

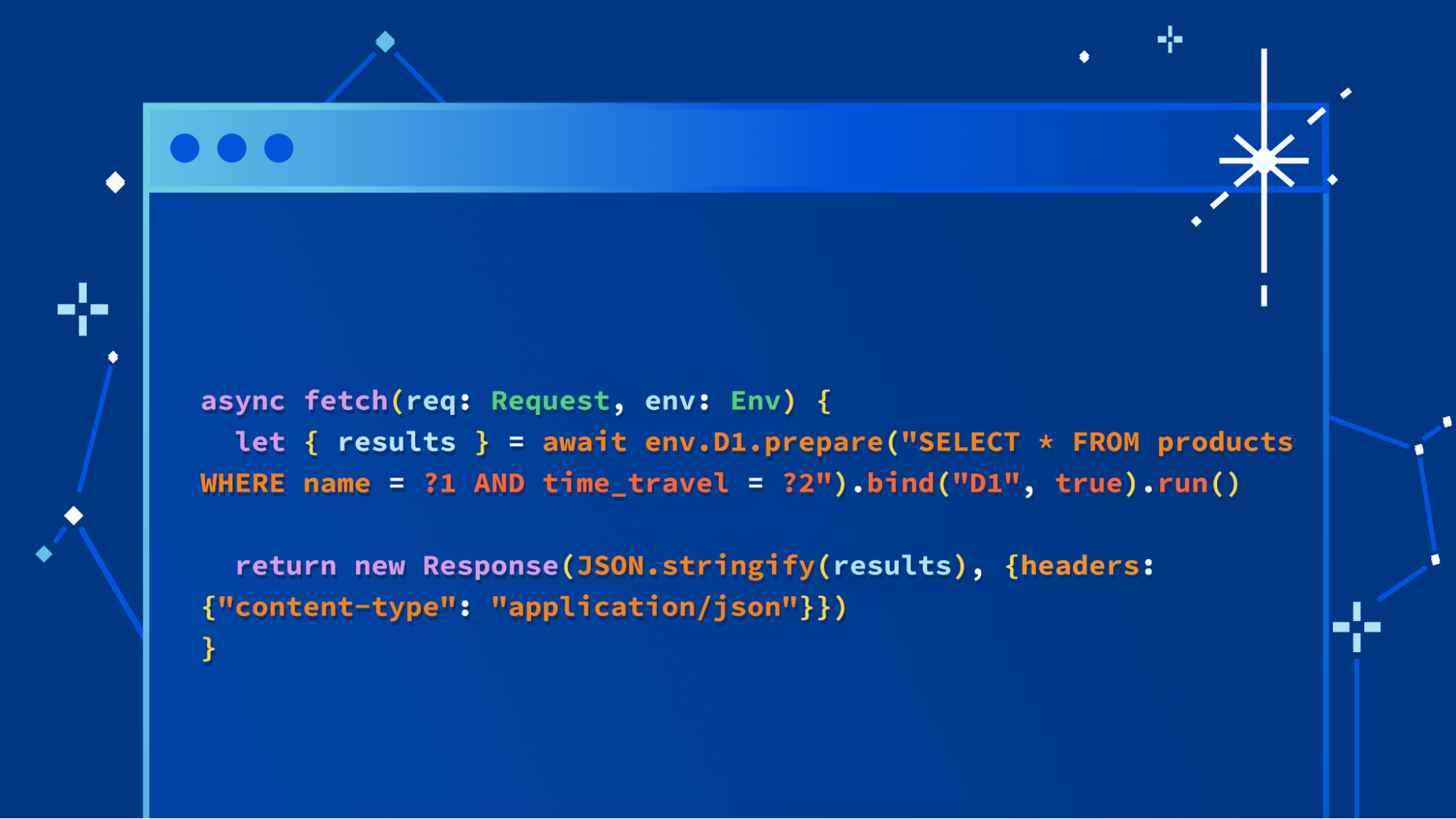
Wir wollen nicht lange um den heißen Brei herumreden: Wir freuen uns, ein größeres Update für unsere D1-Datenbank vorzustellen, das die Performance und Skalierbarkeit erheblich verbessert. Alpha-Nutzer (d.h. alle Workers-Nutzer) können ab sofort mit dem folgenden Befehl neue Datenbanken mit dem neuen Speicher-Backend erstellen:
$ wrangler d1 create your-database --experimental-backend
In den kommenden Wochen wird die neue Version standardmäßig für alle verfügbar sein, aber wir möchten Entwickler dazu einladen, bereits jetzt mit der neuen Version von D1 ein wenig zu experimentieren. In Kürze werden wir auch mehr darüber berichten, wie wir das neue Speichersubsystem von D1 entwickelt haben und wie es vom verteilten Netzwerk von Cloudflare profitiert..
