

Als ich kürzlich das Computer History Museum in Mountain View besuchte, stieß ich auf einen alten Magnetkernspeicher.

Ich kam ziemlich schnell zu dem Schluss, dass ich keine Ahnung davon hatte, wie diese Dinger je funktionieren konnten. Ich fragte mich, ob die Ringkerne rotieren (sie tun es nicht) und warum durch jeden Ringkern drei Drähte geführt sind (und ich verstehe immer noch nicht genau, wie sie funktionieren). Noch wichtiger ist, dass ich erkannte, dass ich fast nichts darüber weiß, wie der moderne Computerspeicher – dynamisches RAM – funktioniert!
Besonders interessiert hat mich eine der Folgen der Funktionsweise von dynamischem RAM. Denn jedes Bit von Daten wird durch die Ladung (oder deren Fehlen) auf einem kleinen Kondensator im RAM-Chip gespeichert. Aber diese Kondensatoren verlieren mit der Zeit allmählich ihre Ladung. Um den Verlust der gespeicherten Daten zu vermeiden, müssen sie regelmäßig aufgefrischt werden, um die Ladung (falls vorhanden) wieder auf ihr ursprüngliches Niveau zu bringen. Bei diesem Refresh-Prozess wird der Wert jedes Bits gelesen und dann zurückgeschrieben. Während dieser „Auffrischungs“-Zeit ist der Speicher blockiert und kann keine normalen Operationen wie Laden oder Speichern von Bits ausführen.
Das hat mich schon seit geraumer Zeit beschäftigt und ich habe mich gefragt: Ist es möglich, die Verzögerung bei der Wiederauffrischung in der Software zu bemerken?
Einführung in den Refresh von dynamischem RAM
Jedes DIMM-Modul besteht aus „cells“ („Zellen“) und „rows“ („Zeilen“), „columns“ („Spalten“), „sides“ („Seiten“) und/oder „ranks“ („Reihen“). In dieser Präsentation der University of Utah werden die Bezeichnungen erklärt (auf Englisch). Sie können die Konfiguration des Speichers in Ihrem Computer mit dem Befehl decode-dimms überprüfen. Hier ist ein Beispiel:
$ decode-dimms
Size 4096 MB
Banks x Rows x Columns x Bits 8 x 15 x 10 x 64
Ranks 2
Für heute müssen wir uns nicht mit dem gesamten DDR-DIMM-Aufbau beschäftigen. Wir müssen nur eine einzelne Speicherzelle, die ein Datenbit speichert, verstehen. Konkret geht es uns nur darum, wie der Refresh-Prozess durchgeführt wird.
Werfen wir einen Blick auf zwei Quellen:
- Ein DRAM-Refresh-Tutorial der University of Utah (auf Englisch)
- Und eine fantastische Dokumentation zu 1-Gigabit Zellen von Micron: TN-46-09 Designing for 1Gb DDR SDRAM
Jedes Bit, das im dynamischen Speicher gespeichert ist, muss aufgefrischt werden, normalerweise alle 64 ms (der sogenannte „Static Refresh“). Das ist ein ziemlich aufwendiger Vorgang. Um einen größeren Stillstand alle 64 ms zu vermeiden, ist dieser Prozess in 8192 kleinere Auffrischungsvorgänge unterteilt. Bei jedem Vorgang sendet der Speichercontroller des Computers Refresh-Befehle an die DRAM-Chips. Nach Erhalt der Anweisung frischt ein Chip 1/8192 seiner Zellen auf. Mathematisch ausgedrückt: 64 ms / 8192 = 7812,5 ns oder 7,81 μs. Das bedeutet:
- Alle 7812,5 ns wird ein Refresh-Befehl ausgegeben. Dieses Intervall wird als tREFI bezeichnet.
- Es dauert einige Zeit, bis der Chip den Refresh durchgeführt hat und wieder normale Lese- und Schreibvorgänge ausführen kann. Diese Periode wird als tRFC bezeichnet und dauert entweder 75 ns oder 120 ns (laut dem erwähnten Datenblatt von Micron).
Wenn der Speicher heiß ist (>85 °C), sinkt die Speicherhaltezeit und die statische Refresh-Zeit halbiert sich auf 32 ms. Dabei sinkt tREFI auf 3906,25 ns.
