folgendes angezeigt:
;; ANSWER SECTION:
google.com. 299 IN A 172.217.4.206
Damit wird uns mitgeteilt, dass google.com unter 172.217.4.206 erreichbar ist. Wie Sie vielleicht wissen, besagt das A, dass es sich um einen „Adresseintrag“ handelt, mit dem eine Domain einer IPv4-Adresse zugeordnet wird. Die Zahl 299 ist die „Lebenszeit“, die uns informiert, wie lange (in Sekunden) dieser Wert noch gültig ist, bis man ihn erneut abfragen sollte. Aber was bedeutet IN?
IN steht für „Internet“. Wie so vieles geht auch dieses Feld auf eine Zeit zurück, in der es mehrere Computernetzwerke gab, die zwar einerseits miteinander konkurrierten, andererseits aber auch kompatibel sein mussten. Andere mögliche Werte waren CH für CHAOSNET oder HS für Hesiod, den Namensdienst des Athena-Systems. CHAOSNET gibt es schon lange nicht mehr, aber Athena wird in einer stark weiterentwickelten Version noch heute von Studenten am MIT genutzt. Auf der IANA-Website finden Sie noch die Liste der DNS-Klassen, aber es wird Sie nicht überraschen, dass heute nur noch einer der möglichen Werte gebräuchlich ist.
Top-Level-Domains
Es ist äußerst unwahrscheinlich, dass noch weitere TLDs entstehen.
– John Postel, 1994
Als feststand, dass Domainnamen hierarchisch angeordnet werden sollten, musste man auch festlegen, wie der Ausgangspunkt dieser Hierarchie aussehen sollte. Diese Wurzel wird traditionell mit einem einzigen Punkt („.“) angegeben. Es ist tatsächlich semantisch korrekt, alle Ihre Domainnamen mit einem Punkt abzuschließen, und das funktioniert garantiert auch in Ihrem Webbrowser: google.com.
Die erste TLD war .arpa. Mit ihr konnten die Nutzer in der Übergangszeit ihre alten, traditionellen ARPANET-Hostnamen adressieren. Wenn mein Rechner beispielsweise vorher als hfnet registriert war, dann lautete meine neue Adresse hfnet.arpa. Dies galt allerdings nur vorübergehend, während die Serveradministratoren eine sehr wichtige Entscheidung treffen mussten: Welche der fünf möglichen TLDs sollten sie nehmen? „.com“, „.gov“, „.org“, „.edu“ oder „.mil“?
Wenn wir das DNS als hierarchisch bezeichnen, dann ist damit gemeint, dass es eine Reihe von DNS-Rootservern gibt, die dafür zuständig sind, beispielsweise aus .com die .com-Nameserver zu machen, die wiederum mitteilen, wie man zu google.com gelangt. Die DNS-Rootzone des Internets besteht aus dreizehn Serverclustern – mehr sind es nicht, weil in ein einzelnes UDP-Paket nicht mehr hineinpassen: Früher wurde das DNS auf der Grundlage von UDP-Paketen betrieben, sodass die Antwort auf eine Anfrage nie größer sein kann als 512 Bytes.
; This file holds the information on root name servers needed to
; initialize cache of Internet domain name servers
; (e.g. reference this file in the "cache . "
; configuration file of BIND domain name servers).
;
; This file is made available by InterNIC
; under anonymous FTP as
; file /domain/named.cache
; on server FTP.INTERNIC.NET
; -OR- RS.INTERNIC.NET
;
; last update: March 23, 2016
; related version of root zone: 2016032301
;
; formerly NS.INTERNIC.NET
;
. 3600000 NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30
;
; FORMERLY NS1.ISI.EDU
;
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201
B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b
;
; FORMERLY C.PSI.NET
;
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
C.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2::c
;
; FORMERLY TERP.UMD.EDU
;
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 199.7.91.13
D.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2d::d
;
; FORMERLY NS.NASA.GOV
;
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
;
; FORMERLY NS.ISC.ORG
;
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
F.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2f::f
;
; FORMERLY NS.NIC.DDN.MIL
;
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
;
; FORMERLY AOS.ARL.ARMY.MIL
;
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 198.97.190.53
H.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:1::53
;
; FORMERLY NIC.NORDU.NET
;
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
I.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fe::53
;
; OPERATED BY VERISIGN, INC.
;
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
J.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:c27::2:30
;
; OPERATED BY RIPE NCC
;
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
K.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fd::1
;
; OPERATED BY ICANN
;
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 199.7.83.42
L.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:9f::42
;
; OPERATED BY WIDE
;
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
M.ROOT-SERVERS.NET. 3600000 AAAA 2001:dc3::35
; End of file
DNS-Rootserver sind in Tresoren untergebracht, die in vergitterten Räumen stehen. Auf jedem Tresor steht eine Uhr, damit die Aufnahme der Überwachungskamera nicht unbemerkt durch einen Loop ersetzt werden kann. Nicht zuletzt angesichts der langsamen Implementierung von DNSSEC könnte man mit einem Angriff auf einen dieser Server den gesamten Internet-Traffic eines Teils der Internetnutzer umleiten. Das wäre sicherlich der Stoff für einen der fantastischsten Thriller, die je gedreht wurden.
Es ist keine Überraschung, dass die Nameserver für Top-Level-TLDs nur selten geändert werden. 98 % aller Anfragen an DNS-Rootserver sind fehlerhaft, meist weil die Clients unbrauchbar sind und ihre Ergebnisse nicht richtig cachen. Dieses Problem hat sich so verschärft, dass mehrere Rootbetreiber zusätzliche Server bereitstellen mussten, die nur die Aufgabe haben, jeden abzuweisen, der eine inverse Anfrage für seine eigene lokale IP-Adresse stellt.
Die TLD-Nameserver werden von verschiedenen Unternehmen und Regierungen in aller Welt verwaltet (Verisign ist für die Verwaltung von .com zuständig). Wenn Sie eine .com-Domain erwerben, erhält die ICANN etwa 0,18 $, Verisign bekommt 7,85 $.
