
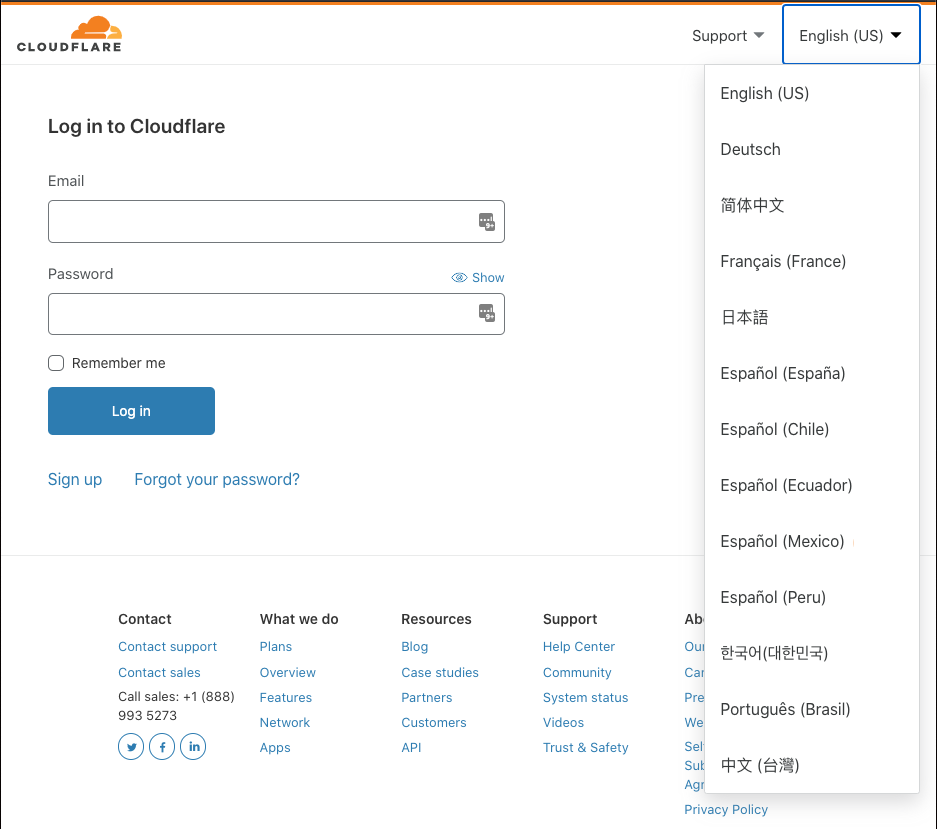
Das Cloudflare-Dashboard unterstützt jetzt vier neue Sprachen (und mehrere Sprachregionen): Spanisch (mit den länderspezifischen Variationen: Chile, Ecuador, Mexiko, Peru und Spanien), brasilianisches Portugiesisch, Koreanisch und Chinesisch (traditionell). Unser Kundenstamm erstreckt sich über die ganze Welt und ist dementsprechend vielfältig. Wenn wir ein besseres Internet aufbauen wollen, müssen wir den Kunden unsere Produkte und Dienstleistungen in ihrer Muttersprache anbieten.
Seit dem letzten Jahr arbeiten wir bei Cloudflare tatkräftig daran, unser Dashboard in verschiedene Sprachen zu übertragen. Ende 2019 haben wir unsere erste weitere Sprache neben dem amerikanischem Englisch eingeführt: Deutsch. Ende März 2020 haben wir drei weitere Sprachen veröffentlicht: Französisch, Japanisch und Chinesisch (vereinfacht). Wenn Sie das Dashboard in einer dieser Sprachen verwenden möchten, können Sie Ihre Sprachpräferenz oben rechts auf dem Cloudflare-Dashboard ändern. Die gewählte Einstellung wird gespeichert und in allen Sitzungen verwendet.
Allen, die mit Internationalisierung und Lokalisierung nicht vertraut sind, soll dieser Blogeintrag helfen, den Prozess besser zu verstehen. Außerdem möchte ich berichten, wie wir die Internationalisierung und Lokalisierung unserer Anwendung zu einem standardisierten und wiederholbaren Prozess gemacht haben – und Ihnen nebenbei ein paar Tipps geben, wie Sie die Aufgabe für Ihr eigenes Unternehmen realisieren können.
Die Reise geht los
Der erste Schritt Richtung Internationalisierung ist die Externalisierung aller Strings in Ihrer Anwendung. Konkret bedeutet dies, dass Sie jeden Text, der von einem Nutzer gelesen werden könnte, aus Ihrem Anwendungscode in separate, eigenständige Dateien extrahieren. Dies muss aus verschiedenen Gründen geschehen:
- So können Übersetzungsteams an der Übersetzung dieser Strings arbeiten, ohne den Anwendungscode sehen oder bearbeiten zu müssen.
- Die meisten Übersetzer verwenden in der Regel Übersetzungsmanagement-Anwendungen, die Aspekte des Arbeitsablaufs automatisieren und ihnen nützliche Werkzeuge zur Verfügung stellen (beispielsweise Translation Memory, Änderungsverfolgung und eine Reihe nützlicher Analyse- und Formatierungswerkzeuge). Diese Anwendungen benötigen standardisierte Textformate (wie json-, xml-, md- oder csv-Dateien).
Aus technischer Sicht ermöglicht es die Trennung von Anwendungscode und Übersetzungen, Änderungen an Strings vorzunehmen, ohne Code neuzukompilieren und/oder erneut bereitstellen zu müssen. In unserer react-basierten Anwendung lief die Externalisierung der meisten unserer Strings darauf hinaus, Codeblöcke wie diesen zu bearbeiten:
<Button>Cancel</Button>
<Button>Next</Button>
Zu:
<Button><Trans id="signup.cancel" /></Button>
<Button><Trans id="signup.next" /></Button>
// And in a separate catalog.json file for en_US:
{
"signup.cancel": "Cancel",
"signup.next": "Next",
// ...many more keys
}
Die oben gezeigte <Trans>-Komponente ist der grundlegende i18n-Baustein in unserer Anwendung. In diesem Schema werden übersetzte Zeichenketten in großen Wörterbüchern aufbewahrt, die durch eine Übersetzungs-ID verschlüsselt sind. Wir nennen diese Wörterbücher „Übersetzungskataloge“ und für jede von uns unterstützte Sprache gibt es eine Reihe von Übersetzungskatalogen.