Ein typischer Speicherchip ist für einen wesentlichen Teil seiner Laufzeit mit Auffrischungen beschäftigt – zwischen 0,4 % und 5 %. Darüber hinaus sind Speicherchips für einen nicht trivialen Anteil des Stromverbrauchs eines typischen Computers verantwortlich. Ein großer Teil dieses Stroms wird für die Durchführung der Auffrischungen verwendet.
Für die Dauer des Refresh-Vorgangs ist der gesamte Speicherchip blockiert. Das bedeutet, dass jedes einzelne Bit im Speicher alle 7812 ns für mehr als 75 ns blockiert ist. Lassen Sie uns das messen.
Vorbereitung eines Experiments
Um Vorgänge mit Nanosekunden-Granularität zu messen, müssen wir eine enge Programmschleife schreiben, beispielsweise in C. Sie sieht folgendermaßen aus:
for (i = 0; i < ...; i++) {
// Perform memory load. Any load instruction will do
*(volatile int *) one_global_var;
// Flush CPU cache. This is relatively slow
_mm_clflush(one_global_var);
// mfence is needed, otherwise sometimes the loop
// takes very short time (25ns instead of like 160). I
// blame reordering.
asm volatile("mfence");
// Measure and record time
clock_gettime(CLOCK_MONOTONIC, &ts);
}
Der vollständige Code steht auf Github zur Verfügung.
Der Code ist wirklich unkompliziert: Eine Speicherauslesung durchführen. Die Daten aus CPU-Caches löschen. Die Zeit messen.
(Anmerkung: Bei einem zweiten Experiment versuchte ich, MOVNTDQA zu verwenden, um die Speicherladung durchzuführen, aber das erfordert eine spezielle, nicht Cache-fähige Speicherseite, für die Root-Zugriff notwendig ist.)
Auf meinem Computer erzeugt das Daten wie diese:
# timestamp, loop duration
3101895733, 134
3101895865, 132
3101896002, 137
3101896134, 132
3101896268, 134
3101896403, 135
3101896762, 359
3101896901, 139
3101897038, 137
Normalerweise erhalte ich ~140 ns pro Schleife, aber periodisch steigt die Schleifendauer auf ~360 ns. Manchmal bekomme ich seltsame Messwerte, die höher als 3200 ns sind.
Leider erweisen sich die Daten als sehr verrauscht. Es ist sehr schwer zu erkennen, ob es eine spürbare Verzögerung im Zusammenhang mit den Refresh-Zyklen gibt.
Schnelle Fourier-Transformation
Irgendwann machte es Klick. Da wir ein Ereignis mit festem Intervall finden wollen, können wir die Daten in den FFT-Algorithmus (Fast Fourier Transform – schnelle Fourier-Transformation) einspeisen, der die zugrunde liegenden Frequenzen entschlüsselt.
Ich bin nicht der Erste, der diesen Gedanken hatte – der durch Rowhammer bekannte Mark Seaborn hat genau diese Technik bereits 2015 eingesetzt. Aber selbst nachdem ich einen Blick auf Marks Code geworfen hatte, musste ich feststellen, dass es schwieriger als erwartet war, die FFT zum Funktionieren zu bringen. Schließlich gelang es mir jedoch, die Teile des Puzzles zusammenzufügen.
Zuerst müssen wir die Daten vorbereiten. Bei der FFT müssen die Eingabedaten mit einem konstanten Abtastintervall abgetastet werden. Außerdem müssen wir die Daten zuschneiden, um das Rauschen zu reduzieren. Durch Herumprobieren fand ich heraus, dass die besten Ergebnisse erzielt werden, wenn die Daten vorverarbeitet werden:
- Kleine Werte (kleiner als der Durchschnitt x 1,8) von Schleifeniterationen werden ausgeschnitten, ignoriert und durch den Messwert „0“ ersetzt. Wir wollen das Rauschen nicht in den Algorithmus einspeisen.
- Alle anderen Werte werden durch „1“ ersetzt, da uns die Amplitude der Verzögerung durch Rauschen wirklich egal ist.
- Ich habe mich für ein Abtastintervall von 100 ns entschieden, aber jede Zahl bis zu einem Nyquist-Wert (doppelte erwartete Frequenz) funktioniert auch gut.
- Die Daten müssen mit festen Zeitabständen abgetastet werden, bevor sie in die FFT eingespeist werden. Alle vernünftigen Abtastmethoden funktionieren gut; ich habe am Ende eine einfache lineare Interpolation durchgeführt.
