


Hyperdrive macht den Zugriff auf Ihre bestehenden Datenbanken von Cloudflare Workers aus hyperschnell, egal wo sie laufen. Sie verbinden Hyperdrive mit Ihrer Datenbank, ändern eine Codezeile, um eine Verbindung über Hyperdrive herzustellen, und voilà: Verbindungen und Abfragen werden schneller (und Spoiler: Sie können es schon heute nutzen).
Kurz gesagt: Hyperdrive nutzt unser globales Netzwerk, um Abfragen an Ihre bestehenden Datenbanken zu beschleunigen, unabhängig davon, ob sich diese bei einem alten Cloud-Provider oder bei Ihrem bevorzugten Provider für Serverless-Datenbanken befinden. Die Latenz, die durch das wiederholte Einrichten neuer Datenbankverbindungen entsteht, wird drastisch reduziert, und die beliebtesten Leseabfragen an Ihre Datenbank werden zwischengespeichert, sodass Sie oft gar nicht mehr zu Ihrer Datenbank zurückkehren müssen.
Wenn Ihre Kerndatenbank – mit Ihren Nutzerprofilen, Ihrem Produktbestand oder Ihrer wichtigen Web-App – in der us-east1-Region eines veralteten Cloud-Anbieters angesiedelt ist, wird der Zugriff für Nutzende in Paris, Singapur und Dubai ohne Hyperdrive sehr langsam sein und selbst für Nutzende in Los Angeles oder Vancouver langsamer, als er sein sollte. Da jeder Roundtrip bis zu 200 ms dauert, können die mehrfachen Roundtrips, die allein für den Verbindungsaufbau erforderlich sind, leicht bis zu einer Sekunde (oder mehr!) in Anspruch nehmen; und das, bevor Sie überhaupt eine Abfrage für Ihre Daten gemacht haben. Hyperdrive soll dieses Problem lösen.
