

Aufgrund einer Anpassung bei unserem Tiered Cache-System wurden in einigen Fällen Anfragen von Nutzern mit einer 530-Fehlermeldung beantwortet. Der Vorfall dauerte insgesamt sechs Stunden. Unserer Schätzung nach schlugen auf seinem Höhepunkt etwa 5 % aller Anfragen fehl. Wegen der hohen Komplexität unseres Systems und eines blinden Flecks bei unseren Tests haben wir dies bei Einführung der Änderung in unserer Testumgebung nicht erkannt.
Die Ausfälle wurden durch Begleiterscheinungen unseres Umgangs mit zwischenspeicherbaren Anfragen an verschiedenen Standorten ausgelöst. Zunächst hatte es den Anschein, als würde der Fehler durch ein anderes System verursacht, bei dem zuvor ein Release gestartet worden war. Unsere Teams brauchten mehrere Anläufe, bis sie die Fehlerquelle gefunden hatten. Anschließend haben wir innerhalb von 87 Minuten ein Rollback durchgeführt.
Wir bedauern diesen Vorfall und unternehmen die nötigen Schritte, um sicherzustellen, dass er sich nicht wiederholt.
Hintergrund
Zu den Produkten von Cloudflare zählt unser Content Delivery Network (CDN). Dieses wird verwendet, um Assets für Websites weltweit zwischenzuspeichern. Man kann sich jedoch nicht darauf verlassen, dass ein Rechenzentrum ein Asset zwischengespeichert hat. Es kann neu, abgelaufen oder gelöscht worden sein. Wenn das der Fall ist und ein Nutzer dieses Asset anfordert, muss unser CDN eine neue Kopie vom Ursprungsserver der Website abrufen. Doch das Rechenzentrum, auf das der User zugreift, ist unter Umständen relativ weit vom Ursprungsserver entfernt. Das stellt für Kunden ein zusätzliches Problem dar: Jedes Mal, wenn ein Asset nicht im Rechenzentrum zwischengespeichert ist, müssen wir eine neue Kopie vom Ursprungsserver abrufen.
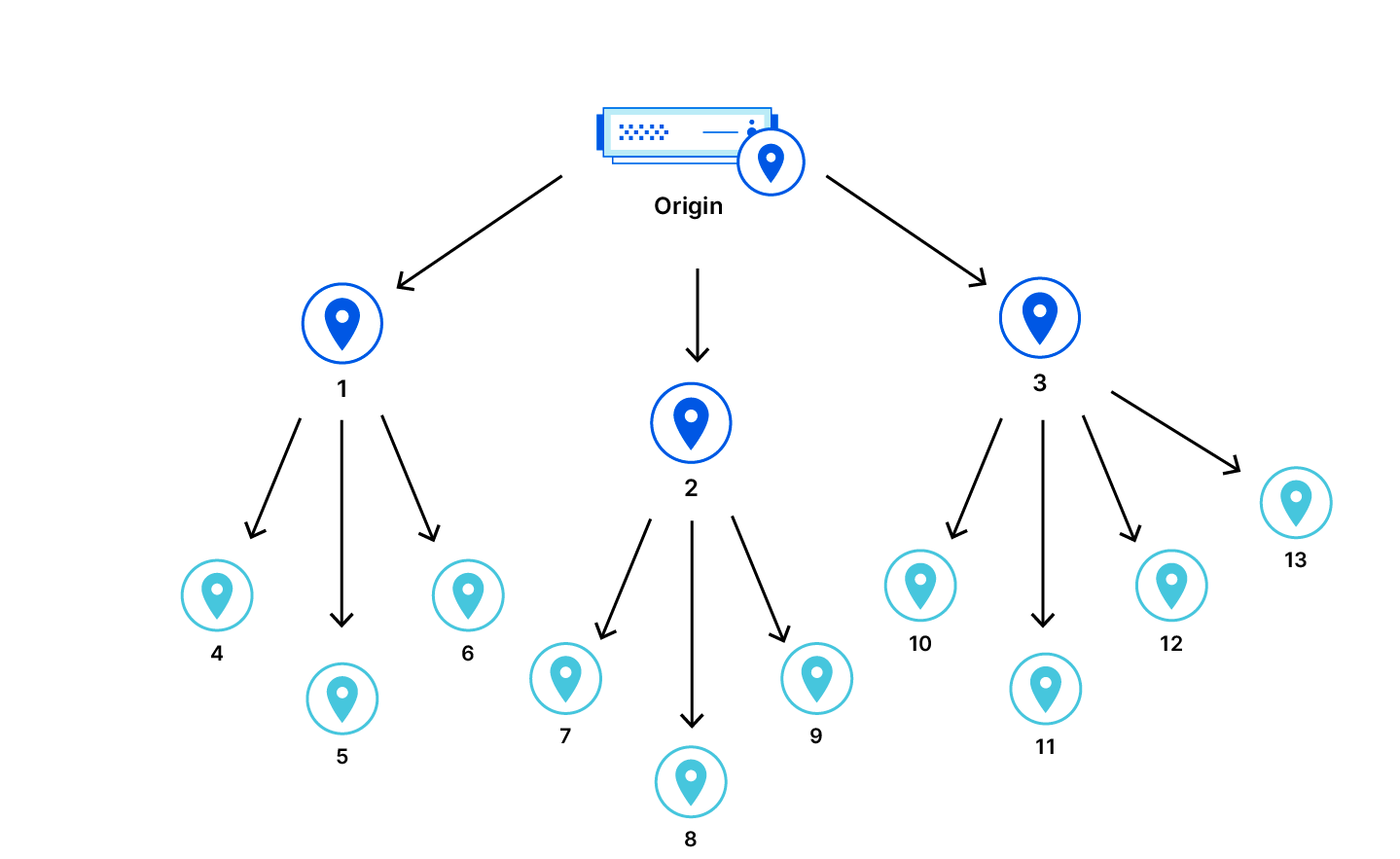