Zur Erinnerung: Was ist D1?
D1 ist die native serverlose Datenbank von Cloudflare, die wir im November letzten Jahres in die Alpha-Phase gebracht haben. Entwickler haben komplexe Anwendungen mit Workers, KV, Durable Objects und neuerdings auch Queues & R2 erstellt, aber sie haben uns auch immer wieder um eines gebeten: eine abfragbare Datenbank.
Wir haben auch immer wieder gehört, dass es SQL-basiert und skalierbar sein sollte und (genau wie Workers selbst) dem Ansatz von „Region: Erde“ folgen sollte. Wir haben dieses Feedback aufgegriffen und uns daran gemacht, D1 zu entwickeln. Mit SQLite verfügen wir über einen vertrauten SQL-Dialekt, eine robuste Abfrage-Engine und eine der am besten getesteten Code-Basen, auf die wir aufbauen können.
Wir haben die erste Version von D1 als „echte“ Alpha-Version herausgebracht: eine Möglichkeit für uns, offen zu entwickeln, direktes Feedback von den Entwicklern einzuholen und besser zu priorisieren, was wichtig ist. Und wie es sich für eine Alpha-Version gehört, gab es Bugs, Performance-Probleme und einen ziemlich engen „Happy Path“.
Trotzdem haben wir beobachtet, dass Entwickler Tausende von Datenbanken eingerichtet und Milliarden von Abfragen durchgeführt haben. Beliebte ORMs wie Drizzle und Kysely unterstützen D1 (bereits!), und auch Remix- und Nuxt-Vorlagen bauen direkt darauf auf.
Wir setzen eins drauf
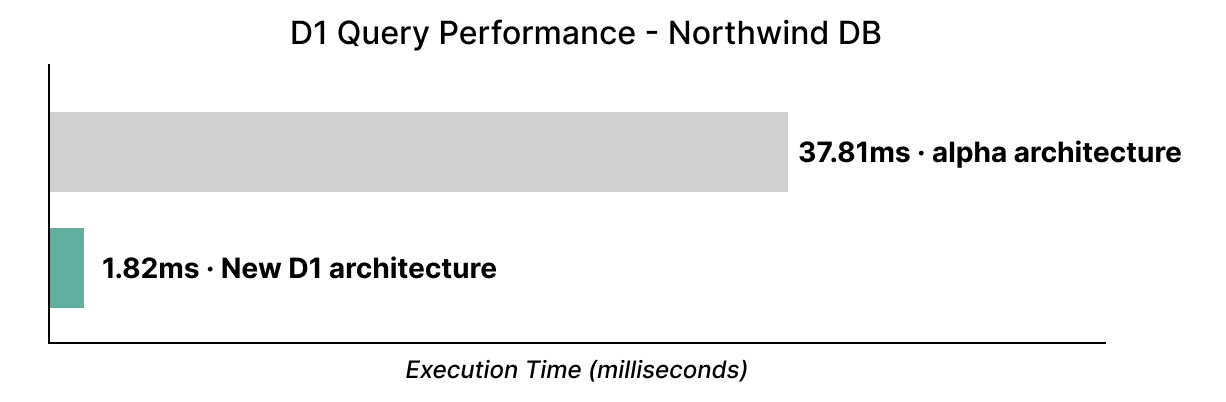
Wenn Sie D1 bisher in der Alphaversion genutzt haben: vergessen Sie alles, was Sie bisher kannten. D1 ist jetzt wesentlich schneller: bis zu 36x schneller in der bekannten Northwind Traders-Demo, die wir gerade auf unser neues Speicher-Backend umgestellt haben:
Unsere neue Architektur erhöht auch die Performance bei Schreibvorgängen: Ein einfacher Benchmark, bei dem 1.000 Zeilen (jede Zeile ist etwa 200 Byte breit) eingefügt werden, ist etwa 6,8-mal schneller als die vorherige Version von D1.