Zur Laufzeit sucht die <Trans>-Komponente die Übersetzung im richtigen Katalog für den angegebenen Key heraus und fügt diese Übersetzung dann in die Seite ein (über das DOM). Der gesamte statische Text einer Anwendung kann mit einfachen Transformationen wie diesen externalisiert werden.
Wenn jedoch dynamische Daten mit statischem Text vermischt werden müssen, sieht die Lösung etwas komplizierter aus. Schauen Sie sich das folgende vermeintlich einfache Beispiel an, das aber mit potentiellen i18n-Fehlern durchsetzt ist:
<span>You've selected { totalSelected } Page Rules.</span>
Es mag verlockend sein, diesen Satz zu externalisieren, indem man ihn in einige wenige Teile aufbricht, etwa so:
<span>
<Trans id="selected.prefix" /> {totalSelected } <Trans id="pageRules" />
</span>
// English catalog.json
{
"selected.prefix": "You've selected",
"pageRules": "Page Rules",
// ...
}
// Japanese catalog.json
{
"selected.prefix": "選択しました",
"pageRules": "ページ ルール",
// ...
}
// German catalog.json
{
"selected.prefix": "Sie haben ausgewählt",
"pageRules": "Page Rules",
// ...
}
// Portuguese (Brazil) catalog.json
{
"selected.prefix": "Você selecionou",
"pageRules": "Page Rules",
// ...
}
Damit scheint die Aufgabe erledigt und sogar elegant gelöst. Schließlich sind die Strings selected.prefix und pageRules.suffix doch sicherlich wiederverwendbar. Leider erweist sich das Zerschneiden von Sätzen und das anschließende Zusammensetzen der übersetzten Bits als der größte Fallstrick, wenn Strings für die Internationalisierung externalisiert werden.
Das Problem ist, dass bei der Übersetzung die verschiedenen Wörter in einem Satz auf verschiedene Weise verändert werden können, je nach Kontexts (Singular vs. Plural, Artikel, die Übereinstimmung von Subjekt und Verb usw.). Diese Aspekte variieren stark von Sprache zu Sprache, genau wie die Satzstellung. Beispielsweise folgt der Englische Satz „We like them“ der Satzstellung Subjekt-Verb-Objekt. In anderen Sprachen kann die Satzstellung variieren: Subjekt-Objekt-Verb („We them like“), Verb-Subjekt-Objekt („Like we them“) oder kann sogar ganz anders aussehen. Aufgrund dieser nuancierten Unterschiede zwischen Sprachen entstehen fast immer Lokalisierungsfehler, sobald die zerschnittenen Satzteile wieder zu einem Satz verkettet werden.
Das obige Code-Beispiel enthält tatsächliche Übersetzungen, die wir von unseren Übersetzungsteams erhalten haben, als wir ihnen „You’ve selected“ und "Page Rules" als separate Strings zur Verfügung gestellt haben. So würde dieser Satz aussehen, wenn er so in den verschiedenen Sprachen wiedergegeben würde:
| Sprache | Übersetzung |
|---|---|
| Japanisch | 選択しました { totalSelected } ページ ルール。 |
| Deutsch | Sie haben ausgewählt { totalSelected } Page Rules |
| Portugiesisch (Brasilien) | Você selecionou { totalSelected } Page Rules. |
Zum Vergleich gaben wir den Übersetzungsteams den Satz auch als einzelnen String mit einem Platzhalter für die Variable. Hier ist das Ergebnis:
| Sprache | Übersetzung |
|---|---|
| Japanisch | %{ totalSelected } 件のページ ルールを選択しました。 |
| Deutsch | Sie haben %{ totalSelected } Page Rules ausgewählt. |
| Portugiesisch (Brasilien) | Você selecionou %{ totalSelected } Page Rules. |
Wie Sie sehen können, sind die Übersetzungen für Japanisch und Deutsch anders aufgebaut. Wir haben es mit einem Lokalisierungsfehler zu tun.
Um zu gewährleisten, dass die Übersetzer den wahren Sinn Ihres Textes originalgetreu wiedergeben können, ist es wichtig, dass jeder Satz als ein ganzer externalisierter String erhalten bleibt. Unsere <Trans>-Komponente erlaubt die einfache Injektion von Werten in Template-Strings, was uns genau dies ermöglicht:
<span>
<Trans id="pageRules.selectedForDeletion" values={{ count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ count } Page Rules.",
// ...
}
// Japanese catalog.json
{
"pageRules.selected": "%{ count } 件のページ ルールを選択しました。",
// ...
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ count } Page Rules ausgewählt.",
// ...
}
// Portuguese(Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ count } Page Rules.",
// ...
}
Auf diese Weise erhalten die Übersetzer den vollständigen Kontext des Satzes und können alle Wörter grammatikalisch korrekt übersetzen.
Vielleicht ist Ihnen ein weiteres potenzielles Problem aufgefallen. Was passiert in diesem Beispiel, wenn totalSelected nur 1 beträgt? Mit dem obigen Code würde der Nutzer „Sie haben 1 Page Rules zum Löschen ausgewählt“ sehen. Wir müssen den Satz bedingt pluralisieren, basierend auf dem Wert der dynamischen Daten. Das passiert sogar ziemlich oft und unsere <Trans>-Komponente handhabt dies automatisch über die smart_count-Funktion:
<span>
<Trans id="pageRules.selectedForDeletion" values={{ smart_count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ smart_count } Page Rule. |||| You've selected %{ smart_count } Page Rules.",
}
// Japanese catalog.json
{
"pageRules.selected": "%{ smart_count } 件のページ ルールを選択しました。 |||| %{ smart_count } 件のページ ルールを選択しました。",
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ smart_count } Page Rule ausgewählt. |||| Sie haben %{ smart_count } Page Rules ausgewählt.",
}
// Portuguese (Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ smart_count } Page Rule. |||| Você selecionou %{ smart_count } Page Rules.",
}
Hier werden die Singular- und Pluralversionen durch |||| abgegrenzt. <Trans> wählt je nach dem Wert der eingegebenen totalSelected-Variabel automatisch die richtige Übersetzung aus.