Um die Performance von Hyperdrive zu demonstrieren, haben wir eine Demo-Anwendung erstellt, die Abfragen gegen dieselbe Datenbank durchführt: sowohl mit Hyperdrive als auch ohne Hyperdrive (direkt). Die App wählt eine Datenbank in einem Nachbarkontinent aus: Wenn Sie sich in Europa befinden, wählt sie eine Datenbank in den USA – etwas, das europäische Nutzende allzu häufig erleben – und wenn Sie sich in Afrika befinden, wählt sie eine Datenbank in Europa (und so weiter). Sie erhalten die Rohdaten einer einfachen SELECT-Abfrage, ohne sorgfältig ausgewählte Durchschnittswerte oder herausgepickte Metriken.
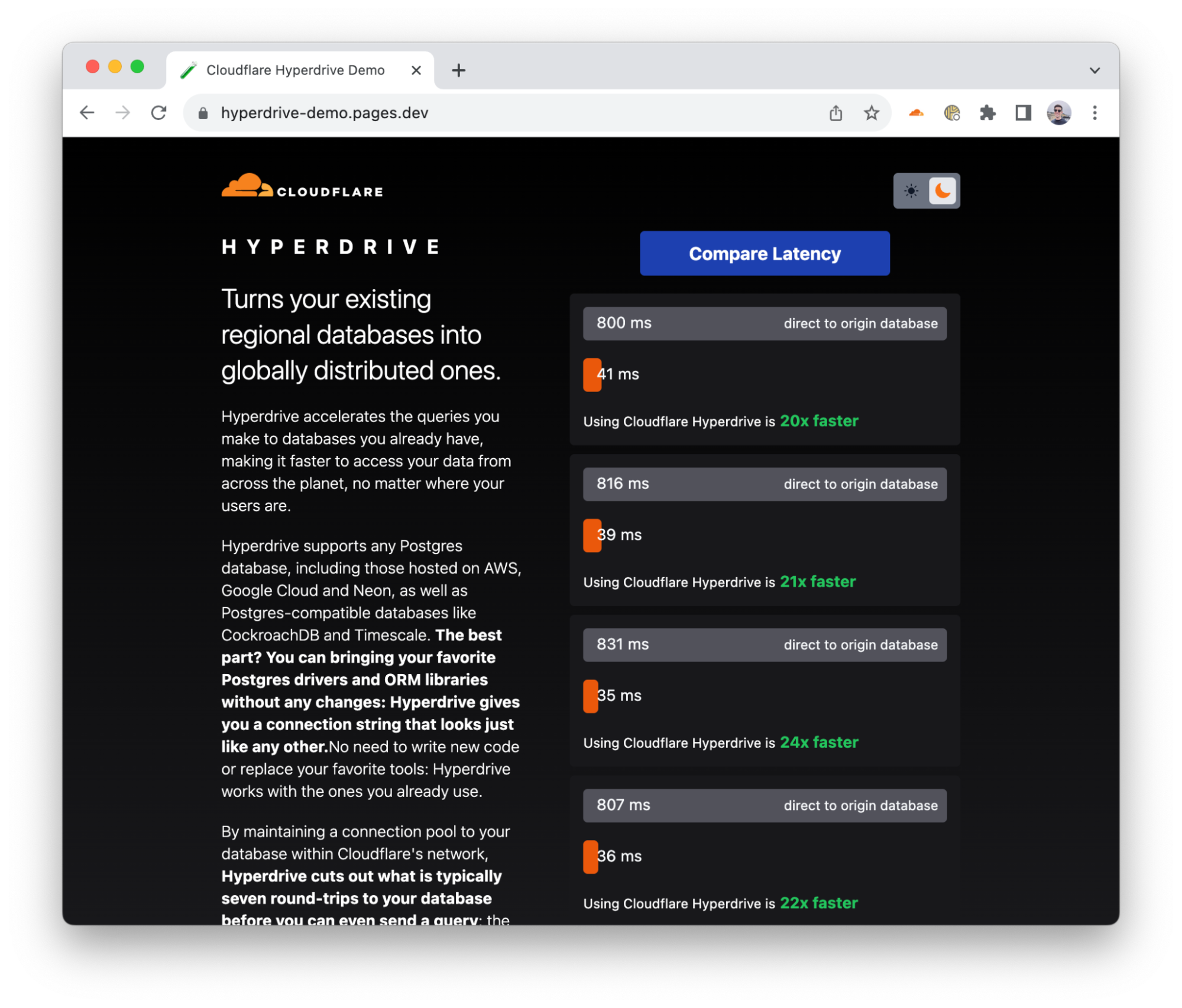
Bei internen Tests, ersten Berichten von Nutzenden und mehreren Durchläufen in unserem Benchmark erzielte Hyperdrive bei gecachten Abfragen eine 17- bis 25-fache Performance-Verbesserung im Vergleich zur direkten Abfrage der Datenbank und eine sechs- bis achtfache Verbesserung bei ungecachten Abfragen und Schreibvorgängen. Die gecachte Latenz wird Sie vielleicht nicht überraschen, aber wir sind der Meinung, dass die sechs- bis achtfache Verbesserung bei nicht gecachten Abfragen aus „Ich kann keine zentralisierte Datenbank von Cloudflare Workers aus abfragen“ in „Wie bin ich nur solange ohne diese Möglichkeit ausgekommen?!“ verwandelt. Wir arbeiten auch weiterhin an der Verbesserung der Performance: Wir haben bereits weitere Einsparungen bei der Latenz festgestellt und werden diese in den kommenden Wochen veröffentlichen.
Und das Beste daran? Entwickler und Entwicklerinnen mit einem kostenpflichtigen Tarif können sofort die offene Betaversion von Hyperdrive ausprobieren: Es gibt keine Wartelisten oder spezielle Anmeldeformulare.
Hyperdrive? Noch nie davon gehört?
Wir arbeiten seit einiger Zeit im Verborgenen an Hyperdrive. Aber die Möglichkeit für Entwicklungsteams, sich mit bereits vorhandenen Datenbanken zu verbinden – mit ihren bestehenden Daten, Abfragen und Werkzeugen – beschäftigt uns schon seit geraumer Zeit.
