

Einleitung
Sie können Daten auf viele Arten in Ihren Anwendungen speichern. In Cloudflare Workers-Anwendungen ermöglichen beispielsweise Workers KV die Speicherung der Schlüssel-Werte, und Durable Objects erledigen eine koordinierte Speicherung in Echtzeit, ohne Kompromisse bei der Konsistenz. Außerhalb des Cloudflare-Ökosystems können Sie auch andere Tools wie NoSQL- und Graphdatenbanken einbinden.
Aber manchmal brauchen Sie SQL. Mit einem Index können wir Daten schnell abrufen. Mit Joins beschreiben wir komplexe Beziehungen zwischen verschiedenen Tabellen. SQL beschreibt deklarativ, wie die Daten unserer Anwendung validiert, erstellt und performant abgefragt werden.
D1 ist seit heute in der offenen Alpha-Phase und zur Feier des Tages möchte ich meine Erfahrungen mit der Erstellung von Apps mit D1 teilen; insbesondere die ersten Schritte und warum ich mich darüber freue, dass D1 in die umfangreiche Palette der Tools aufgenommen wurde, mit denen Sie Apps auf Cloudflare bauen können.
D1 ist deshalb so beeindruckend, weil es unmittelbar einen Mehrwert für Anwendungen bietet, und zwar ohne dass wir neue Tools brauchen oder das Cloudflare-Ökosystem verlassen müssen. Mit Wrangler können wir unsere Workers-Anwendungen lokal entwickeln, und mit D1 in Wrangler entwickeln wir jetzt auch richtige Stateful-Anwendungen lokal. Wenn die Anwendung dann bereitgestellt werden soll, können wir mit Wrangler sowohl auf Ihre D1-Datenbank als auch auf Ihre API selbst zugreifen und Befehle ausführen.
Was wir bauen
In diesem Blogbeitrag wird erläutert, wie mit D1 einer statischen Blog-Website Kommentare hinzugefügt werden können. Dafür werden wir eine neue D1-Datenbank erstellen und eine einfache JSON-API entwickeln, mit der sich Kommentare verfassen und abrufen lassen.
Wie ich bereits erwähnt habe: Mit der Trennung von D1 und der eigentlichen App (einer API und Datenbank, die von der statischen Website getrennt bleibt) können wir die statischen und dynamischen Teile unserer Website voneinander abstrahieren. So können wir eine Anwendung auch einfacher bereitstellen: Wir stellen das Frontend auf Cloudflare Pages bereit und die D1-gestützte API auf Cloudflare Workers.
Eine neue Anwendung bauen
Zunächst fügen wir eine Basis-API in Workers hinzu. Erstellen Sie ein neues Verzeichnis und darin ein neues Wrangler-Projekt:
$ mkdir d1-example && d1-example
$ wrangler init
In diesem Beispiel verwenden wir Hono, ein Framework im Stil von Express.js, um unsere API schnell zu bauen. Um Hono in diesem Projekt zu verwenden, installieren Sie es mit NPM:
$ npm install hono
Dann initialisieren wir in src/index.ts eine neue Hono-App und definieren ein paar Endpunkte – GET /API/posts/:slug/comments und POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
Jetzt werden wir eine D1-Datenbank erstellen. In Wrangler 2 gibt es Unterstützung für den Unterbefehl wrangler d1. Mit diesem Befehl erstellen Sie Ihre D1-Datenbanken direkt über die Befehlszeile und fragen sie ab. So können wir zum Beispiel eine neue Datenbank mit einem einzigen Befehl erstellen:
$ wrangler d1 create d1-example
Mit unserer erstellten Datenbank verknüpften wir die Datenbanknamen-ID mit einer Bindung in wrangler.toml, der Konfigurationsdatei von Wrangler. Bindungen ermöglichen uns den Zugriff auf Cloudflare-Ressourcen wie die D1-Datenbanken, KV-Namespaces und R2-Buckets über einen einfachen Variablennamen in unserem Code. Im Folgenden erstellen wir die Bindung DB und repräsentieren damit unsere neue Datenbank:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Beachten Sie, dass diese Direktive, das [[d1_databases]]-Feld, derzeit eine Beta-Version von Wrangler erfordert. Sie können diese für Ihr Projekt mit dem Befehl npm install -D wrangler/beta installieren.
Nachdem wir die Datenbank in unserer wrangler.toml konfiguriert haben, können wir mit ihr über die Befehlszeile und innerhalb unserer Workers-Funktion interagieren.
