


Inferenz aus fein abgestimmten LLMs mit LoRAs ist jetzt in der Open Beta-Phase
Wir freuen uns, heute ankündigen zu können, dass Sie jetzt fein abgestimmte Inferenzen mit LoRAs auf Workers AI durchführen können. Diese Funktion befindet sich in der Open Beta-Phase und ist für vortrainierte LoRA-Adapter verfügbar, die mit Mistral, Gemma oder Llama 2 verwendet werden können, mit einigen Einschränkungen. Werfen Sie einen Blick auf unseren Blog-Beitrag zu Produktankündigungen, um einen umfassenden Überblick über unsere Bring Your Own (BYO) LoRAs-Funktion zu erhalten.
In diesem Beitrag gehen wir näher darauf ein, was Feinabstimmung (Fine-Tuning) und LoRAs sind, zeigen Ihnen, wie Sie sie auf unserer Workers AI-Plattform nutzen können, und gehen dann auf die technischen Details ein, wie wir sie auf unserer Plattform implementiert haben.
Was ist Fine-Tuning?
Feinabstimmung (Fine-Tuning) ist ein allgemeiner Begriff für die Modifizierung eines KI-Modells, indem es mit zusätzlichen Daten weiter trainiert wird. Das Ziel der Feinabstimmung ist es, die Wahrscheinlichkeit zu erhöhen, dass generierte Inhalte Ihrem Datensatz ähnlich sind. Ein Modell von Grund auf neu zu trainieren ist für viele Anwendungsfälle nicht praktikabel, da das Trainieren von KI-Modellen sehr teuer und zeitaufwändig ist. Durch die Feinabstimmung eines bestehenden, vortrainierten Modells profitieren Sie von dessen Fähigkeiten und können gleichzeitig Ihre gewünschte Aufgabe erfüllen. Low-Rank Adaptation (LoRA) ist eine spezielle Methode des Fine-Tunings, die auf verschiedene Modellarchitekturen angewendet werden kann, nicht nur auf LLMs. Bei herkömmlichen Methoden des Fine-Tunings werden die vortrainierten Modellgewichte direkt geändert oder mit zusätzlichen fein abgestimmten Gewichten verschmolzen. Bei LoRA hingegen bleiben die fein abgestimmten Gewichte und das vortrainierte Modell getrennt, und das vortrainierte Modell bleibt unverändert. Dadurch können Sie die Modelle so trainieren, dass sie bei bestimmten Aufgaben genauer sind, z. B. beim Schreiben von Programmcode, der Erstellung von Bildern oder etwa auch, um dem verfassten Text eine bestimmte Persönlichkeit bzw. einen bestimmten Stil zu verleihen. Sie können sogar ein bestehendes LLM fein abstimmen, damit es zusätzliche Informationen über ein bestimmtes Thema verstehen kann.
Der Ansatz, die ursprünglichen Gewichte des Basismodells beizubehalten, bedeutet, dass Sie neue Gewichte für die Feinabstimmung mit relativ wenig Rechenaufwand erstellen können. Sie können die Vorteile bestehender Basismodelle (wie Llama, Mistral und Gemma) nutzen und sie für Ihre Bedürfnisse anpassen.
Wie funktioniert die Feinabstimmung?
Um das Fine-Tuning besser zu verstehen und zu begreifen, warum LoRA so effektiv ist, müssen wir zunächst die Funktionsweise von KI-Modellen erörtern. KI-Modelle (wie LLMs) sind neuronale Netze, die mithilfe von Deep-Learning-Techniken trainiert werden. In neuronalen Netzen gibt es eine Reihe von Parametern, die als mathematische Darstellung des Fachwissens des Modells fungieren und aus Gewichten und Verzerrungen bestehen – oder einfacher gesagt: aus Zahlen. Diese Parameter werden in der Regel als große Matrizen von Zahlen dargestellt. Je mehr Parameter ein Modell hat, desto größer ist es. Wenn Sie also Modelle wie Lama-2-7b sehen, können Sie daran nun ablesen, dass das Modell 7 Milliarden Parameter hat.