Ein weiterer Stolperstein tritt auf, wenn Markup mit einem Textblock vermischt wird, den wir als einen einzelnen String externalisieren möchten. Was passiert zum Beispiel, wenn ein Satzteil in Ihrem Satz ein Link zu einer anderen Seite sein soll?
<VerificationReminder>
Don't forget to <Link>verify your email address.</Link>
</VerificationReminder>
Um diesen Anwendungsfall zu lösen, muss die <Trans>-Komponente die Injektion beliebiger Elemente in Platzhalter in einem Übersetzungsstring ermöglichen, wie z. B:
<VerificationReminder>
<Trans id="notification.email_verification" Components={[Link]} componentProps={[{ to: '/profile' }]} />
</VerificationReminder>
// catalog.json
{
"notification.email_verification": "Don't forget to <0>verify your email address.</0>",
// ...
}
In diesem Beispiel wird die <Trans>-Komponente Platzhalterelemente (<0>,<1>, usw.) durch Instanzen des Komponententyps ersetzen, die sich bei diesem Index in der Komponenten-Anordnung befinden. Sie gibt auch alle Daten weiter, die in componentProps zu dieser Instanz festgelegt sind. Das obige Beispiel würde in React auf Folgendes hinauslaufen:
// en-US
<VerificationReminder>
Don't forget to <Link to="/profile">verify your email address.</Link>
</VerificationReminder>
// es-ES
<VerificationReminder>
No olvide <Link to="/profile">verificar la dirección de correo electrónico.</Link>
</VerificationReminder>
Sicherheit an dritter Stelle
Die oben skizzierte Funktionalität reichte uns aus, um unsere Strings zu externalisieren. Es führte jedoch zuweilen zu sperrigem, sich wiederholendem Code, den man leicht durcheinander bringen konnte. Einige Fallstricke wurden schnell deutlich.
Der erste Fallstrick: Kleine fest einprogrammierte Strings konnten nun leichter vor aller Augen verborgen werden. Da sie für einen Entwickler erst nach der Übersetzung der restlichen Seite deutlich sichtbar wurden, dauerte die Feedback-Schleife bei der Suche nach diesen Strings oft Tage oder Wochen. Eine gängige Lösung zur Behebung dieser Probleme ist die Einführung eines Pseudolokalisierungsmodus. Während der Entwicklung wandelt es alle ordnungsgemäß internationalisierten Strings um, indem jedes Zeichen durch ein ähnlich aussehendes Unicode-Zeichen ersetzt wird.
Zum Beispiel könnte You've selected 3 Page Rules. umgewandelt werden in Ýôôú'Ʋè ƨèℓèçƭèδ 3 Þáϱè Rúℓèƨ.
Eine weitere praktische Funktion eines Pseudolokalisierungsmodus ist die Möglichkeit, alle Strings um einen festen Betrag zu verkleinern oder zu verlängern, um Unterschiede in der Inhaltsbreite einzuplanen. Hier ist derselbe pseudolokalisierte Satz um 50 % verlängert: Ýôôú'Ʋè ƨèℓèçƭèδ 3 Þáϱè Rúℓèƨ. ℓôřè₥ ïƥƨú₥ δô. Das hilft sowohl Entwicklern als auch Designer, zu erkennen, an welchen Stellen die Länge des Inhalts möglicherweise ein Problem darstellen könnte. Wir erkannten dieses Problem erstmals bei der deutschen Übersetzung, da deutsche Wörter manchmal etwas länger als englische sind.
Dies führte dazu, dass an vielen Stellen der Text in Seitenelementen überlaufen würde, wie z. B. in dieser Schaltfläche, die im Englischen nur knapp „Add“ heißt:
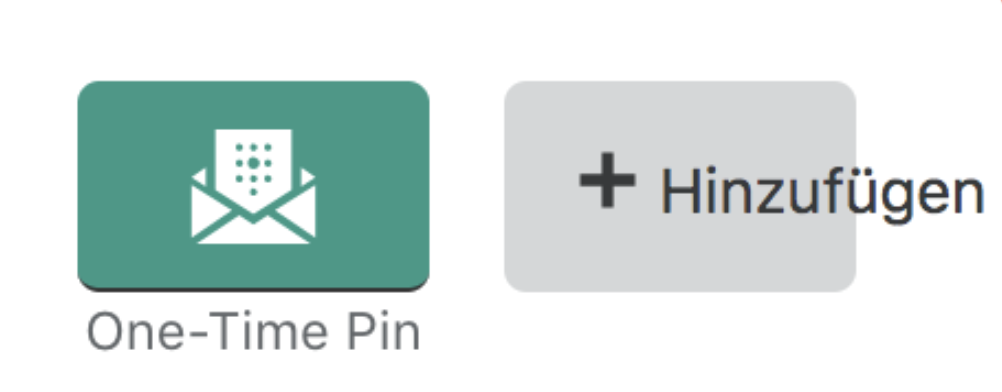
Es gibt nicht viele einfache Möglichkeiten, dieses Problem zu lösen, ohne die Nutzererfahrung zu beeinträchtigen.