Punycode
Es passiert nur selten, dass ein fertiges und veröffentlichtes Produkt noch den albernen Namen trägt, den sich Entwickler in der Anfangszeit des Projekts ausgedacht hatten. Wir Entwickler mögen einer Unternehmensdatenbank vielleicht den Namen „Delaware“ geben (da in dem US-Bundesstaat alle Unternehmen registriert sind), aber Sie können sicher sein, dass das Produkt dann eher mit einem Namen wie „CompanyMetadataDatastore“ auf den Markt kommt. Nur manchmal, wenn die Sterne richtig stehen und der Boss gerade im Urlaub ist, rutscht so ein Name aus der Entwicklungsphase durch.
Das System, mit dem wir Unicode in Domainnamen umwandeln, heißt Punycode. Dabei geht es um ganz einfaches Problem: Wie schreibt man „比薩.com“, wenn das ganze System des Internets auf dem ASCII-Zeichensatz beruht, dessen exotischstes Zeichen die Tilde ist?
Man kann Domains nicht so einfach auf Unicode umstellen. In den Originaldokumenten mit den Spezifikationen für Domains ist festgelegt, dass diese in ASCII kodiert werden müssen. Die gesamte Internet-Hardware der letzten vierzig Jahre geht von dieser Annahme aus, einschließlich der Cisco- und Juniper-Router, die Ihnen die Seite liefern, die Sie gerade lesen.
Das Web selbst war hingegen noch nie reines ASCII. Ursprünglich war es auf ISO 8859-1 ausgelegt. In diesem Zeichensatz sind alle ASCII-Zeichen enthalten, dazu aber weitere Sonderzeichen wie „¼“ und diakritische Zeichen wie „ä“ oder „á“. Allerdings enthält er keine nicht-lateinischen Zeichen.
Diese Einschränkung für HTML wurde 2007 endgültig beseitigt und im gleichen Jahr wurde Unicode zum beliebtesten Zeichensatz im Web. Für Domains konnte jedoch weiterhin nur ASCII verwendet werden.
Wie Sie sich vorstellen können, war Punycode nicht der erste Lösungsvorschlag für dieses Problem. Wahrscheinlich haben Sie schon von UTF-8 gehört, einer gängigen Möglichkeit, Unicode als Bytes zu kodieren (die 8 steht für die acht Bits eines Bytes). Im Jahr 2000 stellten mehrere Mitglieder der Internet Engineering Task Force UTF-5 vor. Die Idee dabei war, Unicode als Fünf-Bit-Abschnitte zu kodieren. Jede Fünf-Bit-Kombination konnte dann einem in Domainnamen zulässigen Zeichen zugeordnet werden (A–V und 0–9). Wenn ich beispielsweise eine Website zum Japanisch lernen anbiete, würde nach diesem Schema aus dem ursprünglichen Domainnamen 日本語.com die kryptische Version M5E5M72COA9E.com.
Diese Kodierungsmethode hat allerdings mehrere Nachteile. Erstens werden die Zeichen A–V und 0–9 in der kodierten Ausgabe verwendet. Wenn also eines dieser Zeichen auch im Domainnamen vorkommt, muss es genauso konvertiert werden wie alle anderen. Dadurch wurden einige Domainnamen sehr lang, und das ist ein echtes Problem, denn jeder Abschnitt eines Domainnamens kann maximal 63 Zeichen umfassen. Eine Domain in birmanischer Schrift ist damit effektiv auf 15 Zeichen begrenzt. Doch immerhin beinhaltete dieser Vorschlag auch die durchaus interessante Anregung, UTF-5 zu nutzen, um Unicode auch per Morsecode und Telegramm zu übertragen.
Außerdem stand die Frage im Raum, wie man dem Client mitteilen kann, dass eine Domain kodiert ist, sodass er sie in den entsprechenden Unicode-Zeichen darstellen kann, anstatt in der Adressleiste „M5E5M72COA9E.com“ anzuzeigen. Dafür gab es mehrere Vorschläge, zum Beispiel die Idee, dies über ein unbenutztes Bit in der DNS-Antwort zu tun. Doch dabei handelte es sich um das „letzte unbenutzte Bit im Header“ und die DNS-Verantwortlichen waren „äußerst abgeneigt, es herauszurücken“.
Ein anderer Vorschlag bestand darin, jedem mit dieser Methode umgewandelten Domainnamen ra-- voranzustellen, denn wie es der Zufall wollte, gab es zu diesem Zeitpunkt (Mitte April 2000) noch keine Domains, die mit diesen Zeichen begannen. Aber wie ich das Internet kenne, hat nach der Veröffentlichung des Vorschlags gleich irgendjemand eine Domain mit ra-- cregistrieren lassen, einfach nur aus Bosheit.
Die endgültige Entscheidung fiel 2003: Ein Format namens Punycode wurde eingeführt, das auf einer Art Delta-Komprimierung basierte und die umgewandelten Domainnamen dadurch deutlich verkürzen konnte. Delta-Komprimierung ist hierfür besonders sinnvoll, weil es sehr wahrscheinlich ist, dass alle Zeichen in einem Domainnamen aus dem gleichen Unicode-Block stammen. Zwei Farsi-Zeichen stehen beispielsweise in Unicode viel näher beieinander als ein Farsi- und ein Hindi-Zeichen. Um zu zeigen, wie das funktioniert, sehen wir uns die folgende (unsinnige) Zeichenfolge an:
يذؽ
In einem nicht komprimierten Format müsste sie als drei Zeichen gespeichert werden: [1610, 1584, 1597] (auf der Grundlage der Unicode-Codepunkte). Um diese Werte zu komprimieren, sortieren wir sie zunächst numerisch (merken uns dabei aber die ursprüngliche Position der Zeichen): [1584, 1597, 1610]. Dann können wir den kleinsten Wert ( 1584 ) und die Deltas zwischen diesem Wert und dem nächsten Zeichen ( 13 ) sowie zwischen dem zweiten und dem dritten Zeichen ( 23 ) speichern. Das ergibt deutlich weniger Daten, die übertragen oder gespeichert werden müssen.