Die Parameter eines Modells bestimmen sein Verhalten. Wenn Sie ein Modell von Grund auf trainieren, sind diese Parameter in der Regel zunächst Zufallszahlen. Wenn Sie das Modell auf einem Datensatz trainieren, werden diese Parameter nach und nach angepasst, bis das Modell den Datensatz widerspiegelt und das richtige Verhalten zeigt. Einige Parameter werden wichtiger sein als andere, also wenden wir eine Gewichtung an und zeigen damit an, ob sie wichtiger oder weniger wichtig sind. Gewichte spielen eine entscheidende Rolle bei der Fähigkeit des Modells, Muster und Beziehungen in den Daten zu erfassen, auf die es trainiert wurde.
Bei der herkömmlichen Feinabstimmung werden alle Parameter des trainierten Modells mit einem neuen Satz von Gewichten angepasst. Damit wir ein fein abgestimmtes Modell erhalten, müssen wir die gleiche Anzahl von Parametern wie das ursprüngliche Modell verwenden. Das bedeutet, dass das Trainieren und Ausführen von Inferenzen für ein vollständig fein abgestimmtes Modell sehr zeit- und rechenintensiv sein können. Hinzu kommt, dass regelmäßig neue Modelle auf dem neuesten Stand der Technik oder Versionen bestehender Modelle veröffentlicht werden, wodurch das Trainieren, Warten und Speichern vollständig abgestimmter Modelle kostspielig werden kann.
LoRA ist eine effiziente Methode zur Feinabstimmung
Vereinfacht ausgedrückt, vermeidet LoRA die Anpassung von Parametern in einem vortrainierten Modell und ermöglicht uns stattdessen die Anwendung einer kleinen Anzahl zusätzlicher Parameter. Diese zusätzlichen Parameter werden vorübergehend auf das Basismodell angewendet, um das Verhalten des Modells effektiv zu steuern. Im Vergleich zu herkömmlichen Methoden der Feinabstimmung ist es weniger zeit- und rechenaufwändig, diese zusätzlichen Parameter zu trainieren, die als LoRA-Adapter bezeichnet werden. Nach dem Training verpacken wir den LoRA-Adapter als separate Modelldatei, die dann mit dem Basismodell verbunden werden kann, anhand dessen sie trainiert wurde. Ein vollständig fein abgestimmtes Modell kann Dutzende Gigabyte groß sein, während diese Adapter in der Regel nur ein paar Megabyte groß sind. Das macht die Verteilung viel einfacher, und die Bereitstellung fein abgestimmter Inferenzen mit LoRA erhöht die Gesamtinferenzzeit nur um einige Millisekunden.
Sie möchten wissen, warum LoRA so effektiv ist? Achtung, dann schnallen Sie sich an: Wir müssen uns hierfür zunächst kurz mit etwas linearer Algebra befassen. Sie haben sich seit Ihrem Studium nicht mehr um diese mathematische Disziplin gesorgt? Keine Angst, gemeinsam schaffen wir das.
Also legen wir los!
Bei der traditionellen Feinabstimmung können wir die Gewichte eines Modells (W0) nehmen und sie optimieren, um einen neuen Satz von Gewichten auszugeben – die Differenz zwischen den ursprünglichen Modellgewichten und den neuen Gewichten ist also ΔW, was die Änderung der Gewichte darstellt. Ein abgestimmtes Modell hat also einen neuen Satz von Gewichten, der als die ursprünglichen Modellgewichte plus die Änderung der Gewichte, W0 + ΔW, dargestellt werden kann.
