


Cloudflare erkennt jetzt automatisch alle API-Endpunkte und erfasst bzw. erlernt die API-Schemata für alle unsere API-Gateway-Kunden. Kunden können diese neuen Funktionen nutzen, um ein positives Sicherheitsmodell für ihre API-Endpunkte durchzusetzen, selbst wenn sie heute nur wenige bis gar keine Informationen über ihre bestehenden APIs haben.
Der erste Schritt zur Sicherung Ihrer APIs besteht darin, die Hostnamen und Endpunkte Ihrer APIs zu kennen. Wir hören oft, dass Kunden gezwungen sind, ihre Bemühungen um die Katalogisierung und Verwaltung von APIs in etwa so zu beginnen „Wir mailen eine Tabelle herum und bitten die Entwickler, alle ihre Endpunkte aufzulisten“.
Können Sie sich die Probleme mit diesem Ansatz vorstellen? Vielleicht haben Sie sie selbst erlebt. Der Ansatz „mailen und fragen“ schafft eine punktuelle Bestandsaufnahme, die sich mit der nächsten Codeversion wahrscheinlich ändern wird. Sie stützt sich auf undokumentiertes Wissen, das mit dem Ausscheiden von Mitarbeitern aus dem Unternehmen verschwinden kann. Zudem ist es anfällig für menschliche Fehler.
Selbst wenn Sie über ein durch gemeinsame Anstrengungen gesammeltes genaues API-Inventar verfügten; Die Validierung der bestimmungsgemäßen Verwendung der API durch die Durchsetzung eines API-Schemas würde noch mehr kollektives Wissen zur Erstellung dieses Schemas erfordern. Die neuen Funktionen API-Discovery und Schema Learning des API-Gateways schützen APIs im globalen Netzwerk von Cloudflare automatisch und machen eine manuelle API-Erkennung und Schemaerstellung überflüssig.
API-Gateway erkennt und schützt APIs
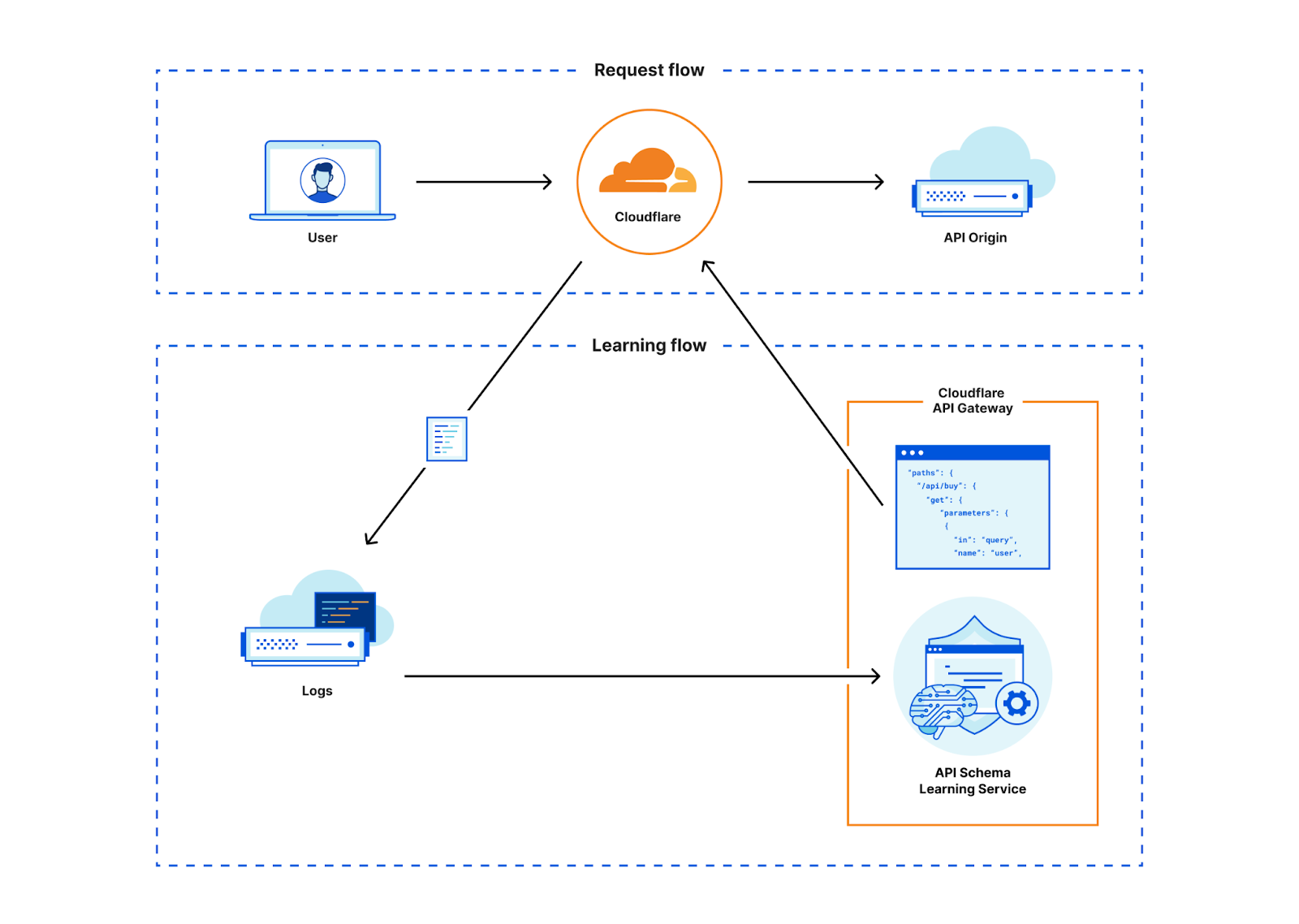
API-Gateway erkennt APIs über eine Funktion namens API-Discovery. Bislang verwendete API-Discovery kundenspezifische Sitzungskennungen (HTTP-Header oder Cookies), um API-Endpunkte zu identifizieren und deren Analysen für unsere Kunden anzuzeigen.
Diese Art der Entdeckung hat funktioniert, aber sie hatte drei Nachteile:
- Die Kunden mussten wissen, welchen Header oder Cookie sie verwendeten, um die Sitzungen abgrenzen zu können. Obwohl Sitzungskennungen weit verbreitet sind, kann es einige Zeit dauern, das richtige Token zu finden.