Zur Verbesserung der Cache-Trefferquoten haben wir Tiered Cache eingeführt. Mit Tiered Cache ordnen wir unsere Rechenzentren im CDN in eine Hierarchie ein. Dabei wird unterschieden zwischen „Lower Tiers“, die näher an den Endnutzern liegen, und „Upper Tiers“, die näher am Ursprungsserver liegen. Wenn ein Cache-Fehler bei einem als „Lower Tier“ eingestuften Rechenzentrum auftritt, wird die „Upper Tier“-Kategorie überprüft. Findet sich dort eine neue Kopie des Assets, können wir diese als Antwort auf die Anfrage bereitstellen. Dadurch verbessert sich die Performance. Zugleich muss Cloudflare seltener zum Abruf von Assets, die nicht in den „Lower Tier“-Rechenzentren zwischengespeichert sind, auf einen Ursprungsserver zugreifen.
Zeitlicher Ablauf und Auswirkungen des Vorfalls
Um 10:40 Uhr (MESZ) begann ein langsamer Rollout der Softwareversion einer CDN-Komponente, die einen Fehler enthielt. Der Fehler kam zum Tragen, wenn ein Nutzer eine Website besuchte, für die entweder Tiered Cache, Cloudflare Images oder Bandwidth Alliance konfiguriert war. Er führte zur Ausgabe des HTTP-Statuscodes 530 – und damit einer Fehlermeldung – bei einem Teil dieser Kunden. Inhalte, die direkt aus dem lokalen Cache eines Rechenzentrums bereitgestellt werden konnten, waren davon nicht betroffen.
Nachdem die fehlerhafte Komponente für eine Untergruppe von Rechenzentren freigegeben worden war und bei uns im Anschluss daran Kundenberichte über einen zeitweiligen Anstieg solcher Fehlermeldungen eingegangen waren, begannen wir, Nachforschungen anzustellen.
Als die Version weltweit an die verbleibenden Rechenzentren verteilt wurde, lösten ein sprunghafter Anstieg der 530-Meldungen sowie weitere Berichte von Kunden Warnmeldungen aus, weshalb ein Incident ausgerufen wurde.