Der Algorithmus sieht ungefähr so aus:
UNIT=100ns
A = [(timestamp, loop_duration),...]
p = 1
for curr_ts in frange(fist_ts, last_ts, UNIT):
while not(A[p-1].timestamp <= curr_ts < A[p].timestamp):
p += 1
v1 = 1 if avg*1.8 <= A[p-1].duration <= avg*4 else 0
v2 = 1 if avg*1.8 <= A[p].duration <= avg*4 else 0
v = estimate_linear(v1, v2, A[p-1].timestamp, curr_ts, A[p].timestamp)
B.append( v )
Was mit meinen Daten einen ziemlich langweiligen Vektor wie diesen hier erzeugt:
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
Der Vektor ist jedoch ziemlich lang, normalerweise etwa ~200.000 Datenpunkte. Wenn die Daten so aufbereitet sind, sind wir bereit, sie in die FFT einzuspeisen!
C = numpy.fft.fft(B)
C = numpy.abs(C)
F = numpy.fft.fftfreq(len(B)) * (1000000000/UNIT)
Ziemlich einfach, oder? Daraus ergeben sich zwei Vektoren:
- C enthält komplexe Zahlen der Frequenzkomponenten. Wir sind nicht an komplexen Zahlen interessiert und können sie durch den Aufruf von abs() abflachen.