Bei größeren Batches (10.000 Zeilen mit einer Breite von ~200 Byte) ist die Verbesserung sogar noch deutlicher: zwischen 10- und 11-mal, wobei die Latenz des neuen Speicher-Backends auch deutlich einheitlicher ist. Dabei haben wir noch gar nicht damit begonnen, unseren gesamten Schreibdurchsatz zu optimieren, sodass wir erwarten, dass D1 hier noch schneller wird.
Mit unserem neuen Speicher-Backend möchten wir auch klarstellen, dass D1 nicht irgendein Spielzeug ist. Wir führen ständig Benchmarking-Tests unserer Performance mit anderen serverlosen Datenbanken durch. Bei einer Abfrage einer 500.000 Zeilen umfassenden Key-Value-Datenbank (wobei zu berücksichtigen ist, dass Benchmarks naturgemäß synthetisch sind) ist D1 etwa 3,2x schneller als ein beliebter serverloser Postgres-Anbieter:
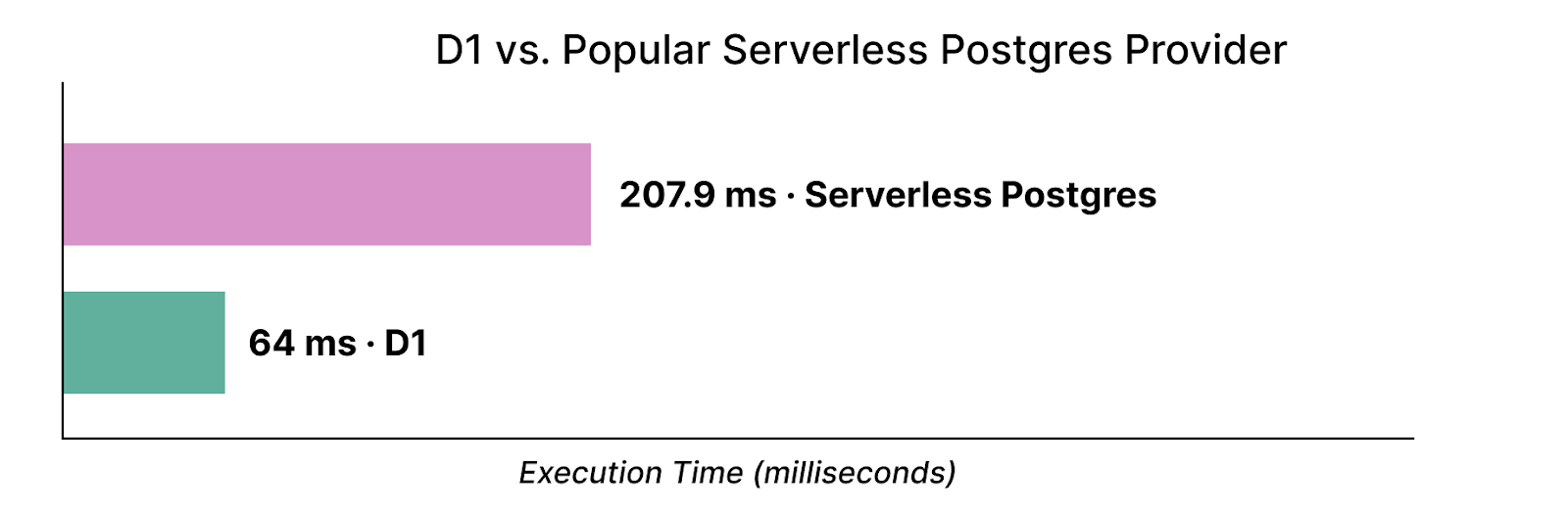
Wir haben die Postgres-Abfragen mehrmals ausgeführt, um den Seiten-Cache vorzubereiten, und dann die vom Server gemessene mittlere Abfragezeit ermittelt. Wir werden unseren Performance-Vorsprung auch in Zukunft weiter ausbauen.
Entwickler mit bestehenden Datenbanken können Daten in eine neue Datenbank importieren, die von der Storage-Engine unterstützt wird, indem sie die Schritte zum Exportieren ihrer Datenbank und anschließendem Importieren in unserer Dokumentation befolgen.