Zunächst können Sie mit wrangler d1 execute direkte SQL-Befehle eingeben:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
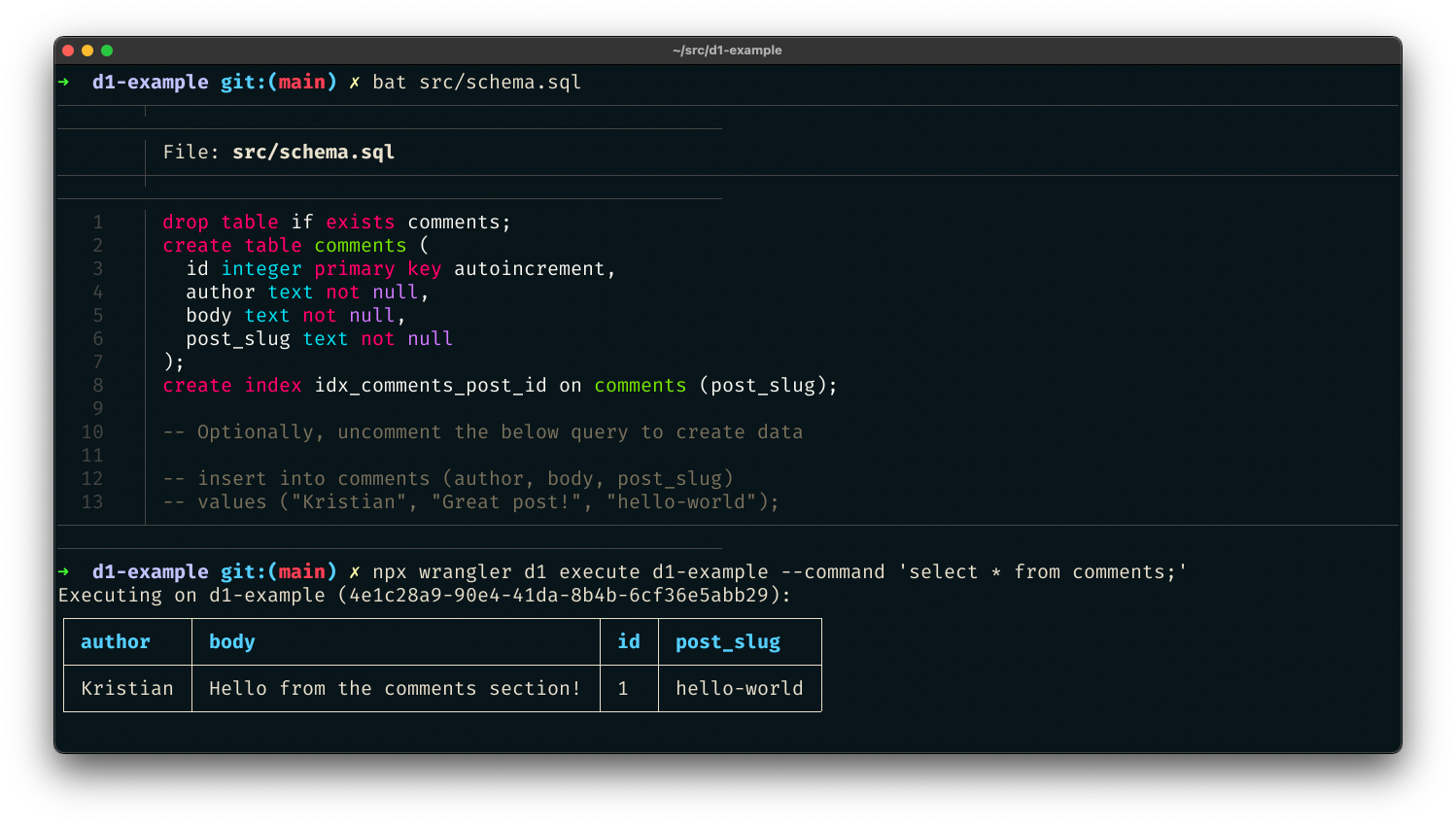
Sie können auch eine SQL-Datei übergeben – ideal für das anfängliche Data Seeding mit einem einzigen Befehl. Erstellen Sie src/schema.sql, um eine neue comments-Tabelle für unser Projekt zu erstellen:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
Nachdem Sie die Datei erstellt haben, führen Sie die Schemadatei gegen die D1-Datenbank aus, indem Sie sie mit dem Flag --file übergeben:
$ wrangler d1 execute d1-example --file src/schema.sql
Wir haben mit nur wenigen Befehlen eine SQL-Datenbank erstellt und sie mit ersten Daten gefüllt. Jetzt können wir eine Route zu unserer Workers-Funktion hinzufügen, um Daten aus dieser Datenbank abzurufen. Basierend auf unserer wrangler.toml-Konfiguration ist die D1-Datenbank jetzt über die DB-Bindung zugänglich. In unserem Code können wir mit der Bindung SQL-Statements vorbereiten und ausführen, zum Beispiel um Kommentare abzurufen:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
In dieser Funktion akzeptieren wir einen slug-URL-Abfrageparameter und richten ein neues SQL-Statement ein, in dem wir alle Kommentare mit einem passenden post_slug-Wert zu unserem Abfrageparameter auswählen. Wir können sie dann als einfache JSON-Antwort zurückgeben.