Punycode wandelt diese Ganzzahlwerte dann (sehr) effizient in Zeichen um, die in Domainnamen zulässig sind, und fügt am Anfang xn-- ein, was die Zeichenfolge als konvertierte Domain kennzeichnet. Wie Sie sehen werden, landen dabei alle Unicode-Zeichen am Ende des Domainnamens. Neben ihrem Wert wird auch die jeweilige Position kodiert, an der sie in den ASCII-Teil der Domain eingefügt werden müssen. Aus der Website 熱狗sales.com wird damit zum Beispiel xn--sales-r65lm0e.com. Jedes Mal, wenn Sie einen Domainnamen in Unicode in die Adressleiste Ihres Browsers eingeben, wird er auf diese Weise umgewandelt.
Diese Transformation könnte transparent vonstatten gehen, das führt aber zu einem größeren Sicherheitsproblem. Eine Menge Unicode-Zeichen unterscheiden sich rein optisch nicht von vorhandenen ASCII-Zeichen. So kann man beispielsweise keinen wirklichen Unterschied zwischen dem kyrillischen Kleinbuchstaben a („а“) und dem lateinischen Kleinbuchstaben a („a“) erkennen. Wenn ich nun аmazon.com mit einem kyrillischen „а“ registriere (xn--mazon-3ve.com) und es schaffe, Sie dorthin zu lotsen, können Sie nur schwer erkennen, dass Sie auf der falschen Website sind. Deshalb erscheint, wenn Sie ??.ws aufrufen, in der Adresszeile Ihres Browsers nur die etwas langweilige Fassung xn--vi8hiv.ws.
Protokoll
Der erste Teil der URL ist das Protokoll, mit dem auf sie zugegriffen werden soll. Am gängigsten ist http, das einfache Protokoll zur Dokumentenübertragung, das Tim Berners-Lee speziell für das Web entwickelte. Allerdings standen auch andere Lösungen zur Debatte. Manche Leute waren der Ansicht, wir sollten einfach Gopher nehmen. Dieses Protokoll ist nicht universell einsetzbar, sondern speziell für den Versand strukturierter Daten ausgelegt, ähnlich wie bei der Struktur eines Dateibaums.
Wenn man beispielsweise den Endpunkt /Cars anfordert, könnte es Folgendes zurückliefern:
1Chevy Camaro /Archives/cars/cc gopher.cars.com 70
iThe Camero is a classic fake (NULL) 0
iAmerican Muscle car fake (NULL) 0
1Ferrari 451 /Factbook/ferrari/451 gopher.ferrari.net 70
which identifies two cars, along with some metadata about them and where you can connect to for more information. The understanding was your client would parse this information into a usable form which linked the entries with the destination pages.
Das erste gängige Protokoll war das 1971 entwickelte FTP, mit dem man Dateien auf Remote-Computern auflisten und herunterladen konnte. Gopher war eine logische Erweiterung dieser Lösung: Das Protokoll lieferte eine ähnliche Liste, fügte aber Funktionen hinzu, die auch das Lesen der Metadaten zu den Einträgen erlaubten. Dadurch konnte es für weitergehende Zwecke wie einen Newsfeed oder eine einfache Datenbank verwendet werden. Es besaß jedoch nicht die Flexibilität und Einfachheit, die HTTP und HTML auszeichnen.
HTTP ist ein sehr simples Protokoll, vor allem im Vergleich zu Alternativen wie FTP oder auch dem Protokoll HTTP/3, das heute an Beliebtheit gewinnt. Zunächst einmal ist HTTP rein textbasiert und nicht aus speziellen binären Geheimformeln zusammengebaut (was seine Effizienz deutlich erhöht hätte). Tim Berners-Lee nahm zu Recht an, dass es Generationen von Programmierern mit einem textbasierten Format leichter fallen würde, HTTP-Anwendungen zu entwickeln und zu debuggen.
HTTP trifft außerdem kaum Annahmen darüber, welche Art von Inhalten übertragen werden soll. Obwohl es ausdrücklich für HTML erfunden wurde, können Sie (über die MIME Content-Type, die damals einen ganz neuen Ansatz darstellte) alle möglichen Inhaltsarten angeben. Das Protokoll selbst ist recht einfach gehalten:
Die folgende Anforderung:
GET /index.html HTTP/1.1
Host: www.example.com
könnte diese Antwort liefern:
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
Insgesamt kann man es sich so vorstellen: Grundlage des Netzwerksystems des Internets ist IP, das Internetprotokoll. Es ist dafür zuständig, ein kleines Datenpaket (ca. 1500 Byte) von einem Computer zu einem anderen zu übertragen. Auf der nächsthöheren Ebene befindet sich TCP, das dafür zuständig ist, größere Datenblöcke wie ganze Dokumente und Dateien zuverlässig in Form vieler IP-Pakete zu versenden. Darüber wird ein Protokoll wie HTTP oder FTP implementiert, das festlegt, mit welchem Format die über TCP (oder UDP usw.) gesendeten Daten verständlich und aussagekräftig werden.
Anders ausgedrückt, TCP/IP sendet einen Haufen Bytes an einen anderen Computer. Das Protokoll sagt dann aus, was diese Bytes sein sollen und was sie bedeuten.
Wenn Sie wollen, können Sie auch ein eigenes Protokoll entwickeln und die Bytes in Ihren TCP-Nachrichten nach Belieben zusammenstellen. Sie müssen nur dafür sorgen, dass jeder, mit dem Sie sich austauschen, die gleiche Sprache spricht. Deshalb ist es üblich, diese Protokolle zu standardisieren.
Natürlich gibt es noch viele andere, weniger bedeutende Protokolle, mit denen man herumspielen kann. So gibt es zum Beispiel ein Protokoll für das Zitat des Tages (Port 17) und eines für zufällige Zeichen (Port 19). Das wirkt heute vielleicht albern, aber es zeigt auch, wie wichtig es war, ein Universalformat für die Dokumentenübertragung wie HTTP zu entwickeln.