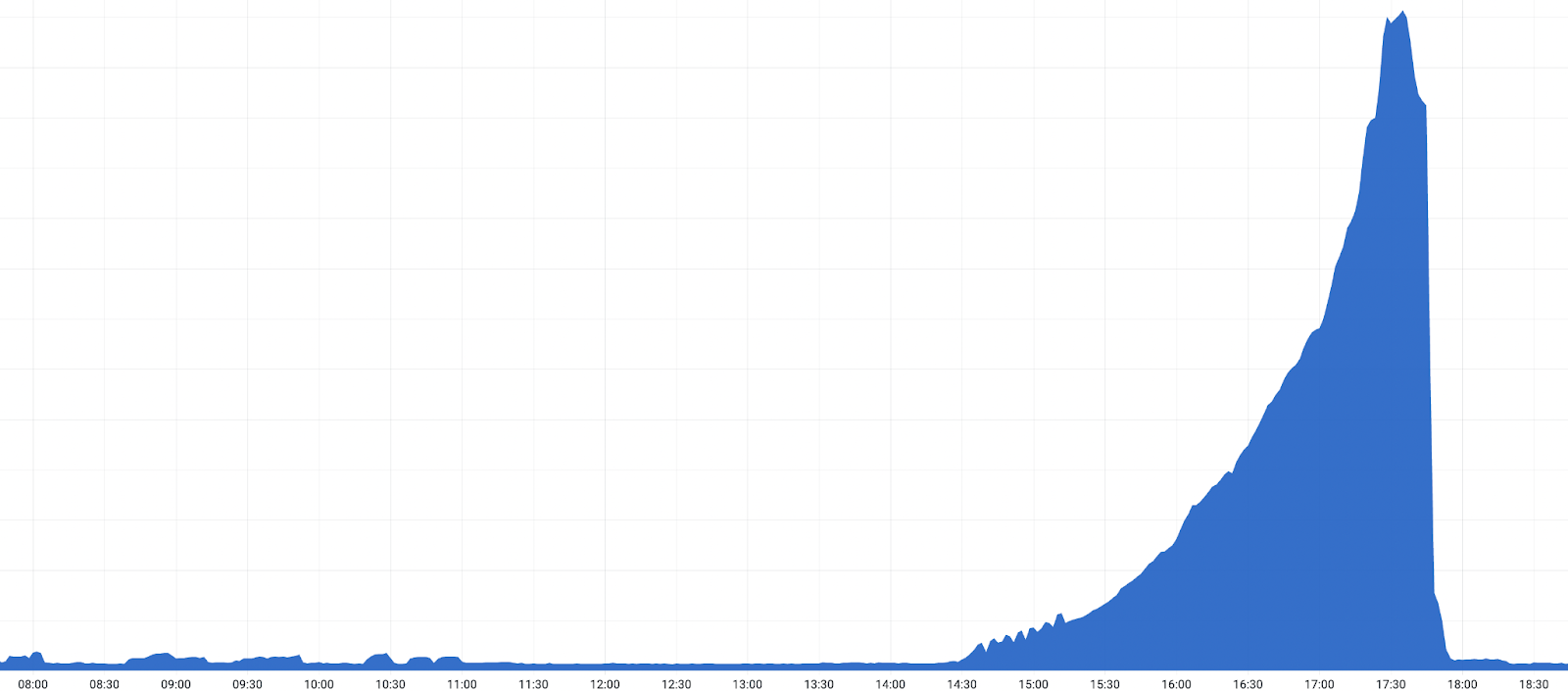
Um uns zu vergewissern, dass eine fehlerhafte Version für die Vorfälle verantwortlich war, setzten wir die Version in einem Rechenzentrum um 19:03 Uhr zurück. Nach dem Rollback registrierten wir einen Rückgang der 530-Fehlermeldungen. Im Anschluss an diese Bestätigung begann ein beschleunigter globaler Rollback und die Zahl der 530-Fehlermeldungen nahm ab. Die Störungen endeten, sobald die Version um 20:04 Uhr in allen nach dem Tiered Cache-System als „Upper Tiers“ konfigurierten Rechenzentren zurückgesetzt worden war.
Zeitlicher Ablauf:
- 25.10.2022, 10:40 Uhr (MESZ): Die Version wird zunächst an eine kleine Gruppe von Rechenzentren verteilt.
- 25.10.2022, 12:35 Uhr: Ein individueller Kundenalarm wird ausgelöst, der eine Zunahme von 500-Fehlermeldungen anzeigt.
- 25.10.2022, 13:20: Nach einer Untersuchung wird ein einzelnes kleines Rechenzentrum als Quelle des Problems ausgemacht und aus dem Verkehr gezogen, während die Teams dem dort auftretenden Problem auf den Grund gehen.
- 25.10.2022, 14:30 Uhr: Das Problem breitet sich immer weiter aus, je mehr Rechenzentren die Codeänderungen erhalten.
- 2022-10-25 14:22 Uhr: 530-Fehlermeldungen nehmen zu, da die Version langsam in unseren größten Rechenzentren verteilt wird.
- 25.10.2022, 16:39 Uhr: Mehrere Teams werden an der Untersuchung beteiligt, da immer mehr Kunden eine Fehlerzunahme melden.
- 25.10.2022, 19:03 Uhr: Die CDN-Version wird in Atlanta zurückgesetzt und der Verdacht hinsichtlich der Fehlerquelle kann bestätigt werden.