Bis jetzt haben wir nur Lesezugriff auf unsere Daten eingerichtet. Aber das „Einfügen“ von Werten in SQL ist natürlich auch möglich. Definieren wir also eine weitere Funktion, die das POST-ing an einen Endpunkt ermöglicht, um einen neuen Kommentar zu erstellen:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
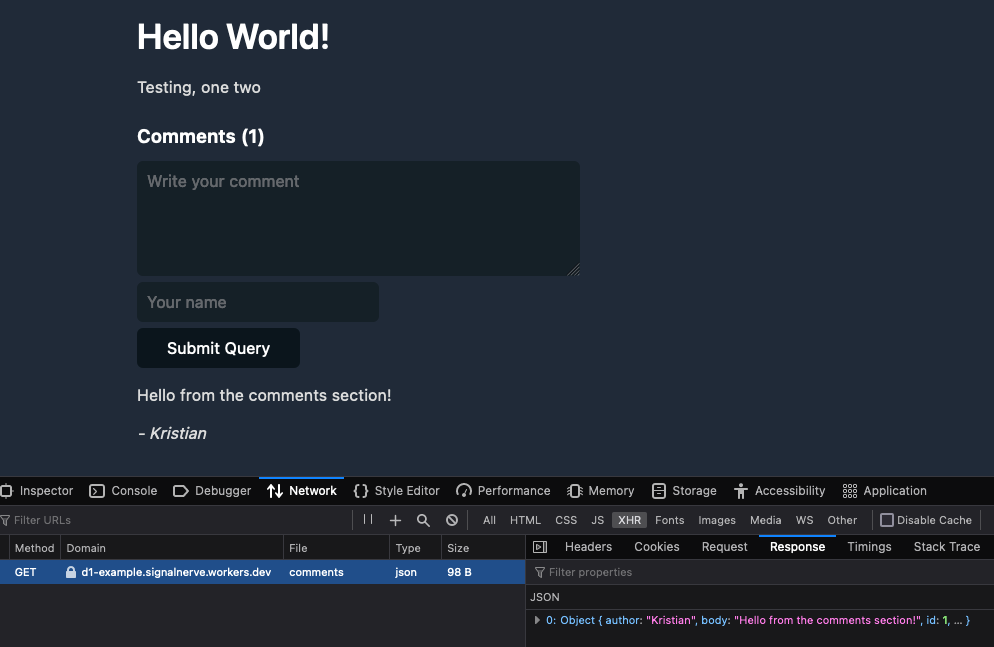
In diesem Beispiel haben wir eine Kommentar-API für einen Blog erstellt. Den Quellcode für diese von D1 betriebene Kommentar-API finden Sie unter cloudflare/templates/worker-d1-api.
Fazit
Einer der spannendsten Punkte an D1 ist die Möglichkeit, bestehende Anwendungen oder Websites mit dynamischen, relationalen Daten zu erweitern. Als ehemaliger Ruby on Rails-Entwickler vermisse ich in der Welt der JavaScript- und Serverless-Entwicklungstools vor allem die Möglichkeit, in kurzer Zeit vollständige datengesteuerte Anwendungen zu erstellen, ohne ein Experte für die Verwaltung von Datenbankinfrastruktur zu sein. Mit D1 und seiner einfachen Anbindung an SQL-basierte Daten können wir echte datengesteuerte Anwendungen erstellen, ohne bei der Performance oder der Entwicklererfahrung Abstriche machen zu müssen.
Diese Verschiebung passt gut zur Verbreitung von statischen Websites in den letzten Jahren (mit Tools wie Hugo oder Gatsby). Ein Blog, der mit einem statischen Website-Generator wie Hugo erstellt wurde, ist unglaublich leistungsfähig – er wird in Sekundenschnelle mit kleinen Assets erstellt.
Aber wenn Sie ein Tool wie WordPress gegen einen statischen Website-Generator eintauschen, können Sie Ihrer Website keine dynamischen Informationen hinzufügen. Viele Entwickler haben dieses Problem überbrückt, indem sie ihre Build-Prozesse noch komplexer gestaltet haben: Abrufen und Abfragen von Daten und Generieren von Seiten, die diese Daten als Teil des Builds verwenden.
Diese zusätzliche Komplexität im Erstellungsprozess soll den Mangel an Dynamik in den Anwendungen beheben, aber wirklich dynamisch wird es trotzdem nicht. Anstatt neue Daten bei ihrer Erstellung abzurufen und anzuzeigen, wird die Anwendung bei jeder Datenänderung neu erstellt und eingesetzt, so dass sie wie eine dynamische Echtzeitdarstellung der Daten wirkt. Ihre Anwendung kann statisch bleiben, und die dynamischen Daten befinden sich geografisch in der Nähe Ihrer Websitenutzer und sind über eine abfragbare und expressive API zugänglich.