Port
Die zeitliche Einordnung von Gopher und HTTP lässt sich an ihren Standard-Portnummern ablesen. Gopher ist Port 70, HTTP Port 80. Der HTTP-Port wurde auf Anforderung von Tim Berners-Lee (wahrscheinlich von Jon Postel bei der IANA) irgendwann zwischen 1990 und 1992 zugewiesen.
Dieses Konzept, „Portnummern“ zu registrieren, ist noch älter als das Internet. Im ursprünglichen NCP-Protokoll für das ARPANET wurden Remote-Adressen durch 40 Bits identifiziert. Die ersten 32 Bit identifizierten den Remote-Host, ganz ähnlich wie heute eine IP-Adresse. Die letzten acht wurden als AEN bezeichnet (das stand für „Another Eight-bit Number“, also einfach „Noch eine Acht-Bit-Zahl“). Der Remote-Rechner benutzte diese Bits genauso, wie wir eine Portnummer benutzen, also zur Unterscheidung von Nachrichten für verschiedene Prozesse. Anders gesagt, mit der Adresse wird angegeben, an welchen Rechner die Nachricht gerichtet ist, und die AEN (oder Portnummer) sagt dem Remote-Rechner dann, welche Anwendung die Nachricht empfangen soll.
Das führte umgehend zu der Anforderung an die Nutzer, diese „Socket-Nummern“ registrieren, damit weniger Konflikte drohen. Als die Portnummern durch TCP/IP auf 16 Bits erweitert wurden, ging dieser Registrierungsprozess weiter.
Bei Protokollen gibt es zwar einen Standard-Port, aber es ist sinnvoll, auch die manuelle Anpassung von Ports zuzulassen, damit Entwicklung lokal möglich ist und mehrere Dienste auf dem gleichen Rechner gehostet werden können. Diese Überlegungen führten auch zu dem Vorschlag, Websites mit dem Präfix www. zu versehen. Zu diesem Zeitpunkt war es zwar unwahrscheinlich, dass irgendjemand den Zugang zur Root einer Domain erhielt, nur um eine „experimentelle“ Website zu hosten. Aber wenn man den Nutzern den Hostnamen des jeweiligen Rechners ( dx3.cern.ch) mitteilt, bekommt man Probleme, wenn dieser Rechner ausgetauscht werden muss. Mit einer gemeinsamen Subdomain ( www.cern.ch ) kann man je nach Bedarf das Ziel der Weiterleitung ändern.
Das Bit dazwischen
Wie Sie sicher wissen, fügt man gemäß der URL-Syntax zwei Schrägstriche ( // ) zwischen der Protokollangabe und der restlichen URL ein:
http://cloudflare.com
Dieser doppelte Schrägstrich wurde von einer der ersten vernetzten Workstations übernommen, dem Computersystem Apollo. Das Apollo-Team hatte ein ganz ähnliches Problem wie Tim Berners-Lee: Es brauchte eine Möglichkeit, einen Pfad von dem Rechner zu trennen, auf dem sich dieser Pfad befindet. Als Lösung entwickelten Sie ein spezielles Pfadformat:
//computername/file/path/as/usual
Und Tim Berners-Lee übernahm dieses Schema. Tatsächlich bereut er diese Entscheidung inzwischen; es wäre ihm lieber, die Domain (in diesem Fall beispiel.com) käme im Pfad zuerst:
http:com/example/foo/bar/baz
URLs waren nie als das gedacht, was sie inzwischen geworden sind: eine schwer durchschaubare Methode, um als Nutzer eine Website zu identifizieren. Leider ist es nie gelungen, URNs zum Standard zu machen. Das hätte uns ein nützlicheres Namenssystem verschafft. Wenn man der Meinung ist, dass das derzeitige URL-System ausreicht, kann man auch die DOS-Befehlszeile toll finden und die Meinung vertreten, dass die Mehrheit der Nutzer eben einfach die Befehlszeilensyntax erlernen sollten. Wir haben Fenstersysteme entwickelt, damit Computer benutzerfreundlicher werden und breitere Akzeptanz finden. In gleicher Weise sollten wir darüber nachdenken, wie ein besserer Ansatz zum Auffinden bestimmter Websites aussehen könnte.
– Dale Dougherty 1996
Unter dem „Internet“ kann man verschiedene Dinge verstehen. Zum Beispiel kann man es als ein System von Computern begreifen, die über ein Computernetzwerk verbunden sind. Diese Version des Internets entstand 1969 mit dem ARPANET. E-Mails, Dateien und Chats wurden schon über dieses Netzwerk ausgetauscht, bevor es HTTP, HTML oder „Webbrowser“ gab.
1992 kamen durch Tim Berners-Lee drei Dinge hinzu, die das ausmachen, was wir als das Internet betrachten: HTTP als Protokoll, HTML und die URL. Sein Ziel war es, „Hypertext“ zum Leben zu erwecken. In seiner einfachsten Form ist dies die Möglichkeit, miteinander verknüpfte Dokumente zu erzeugen. Das wurde damals eher als Wundermittel einer fernen Zukunft betrachtet, zusammen mit Hypermedia und allen möglichen anderen Begriffen mit der Vorsilbe „Hyper“.
Die entscheidende Anforderung an Hypertext war die Möglichkeit, Dokumente zu verlinken. Zu Berners-Lees Zeiten wurden diese Dokumente allerdings in einer Vielzahl von Formaten gehostet und über Protokolle wie Gopher und FTP aufgerufen. Er brauchte eine einheitliche Methode, die es erlaubte, auf eine Datei zu verweisen, und dabei auch das Protokoll, den Host im Internet und den Ablageort auf diesem Host kodierte.