- Da wir für API-Discovery eine Sitzungskennung benötigten, konnten wir völlig unauthentifizierte APIs nicht überwachen und keine Berichte darüber erstellen. Kunden wollen auch heute noch Einblick in den sitzungslosen Traffic, um sicherzustellen, dass alle API-Endpunkte dokumentiert sind und der Missbrauch auf ein Minimum reduziert wird.
- Sobald die Sitzungskennung in das Dashboard eingegeben wurde, mussten die Kunden bis zu 24 Stunden warten, bis der Discovery-Prozess abgeschlossen war. Niemand wartet gerne.
Dieser Ansatz hatte zwar Nachteile, aber wir wussten, dass wir unseren Kunden schnell einen Mehrwert bieten konnten, indem wir mit einem sitzungsbasierten Produkt begannen. Mit zunehmender Kundenzahl und steigendem Traffic im System wussten wir, dass unsere neuen markierten Daten für den weiteren Ausbau unseres Produkts äußerst nützlich sein würden. Wenn wir ein Machine-Learning-Modell mit unseren bestehenden API-Metadaten und den neuen gelabelten Daten trainieren könnten, bräuchten wir keine Sitzungskennung mehr, um die Endpunkte für APIs zu ermitteln. Also haben wir beschlossen, diesen neuen Ansatz zu entwickeln.
Wir nutzten die Erkenntnisse, die wir aus den auf der Sitzungskennung basierenden Daten gewonnen haben, und erstellten ein Machine-Learning-Modell, um den gesamten API-Traffic zu einer Domain aufzudecken, unabhängig von der Sitzungskennung. Mit unserer neuen, auf Machine Learning-basierenden API-Erkennung entdeckt Cloudflare kontinuierlich den gesamten API-Traffic, der durch unser Netzwerk geleitet wird, ohne jegliches Zutun des Kunden. Mit dieser Version können API-Gateway-Kunden schneller als je zuvor mit der API-Erkennung beginnen und nicht-authentifizierte APIs erkennen, die sie vorher nicht aufspüren konnten.
Sitzungskennungen sind für API-Gateway nach wie vor wichtig, da sie die Grundlage für unsere volumetrischen Durchsatzbegrenzungen zur Missbrauchsprävention sowie für unsere Sequence Analytics bilden. Weitere Informationen darüber, wie der neue Ansatz abschneidet, erhalte Sie im Abschnitt „So funktioniert's“ weiter unten.