Was habe ich verpasst?
Wir haben auch an einer Reihe von Verbesserungen der D1-Entwicklererfahrung gearbeitet:
- Eine neue Konsole, die es Ihnen ermöglicht, Abfragen direkt vom Dashboard aus zu erstellen, was den Einstieg erleichtert und/oder einmalige Abfragen ermöglicht.
- Formale Unterstützung für JSON-Funktionen, die JSON direkt in Ihrer Datenbank abfragen.
- Location Hints (Standorthinweise), mit denen Sie beeinflussen können, wo sich Ihr Leader (der für Schreibvorgänge zuständig ist) weltweit befindet.
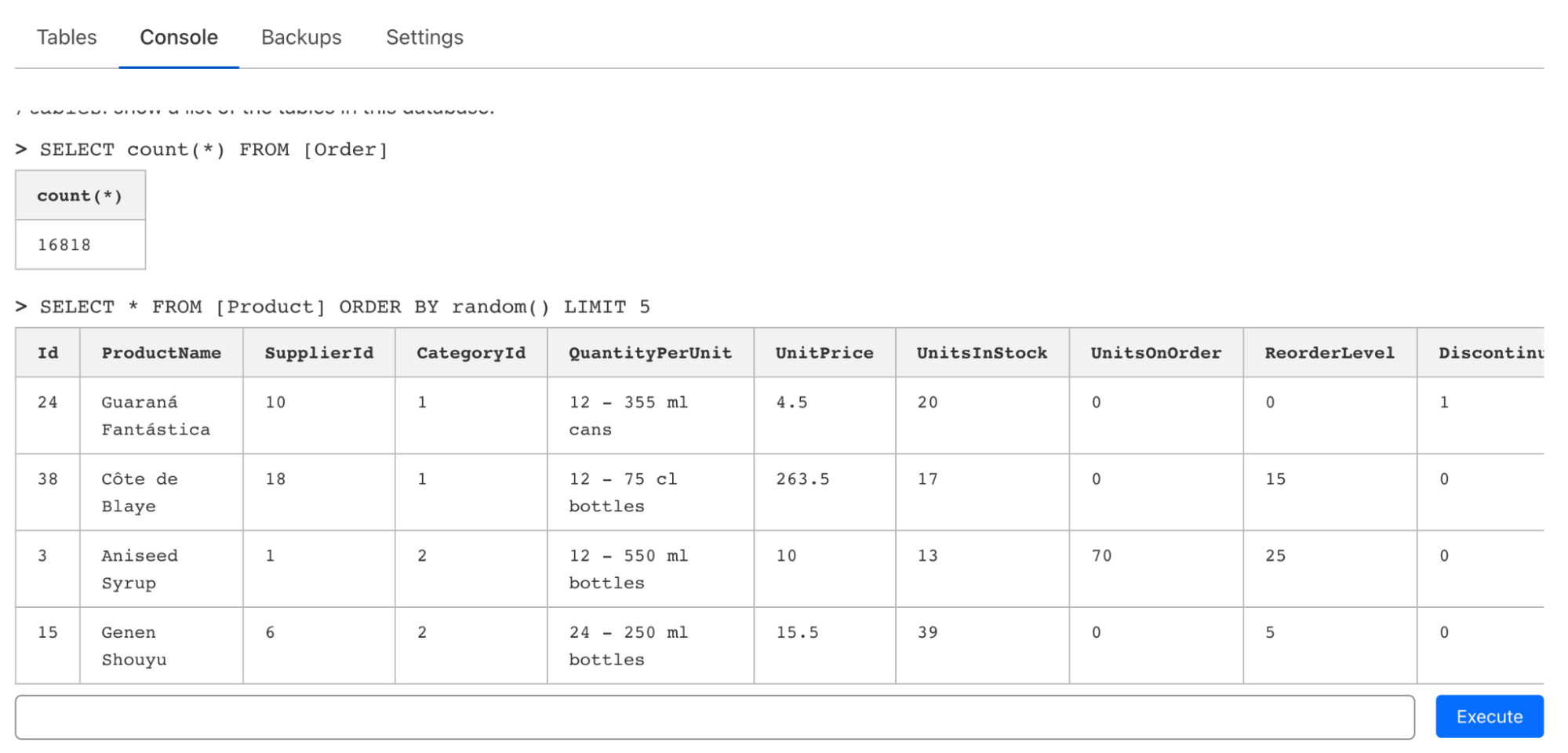
Obwohl D1 so konzipiert ist, dass es nativ in Cloudflare Workers funktioniert, ist uns klar, dass es oft notwendig ist, beim Prototyping oder bei der Erkundung einer Datenbank schnell einmalige Abfragen über CLI oder einen Webeditor zu erstellen. Zusätzlich zur Wrangler-Unterstützung für die Ausführung von Abfragen (und Dateien) haben wir einen Konsolen-Editor eingeführt, mit dem Sie Abfragen erstellen, Tabellen prüfen und sogar Daten im laufenden Betrieb bearbeiten können:
JSON-Funktionen ermöglichen Ihnen die Abfrage von JSON-Daten, die in TEXT-Spalten in D1 gespeichert ist: So können Sie flexibel entscheiden, welche Daten ausschließlich mit Ihrem relationalen Datenbankschema verknüpft sind und welche nicht, während Sie dennoch in der Lage sind, alle Daten über SQL abzufragen (bevor sie Ihre Anwendung erreichen).