Seine Lösung beschrieb Berners-Lee bei der allerersten Vorstellung des World Wide Web im März 1992 als „Universal Document Identifier“ (universelle Dokumentenkennung, UDI). Für diese Kennung kamen viele verschiedene Formate in Frage:
protocol: aftp host: xxx.yyy.edu path: /pub/doc/README
PR=aftp; H=xx.yy.edu; PA=/pub/doc/README;
PR:aftp/xx.yy.edu/pub/doc/README
/aftp/xx.yy.edu/pub/doc/README
In seinem Dokument wird auch erklärt, warum Leerzeichen in URLs kodiert werden müssen (%20):
> The use of white space characters has been avoided in UDIs: spaces
> are not legal characters. This was done because of the frequent
> introduction of extraneous white space when lines are wrapped by
> systems such as mail, or sheer necessity of narrow column width, and
> because of the inter-conversion of various forms of white space
> which occurs during character code conversion and the transfer of
> text between applications.Man muss sich vor allem klarmachen, dass die URL im Grunde nur eine Abkürzung für die Kombination aus Schema, Domain, Port, Anmeldedaten und Pfad ist, die früher für jedes einzelne Kommunikationssystem im Kontext betrachtet werden mussten.
Die URL wurde erstmals 1994 in Form eines RFC veröffentlicht.
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
Mit dieser Lösung konnte man aus Hypertext heraus auf verschiedene Systeme verweisen. Da heute aber praktisch alle Inhalte über HTTP gehostet werden, braucht man sie im Grunde nicht mehr. Bereits 1996 wurde http:// und www. von den Browsern automatisch eingefügt (und wenn diese Bestandteile in Werbeanzeigen noch heute genannt werden, ist das wirklich albern).
Pfad
Es geht meiner Meinung nach nicht darum, ob die Leute lernen können, was eine URL bedeutet. Ich finde es moralisch einfach nur schauderhaft, Oma und Opa zu zwingen, sich mit Dingen auseinanderzusetzen, die eigentlich den Konventionen des UNIX-Dateisystems entstammen.
– Israel del Rio 1996
Der durch Schrägstriche getrennte Pfad einer URL sollte jedem vertraut sein, der schon mal einen Computer aus den letzten fünfzig Jahren benutzt hat. Das hierarchische Dateisystem selbst wurde vom System MULTICS eingeführt. Dessen Erfinder wiederum führt es auf ein 1952 stattgefundenes zweistündiges Gespräch mit Albert Einstein zurück.
Bei MULTICS wurde das Größer-als-Zeichen (>) zur Trennung der Bestandteile des Dateipfads benutzt. Beispiel:
>usr>bin>local>awk
Das war auch durchaus schlüssig, aber die Unix-Entwickler beschlossen leider, das Zeichen > als Symbol für die Weiterleitung zu nutzen. Als Trennzeichen bei Pfaden kam stattdessen der normale Schrägstrich ( /) zum Einsatz.
Snapchat beim höchsten Gericht
Falsch. Wir sind, das sehe ich jetzt ganz deutlich, *verschiedener Meinung*. Sie und ich.
...
Als Person behalte ich mir das Recht vor, unterschiedliche Kriterien für unterschiedliche Zwecke zu verwenden. Ich möchte in der Lage sein, generischen Werken UND bestimmten Übersetzungen UND bestimmten Versionen verschiedene Namen zu geben. Ich möchte eine vielfältigere Welt als die, die Sie vorschlagen. Ich möchte mich nicht von Ihrem zweistufigen System aus „Dokumenten“ und „Varianten“ einschränken lassen.
– Tim Berners-Lee 1993
Die Hälfte der URLs in den Stellungnahmen des Obersten Gerichtshofs der USA verlinken Seiten, die es nicht mehr gibt. 2011 lag die Wahrscheinlichkeit, dass eine beliebige URL in einer 2001 verfassten wissenschaftlichen Arbeit ungültig ist, bei über 50 %.
1993 war man fest überzeugt, dass die URL aussterben und durch den „URN“ ersetzt werden würde. Der „Uniform Resource Name“ (einheitlicher Name für Ressourcen) ist ein permanenter Verweis auf einen bestimmten Inhalt, der im Gegensatz zu einer URL niemals angepasst oder ungültig wird. Tim Berners-Lee führte schon 1991 aus, dass hier „dringender Bedarf“ besteht.
Die einfachste Möglichkeit, einen URN zu erzeugen, wäre ein kryptografischer Hashwert des Seiteninhalts, zum Beispiel: urn:791f0de3cfffc6ec7a0aacda2b147839. Diese Methode erfüllt jedoch nicht die Kriterien der Web-Community, denn man konnte nicht so recht klären, wer dafür zuständig sein sollte, diesen Hashwert in den echten Inhalt umzuwandeln. Außerdem werden Formatänderungen dabei nicht berücksichtigt: Dateien treten oft in verschiedenen Formaten auf (zum Beispiel komprimiert und unkomprimiert), haben aber den gleichen Inhalt.
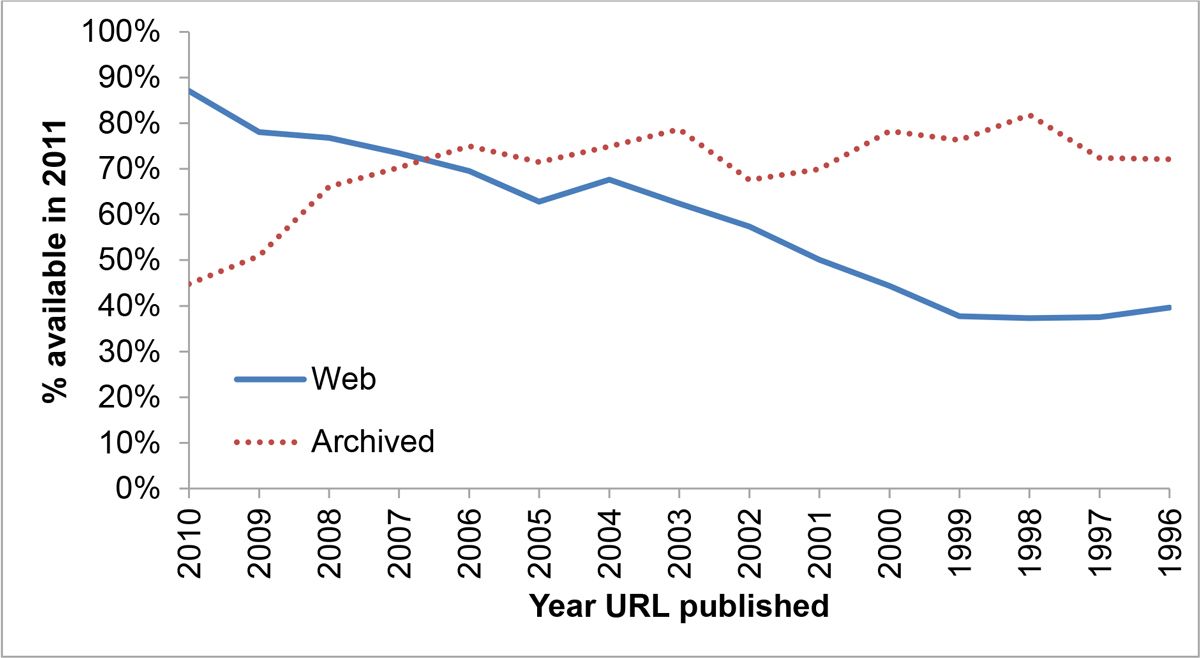
1996 schlug Keith Shafer gemeinsam mit einigen anderen eine Lösung für das Problem ungültiger URLs vor. Der Link zu dieser Lösung ist inzwischen ungültig. Roy Fielding veröffentlichte im Juli 1995 einen Implementierungsvorschlag. Dieser Link ist mittlerweile ebenfalls ungültig.