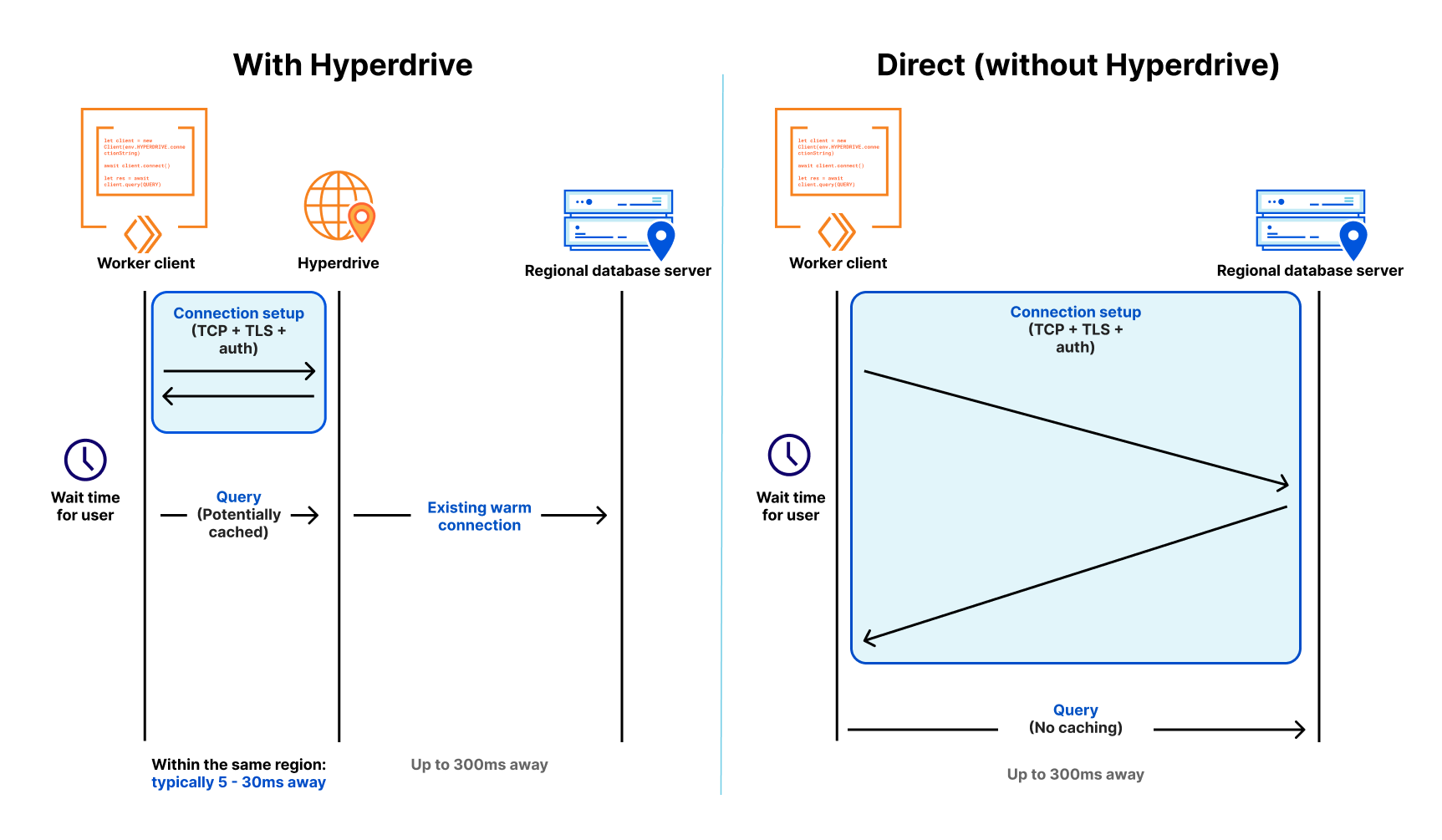
In einer modernen verteilten Cloud-Umgebung wie der von Workers, in der die Rechenleistung global verteilt ist (also in der Nähe der Nutzenden) und die Funktionen kurzlebig sind (sodass nicht mehr als nötig in Rechnung gestellt wird), war die Verbindung zu herkömmlichen Datenbanken sowohl langsam als auch nicht skalierbar. Langsam, weil es für den Verbindungsaufbau mehr als sieben Runden braucht (TCP-Handshake, TLS-Verhandlung und Autorisierung). Und nicht skalierbar, weil Datenbanken wie PostgreSQL hohe Ressourcenkosten pro Verbindung verursachen. Schon einige hundert Verbindungen zu einer Datenbank können einen nicht zu unterschätzenden Arbeitsspeicher verbrauchen – den für die Abfragen benötigten Arbeitsspeicher nicht mitgerechnet.
Unsere Freunde bei Neon (einem beliebten Serverless Postgres-Provider) haben darüber geschrieben und sogar einen WebSocket-Proxy und -Treiber veröffentlicht, um den Verbindungsaufwand zu reduzieren. Aber sie haben trotzdem zu kämpfen: Selbst mit einem benutzerdefinierten Treiber sind wir bei vier Roundtrips, die jeweils 50–200 Millisekunden oder mehr dauern können. Wenn diese Verbindungen langlebig sind, ist das in Ordnung – es kann bestenfalls einmal alle paar Stunden passieren. Aber wenn sie auf einen einzelnen Funktionsaufruf beschränkt sind und nur wenige Millisekunden bis bestenfalls Minuten von Nutzen sind, verbringt Ihr Code mehr Zeit mit Warten. Das ist praktisch eine andere Art von Kaltstart: Da Sie vor einer Abfrage eine neue Verbindung zu Ihrer Datenbank herstellen müssen, ist die Verwendung einer herkömmlichen Datenbank in einer verteilten oder serverlosen Umgebung (vorsichtig ausgedrückt) sehr langsam.