Nehmen wir zum Beispiel an, Sie speichern die Zeitstempel der letzten Anmeldung als JSON-Array in einer login_history TEXT-Spalte: Ich kann Unterobjekte oder Array-Elemente direkt abfragen (und extrahieren), indem ich einen Pfad zu ihrem Schlüssel angebe:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
Die Unterstützung von D1 für JSON-Funktionen ist äußerst flexibel und nutzt den SQLite-Core, auf dem D1 aufbaut.
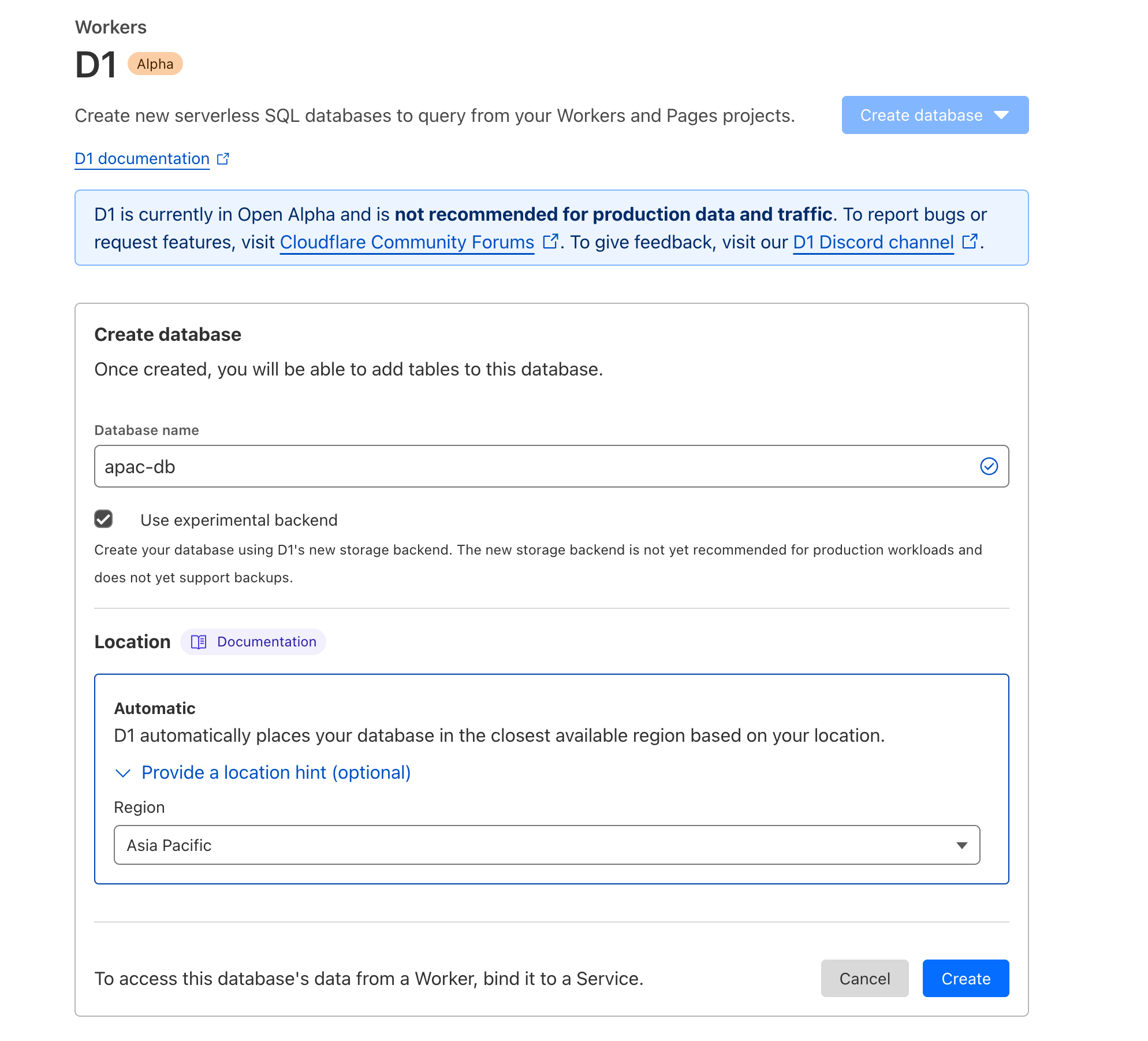
Wenn Sie zum ersten Mal eine Datenbank mit D1 erstellen, leiten wir den Standort automatisch daraus ab, von wo aus Sie sich gerade verbinden. Es gibt jedoch einige Fälle, in denen Sie das beeinflussen möchten – vielleicht sind Sie auf Reisen oder Sie haben ein verteiltes Team, das sich von der Region unterscheidet, aus der Sie die meisten Ihrer Schreibvorgänge erwarten.
Die D1-Unterstützung für Location Hints macht das ganz einfach:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints sind jetzt auch im Cloudflare Dashboard verfügbar:
Wir haben auch mehr Dokumentation veröffentlicht, um Entwicklern nicht nur den Einstieg, sondern auch die Nutzung der erweiterten Funktionen von D1 zu erleichtern. In den kommenden Monaten wird die Dokumentation von D1 noch erheblich erweitert werden.
Wird Sie kein Vermögen kosten
Seit der Ankündigung der Alpha-Phase haben uns viele Entwickler gefragt, wie die Preise für D1 aussehen werden. Wir sind nun bereit, Ihnen nähere Infos zu den Preisen mitzuteilen. Wir wissen, dass Sie die Kosten kennen sollten, bevor Sie mit der Entwicklung beginnen, um später nicht überrascht zu werden.