API-Schutz aus dem Nichts
Nun, da Sie mit der API-Erkennung neue APIs aufgespürt haben, stellt sich die Frage, wie Sie diese schützen können. Um sich gegen Angriffe zu schützen, müssen API-Entwickler genau wissen, wie ihre APIs verwendet werden sollen. Glücklicherweise können Entwickler programmatisch eine API-Schemadatei generieren, die akzeptable Eingaben für eine API kodiert, und diese in die Schema Validation von API-Gateway hochladen.
Wir haben jedoch bereits darüber gesprochen, dass viele Kunden ihre APIs nicht so schnell aufspüren können, wie ihre Entwickler sie erstellen. Wenn sie APIs finden, ist es sehr schwierig, ein eindeutiges OpenAPI-Schema für jeden von möglicherweise Hunderten von API-Endpunkten zu erstellen, da Sicherheitsteams in ihren Protokollen selten mehr als die HTTP-Anfragemethode und den Pfad sehen.
Als wir die Nutzungsmuster von API-Gateway untersuchten, stellten wir fest, dass Kunden zwar APIs entdecken, aber fast nie ein Schema durchsetzen. Als wir sie fragten: „Warum nicht?“, antworteten sie in etwa so: „Selbst wenn ich weiß, dass es eine API gibt, kostet es so viel Zeit, herauszufinden, wem die einzelnen APIs gehören, damit sie ein Schema bereitstellen können. Ich kann diese Aufgaben nicht höher priorisieren als andere wichtige Sicherheitsaufgaben.“ Mangelnde Zeit und fehlendes Fachwissen waren die größten Schwierigkeiten, mit denen unsere Kunden bei der Umsetzung von Schutzmaßnahmen zu kämpfen hatten.
Also haben wir beschlossen, diese Lücke zu schließen. Wir fanden heraus, dass derselbe Lernprozess, den wir für die Entdeckung von API-Endpunkten verwendet haben, auch auf Endpunkte angewendet werden kann, sobald sie entdeckt wurden, um automatisch ein Schema zu lernen. Mit dieser Methode können wir nun für jeden einzelnen Endpunkt, den wir entdecken, ein OpenAPI-formatiertes Schema in Echtzeit generieren. Wir nennen diese neue Funktion Schema Learning. Kunden können dieses von Cloudflare generierte Schema dann in Schema Validation hochladen, um ein positives Sicherheitsmodell durchzusetzen.
So funktioniert’s
Auf Machine Learning-basierende API-Erkennung
Bei RESTful APIs bestehen die Anfragen aus verschiedenen HTTP-Methoden und Pfaden. Nehmen Sie zum Beispiel die Cloudflare API. Bei den Pfaden ist ein gemeinsamer Trend zu erkennen, durch den sich Anfragen an diese API von Anfragen an diesen Blog abheben könnten: Die API-Anfragen beginnen alle mit /client/v4 und setzen sich fort mit dem Namen des Dienstes, einer eindeutigen Kennung und manchmal mit den Namen der Dienstmerkmale und weiteren Kennungen.
Wie können wir API-Anfragen leicht erkennen? Auf den ersten Blick scheint es einfach zu sein, diese Anfragen mit einer Heuristik wie "Pfad beginnt mit /client" programmatisch zu entdecken, aber der Kern unserer neuen Discovery enthält ein Machine-Learning-Modell, das einen Klassifikator zur Bewertung von HTTP-Transaktionen verwendet. Wenn API-Pfade so strukturiert sind, warum benötigt man dann Machine-Learning dafür und kann nicht einfach eine einfache Heuristik verwenden?
Die Antwort läuft auf die Frage hinaus: Was ist eigentlich eine API-Anfrage und wie unterscheidet sie sich von einer Nicht-API-Anfrage? Sehen wir uns zwei Beispiele an.
Wie die Cloudflare-API folgen auch die APIs vieler unserer Kunden dem Muster, dem Pfad ihrer API-Anfrage eine „api“-Kennung und eine Version voranzustellen, zum Beispiel: /api/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d.
Wenn Sie also einfach nur nach „api“ oder einer Version im Pfad suchen, ist das schon eine ziemlich gute Heuristik, die uns sagt, dass es sich höchstwahrscheinlich um einen Teil einer API handelt. Allerdings ist es leider nicht immer so einfach.