- F enthält Kennsätze dafür, welche Frequenzklasse an welcher Stelle im Vektor C liegt. Wir müssen sie auf Hz normieren – durch Multiplikation mit der Abtastfrequenz des Eingabevektors.
Das Ergebnis kann grafisch dargestellt werden:
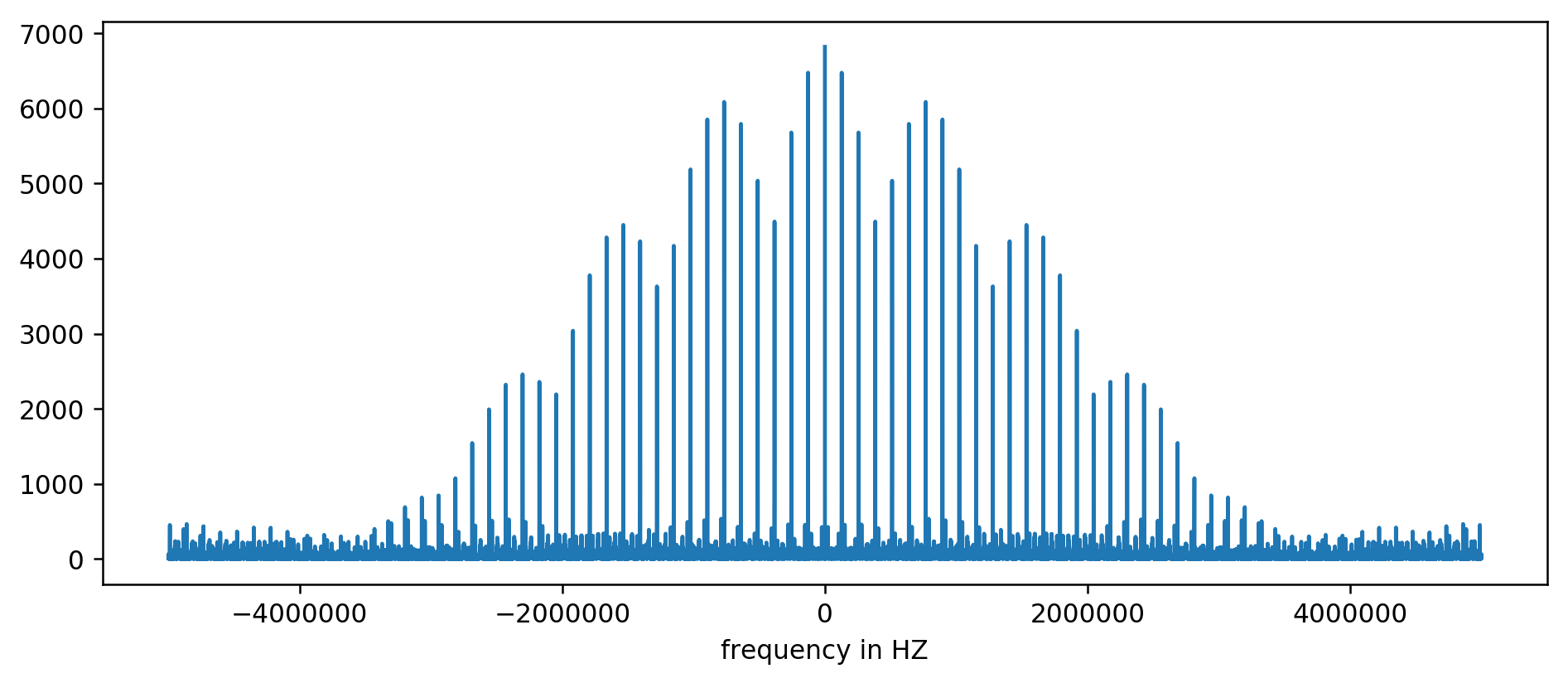
Die Y-Achse ist ohne Einheit, da wir die Verzögerungszeiten normiert haben. Dennoch zeigt sie deutliche Spitzen in einigen festen Frequenzintervallen. Zoomen wir rein:
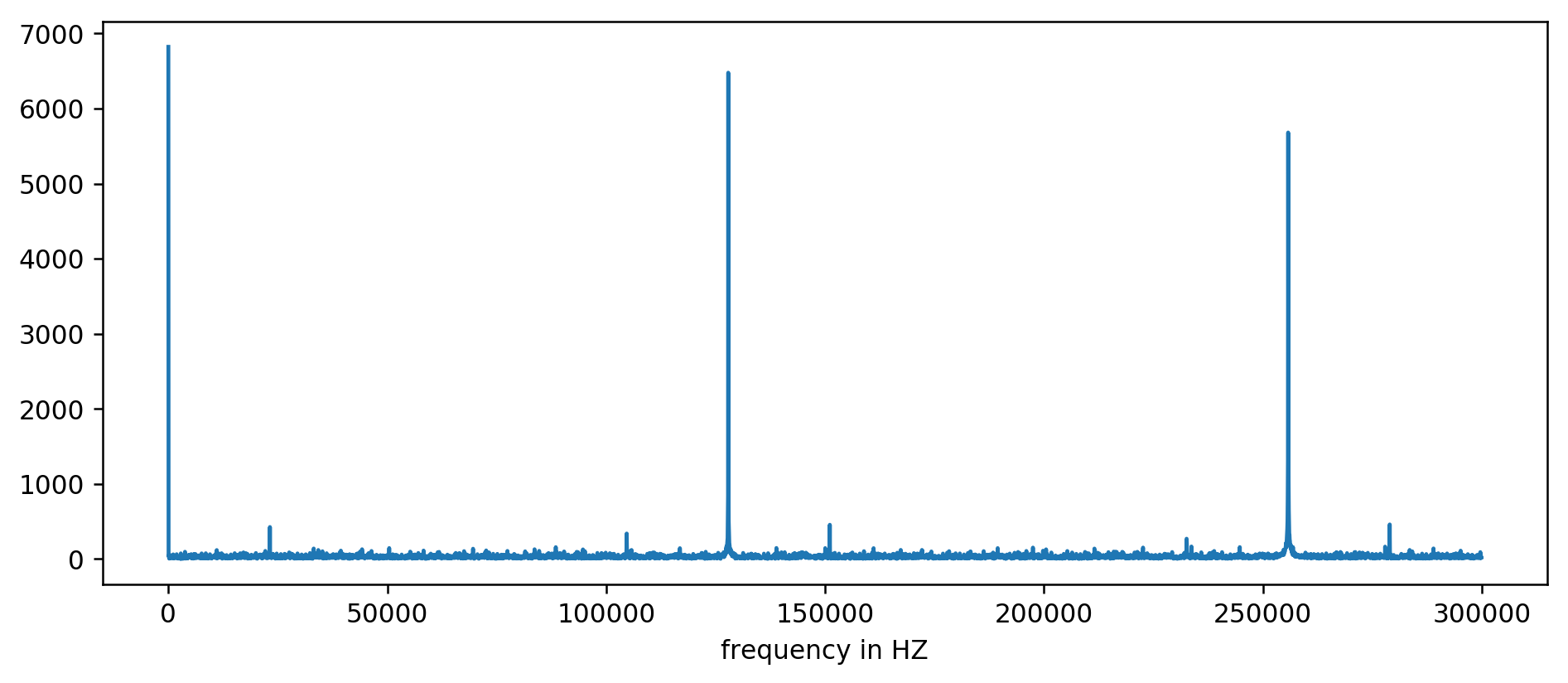
Wir können die ersten drei Spitzen deutlich sehen. Nach ein wenig Herumrechnen, bei dem Messwerte, die mindestens zehnmal so groß wie der Durchschnitt sind, herausgefiltert werden, können wir die zugrunde liegenden Frequenzen extrahieren:
127850.0
127900.0
127950.0
255700.0
255750.0
255800.0
255850.0
255900.0
255950.0
383600.0
383650.0
Mathematisch ausgedrückt: 1000000000 (ns/s) / 127900 (Hz) = 7818,6 ns
Hurra! Die erste Frequenzspitze ist in der Tat das, wonach wir gesucht haben, und korreliert tatsächlich mit den Refresh-Zeiten.