Um beste Ergebnisse zu erzielen, muss eine variable Inhaltsbreite in das Design selbst einfließen. Da die Behebung dieser Fehler oft bedeutet, dass die Software zurückgeschickt werden muss, um ein neues Design anzufordern, ist der Prozess tendenziell zeitaufwändig. Wenn Sie sich noch keine Gedanken über die Inhaltsgestaltung im Allgemeinen gemacht haben, kann eine Internationalisierung ein guter Zeitpunkt sein, um damit anzufangen. Mit Standards und Einheitlichkeit rund um den Text, der für verschiedene Elemente in Ihrer Anwendung genutzt wird, können Sie nicht nur die Anzahl der zu übersetzenden Wörter reduzieren, sondern auch die inhaltlichen Fallstricke bei der Verwendung eines neuen Satzes vermeiden.
Die andere Fallstrick, auf den wir gestoßen sind, war, dass die Übersetzungs-IDs – insbesondere wenn sie lang und voller Wiederholungen waren – sehr anfällig für Tippfehler sind.
Raten Sie, welcher dieser Übersetzungskeys unsere App unterbrechen wird: traffic.load_balancing.analytics.filters.origin_health_title oder traffic.load_balancing.analytics.filters.origin_heath_title?
Eingebettet zwischen Hunderten von anderen veränderten Zeilen sind sie bei der Überprüfung des Codes schwer auszumachen. Die meisten Anwendungen haben ein Fallback, damit fehlende Übersetzungen nicht zu einem Seitenumbruchfehler führen. Infolgedessen könnte ein Fehler wie dieser völlig unbemerkt bleiben, wenn er gut genug versteckt ist (etwa in einem Hilfetext-Flyout).
Glücklicherweise konnten wir mit einem wachsenden Prozentsatz unserer Codebasis in TypeScript den Type-Checker nutzen, um den Entwicklern beim Schreiben des Codes Feedback zu geben. Hier ist ein Beispiel, bei dem unser Code-Editor uns hilfsbereit einen roten Unterstrich anzeigt, um signalisieren, dass die id-Eigenschaft ungültig ist (aufgrund des fehlenden „l“):

Das macht zum einen Probleme offensichtlicher. Zum anderen bedeutet es auch, dass Verstöße dazu führen würden, dass Builds scheiterten und schlechter Code gar nicht erst in die Codebasis gelangen konnte.
Dateien der Sprachregionen skalieren
Am Anfang beginnen Sie wahrscheinlich mit einer Übersetzungsdatei pro Sprachregion, das Sie unterstützen. Außerdem kann das Benennungsschema, das Sie für Ihre Keys verwenden, mehr oder weniger einfach bleiben. Wenn Ihre Anwendung wächst, wird Ihre Übersetzungsdatei zu groß und muss in separate Dateien aufgeteilt werden. Zu große Dateien überfordern Übersetzungsmanagement-Anwendungen oder, wenn sie nicht überprüft werden, auch Ihren Code-Editor. Alle unsere Übersetzungsstrings (ohne Keys) ergeben in einer einzigen Datei etwa 50.000 Wörter. Zum Vergleich: Das ist ungefähr die gleiche Textmenge wie ein Exemplar von „Per Anhalter durch die Galaxis“ oder „Schlachthof 5“.
Wir teilen unsere Übersetzungen in eine Reihe von „Katalog“-Dateien auf, die in etwa den Feature-Vertikalen entsprechen (wie Firewall oder Cloudflare Workers). Das funktioniert gut für unsere Entwickler, so weiß man, wo man Strings findet, und die Zeilenanzahl eines Übersetzungskatalogs wird auf eine überschaubare Länge beschränkt. Es funktioniert auch gut für die externen Übersetzungsteams, da eine einzige vertikale Funktion eine gute Arbeitseinheit für einen Übersetzer (oder ein kleines Team) darstellt.
Zusätzlich zu den Katalogen für einzelne Funktionen haben wir eine gemeinsame Katalogdatei, die Strings enthält, die in der gesamten Anwendung wiederverwendet werden. So können wir die IDs kurz halten ( allgemein.löschen im Vergleich zu irgendeine.Seite.irgendeinen_Tab.einige_Featuresachen.löschen ) und Duplizierung unwahrscheinlicher machen, da Entwickler gewöhnlich den gemeinsamen Katalog überprüfen, bevor sie neue Strings hinzufügen.
Bibliotheken
Bislang haben wir ausführlich beschrieben, was unsere <Trans>-Komponente ist und was sie tun kann. Schauen wir uns jetzt an, wie sie gebaut wird.
Es überrascht vielleicht nicht, dass wir das Rad nicht neu erfinden und eine i18n-Bibliothek nicht von Grund auf entwickeln wollten. Aufgrund früherer Bemühungen, die in Backbone geschriebenen Legacy-Teile unserer Anwendung zu internationalisieren, benutzten wir bereits die Polyglot Library von Airbnb, eine „kleine i18n-Hilfsbibliothek, geschrieben in JavaScript“, die unter anderem „eine einfache Lösung für Interpolation und Pluralisierung bietet, basierend auf der Erfahrung von Airbnb beim Einbauen von i18n-Funktionalität zu seine Backbone.js und Node-Apps“.
Wir sahen uns einige der beliebtesten Bibliotheken an, die speziell für die Internationalisierung von React-Anwendungen entwickelt worden waren, entschieden uns aber letztendlich für Polyglot. Wir entwickelten unsere eigene <Trans>-Komponente, um die Lücke zu React zu überbrücken. Wir haben aus mehreren Gründen für diesen Weg entschieden:
- Wir wollten den älteren Code in unserer Anwendung nicht re-internationalisieren, um zu einer neuen i18n-Support-Bibliothek zu migrieren.
- Wir wollten auch nicht den kombinierten Aufwand der Unterstützung von zwei verschiedenen i18n-Schemata für neuen vs. für älteren Code.
- Eine Transkomponente zu schreiben, gab uns die Flexibilität, das Interface zu entwickeln, das wir haben wollten. Da Trans so gut wie überall eingesetzt wird, wollten wir sicherstellen, dass es für die Entwickler so ergonomisch wie möglich ist.
Wenn Sie gerade erst mit i18n in einer neuen react-basierten Webanwendung beginnen, dann sind react-intl und i18n-next zwei beliebte Bibliotheken, die eine Komponente bieten, die der oben beschriebenen <Trans> ähnelt.