Über Google konnte ich diese Seiten aber aufstöbern. Durch Google wurden die Seitentitel effektiv zum URN von heute. Das URN-Format wurde 1997 endgültig fertiggestellt und seitdem praktisch nicht benutzt. Die Implementierung selbst ist allerdings durchaus interessant: Jeder URN setzt sich aus zwei Teilen zusammen, einer authority (zuständigen Stelle), die einen bestimmten URN-Typ auflösen kann, und der spezifischen ID dieses Dokuments, in dem jeweiligen Format, das die authority versteht. So wird durch urn:isbn:0131103628 beispielsweise ein Buch identifiziert. Dies dient als permanenter Link, der von Ihrem örtlichen isbn-Resolver (hoffentlich) in einen Satz URLs umgewandelt werden kann.
Angesichts der Leistungsfähigkeit von Suchmaschinen bestünde das beste URN-Format heute möglicherweise darin, dass Dateien einfach auf ihre bisherigen URLs verweisen. Wir könnten den Suchmaschinen erlauben, diese Informationen zu indexieren und uns entsprechend zu verlinken:
<!-- On http://zack.is/history -->
<link rel="past-url" href="http://zackbloom.com/history.html">
<link rel="past-url" href="http://zack.is/history.html">
Query-Parameter
Das Format „application/x-www-form-urlencoded“ ist in vielerlei Hinsicht eine abartige Monstrosität und das Ergebnis vieler Jahre der Willkürlichkeiten und Kompromisse bei der Implementierung. So kam eine Reihe von Anforderungen zusammen, die zwar für die Interoperabilität notwendig sind, aber keineswegs den Prinzipien benutzerfreundlicher Gestaltung entsprechen.
– URL-Spezifikation der WhatWG
Jeder Internetnutzer erlernt früher oder später den Umgang mit Query-Parametern. Sie kommen nach dem Pfadteil der URL und kodieren bestimmte Optionen, zum Beispiel ?name=zack&state=mi. Vielleicht kommt es Ihnen seltsam vor, dass in diesen Abfragen das Ampersand-Zeichen ( &) benutzt wird, denn mit dem gleichen Symbol werden in HTML Sonderzeichen kodiert. Und wenn Sie ein bisschen mit HTML zu tun hatten, mussten Sie wahrscheinlich auch schon das Ampersand-Zeichen in URLs kodieren, indem Sie etwa aus http://host/?x=1&y=2 entweder http://host/?x=1&y=2 oder http://host?x=1&y=2 machten (dieses spezielle Durcheinander gab es von Anfang an).
Vielleicht ist Ihnen auch schon aufgefallen, dass das Format bei Cookies ganz ähnlich ist, wenn auch nicht identisch: x=1;y=2. Dieses Format steht tatsächlich nicht im Konflikt mit der HTML-Zeichenkodierung. Das war auch dem W3C nicht entgangen, und es ermunterte die Entwickler schon 1995, bei Query-Parametern sowohl ; als auch & zu unterstützen.
Dieser URL-Abschnitt war ursprünglich ausschließlich für die Suche nach „Indexen“ vorgesehen. Das Web war anfangs für die Kooperation von Hochenergiephysikern entwickelt worden (und mit diesem Ziel wurde es auch finanziert). Trotzdem war sich Tim Berners-Lee sicherlich darüber im Klaren, dass er eigentlich ein universelles Kommunikationswerkzeug schuf. Jahrelang versäumte er es, Unterstützung für Tabellen einzubauen, die die Physiker wahrscheinlich gebraucht hätten.
Jedenfalls benötigten diese „Physiker“ eine Möglichkeit, Informationen zu kodieren und zu verlinken, sowie eine Lösung, um nach diesen Informationen suchen zu können. Dafür entwickelte Tim Berners-Lee das Tag <ISINDEX>. Wenn auf einer Seite <ISINDEX> vorkam, besagte dies für den Browser, dass dies eine durchsuchbare Seite war. Der Browser sollte dann ein Suchfeld einblenden und dem Nutzer ermöglichen, eine Abfrage an den Server zu senden.
Das Format dieser Abfrage bestand aus Schlüsselwörtern, die durch Pluszeichen (+) getrennt waren:
http://cernvm/FIND/?sgml+cms
In wilder Internet-Manier wurde dieses Tag schon bald für alles Mögliche zweckentfremdet, bis hin zu einer Eingabemöglichkeit für die Berechnung von Quadratwurzeln. Schnell wurde vorgeschlagen, diese vielleicht allzu spezifische Lösung unbedingt um das universelle Tag <input> zu ergänzen.