Betrachten wir zwei weitere Beispiele, /users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpg und /users/7f577081-7003-451e-9abe-eb2e8a0f103d, die sich beide nur durch eine .jpg-Erweiterung unterscheiden. Der erste Pfad könnte eine statische Ressource wie das Miniaturbild eines Nutzers sein. Der zweite Pfad gibt uns nicht viele Anhaltspunkte allein durch den Pfad.
Die manuelle Ausarbeitung solcher Heuristiken wird schnell schwierig. Menschen sind zwar gut darin, Muster zu erkennen, aber die Entwicklung von Heuristiken ist angesichts des Umfangs der Daten, die Cloudflare jeden Tag erfasst, eine Herausforderung. Daher verwenden wir Machine Learning, um diese Heuristiken automatisch abzuleiten, sodass wir wissen, dass sie reproduzierbar sind und eine bestimmte Genauigkeit einhalten.
Als Input für das Training des Machine Learning-Modells dienen Merkmale von HTTP-Anfrage/Antwort-Beispielen wie der Inhaltstyp oder die Dateierweiterung, die wir durch die bereits erwähnte, auf Sitzungskennungen basierende Entdeckung gesammelt haben. Leider ist nicht alles, was wir in diesen Daten haben, eindeutig eine API. Darüber hinaus benötigen wir auch Proben, die nicht-API Traffic repräsentieren. Wir begannen also mit den Discovery-Daten zur Sitzungskennung, bereinigten sie manuell und leiteten weitere Stichproben des Nicht-API-Traffics ab. Wir waren sehr bedacht, das Modell nicht zu sehr an die Daten anzupassen. Das heißt, wir wollen, dass das Modell über die Trainingsdaten hinaus verallgemeinert.
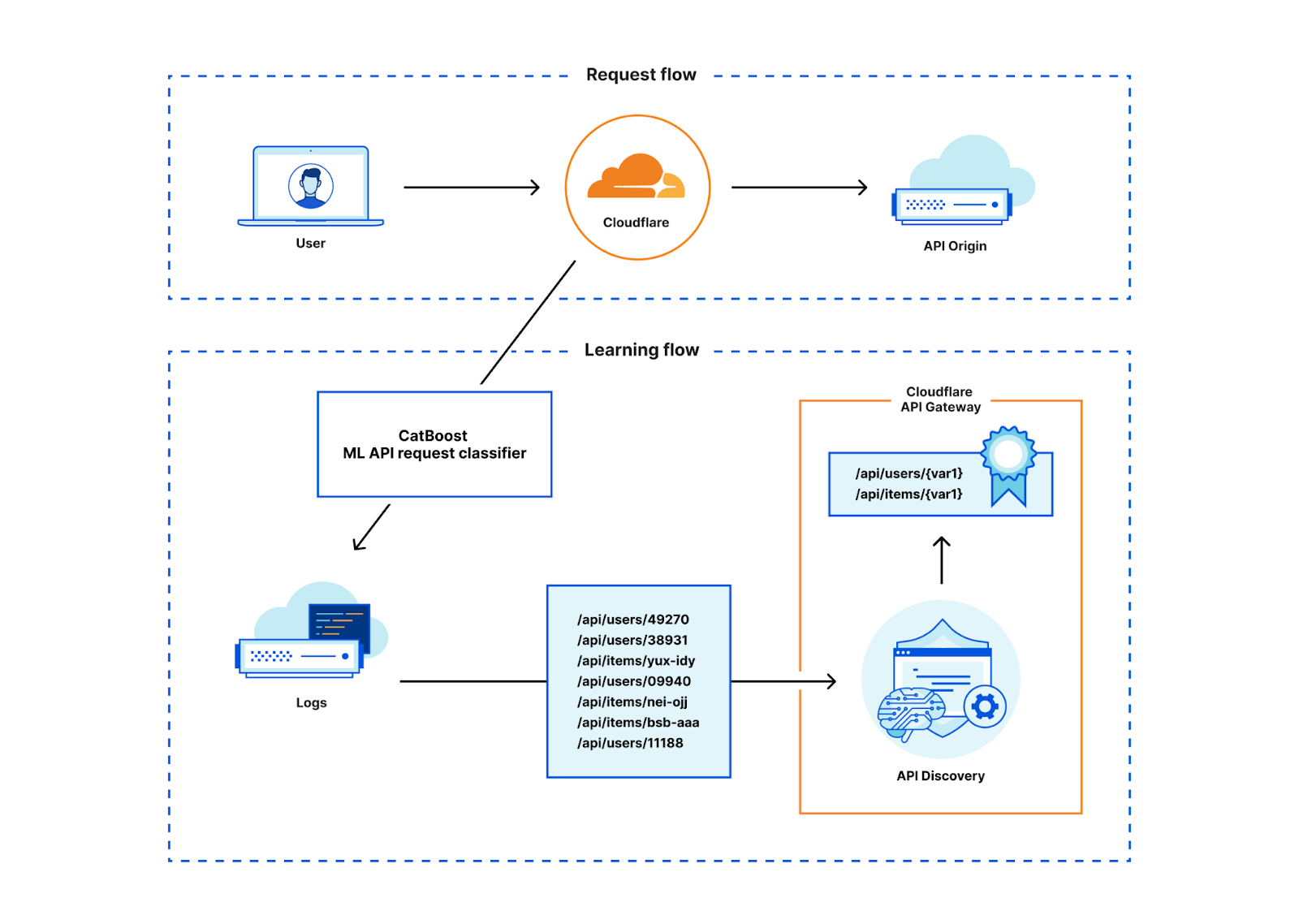
Um das Modell zu trainieren, haben wir die CatBoost-Bibliothek verwendet, mit der wir bereits eine Menge Erfahrung haben, da wir sie auch für unsere ML-Modelle für Bot-Management nutzen. Vereinfacht kann man das resultierende Modell als ein Flussdiagramm betrachten, das uns sagt, welche Bedingungen wir nacheinander prüfen sollten, zum Beispiel: Wenn der Pfad „api“ enthält, dann prüfen Sie auch, ob es keine Dateierweiterung gibt und so weiter. Am Ende dieses Flussdiagramms steht eine Punktzahl, die uns sagt, wie hoch die Wahrscheinlichkeit ist, dass eine HTTP-Transaktion zu einer API gehört.