Auf den Punkt gebracht:
- Wir geben die Preise bekannt, sodass Sie schon im Voraus modellieren können, wie viel D1 für Ihren Anwendungsfall kosten wird. Die endgültige Preisgestaltung kann sich noch ändern, obwohl wir davon ausgehen, dass die Änderungen relativ gering ausfallen werden.
- Wir werden die Abrechnung erst zu einem späteren Zeitpunkt in diesem Jahr aktivieren und bestehende Nutzer von D1 per E-Mail über diese Änderung informieren. Bis dahin bleibt die Nutzung von D1 kostenlos.
- D1 wird eine dauerhaft kostenlose Tarifstufe beinhalten, die Nutzung ist in unserem 5 USD/Monat Workers-Abonnement inbegriffen, und die Abrechnung erfolgt auf der Grundlage von Lese- und Schreibvorgängen und Speicherplatz.
Wenn Sie Workers bereits abonniert haben, müssen Sie keinen Finger rühren: Ihr bestehendes Abonnement wird die D1-Nutzung einschließen, wenn wir die Abrechnung in Zukunft aktivieren.
Hier ist eine Zusammenfassung (bewusst einfach gehalten):

Wichtig ist, dass Sie, wenn wir die globale Lesereplikation aktivieren, weder extra dafür bezahlen müssen, noch wird die Replikation Ihren Speicherverbrauch vervielfachen. Wir sind der Meinung, dass eine integrierte, automatische Replikation wichtig ist und dass Entwickler keine multiplikativen Kosten (Replikate x Speichergebühren) zahlen sollten, um ihre Datenbank überall zu beschleunigen.