Denken Sie daran, dass alle diese Modellgewichte als große Matrizen von Zahlen dargestellt werden. In der Mathematik hat jede Matrix eine Eigenschaft namens Rang (r), die die Anzahl der linear unabhängigen Spalten oder Zeilen in einer Matrix beschreibt. Bei Matrizen mit niedrigem Rang gibt es nur wenige Spalten oder Zeilen, die „wichtig“ sind, sodass wir sie in zwei kleinere Matrizen mit den wichtigsten Parametern zerlegen oder aufteilen können (man kann sich das wie das Faktorisieren in der Algebra vorstellen). Diese Technik wird als Rangzerlegung bezeichnet, die es uns ermöglicht, Matrizen stark zu reduzieren und zu vereinfachen und dabei die wichtigsten Bits zu behalten. Im Zusammenhang mit dem Fine-Tuning bestimmt der Rang, wie viele Parameter im Vergleich zum ursprünglichen Modell geändert werden – je höher der Rang, desto stärker die Feinabstimmung, was eine größere Präzision des Ergebnisses ermöglicht.
Laut dem ursprünglichen LoRA-Artikel haben Forscher herausgefunden, dass bei einem Modell mit niedrigem Rang auch die Matrix, die die Änderung der Gewichte darstellt, einen niedrigen Rang hat. Daher können wir auf unsere Matrix, die die Änderung der Gewichte ΔW darstellt, eine Rangzerlegung anwenden, um zwei kleinere Matrizen A, B zu erstellen, wobei ΔW = BA ist. Nun kann die Änderung des Modells durch zwei kleinere Matrizen mit niedrigem Rang dargestellt werden. Deshalb wird diese Methode der Feinabstimmung Low-Rank-Adaptation genannt.
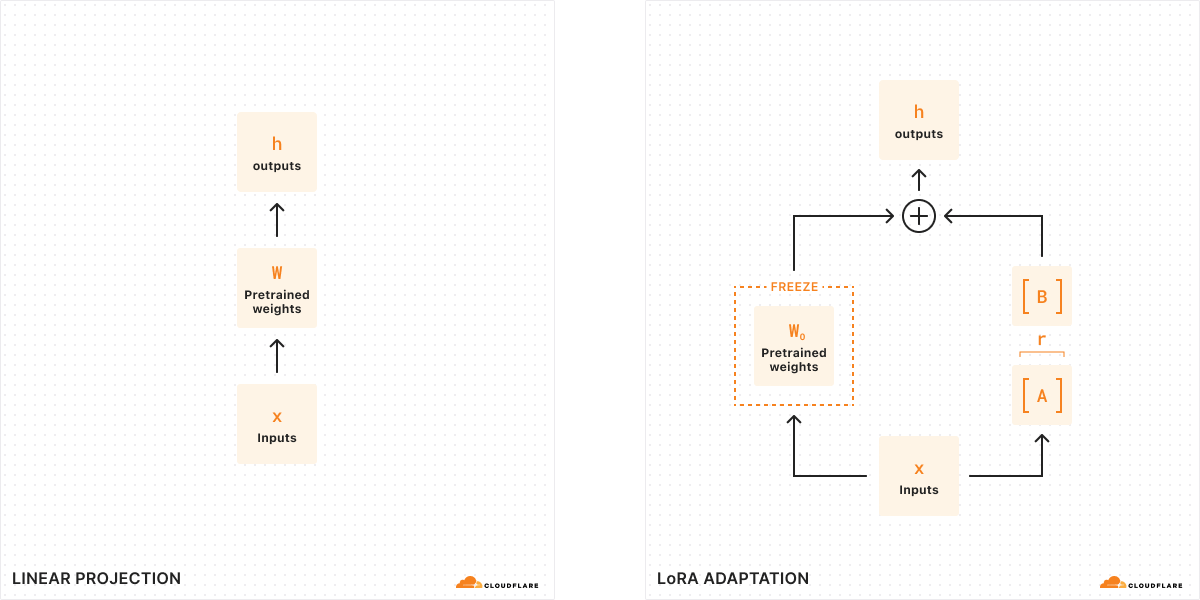
Bei der Inferenz benötigen wir nur die kleineren Matrizen A, B, um das Verhalten des Modells zu ändern. Die Modellgewichte in A, B bilden unseren LoRA-Adapter (zusammen mit einer Konfigurationsdatei). Zur Laufzeit addieren wir die Modellgewichte zusammen und kombinieren das ursprüngliche Modell (W0) und den LoRA-Adapter (A, B). Addieren und Subtrahieren sind einfache mathematische Operationen, was bedeutet, dass wir schnell verschiedene LoRA-Adapter austauschen können, indem wir A, B von W0 addieren und subtrahieren. Indem wir die Gewichte des ursprünglichen Modells vorübergehend anpassen, ändern wir das Verhalten und die Ausgabe des Modells und erhalten so eine fein abgestimmte Inferenz mit minimaler zusätzlicher Latenz.