Mit dem trainierten Modell können wir also Merkmale von HTTP-Anfragen/Antworten eingeben, die durch das Cloudflare-Netzwerk fließen und die Wahrscheinlichkeit berechnen, dass diese HTTP-Transaktion zu einer API gehört oder nicht. Die Merkmalsextraktion und Modellbewertung erfolgt in Rust und dauert in unserem globalen Netzwerk nur ein paar Mikrosekunden. Da Discovery die Daten aus unserer leistungsstarken Datenpipeline bezieht, ist es eigentlich nicht notwendig, jede Transaktion zu bewerten. Wir können die Last auf unseren Servern reduzieren, indem wir nur die Transaktionen bewerten, von denen wir wissen, dass sie in unserer Datenpipeline landen werden. Das spart CPU-Zeit und macht das Feature kostengünstig.
Sobald wir die Klassifizierungsergebnisse in unserer Datenpipeline haben, können wir denselben API-Discovery-Mechanismus verwenden, den wir auch für die auf Sitzungskennungen basierende Discovery genutzt haben. Dieses bestehende System funktioniert hervorragend und ermöglicht uns die effiziente Wiederverwendung von Code. Es hat uns auch beim Vergleich unserer Ergebnisse mit der auf Sitzungskennungen basierenden Discovery geholfen, da die Systeme direkt vergleichbar sind.
Damit die Ergebnisse von API-Discovery nützlich sind, besteht die erste Aufgabe von Discovery darin, die eindeutigen Pfade, die wir sehen, in Variablen zu vereinfachen. Wir haben bereits darüber gesprochen. Es ist nicht trivial, die verschiedenen Identifizierungsschemata, die wir im globalen Netzwerk verzeichnen, abzuleiten, insbesondere wenn Websites benutzerdefinierte Identifizierungen verwenden, die über ein einfaches GUID- oder Ganzzahlformat hinausgehen. API-Discovery normalisiert Pfade, die Variablen enthalten, mit Hilfe einiger verschiedener Variablenklassifikatoren und überwachtem Lernen.
Erst nach der Normalisierung der Pfade stehen die Discovery-Ergebnisse für unsere Nutzer auf einfache Weise zur Verfügung.
Die Ergebnisse: Hunderte von aufgespürten Endpunkten pro Kunde
Wie unterscheidet sich nun die ML-Discovery von der auf Sitzungskennungen-basierenden Discovery, die sich auf Header oder Cookies stützt, um den API-Traffic zu kennzeichnen?