Die anderen Spitzen bei 256 kHz, 384 kHz, 512 kHz und so weiter sind Multiplikatoren unserer Basisfrequenz von 128 kHz, sogenannte Oberwellen. Dabei handelt es sich um einen zu erwartenden Nebeneffekt der Durchführung von FFT bei etwas wie einer Rechteckwelle.
Um das Experimentieren zu erleichtern, haben wir eine Kommandozeilenversion dieses Tools erstellt. Sie können den Code selbst ausführen. Hier ist ein Probelauf auf meinem Server:
~/2018-11-memory-refresh$ make
gcc -msse4.1 -ggdb -O3 -Wall -Wextra measure-dram.c -o measure-dram
./measure-dram | python3 ./analyze-dram.py
[*] Verifying ASLR: main=0x555555554890 stack=0x7fffffefe2ec
[ ] Fun fact. I did 40663553 clock_gettime()'s per second
[*] Measuring MOVQ + CLFLUSH time. Running 131072 iterations.
[*] Writing out data
[*] Input data: min=117 avg=176 med=167 max=8172 items=131072
[*] Cutoff range 212-inf
[ ] 127849 items below cutoff, 0 items above cutoff, 3223 items non-zero
[*] Running FFT
[*] Top frequency above 2kHz below 250kHz has magnitude of 7716
[+] Top frequency spikes above 2kHZ are at:
127906Hz 7716
255813Hz 7947
383720Hz 7460
511626Hz 7141
Ich muss zugeben, dass der Code nicht ganz stabil ist. Falls Probleme auftreten, sollten Sie die Deaktivierung von Turbo Boost, CPU-Frequenzskalierung und Leistungsoptimierung in Betracht ziehen.
Abschluss
Es gibt zwei Erkenntnisse aus dieser Arbeit.
Wir haben gesehen, dass die Low-Level-Daten ziemlich schwer zu analysieren sind und ziemlich verrauscht zu sein scheinen. Anstatt zu versuchen, etwas mit bloßem Auge zu erkennen, können wir immer auf die gute alte FFT zurückgreifen. Bei der Vorbereitung der Daten ist ein gewisses Wunschdenken erforderlich.
Am wichtigsten ist, dass wir gezeigt haben, dass es oft möglich ist, subtiles Hardware-Verhalten anhand eines einfachen Userspace-Prozesses zu messen. Diese Art von Denken führte zur Entdeckung der ursprünglichen Rowhammer-Schwachstelle, wurde bei Meltdown/Spectre-Angriffen eingesetzt und zeigte sich erneut beim jüngsten Einsatz von Rowhammer zur Überwindung von ECC.
Es gäbe noch sehr viel zu sagen. Wir haben kaum an der Oberfläche des Innenlebens des Speicher-Subsystems gekratzt. Für die weitere Lektüre empfehle ich:
- L3-Cache-Mapping von Sandy Bridge CPUs (auf Englisch)
- Wie physische Adressen auf Zeilen und Bänken im DRAM abgebildet werden (auf Englisch)
- Hannu Hartikainen hackt das DDR3 SO-DIMM, damit es ... langsamer wird (auf Englisch)
Und schließlich ist hier noch eine gute Lektüre über den alten Magnetkernspeicher:
Der Kernspeicher der PDP-11, erklärt von der University of Sydney (auf Englisch)