Laut dem ursprünglichen LoRA-Artikel „kann LoRA die Anzahl der trainierbaren Parameter um das 10.000-fache und den Speicherbedarf der GPU um das Dreifache reduzieren“. Aus diesem Grund ist LoRA eine der beliebtesten Methoden zur Feinabstimmung, da sie viel weniger rechenintensiv ist als ein vollständig fein abgestimmtes Modell, keine zusätzliche Zeit für die Inferenz benötigt und viel kleiner und portabel ist.
Wie können Sie LoRAs mit Workers AI nutzen?
Workers AI ist aufgrund der Art und Weise, wie wir serverlose Inferenzen durchführen, sehr gut für die Ausführung von LoRAs geeignet. Die Modelle in unserem Katalog sind immer auf unseren GPUs vorgeladen, d. h. wir „halten sie warm“, damit Ihre Anfragen nie einen „Kaltstart“ erleben. Das Basismodell ist also immer verfügbar, und wir können die LoRA-Adapter bei Bedarf dynamisch laden und auswechseln. Wir können tatsächlich mehrere LoRA-Adapter an ein Basismodell anschließen, sodass wir mehrere verschiedene, fein abgestimmte Inferenzanfragen auf einmal verarbeiten können.
Wenn Sie mit LoRA eine Feinabstimmung vornehmen, erhalten Sie zwei Dateien: Ihre benutzerdefinierten Modellgewichte (im safetensors-Format) und eine Konfigurationsdatei für den Adapter (im json-Format). Um diese Gewichte selbst zu erstellen, können Sie einen LoRA auf Ihren eigenen Daten trainieren, indem Sie die Hugging Face PEFT (Parameter-Efficient Fine-Tuning)-Bibliothek mit der Hugging Face AutoTrain LLM Bibliothek kombinieren. Sie können Ihre Trainingsaufgaben auch mit Diensten wie Auto Train und Google Colab durchführen. Alternativ dazu gibt es heute viele Open-Source-LoRA-Adapter auf Hugging Face, die eine Vielzahl von Anwendungsfällen abdecken.
Letztendlich möchten wir die LoRA-Trainings-Workloads auf unserer Plattform unterstützen, aber Sie müssen schon heute Ihre trainierten LoRA-Adapter zu Workers AI bringen, weshalb wir diese Funktion „Bring Your Own (BYO) LoRAs“ nennen.
Für die erste Open Beta-Version erlauben wir die Verwendung von LoRAs mit unseren Mistral-, Llama- und Gemma-Modellen. Wir haben Versionen dieser Modelle zur Verfügung gestellt, die LoRAs akzeptieren, auf die Sie zugreifen können, indem Sie `-lora` an das Ende des Modellnamens anhängen. Ihr Adapter muss auf eines der unten aufgeführten unterstützten Basismodelle abgestimmt worden sein. :
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
Da wir diese Funktion in der Open Beta-Phase einführen, gibt es heute einige Einschränkungen zu beachten: quantisierte LoRA-Modelle werden noch nicht unterstützt, LoRA-Adapter müssen kleiner als 100 MB sein und dürfen maximal einen Rang von 8 haben, und Sie können während der ersten Open Beta-Phase bis zu 30 LoRAs pro Konto ausprobieren. Um mit LoRAs auf Workers AI zu beginnen, lesen Sie bitte die Entwicklerdokumentation.