Wir gehen davon aus, dass sie eine sehr ähnliche Reihe von Endpunkten erkennt. Wir wussten jedoch, dass es in unseren Daten zwei Lücken geben würde. Erstens stellen wir manchmal fest, dass Kunden nicht in der Lage sind, den reinen API-Traffic anhand von Sitzungskennungen sauber aufzuschlüsseln. In diesem Fall wird der Discovery-Traffic, der nicht von der API stammt, angezeigt. Zweitens: Da wir in der ersten Version von API-Discovery Sitzungskennungen verlangt haben, waren Endpunkte, die nicht Teil einer Sitzung sind (z.B. Login-Endpunkte oder nicht authentifizierte Endpunkte) konzeptionell nicht auffindbar.
Das folgende Diagramm zeigt ein Histogramm der Anzahl der auf Kundendomains entdeckten Endpunkte für beide Erkennungsvarianten.

Aus der Vogelperspektive sehen die Ergebnisse sehr ähnlich aus, was ein guter Indikator dafür ist, dass ML-Discovery so funktioniert, wie es soll. In diesem Diagramm sind bereits einige Unterschiede sichtbar. Das ist jedoch auch zu erwarten, da wir auch Endpunkte entdecken werden, die konzeptionell nicht nur mit einer Sitzungskennung auffindbar sind. Sehen wir uns den Vergleich der einzelnen Domains genauer an, so stellen wir fest, dass es bei etwa 46 % der Domains keine Veränderungen gibt. Das nächste Diagramm vergleicht den Unterschied (in Prozent der Endpunkte) zwischen sitzungsbasierter und ML-basierter Erkennung:

Bei ~15 % der Domains sehen wir eine Zunahme der Endpunkte zwischen 1 und 50, und bei ~9 % sehen wir eine ähnliche Abnahme. Bei ~28 % der Domains finden wir mehr als 50 zusätzliche Endpunkte.
Diese Ergebnisse zeigen, dass ML-Discovery in der Lage ist, zusätzliche Endpunkte aufzuspüren, die bisher unbemerkt geblieben sind, und somit die Palette der Tools erweitert, die API-Gateway bietet, um Ordnung in Ihre API-Landschaft zu bringen.
Sofortiger API-Schutz durch Erlernen von API-Schemata
Wie kann ein Praktiker die neu entdeckten Endpunkte schützen, nachdem die API-Discovery erledigt ist? Wir haben uns bereits die Metadaten der API-Anfrage angesehen, also lassen Sie uns jetzt den API-Anfragetext betrachten. Die Zusammenstellung aller erwarteten Formate für alle API-Endpunkte einer API wird als API-Schema bezeichnet. Die Schema-Validierung von API-Gateway ist eine großartige Möglichkeit, sich gegen die OWASP Top 10 API-Angriffe zu schützen. Sie stellt sicher, dass der Textkörper, der Pfad und der Query-String einer Anfrage die erwarteten Informationen für diesen API-Endpunkt in einem erwarteten Format enthalten. Was aber, wenn Sie das erwartete Format nicht kennen?
Selbst wenn das Schema einer bestimmten API dem Kunden nicht bekannt ist, wurden die Clients, die diese API verwenden, so programmiert, dass sie hauptsächlich Anfragen senden, die diesem unbekannten Schema entsprechen (oder sie wären nicht in der Lage, den Endpunkt erfolgreich abzufragen). Schema Learning macht sich diese Tatsache zunutze und betrachtet erfolgreiche Anfragen an diese API, um das Eingabeschema für den Kunden automatisch zu rekonstruieren. Ein Beispiel: Eine API könnte erwarten, dass der Parameter Nutzer-ID in einer Anfrage die Form id12345-a hat. Auch wenn diese Erwartung nicht explizit angegeben ist, werden Clients, die erfolgreich mit der API interagieren möchten, Nutzer-IDs in diesem Format senden.
Schema Learning identifiziert zunächst alle letzten erfolgreichen Anfragen an einen API-Endpunkt und analysiert dann die verschiedenen Eingabeparameter für jede Anfrage entsprechend ihrer Position und ihres Typs. Nach dem Parsen aller Anfragen sieht sich Schema Learning die verschiedenen Eingabewerte für jede Position an und erkennt, welche Merkmale sie gemeinsam haben. Nachdem überprüft wurde, dass alle beobachteten Anfragen diese Gemeinsamkeiten aufweisen, erstellt Schema Learning ein Eingabeschema, das die Eingabe auf die Einhaltung dieser Gemeinsamkeiten beschränkt und direkt für die Schema-Validierung verwendet werden kann.