Der größte Schmerzpunkt der <Trans>-Komponente wie oben beschrieben ist, dass Strings in einer von Ihrem Quellcode getrennten Datei aufbewahrt werden müssen. Das Wechseln zwischen mehreren Dateien während Sie neuen Code schreiben oder bestehende Features modifizieren, kann einem einfach nur auf die Nerven. Noch mehr nervt es, wenn Übersetzungsdateien weit entfernt in der Verzeichnisstruktur gehalten werden, wie es oft notwendig ist.
Es gibt einige neue i18n-Bibliotheken wie jslingui, die dieses Problem durch einen extraktionsbasierten Ansatz bei der Handhabung von Übersetzungskatalogen umgehen. In diesem Schema verwenden Sie nach wie vor eine <Trans>-Komponente, aber Sie behalten Ihre Strings in der Komponente selbst und nicht in einem separaten Katalog:
<span>
<Trans>Hmm... We couldn't find any matching websites.</Trans>
</span>
Ein Tool, das Sie zur Erstellungszeit ausführen, übernimmt dann die Arbeit, alle diese Zeichenfolgen zu finden und in Kataloge zu extrahieren. Das oben genannte Beispiel würde dann zu den folgenden generierten Katalogen führen:
// locales/en_US.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... We couldn't find any matching websites.",
}
// locales/de_DE.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... Wir konnten keine übereinstimmenden Websites finden."
}
Der offensichtliche Vorteil dieses Ansatzes besteht darin, dass wir es nicht mehr mit separaten Dateien zu tun haben! Der andere Vorteil besteht darin, dass es keinen Bedarf mehr für Type-Checking-IDs gibt, da Tippfehler nicht mehr vorkommen können.
Allerdings gab es – zumindest für unseren Anwendungsfall – einige Nachteile.
Erstens sehen menschliche Übersetzer manchmal gerne den Kontext der Übersetzungskeys. Kontext hilft bei der Organisation und weist darauf hin, was der String tun soll.
Und obwohl wir uns keine Sorgen mehr über Tippfehler in den Übersetzungsidentifikationen machen müssen, sind wir genauso anfällig für leichte Abweichungen in den Texten (z. B. „Verify your email“ und „Verify your e-mail“). Das ist fast noch schlimmer, da es in diesem Fall zu einer Beinahe-Duplizierung führen würde, die sich nur schwer entdecken lässt. Und wir müssten auch dafür bezahlen.
Mit welchem Tech-Stack Sie auch immer arbeiten, es gibt wahrscheinlich einige i18n-Bibliotheken, die Ihnen dabei helfen können. Welche Option die richtige ist, hängt stark von den technischen Zwängen Ihrer Anwendung und vom Kontext der Ziele und der Kultur Ihres Teams ab.
Zahlen, Daten und Uhrzeiten
Als wir weiter oben über das Einfügen von übersetzten Datenstrings sprachen, haben wir einen wichtigen Punkt ausgelassen: Die Daten, die wir einfügen, müssen möglicherweise auch so formatiert werden, dass sie den lokalen Gewohnheiten des Nutzers entsprechen. Dies gilt für Daten, Uhrzeiten, Zahlen, Währungen und einige andere Arten von Daten.
Nehmen wir unser einfaches Beispiel von vorhin:
<span>You've selected { totalSelected } Page Rules.</span>
Ohne richtige Formatierung wird dies bei kleinen Zahlen korrekt angezeigt, aber sobald es in die Tausende geht, werden Lokalisierungsprobleme auftreten. Die Art und Weise, wie Ziffern gruppiert und mit Symbolen getrennt werden variiert je nach Kultur. Hier sehen Sie, wie dreihunderttausend und drei Hundertstel in einigen verschiedenen Sprachregionen formatiert werden:
| Sprache (Land) | Code | Formatierte Daten |
|---|---|---|
| Deutsch (Deutschland) | de-DE | 300.000,03 |
| English (US) | en-US | 300,000.03 |
| English (GB) | en-GB | 300,000.03 |
| Spanisch (Spanien) | es-ES | 300.000,03 |
| Spanisch (Chile) | es-CL | 300.000,03 |
| Französisch (Frankreich) | fr-FR | 300 000,03 |
| Hindi (Indien) | hi-IN | 3,00,000.03 |
| Indonesich (Indonesien) | in-ID | 300.000,03 |
| Japanisch (Japan) | ja-JP | 300,000.03 |
| Koreanisch (Südkorea) | ko-KR | 300,000.03 |
| Portuguese (Brazil) | pt-BR | 300.000,03 |
| Portugiesisch (Portugal) | pt-PT | 300 000,03 |
| Russisch (Russland) | ru-RU | 300 000,03 |
Die Art und Weise, wie Daten formatiert werden unterscheidet sich von Land zu Land erheblich. Wenn Sie Ihre Benutzeroberfläche hauptsächlich für ein US-amerikanisches Publikum entwickelt haben, zeigen Sie die Daten wahrscheinlich auf eine Art und Weise an, die für Nutzer von fast jedem anderen Land der Welt fremd und möglicherweise unintuitiv erscheint. Unter anderem kann die Datumsformatierung in Bezug auf die Wahl des Trennzeichens variieren (ob einzelne Ziffern mit Nullen aufgefüllt werden) und auch Tages-, Monats- und Jahreszahlen können unterschiedlich angeordnet sein. Im Folgenden wird gezeigt, wie der 4. März des laufenden Jahres in verschiedenen Sprachregionen formatiert wird:
| Sprache (Land) | Code | Formatierte Daten |
|---|---|---|
| Deutsch (Deutschland) | de-DE | 4.3.2020 |
| English (US) | en-US | 3/4/2020 |