Wie immer erwarten wir, dass bei der Nutzung von Workers AI und unserer neuen BYO LoRA-Funktion unsere Nutzungsbedingungen beachtet werden, einschließlich aller modellspezifischen Nutzungsbeschränkungen, die in den Lizenzbedingungen der Modelle enthalten sind.
Wie haben wir den mandantenfähigen LoRA-Service entwickelt?
Die gleichzeitige Bereitstellung mehrerer LoRA-Modelle stellt eine Herausforderung für die Nutzung der GPU-Ressourcen dar. Es ist zwar möglich, Inferenzanfragen an ein Basismodell zu bündeln („Batch“), aber es ist viel schwieriger, Anfragen mit der zusätzlichen Komplexität der Bedienung einzigartiger LoRA-Adapter zu bündeln. Um dieses Problem zu lösen, nutzen wir das Design des Punica CUDA-Kernels in Kombination mit globalen Cache-Optimierungen, um die speicherintensiven Workloads des mandantenfähigen LoRA-Services zu bewältigen und gleichzeitig eine niedrige Inferenzlatenz zu bieten.
Der Punica CUDA-Kernel wurde im Artikel Punica: Multi-Tenant LoRA Serving als eine Methode vorgestellt, mit der mehrere, deutlich unterschiedliche LoRA-Modelle bedient werden können, die auf dasselbe Basismodell angewendet werden. Im Vergleich zu früheren Inferenztechniken bietet die Methode erhebliche Verbesserungen bei Durchsatz und Latenzzeit. Diese Optimierung wird zum Teil dadurch erreicht, dass das Bündeln („Batching“) von Anfragen auch bei Anfragen, die verschiedene LoRA-Adapter bedienen, möglich ist.
Der Kern des Punica-Kernelsystems ist ein neuer CUDA-Kernel namens „Segmented Gather Matrix-Vector Multiplication“ (SGMV). SGMV ermöglicht es einer GPU, nur eine einzige Kopie des vortrainierten Modells zu speichern, während verschiedene LoRA-Modelle bedient werden. Das Punica-Kernel-Designsystem konsolidiert die Stapelverarbeitung von Anfragen für eindeutige LoRA-Modelle, um die Performance durch Parallelisierung der Multiplikation von Merkmalsgewichten verschiedener Anfragen in einem Stapel zu verbessern. Anfragen für das gleiche LoRA-Modell werden dann gruppiert, um die Intensität des Betriebs zu erhöhen. Zu Beginn lädt die GPU das Basismodell und reserviert den größten Teil ihres GPU-Speichers für den KV-Cache. Die LoRA-Komponenten (A- und B-Matrizen) werden dann bei Bedarf aus einem entfernten Speicher (Cache von Cloudflare oder R2) geladen, wenn eine eingehende Anfrage dies erfordert. Dieses bedarfsgesteuerte Laden verursacht nur eine Latenz von Millisekunden. Das bedeutet, dass mehrere LoRA-Adapter nahtlos abgerufen und bedient werden können, ohne die Performance der Inferenz zu beeinträchtigen. Häufig angefragte LoRA-Adapter werden für die schnellstmögliche Ableitung zwischengespeichert.