Im Rahmen dieses Vorschlags werden tatsächlich Pluszeichen verwendet, um die Bestandteile einer Abfrage zu trennen, die ansonsten schon sehr nach einer modernen GET-Abfrage aussieht:
http://somehost.somewhere/some/path?x=xxxx+y=yyyy+z=zzzz
Dies fand allerdings noch lange keine allgemeine Akzeptanz. Manche Leute waren der Ansicht, man müsse irgendwie ausdrücken können, dass die Inhalte auf der anderen Seite von Links durchsuchbar sein sollten:
<a HREF="wais://quake.think.com/INFO" INDEX=1>search</a>
Tim Berners-Lee war der Meinung, man sollte Abfragen streng typisiert definieren können:
<ISINDEX TYPE="iana:/www/classes/query/personalinfo">
Im Nachhinein bin ich doch recht froh, dass sich die allgemeinere Lösung durchgesetzt hat.
Die eigentliche Arbeit an <INPUT> begann im Januar 1993 auf der Grundlage eines älteren SGML-Typs. Man beschloss, dass <SELECT>-Eingaben eine separate, komplexere Struktur benötigten (was vielleicht keine so gute Idee war):
<select name=FIELDNAME type=CHOICETYPE [value=VALUE] [help=HELPUDI]>
<choice>item 1
<choice>item 2
<choice>item 3
</select>
Falls es Sie interessiert: Die Idee, <li> wiederzuverwenden, anstatt das neue Element <option> einzuführen, wurde durchaus in Betracht gezogen. Natürlich gab es auch andere Formularvorschläge. Einer davon sah auch Variablensubstitution vor, ähnlich wie Angular heutzutage:
<ENTRYBLANK TYPE=int LENGTH=length DEFAULT=default VAR=lval>Prompt</ENTRYBLANK>
<QUESTION TYPE=float DEFAULT=default VAR=lval>Prompt</QUESTION>
<CHOICE DEFAULT=default VAR=lval>
<ALTERNATIVE VAL=value1>Prompt1 ...
<ALTERNATIVE VAL=valuen>Promptn
</CHOICE>
In diesem Beispiel werden die Eingaben mit dem unter type festgelegten Typ abgeglichen und die VAR-Werte stehen auf der Seite für Zeichenkettensubstitution in URLs zur Verfügung, nach dem Schema:
http://cloudflare.com/apps/$appId
Bei weiteren Vorschlägen wurde das Zeichen @ anstelle von = als Trennzeichen zwischen Abfragekomponenten benutzt:
name@value+name@(value&value)
Marc Andreessen war derjenige, der unsere heutige Methode vorschlug. Die Grundlage dafür war etwas, das er schon in Mosaic implementiert hatte:
name=value&name=value&name=value
Nur zwei Monate später unterstützte Mosaic auch Formulare mit method=POST und das „moderne“ HTML-Formular war geboren.
Natürlich war es auch Marc Andreessen und sein Unternehmen Netscape, die das Cookie-Format (mit einem anderen Trennzeichen) entwickelten. Ihr Vorschlag war allerdings leider sehr kurzsichtig. Er führte zu dem Versuch, einen Header Set-Cookie2 einzuführen, und zu grundlegenden strukturellen Schwächen, mit denen wir uns bei Cloudflare bis heute herumschlagen.
Fragmente
Der Bestandteil der URL, der nach dem „#“ kommt, wird als Fragment bezeichnet. Fragmente gehörten schon seit der ersten Spezifikation zu URLs. Sie verlinken zu einer bestimmten Position auf der Seite, die gerade geladen wird. Wenn ich zum Beispiel den folgenden Anker auf meiner Website habe:
<a name="bio"></a>
dann kann ich diesen verlinken:
http://zack.is/#bio
Dieses Konzept blieb nicht auf Anker begrenzt, sondern wurde schrittweise auf alle Elemente erweitert und in das Attribut id anstelle von name verschoben:
<h1 id="bio">Bio</h1>
Tim Berners-Lee entschied sich für das Zeichen # aufgrund dessen Verwendung in US-Adressen (auch wenn er eigentlich Brite ist). In seinen eigenen Worten:
Bei Postanschriften wird zumindest in den USA das Nummernzeichen üblicherweise für die Wohnungs- oder Suite-Nummern eines Gebäudes verwendet. „12 Acacia Av #12“ bedeutet also „Das Gebäude Nummer 12 in der Acacia Av., und darin dann die Einheit mit der Nummer 12“. Es erschien deshalb naheliegend, dieses Zeichen für diese Aufgabe zu wählen. http://www.beispiel.com/abc#xyz bedeutet nunmehr: „Innerhalb der Ressource http://www.beispiel.com/abc die spezielle Ansicht mit der Bezeichnung xyz“.
Wie sich herausstellte, wurde beim von Douglas Englebart entwickelten ursprünglichen Hypertextsystem ebenfalls das Zeichen „#“ für diesen Zweck verwendet. Das könnte Zufall oder auch ein Fall versehentlichen „Ideenklaus“ sein.
Fragmente sind ausdrücklich nicht Bestandteil von HTTP-Anfragen, sie existieren also nur im Browser. Dieses Konzept erwies sich bei der Entwicklung clientseitiger Navigation als sehr sinnvoll (bevor pushState eingeführt wurde). Auch als es darum ging, wie man Zustände in URLs speichern kann, ohne sie wirklich zum Server zu senden, waren Fragmente von großem Nutzen. Was das bedeuten soll? Schauen wir uns das genauer an:
Mücken und Elefanten
Es gibt einen ganzen Standard, so widerlich wie SGML, für elektronischen Datenaustausch, also für Formulare und Formularübermittlung. Mehr weiß ich auch nicht, nur dass er aussieht wie Fortran rückwärts ohne Leerzeichen.
– Tim Berners-Lee 1993
Oft wird der Eindruck erweckt, die Internet-Standardisierungsgremien hätten zwischen der Fertigstellung von HTTP 1.1 und HTML 4.01 im Jahr 2002 und der Zeit, in der HTML 5 wirklich in Gang kam, nicht viel geleistet. Manche Leute (genaugenommen nur ich) nennen diese Zeit auch das dunkle XHTML-Zeitalter. In Wirklichkeit aber waren die Leute im Standardisierungsbereich sagenhaft fleißig. Das Problem war nur, dass sie sich mit Dingen beschäftigten, die sich im Nachhinein nicht als besonders wertvoll erwiesen.