Um genauere Eingabeschemata zu ermöglichen, erkennt Schema Learning, wann ein Parameter verschiedene Arten von Eingaben empfangen kann. Angenommen, Sie möchten eine OpenAPIv3-Schemadatei schreiben und in einer kleinen Stichprobe von Anfragen manuell feststellen, dass ein Abfrageparameter ein Unix-Zeitstempel ist. Sie schreiben ein API-Schema, das erzwingt, dass dieser Abfrageparameter eine ganze Zahl ist, die größer ist als der Beginn der Unix-Epoche des letzten Jahres. Wenn Ihre API diesen Parameter auch im ISO 8601-Format zulässt, würde Ihre neue Regel zu Fehlalarmen führen, wenn der anders formatierte (aber dennoch gültige) Parameter die API erreicht. Schema Learning nimmt Ihnen diese schwere Arbeit ab und findet, was eine manuelle Überprüfung nicht kann.
Um falsch-positive Ergebnisse zu vermeiden, führt Schema Learning einen statistischen Test der Verteilung dieser Werte durch und schreibt das Schema nur dann, wenn die Verteilung mit hoher Sicherheit begrenzt ist.
Wie gut funktioniert es also? Nachfolgend einige Statistiken zu den Parametertypen und -werten, die wir verzeichnen:

Beim Parameter-Lernen werden etwas mehr als die Hälfte aller Parameter als Zeichenfolgen (Strings) klassifiziert, gefolgt von ganzen Zahlen, die fast ein Drittel ausmachen. Die restlichen 17 % bestehen aus Arrays, Booleschen Parametern und Zahlenparametern (Float), während Objektparameter seltener im Pfad und in der Abfrage vorkommen.

Die Anzahl der Parameter im Pfad ist in der Regel sehr gering. 94 % aller Endpunkte verzeichnen höchstens einen Parameter in ihrem Pfad.

Bei der Abfrage verzeichnen wir viel mehr Parameter, manchmal bis zu 50 verschiedene Parameter für einen Endpunkt!
Das Parameter-lernen kann numerische Einschränkungen für die Mehrzahl der beobachteten Parameter mit einer Zuverlässigkeit von 99,9 % schätzen. Bei diesen Einschränkungen kann es sich entweder um ein Maximum/Minimum für den Wert, die Länge oder die Größe des Parameters handeln oder um eine begrenzte Anzahl von eindeutigen Werten, die ein Parameter annehmen muss.
Schützen Sie Ihre APIs in wenigen Minuten
Ab heute können alle API-Gateway-Kunden APIs mit wenigen Klicks entdecken und schützen, auch wenn Sie ohne vorherige Informationen beginnen. Klicken Sie im Cloudflare-Dashboard auf API-Gateway und dann auf die Registerkarte Discovery, um Ihre entdeckten Endpunkte zu sehen. Diese Endpunkte sind sofort verfügbar, ohne dass Sie etwas unternehmen müssen. Fügen Sie dann die relevanten Endpunkte aus Discovery in Endpunktverwaltung. Schema Learning wird automatisch für alle zu Endpoint Management hinzugefügten Endpunkte ausgeführt. Nach 24 Stunden exportieren Sie das gelernte Schema und laden es in Schema Validation hoch.
Enterprise-Kunden, die API-Gateway noch nicht erworben haben, können zunächst die Gateway-Testversion im Cloudflare Dashboard aktivieren oder sich an ihren Kundenbetreuer wenden.
Was kommt als Nächstes?
Wir planen, Schema Learning zu verbessern, indem wir mehr gelernte Parameter in mehr Formaten unterstützen, wie POST-Body-Parameter mit sowohl JSON- als auch URL-kodierten Formaten sowie Header- und Cookie-Schemata. In Zukunft wird Schema Learning Kunden auch benachrichtigen, wenn es Änderungen im identifizierten API-Schema feststellt und ein aktualisiertes Schema präsentieren.
Wir würden gerne Ihr Feedback zu diesen neuen Funktionen hören. Bitte leiten Sie Ihr Feedback an Ihren Kundenbetreuer weiter, damit wir die richtigen Bereiche für Verbesserungen priorisieren können. Wir freuen uns, von Ihnen zu hören!