| English (GB) | en-GB | 04/03/2020 |
| Spanisch (Spanien) | es-ES | 4/3/2020 |
| Spanisch (Chile) | es-CL | 04-03-2020 |
| Französisch (Frankreich) | fr-FR | 04/03/2020 |
| Hindi (Indien) | hi-IN | 4/3/2020 |
| Indonesich (Indonesien) | in-ID | 4/3/2020 |
| Japanisch (Japan) | ja-JP | 2020/3/4 |
| Koreanisch (Südkorea) | ko-KR | 2020. 3. 4. |
| Portugiesisch (Brasilien) | pt-BR | 04/03/2020 |
| Portugiesisch (Portugal) | pt-PT | 04/03/2020 |
| Russisch (Russland) | ru-RU | 04.03.2020 |
Auch das Uhrzeitformat variiert erheblich. Hier sehen Sie, wie die Urzeit in verschiedenen Sprachregionen formatiert wird:
| Sprache (Land) | Code | Formatierte Daten |
|---|---|---|
| Deutsch (Deutschland) | de-DE | 14:02:37 |
| English (US) | en-US | 2:02:37 PM |
| English (GB) | en-GB | 14:02:37 |
| Spanisch (Spanien) | es-ES | 14:02:37 |
| Spanisch (Chile) | es-CL | 14:02:37 |
| Französisch (Frankreich) | fr-FR | 14:02:37 |
| Hindi (Indien) | hi-IN | 2:02:37 pm |
| Indonesich (Indonesien) | in-ID | 14.02.37 |
| Japanish (Japan) | ja-JP | 14:02:37 |
| Koreanisch (Südkorea) | ko-KR | 오후 2:02:37 |
| Portugiesisch (Brasilien) | pt-BR | 14:02:37 |
| Portugiesisch (Portugal) | pt-PT | 14:02:37 |
| Russisch (Russland) | ru-RU | 14:02:37 |
Bibliotheken für den Umgang mit Zahlen, Daten und Uhrzeiten
All diese Datentypen für alle unterstützten Sprachregionen im richtigen Format bereitzustellen, ist keine leichte Aufgabe. Glücklicherweise gibt es eine Reihe ausgereifter, kampferprobter Bibliotheken, die Ihnen dabei helfen können.
Als wir unser Projekt starteten, benutzten wir intensiv die Moment.js Bibliothek für Datums- und Uhrzeitformatierung. Diese handliche Bibliothek abstrahiert die Details der Formatierung von Datumsangaben in verschiedenen Längen („Jul 9th 20“, „July 9th 2020“ vs. „Donnerstag“), zeigt relative Datumsangaben an („vor 2 Tagen“) und vieles mehr. Da fast alle unsere Datumsangaben aus Gründen der Lesbarkeit bereits über Moment.js formatiert wurden und da Moment.js bereits i18n-Unterstützung für eine große Anzahl von Sprachregionen bietet, konnten wir mit sehr geringem Aufwand einfach einige Schalter umlegen und die Datumsangaben richtig lokalisieren.
Es gibt einige heftige Kritiken an Moment.js (hauptsächlich in Bezug auf überflüssigen Ballast). Aber letztlich summierten sich die Vorteile eines Wechsel zu einer Alternative mit geringerem Platzbedarf nicht im Vergleich zu den Kosten, jedes Datums und jede Uhrzeit zu überarbeiten.
Die Zahlen waren eine ganz andere Geschichte. Wie Sie sich vielleicht vorstellen können, zeigen wir Tausende von rohen, unformatierten Zahlen auf dem gesamten Dashboard an. Sie aufzuspüren war ein mühsamer und oft manueller Prozess.
Um die eigentliche Formatierung der Zahlen zu handhaben, verwendeten wir die Intl API (die durch den ECMAScript-Standard definierte Internationalisierungsbibliothek):
var number = 300000.03;
var formatted = number.toLocaleString('hi-IN'); // 3,00,000.03
// This probably works in the browser you're using right now!
Glücklicherweise ist die Browserunterstützung für Intl in den letzten Jahren ein gutes Stück vorangekommen und alle modernen Browser bieten volle Unterstützung.
Einige moderne JavaScript-Engines wie V8 bevorzugen sogar statt selbst gehosteten JavaScript-Implementierungen dieser Bibliotheken lieber C++ basierte Builtins, was zu einer erheblichen Beschleunigung führt.
Die Unterstützung für ältere Browser kann jedoch lückenhaft sein. Hier ist ein einfache Demo-Site (Quellcode), mit Cloudflare Workers gebaut, die zeigt, wie Daten, Uhrzeiten und Zahlen in einer Handvoll von Sprachregionen angezeigt werden.
Einige Kombinationen aus alten Browsern und Betriebssystemen führen zu weniger als idealen Ergebnissen. So werden beispielsweise die gleichen Datums- und Uhrzeitangaben von oben unter Windows 8 mit IE 10 gerendert:
 |
 |
Wenn Sie ältere Browser unterstützen müssen, kann dies mit einem Polyfill gelöst werden.
Übersetzung
Mit der Externalisierung aller Strings und der sorgfältigen Formatierung aller eingespeisten Daten nach lokalen Standards ist der Großteil der technischen Arbeit abgeschlossen. An diesem Punkt können wir behaupten, dass wir unsere Anwendung internationalisiert haben, da wir sie so angepasst haben, dass sie leicht lokalisierbar ist.
Als nächstes kommt der Lokalisierungsprozess, bei dem wir tatsächlich unterschiedliche Inhalte auf der Grundlage der Sprache und der kulturellen Normen der Nutzer erstellen.
Das ist keine kleine Leistung. Wie bereits erwähnt, haben die Strings in unserer Anwendung zusammengenommen die Länge eines kleinen Romans. Es erfordert ein erhebliches Maß an Koordination und menschlichem Fachwissen, um eine übersetzte Kopie zu erstellen, die sowohl die Informationen originalgetreu erfasst als auch den Nutzer auf vertraute Weise anspricht.