Sobald eine angeforderte LoRA lokal zwischengespeichert wurde, ist die Geschwindigkeit, mit der sie für die Inferenz zur Verfügung gestellt werden kann, nur noch durch die PCIe-Bandbreite begrenzt. Da für jede Anfrage ein eigenes LoRA erforderlich sein kann, ist es von entscheidender Bedeutung, dass LoRA-Downloads und Speicherkopiervorgänge asynchron durchgeführt werden. Der Punica Scheduler geht genau diese Herausforderung an, indem er nur solche Anfragen in eine Warteschlange stellt, für die derzeit die erforderlichen LoRA-Gewichte im GPU-Speicher verfügbar sind. Anfragen, für die dies nicht der Fall ist, werden in eine Warteschlange gestellt, bis die erforderlichen Gewichte verfügbar sind und die Anfrage effizient in einen Stapel aufgenommen werden kann.
Durch die effektive Verwaltung des KV-Cache und die Stapelung dieser Anfragen ist es möglich, erhebliche mandantenfähige LoRA-Workloads zu bewältigen. Eine weitere und wichtige Optimierung ist die Verwendung einer kontinuierlichen Stapelverarbeitung. Gängige Batching-Methoden verlangen, dass alle Anfragen an denselben Adapter ihre Haltebedingung erreichen, bevor sie freigegeben werden. Die kontinuierliche Stapelverarbeitung ermöglicht es, eine Anfrage in einem Stapel frühzeitig freizugeben, sodass sie nicht auf die am längsten laufende Anfrage warten muss.
Da LLMs, die im Cloudflare-Netzwerk eingesetzt werden, weltweit verfügbar sind, ist es wichtig, dass dies auch für die LoRA-Adaptermodelle gilt. In Kürze werden wir Remote-Modelldateien implementieren, die auf Cloudflare zwischengespeichert werden, um die Inferenzlatenz weiter zu reduzieren.
Ein Fahrplan für die Feinabstimmung auf Workers AI
Die Einführung der Unterstützung für LoRA-Adapter ist ein wichtiger Schritt, um die Feinabstimmung auf unserer Plattform zu ermöglichen. Zusätzlich zu den heute verfügbaren LLM-Feinabstimmungen freuen wir uns darauf, mehr Modelle und eine Vielzahl von Aufgabentypen, einschließlich der Bilderzeugung, zu unterstützen.
Unsere Vision für Workers AI ist es, der beste Ort für Entwickler zu sein, um ihre KI-Workloads auszuführen - und das schließt den Prozess der Feinabstimmung selbst ein. Letztendlich wollen wir in der Lage sein, die Feinabstimmung zu trainieren und vollständig abgestimmte Modelle direkt auf Workers AI laufen zu lassen. Dies ermöglicht viele Anwendungsfälle für KI, die in Unternehmen von größerer Relevanz sind, da die Modelle eine größere Präzision und Detailgenauigkeit für bestimmte Aufgaben aufweisen.
Mit AI Gateway können wir Entwicklern helfen, ihre Eingabeaufforderungen und Antworten zu protokollieren, die sie dann zur Feinabstimmung von Modellen mit Produktionsdaten verwenden können. Unsere Vision ist es, einen Ein-Klick-Feinabstimmungsdienst zu haben, bei dem Protokolldaten von AI Gateway verwendet werden können, um ein Modell (auf Cloudflare) neu zu trainieren, und dann kann das fein abgestimmte Modell auf Workers AI zur Inferenz eingesetzt werden. Auf diese Weise können Entwickler ihre KI-Modelle an ihre App anpassen, wobei eine Präzision bis hin zu einer Ebene pro Benutzer möglich ist. Das fein abgestimmte Modell kann dann kleiner und optimierter sein und den Nutzern helfen, Zeit und Geld bei der KI-Inferenz zu sparen – und der Clou ist, dass dies alles innerhalb unserer eigenenEntwicklerplattformgeschehen kann.
Wir freuen uns darauf, dass Sie die Open Beta-Version für BYO LoRAs ausprobieren können! Lesen Sie unsere Entwicklerdokumentation für weitere Details und sagen Sie uns auf Discord, was Sie davon halten.