Ein solches Projekt war das Semantic Web. Sie träumten davon, ein Framework zur Beschreibung von Ressourcen (Resource Description Framework, RDF) zu entwickeln, mit dem die Metadaten von Inhalten universell ausgedrückt werden können (Anmerkung der Redaktion: wenn ein Team ein Framework entwickeln möchte, dann nichts wie weg): Anstatt beispielsweise eine schöne Webseite über meine Corvette Stingray zu gestalten, könnte ich ein RDF-Dokument erstellen, mit Angaben zur Größe und Farbe des Sportwagens und zur Anzahl der Strafzettel, die ich damit erhalten habe.
Natürlich ist das keineswegs eine schlechte Idee. Grundlage des Formats war jedoch XML und es war wie bei der Frage nach der Henne und dem Ei: Einerseits wollte man die ganze Welt dokumentieren, andererseits sollten die Browser irgendetwas Sinnvolles mit dieser Dokumentation anfangen.
Allerdings lieferte das Projekt einen ergiebiges Umfeld für philosophische Streitgespräche. Eine der besten dieser Diskussionen dauerte mindestens zehn Jahre und trug den formvollendeten Codenamen „httpRange-14“.
Mit httpRange-14 sollte die grundlegende Frage beantwortet werden, was eine URL ist. Verweist eine URL immer auf ein Dokument, oder kann sie auf alles Mögliche verweisen? Kann ich eine URL bekommen, die auf mein Auto verweist?
Der Versuch, diese Frage zufriedenstellend zu beantworten, wurde allerdings nicht unternommen. Stattdessen drehte sich vieles darum, wie und wann man Nutzer mithilfe von 303-Weiterleitungen von Links, die keine Dokumente sind, zu solchen führen kann, die es sind, und wann wir URL-Fragmente (den Teil hinter dem „#“) nutzen können, um Nutzer zu verlinkten Daten zu führen.
Das ist aus heutiger, pragmatischer Sicht vielleicht eine alberne Frage. Viele von uns sind der Ansicht, dass man eine URL für alles verwenden kann, was sich eben damit machen lässt, und dann nutzen die Leute diese Lösung, oder auch nicht. Aber beim Semantic Web interessiert nur die Semantik, also wurde die Frage eben diskutiert.
Man debattierte am 1. Juli 2002, 15. Juli 2002, 22. Juli 2002, 29. Juli 2002, 16. September 2002 und zu mindestens 20 weiteren Anlässen bis 2005 über dieses spezielle Thema. Entschieden wurde die Frage schließlich durch die großartige „httpRange-14-Lösung“ von 2005, aber aufgrund von Beschwerden in den Jahren 2007 und 2011 sowie einer Forderung nach neuen Lösungen 2012 landete sie erneut auf der Tagesordnung. Von der Gruppe „Pedantic Web“, deren Name wirklich sehr passend ist, wurde die Frage umfassend diskutiert. Nur eines geschah nicht: Es wurden keine nennenswerten semantischen Daten im Web unter irgendeiner Art von URL platziert.
Auth
Wie Sie wahrscheinlich wissen, können Sie bei URLs auch einen Benutzernamen und ein Passwort angeben:
http://zack:[email protected]
Der Browser kodiert diese Authentifizierungsdaten dann mit Base64 und sendet sie als Header:
Authentication: Basic emFjazpzaGhoaGho
Benutzername und Passwort werden nur deshalb mit Base64 kodiert, damit auch Zeichen zugelassen werden können, die in einem Header möglicherweise nicht gültig sind; verschlüsselt werden Benutzername und Passwort dadurch nicht.
Insbesondere vor der Einführung der SSL-Internetverbindung war das sehr problematisch. Jeder, der Ihre Verbindung anzapfen konnte, konnte mühelos Ihr Passwort auslesen. Dementsprechend fehlte es auch nicht an Alternativvorschlägen, darunter Kerberos, damals wie heute ein breit genutztes Sicherheitsprotokoll.
Wie bei vielen ähnlich gelagerten Fällen war aber der simple Basic-Auth-Vorschlag für die Browserhersteller (Mosaic) am einfachsten zu implementieren. Dadurch wurde er zur ersten und schließlich einzigen Lösung, bis die Entwickler die Werkzeuge zum Aufbau eigener Authentifizierungssysteme bekamen.
Die Webanwendung
In der Welt der Webanwendungen wirkt es vielleicht etwas seltsam, sich vorzustellen, dass der Hyperlink die Grundlage des Web sei. Er ist eine Methode, ein Dokument mit einem anderen zu verknüpfen. Nach und nach wurde er durch stilistische Anpassungen, Codeausführung, Sitzungen und Authentifizierung erweitert, bis schließlich das Computing-Gemeinschaftserlebnis entstand, um das sich so viele Experten der 70er Jahre (vergeblich) bemühten. Letzten Endes bestätigt sich auch hier wieder etwas, das damals wie heute für jedes Projekt oder Startup gilt: Es kommt nur auf die Akzeptanz an. Ganz gleich, wie schlampig Ihre Lösung ist – wenn Sie die Leute dazu bringen können, sie zu benutzen, dann werden sie Ihnen auch helfen, daraus etwas Brauchbares zu machen. Umgekehrt gilt natürlich das Gleiche: Wenn Ihnen die Nutzer fehlen, hilft auch keine technische Perfektion. Es gibt unzählige Werkzeuge, in denen Millionen von Arbeitsstunden stecken und die heute kein Mensch mehr verwendet.
Dieser Artikel ist die überarbeitete Fassung eines Beitrags, der ursprünglich im Eager-Blog erschienen ist. Aus Eager wurde 2016 Cloudflare Apps.
Was ist Cloudflare?
Mit Cloudflare können Sie Caching, Lastverteilung, Rate Limiting und sogar Netzwerk-Firewalls und Codeausführung innerhalb von Millisekunden von praktisch jedem Internetbenutzer aus Ihrer Infrastruktur an unsere Points of Presence verschieben.
Fallstudie lesen Vertrieb kontaktieren