Um dies zu verhindern, macht Hyperdrive zweierlei.
Erstens unterhält es eine Reihe regionaler Datenbankverbindungspools im gesamten Cloudflare-Netzwerk, sodass ein Cloudflare Worker nicht bei jeder Anfrage eine neue Verbindung zu einer Datenbank herstellen muss. Stattdessen kann der Worker eine Verbindung zu Hyperdrive herstellen (schnell!), wobei Hyperdrive einen Pool von einsatzbereiten Verbindungen zurück zur Datenbank unterhält. Da eine Datenbank bei einem einzigen Roundtrip zwischen 30 ms und (oft) 300 ms entfernt sein kann (ganz zu schweigen von den sieben Roundtrips oder mehr, die Sie für eine neue Verbindung benötigen), reduziert ein Pool verfügbarer Verbindungen das Latenzproblem, das bei kurzlebigen Verbindungen sonst auftreten würde, drastisch.
Zweitens versteht es den Unterschied zwischen lesenden (nicht verändernden) und schreibenden (verändernden) Abfragen und Transaktionen und kann Ihre beliebtesten lesenden Abfragen automatisch zwischenspeichern: Diese machen über 80 % der meisten Abfragen aus, die in typischen Webanwendungen an Datenbanken gestellt werden. Die Seite mit den Produktangeboten, die stündlich von Zehntausenden besucht wird, offene Stellen auf einer renommierten Karriereseite oder auch Abfragen von Konfigurationsdaten, die sich gelegentlich ändern. Ein Großteil der abgefragten Daten ändert sich nicht oft, und das Cachen dieser Daten in der Nähe des Ortes, von dem ein Nutzender sie abfragt, kann den Zugriff auf diese Daten für die nächsten zehntausend Nutzenden dramatisch beschleunigen. Schreibabfragen, die nicht sicher zwischengespeichert werden können, profitieren dennoch sowohl vom Verbindungspooling von Hyperdrive als auch vom globalen Netzwerk von Cloudflare: Da wir über unser Backbone die schnellsten Routen durch das Internet nehmen können, wird auch hier die Latenz reduziert.
Hyperdrive funktioniert nicht nur mit PostgreSQL-Datenbanken – einschließlich Neon, Google Cloud SQL, AWS RDS und Timescale – sondern auch mit PostgreSQL-kompatiblen Datenbanken wie Materialize (einer leistungsstarken Stream-Processing-Datenbank), CockroachDB (einer großen verteilten Datenbank), AlloyDB von Google Cloud und AWS Aurora Postgres.
Wir arbeiten außerdem daran, bis zum Ende des Jahres Unterstützung für MySQL, einschließlich Providern wie PlanetScale, zu bieten, und planen für die Zukunft die Unterstützung weiterer Datenbank-Engines.
Der magische Verbindungsstring
Eines der wichtigsten Ziele bei der Entwicklung von Hyperdrive war, dass die Entwicklungsteams ihre bestehenden Treiber, Abfrage-Builder und ORM-Bibliotheken (Object-Relational Mapper) weiter verwenden können. Es wäre egal gewesen, wie schnell Hyperdrive ist, wenn wir von Ihnen verlangt hätten, von Ihrem bevorzugten ORM zu migrieren und/oder Hunderte (oder mehr) von Codezeilen und Tests neu zu schreiben, um von der Performance von Hyperdrive zu profitieren.
Um dies zu erreichen, haben wir mit den Betreuenden beliebter Open-Source-Treiber – einschließlich node-postgres und Postgres.js – zusammengearbeitet, damit ihre Bibliotheken die neue TCP-Socket-API von Workers unterstützen, die derzeit den Standardisierungsprozess durchläuft, und wir erwarten, dass sie auch in Node.js, Deno und Bun Einzug halten wird.
Der einfache Datenbankverbindungsstring ist die gemeinsame Sprache der Datenbanktreiber und hat normalerweise dieses Format:
postgres://user:[email protected]:5432/postgres
Der Zauber von Hyperdrive besteht darin, dass Sie es in Ihren bestehenden Workers-Anwendungen mit Ihren bestehenden Abfragen einsetzen können, indem Sie einfach Ihren Verbindungsstring gegen den von Hyperdrive generierten austauschen.
Hyperdrive erstellen
Mit einer vorhandenen Datenbank – in diesem Beispiel verwenden wir eine Postgres-Datenbank von Neon – dauert es weniger als eine Minute, um Hyperdrive zum Laufen zu bringen (ja, wir haben die Zeit gemessen).