Es gibt viele Möglichkeiten, die Übersetzungsarbeit zu erledigen: Einsatz mehrsprachiger Mitarbeiter, Vergabe der Arbeit an einzelne Übersetzer, Agenturen oder sogar die Einstellung interner Übersetzungsteams. Wofür man sich auch entscheidet, es muss ein reibungsloser Prozess sowohl für die Signalisierung des Arbeitsablaufs als auch für die Bewegung von Assets zwischen den Übersetzungs- und Entwicklungsteams gegeben sein.
Ein gesundes i18n-Programm bietet Entwicklern eine Blackbox-Schnittstelle für den Prozess. Sie legen neue Strings in eine Übersetzungskatalogdatei ein und übergeben die Änderung. Und ohne weiteren Aufwand ihrerseits steht der von ihnen geschriebene Funktionscode wenige Tage später für alle unterstützten Sprachregionen in der Produktion zur Verfügung. In ähnlicher Weise bekommen die Übersetzer in einem gut geführten Prozess nichts von den Einzelheiten des Entwicklungsprozesses und der Anwendungsarchitektur mit. Sie erhalten Dateien, die sich leicht in ihre Tools laden lassen und klar angeben, welche Übersetzungsarbeit zu leisten ist.
Wie funktioniert das alles in der Praxis?
Wir verfügen über eine Reihe automatisierter Skripte, die bei Bedarf vom Lokalisierungsteam ausgeführt werden können, um eine Momentaufnahme unserer Lokalisierungskataloge für alle unterstützten Sprachen zu erstellen. Während dieses Prozesses findet Folgendes statt:
- JSON-Dateien werden aus Katalogdateien generiert, die in TypeScript erstellt wurden.
- Wenn neue Katalogdateien in Englisch hinzugefügt wurden, werden Platzhalterkopien für alle anderen unterstützten Sprachen erstellt.
- Platzhalterstrings werden für alle Sprachen hinzugefügt, wenn neue Strings zu unserem Basiskatalog hinzugefügt werden.
Von dort werden die Übersetzungskataloge über die Benutzeroberfläche oder automatisierte Aufrufe der API in das Übersetzungsmanagementsystem hochgeladen. Vor der Übergabe an die Übersetzer werden die Dateien vorverarbeitet, indem jeder neue String mit einer Translation Memory verglichen wird (einem Cache für bereits übersetzte Strings und Sub-Strings). Wenn eine Übereinstimmung gefunden wird, wird die vorhandene Übersetzung verwendet. Dies spart nicht nur Kosten, da Strings nicht erneut übersetzt werden müssen, sondern verbessert auch die Qualität, da sichergestellt wird, dass zuvor überprüfte und genehmigte Übersetzungen verwendet werden, wann immer möglich.
Angenommen, Ihre lokalisierten Dateien sehen am Ende in etwa so aus:
{
"verify.button": "Verify Email",
"other.verify.button": "Verify Email",
"verify.proceed.link": "Verify Email to proceed",
// ...
}
Hier haben wir Strings, die wortwörtlich dupliziert werden, sowie Unterstrings, die kopiert werden. Übersetzungsdienste berechnen pro Wort. Sie wollen nicht zweimal für etwas bezahlen und gleichzeitig riskieren, dass die Übersetzung nicht einheitlich wird. Zu diesem Zweck stellt eine gut gepflegte Translation Memory sicher, dass diese Strings in den Vorübersetzungsschritten berücksichtigt werden, bevor die Übersetzer die Datei überhaupt zu sehen bekommen.
Sobald der Übersetzungsauftrag als fertig markiert ist, kann es Stunden bis Wochen dauern, bis die Übersetzungsteams die Rückübersetzung fertig gestellt haben. Die Bearbeitungszeit hängt von einer Reihe von Faktoren ab wie dem Umfang des Auftrags, der Verfügbarkeit von Übersetzern und den Vertragsbedingungen. Für die Probleme in dieser Phase könnte man einen anderen, gleichlangen Blogartikel verfassen: das richtige Übersetzungsteam zusammenstellen, die Kosten kontrollieren, Qualität und Einheitlichkeit sicherstellen, sicherstellen, dass die Marke des Unternehmens richtig vermittelt wird, usw. Da der Schwerpunkt dieses Artikels weitgehend technischer Natur ist, werden wir die Details hier auslassen. Aber seien Sie gewiss, wenn Sie in diesem Teil einen Fehler machen, war Ihr ganzer Aufwand umsonst, selbst wenn Sie Ihre technischen Ziele erreicht haben.
Nachdem die Übersetzungsteams signalisiert haben, dass neue Dateien zur Abholung bereit stehen, werden die Assets vom Server abgerufen und an die richtigen Stellen im Anwendungscode entpackt. Wir führen dann eine Reihe von automatischen Prüfungen durch, um sicherzustellen, dass alle Dateien gültig und frei von Formatierungsproblemen sind.
Ein optionaler (aber dringend empfohlener) Schritt findet in dieser Phase statt: die kontextbezogene Überprüfung. Ein Team von Korrekturlesern betrachtet dann die übersetzten Inhalte in ihrem Kontext, um sicherzustellen, dass alles in seinem endgültigen Zustand perfekt ist. Besonders hilfreich sind dabei Support-Mitarbeiter, die sowohl mit dem Produkt sehr gut vertraut sind als auch die Zielsprache fließend beherrschen. An dieser Stelle ein großes Danke an allen Teammitglieder aus dem gesamten Unternehmen, die sich die Zeit und Mühe dafür genommen haben. Um dies für externe Auftragnehmer möglich zu machen, bereiten wir spezielle Vorschau-Versionen unserer Anwendung vor, wo sie die lokalisierten Inhalte testen können.
Und schon haben Sie alles, was Sie brauchen, um Ihren Nutzern auf der ganzen Welt eine lokalisierte Version Ihrer Anwendung zur Verfügung zu stellen.
Kontinuierliche Lokalisierung
Wäre es nicht schön, wenn man an dieser Stelle aufhören könnte? Aber was wir bis zu diesem Punkt besprochen haben, ist der Aufwand, der erforderlich ist, um alles einmal zu tun. Wie wir alle wissen, ändert sich der Code. Nach und nach werden neue Strings hinzugefügt und Strings werden geändert und gelöscht, wenn neue Features eingeführt und optimiert werden.