- 25.10.2022, 19:28 Uhr: Auf dem Höhepunkt des Vorfalls führen etwa 5 % aller HTTP-Anfragen zu einem Fehler mit dem Statuscode 530.
- 25.10.2022, 19:38 Uhr: Ein beschleunigter Rollback wird fortgesetzt, wobei große Rechenzentren für viele Kunden als „Upper Tier“ fungieren.
- 25.10.2022, 20:04 Uhr: Der Rollback ist in allen „Upper Tier“-Rechenzentren abgeschlossen.
- 25.10.2022, 20:30 Uhr: Der Rollback ist vollständig abgeschlossen.
In der Anfangsphase der Untersuchung deutete alles darauf hin, dass es sich um ein Problem mit unserem internen DNS-System handelte, das zur gleichen Zeit ebenfalls eine neue Version einführte. Wie der folgende Abschnitt zeigt, handelte es sich dabei jedoch nur um eine Begleiterscheinung und nicht um die Ursache des Ausfalls.
Auslöser des Problems: Erweiterung von Tiered Cache um dezentrale Nachverfolgung
Um unsere Performance zu verbessern fügen wir routinemäßig Kontrollcode zu verschiedenen Teilen unserer Dienste hinzu. Dieser gibt uns einen Einblick in die Performance der verschiedenen Komponenten und ermöglicht es uns, Engpässe zu ermitteln, sodass wir uns verbessern können. Unser Team hat vor kurzem unsere Tiered-Cache-Logik um eine zusätzliche dezentrale Nachverfolgung erweitert. Der Einsprungspunktcode von Tiered Cache sieht folgendermaßen aus:
* Vorher:
function _M.go()
-- code to run here
end
* Nachher:
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
endDer Code umhüllt die vorhandene go()-Funktion mit trace_fn(), die die go()-Funktion aufruft und dann deren Ausführungszeit meldet.
Die Logik, die eine Funktion in das Opentracing-Modul injiziert, löscht jedoch bei jeder Anfrage die Control-Header:
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
-- Normalerweise extrahieren wir bei der Verarbeitung von Anfragen routinemäßig Daten aus diesen Control-Headern, bevor wir sie löschen.
Der interne Tiered Cache-Traffic erwartet jedoch, dass die Control-Header der „Lower Tier“-Rechenzentren unverändert weitergegeben werden. Aufgrund der Löschung von Headern in Kombination mit der Nutzung von „Upper Tier“-Rechenzentren waren Informationen, die für die Weiterleitung der Anfrage entscheidend sein könnten, nicht verfügbar. Bei der betroffenen Anfragengruppe fehlte uns der Hostname, der von unserem internen DNS-Lookup für die IP-Adressen der Ursprungsserver aufgelöst wird. Infolgedessen wurde eine 530-DNS-Fehlermeldung an den Client übermittelt.
Abhilfe- und Folgemaßnahmen
Um dies zu verhindern, haben wir neben der Behebung des Fehlers eine Reihe von Änderungen vorgenommen, die uns helfen, solche Probleme in Zukunft zu erkennen und zu vermeiden:
- Aufnahme eines größeren, im Tiered Cache-System als „Upper Tier“ konfiguriertes Rechenzentrum in den Release-Plan, und zwar in einer früheren Phase. Auf diese Weise können wir ähnliche Probleme vor einer weltweiten Verteilung schneller erkennen.
- Ausweitung der Akzeptanztests auf eine breitere Palette von Konfigurationen, einschließlich verschiedener Tiered Cache-Topologien.
- Offensivere Warnungen in Situationen, in denen wir nicht über den vollständigen Kontext der Anfragen verfügen und die zusätzlichen Host-Informationen in den Control-Headern benötigen.
- Sicherstellung eines schnellen Fails unseres Systems bei einem vergleichbaren Fehler, was dazu beigetragen hätte, das Problem in der Entwicklungs- und Testphase zu erkennen.
Fazit
Es gab einen Vorfall, von dem eine große Anzahl von Kunden betroffen war, die Tiered Cache verwenden. Nachdem wir die fehlerhafte Komponente identifiziert hatten, konnten wir schnell ein Rollback durchführen und das Problem beheben. Wir entschuldigen uns für die Störungen, die für unsere Kunden und Endnutzer beim Zugriff auf Services aufgetreten sind.
Maßnahmen, mit denen verhindert wird, dass sich ein solcher Vorfall in Zukunft wiederholt, werden so schnell wie möglich eingeleitet.