Wenn Sie kein bestehendes Cloudflare Workers-Projekt haben, können Sie schnell eines erstellen:
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
Von hier aus brauchen wir nur noch den Datenbankverbindungsstring für unsere Datenbank und einen kurzen Wrangler-Befehlszeilenaufruf, damit Hyperdrive sich mit ihr verbindet.
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:[email protected]:5432/neondb"
# This will return an ID: we'll use this in the next step
Fügen Sie unseren Hyperdrive in die Konfigurationsdatei wrangler.toml für unseren Worker ein:
[[hyperdrive]]
name = "HYPERDRIVE"
id = "cdb28782-0dfc-4aca-a445-a2c318fb26fd"
Wir können nun einen Worker schreiben – oder ein bestehendes Worker-Skript nehmen – und Hyperdrive verwenden, um Verbindungen und Abfragen zu unserer bestehenden Datenbank zu beschleunigen. Wir verwenden hier node-postgres, aber wir könnten genauso gut Drizzle ORM nutzen.
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
console.log(JSON.stringify(env));
// Create a database client that connects to our database via Hyperdrive
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
// Connect to our database
await client.connect();
// A very simple test query
let result = await client.query({ text: 'SELECT * FROM pg_tables' });
// Return our result rows as JSON
return Response.json({ result: result });
} catch (e) {
console.log(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
Der obige Code ist absichtlich einfach gehalten, aber die Magie ist hoffentlich nachvollziehbar: Unser Datenbanktreiber erhält einen Verbindungsstring von Hyperdrive und ist dabei völlig ahnungslos. Er muss nichts über Hyperdrive wissen, wir müssen unsere Lieblingsbibliothek für Abfrageerstellung nicht über Bord werfen und wir profitieren sofort von den Geschwindigkeitsvorteilen bei Abfragen.
Verbindungen werden automatisch gepoolt und warmgehalten, unsere beliebtesten Abfragen werden gecacht, und unsere gesamte Anwendung wird schneller.
Wir haben auch Leitfäden für alle wichtigen Datenbank-Provider erstellt, damit Sie das, was Sie von diesen Providern benötigen (einen Verbindungsstring), ganz einfach in Hyperdrive übertragen können.
Schnelles Tempo kann nicht günstig sein, oder?
Wir sind der Meinung, dass Hyperdrive für den Zugriff auf Ihre bestehenden Datenbanken entscheidend ist, wenn Sie auf Cloudflare Workers entwickeln: Herkömmliche Datenbanken wurden einfach nie für eine Welt entwickelt, in der Clients global verteilt sind.
Das Verbindungspooling von Hyperdrive wird immer kostenlos sein, sowohl für Datenbankprotokolle, die wir heute unterstützen, als auch für neue Datenbankprotokolle, die wir in Zukunft hinzufügen werden. Genau wie der DDoS-Schutz und unser globales CDN sind wir der Meinung, dass der Zugang zum Kernfeature von Hyperdrive zu nützlich ist, um ihn zurückzuhalten.
Während der offenen Beta-Phase wird Hyperdrive selbst keine Gebühren für die Nutzung erheben, unabhängig davon, wie Sie es verwenden. Weitere Details zur Preisgestaltung von Hyperdrive werden wir rechtzeitig vor der allgemeinen Freigabe (Anfang 2024) bekannt geben.
Zeit für eine Abfrage
Wie geht es nun mit Hyperdrive weiter?
Wir planen, Hyperdrive Anfang 2024 auf den Markt zu bringen – und arbeiten an mehr Kontrolle über das Caching und die automatische Invalidierung auf der Grundlage von Schreibvorgängen, detaillierten Abfrage- und Performance-Analytics (bald!), Unterstützung für weitere Datenbank-Engines (einschließlich MySQL) und möchten die Geschwindigkeit weiter ankurbeln.
Wir arbeiten auch daran, die Verbindung zu privaten Netzwerken über Magic WAN und Cloudflare Tunneling zu ermöglichen, sodass Sie auf Datenbanken zugreifen können, die nicht im öffentlichen Internet zugänglich sind (oder sein können).
Um Hyperdrive mit Ihrer bestehenden Datenbank zu verbinden, besuchen Sie unsere Dokumentation für die Entwicklung. Es dauert weniger als eine Minute, um einen Hyperdrive zu erstellen und bestehenden Code zu aktualisieren, um ihn zu verwenden. Treten Sie dem Kanal #hyperdrive-beta in unserem Entwicklungs-Discord bei, um Fragen zu stellen, Fehler zu melden und direkt mit unseren Produkt- und Entwicklungsteams zu sprechen.