Übersetzungen sind ein sehr menschlichen Prozess, der oft die Arbeit von Menschen in verschiedenen Teilen der Welt erfordert. Daher ist die Bearbeitungszeit weniger eng gestreckt. Da unsere Veröffentlichungskadenz (täglich) oft schneller ist als diese Berbeitungszeit (2 bis 5 Tage), bedeutet dies, dass Entwickler, die Änderungen an Features vornehmen, eine Wahl treffen müssen: langsamer arbeiten, um dieser Kadenz zu entsprechen, oder etwas vor dem Lokalisierungszeitplan ohne vollständige Abdeckung liefern.
Um sicherzustellen, dass Funktionen, die vor der Übersetzung ausgeliefert werden, keine Fehler verursachen, die Anwendungen unterbrechen, greifen wir auf unsere Basis-Sprache (en_US) zurück, wenn ein String für die konfigurierte Sprache noch nicht existiert.
Einige Anwendungen haben ein etwas anderes Fallback-Verhalten: die Anzeige roher Übersetzungsschlüssel (vielleicht haben Sie irgendeinen.seltsamen.mit.Punkten.abgegrenzten.String in einer von Ihnen verwendeten App gesehen). Hier muss man einen Kompromiss zwischen Geschwindigkeit und Fehlerfreiheit eingehen. Wir haben uns entschieden, auf Geschwindigkeit und minimalen Aufwand zu optimieren. In einigen Anwendungen ist die Fehlerfreiheit wichtig genug, um die Kadenz für i18n zu verlangsamen. Für uns war es nicht der Fall.
Feinschliff
Es gibt noch ein paar weitere Schritte, die wir unternehmen können, um die Nutzererfahrung in unserer neu lokalisierten Anwendung zu optimieren.
Erstens wollen wir sicherstellen, dass es keine Performance-Einbuße gibt. Wenn unsere Anwendung den Nutzer veranlassen würde, alle übersetzten Strings vor dem Rendern der Seite abzurufen, würde dies mit Sicherheit zu Performance-Einbußen führen. Damit also alles reibungslos läuft, werden die Übersetzungskataloge asynchron und nur dann abgerufen, wenn die Anwendung sie benötigt, um einige Inhalte auf der Seite zu rendern. Dies ist heutzutage leicht zu bewerkstelligen dank der in Modul-Bundlern verfügbaren Codeaufteilungsfunktionen, die dynamische Importanweisungen unterstützen, wie beispieslweiseParcel oder Webpack.
Wir möchten auch alle Reibungsverluste vermeiden, die für Nutzer dadurch entstehen können, dass sie beim Besuch verschiedener Cloudflare Websites und Apps ständig die gewünschte Sprache auswählen müssen. Zu diesem Zweck haben wir sichergestellt, dass jede Sprachpräferenz, die ein Nutzer auf unserer Marketing-Website oder unserer Support-Website auswählt, auf ihrem Weg zu und von unserem Dashboard bestehen bleibt (alle Links sind auf Französisch, um den Punkt zu unterstreichen).
Was kommt als Nächstes?
Es war eine aufregende Reise und wir haben eine Menge aus dem Prozess gelernt. Man kann ein i18n-Projekt nur schwer (oder vielleicht gar nicht) als wirklich abgeschlossen bezeichnen. Die Expansion in neue Sprachen wird heimtückische Fehler und neue Herausforderungen aufdecken. Der Budgetdruck wird eine Herausforderung für Sie sein, Wege zur Kostensenkung und Effizienzsteigerung zu finden. Darüber hinaus werden Sie Möglichkeiten entdecken, wie Sie die lokalisierte Erfahrung für die Nutzer noch weiter verbessern können.
Es gibt eine lange Liste von Dingen, die wir gerne verbessern würden, aber hier sind fünf der wichtigsten Punkte:
- Kollation. Der String-Vergleich ist sprachsensibel. Und als solcher ist der Code, den Sie in Ihrer Anwendung für lexikografisch sortierte Listen und Tabellen mit Daten geschrieben haben, für einige Ihrer Nutzer wahrscheinlich nicht der richtige. Dies zeigt sich besonders deutlich bei Sprachen, die logografische Schriftsysteme verwenden (wie Chinesisch oder Japanisch), im Gegensatz zu Sprachen, die Alphabete verwenden (wie Englisch oder Spanisch).
- Unterstützung für Sprachen, die von rechts nach links geschrieben werden (wie Arabisch und Hebräisch).
- Die Lokalisierung von API-Antworten ist schwieriger als die Lokalisierung einer statischen Kopie in der Benutzeroberfläche, da dies einen koordinierten Aufwand zwischen den Teams erfordert. Im Zeitalter der Mikrodienste kann es eine große Herausforderung sein, eine Lösung zu finden, die in den unzähligen technischen Stacks, die jeden Dienst versorgen, gut funktioniert.
- Lokalisierung von Karten. Wir werden daran arbeiten, sicherzustellen, dass alle Inhalte in unseren kartenbasierten Visualisierungen übersetzt werden.
- Maschinelle Übersetzung ist sich in den letzten Jahren ein gutes Stück vorangekommen. Aber sie ist noch nicht ausgereift genug, um ihr unsere Übersetzungen unbeaufsichtigt zu überlassen. Wir möchten jedoch mehr damit experimentieren, maschinelle Übersetzung als einen ersten Durchgang zu verwenden und Korrekturleser dann damit beauftragen, für Fehlerfreiheit und den richtigen Ton zu sorgen.
Ich hoffe, Sie haben Überblick darüber, wie wir bei Cloudflare unser Dashboard internationalisiert und lokalisiert haben, gerne gelesen. Werfen Sie einen Blick auf unsere Karriereseite für weitere Informationen über Vollzeitstellen und Praktikumsplätze auf der ganzen Welt.