Darüber hinaus wollten wir sicherstellen, dass D1 die besten Aspekte der serverlosen Preisgestaltung nutzt: Skalierung bis zum Nullpunkt und nutzungsbasierte Abrechnung. So müssen Sie nicht versuchen zu ermitteln, wie viele CPUs und/oder wie viel Arbeitsspeicher Sie für Ihre Arbeitslast benötigen, oder Skripte schreiben, um Ihre Infrastruktur in den ruhigeren Stunden herunterzufahren.
Die D1-Preise für Lesevorgänge basieren auf dem bekannten Konzept einer Leseeinheit (pro 4 KB gelesen) und einer Schreibeinheit (pro 1 KB geschrieben). Eine Abfrage, die ~10.000 Zeilen zu je 64 Byte liest (scannt), würde 160 Leseeinheiten verbrauchen. Schreiben Sie eine große 3KB-Zeile in eine „blog_posts“-Tabelle, die eine Menge Markdown enthält, so sind das drei Schreibeinheiten. Und wenn Sie Indizes für Ihre beliebtesten Abfragen erstellen, um die Performance zu verbessern und die Datenmenge zu reduzieren, die diese Abfragen durchsuchen müssen, senken Sie auch die Kosten, die wir Ihnen in Rechnung stellen. Wir glauben, dass es der richtige Ansatz ist, den schnellen Pfad standardmäßig kosteneffizienter zu machen.
Wichtig: Wir werden auch weiterhin Feedback zu unserer Preisgestaltung einholen, bevor wir die Abrechnung aktivieren.
Time Travel
Wir führen auch eine neue Backup-Funktion ein: die Point-in-Time-Wiederherstellung, die wir Time Travel nennen, weil sie sich genau so anfühlt. Mit Time Travel können Sie Ihre D1-Datenbank bis zu einer beliebigen Minute innerhalb der letzten 30 Tage wiederherstellen. Die Funktion wird in D1-Datenbanken integriert, die unser neues Speichersystem nutzen. Wir gehen davon aus, dass wir Time Travel in naher Zukunft für neue D1-Datenbanken aktivieren werden.
Was Time Travel wirklich leistungsstark macht, ist, dass Sie nicht mehr in Panik geraten und sich fragen müssen: „Oh, Moment einmal, habe ich ein Backup gemacht, bevor ich diese wichtige Änderung vorgenommen habe?“ – weil wir das für Sie tun. Wir zeichnen alle Änderungen an Ihrer Datenbank auf (das Write-Ahead Log), und können so Ihre Datenbank zu einem bestimmten Zeitpunkt wiederherstellen, indem wir die Änderungen bis zu diesem Zeitpunkt nacheinander abspielen.
Hier ist ein Beispiel (vorbehaltlich einiger kleinerer API-Änderungen):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
Und obwohl die Idee der Point-in-Time-Wiederherstellung nicht neu ist, handelt es sich dabei oft um ein kostenpflichtiges Add-on, wenn es überhaupt verfügbar ist. Wenn Sie feststellen, dass Sie die Funktion hätten aktivieren sollen, nachdem Sie etwas gelöscht oder einen anderen Fehler gemacht haben, ist es oft schon zu spät.
Stellen Sie sich zum Beispiel vor, ich würde den klassischen Fehler machen, ein WHERE bei einer UPDATE-Anweisung zu vergessen:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Ohne Time Travel müsste ich hoffen, dass entweder kürzlich ein geplantes Backup durchgeführt wurde oder dass ich immer daran denke, kurz zuvor ein manuelles Backup zu erstellen. Mit Time Travel kann ich zu einem Punkt zurückkehren, der etwa eine Minute vor diesem Fehler liegt (und hoffentlich daraus für das nächste Mal lernen).
Wir arbeiten auch an Funktionen, mit denen größere Änderungen am Zustand Ihrer Datenbank sichtbar gemacht werden können. Dazu gehört, dass Schemaänderungen, die Anzahl der Tabellen, große Deltas in den gespeicherten Daten und sogar bestimmte Abfragen (über Transaktions-IDs) — leichter identifiziert werden können – damit Sie besser verstehen, zu welchem Zeitpunkt Sie Ihre Datenbank wiederherstellen müssen.
In Vorbereitung
Wie geht es weiter mit D1?
- Open Beta: Wir stellen sicher, dass wir unser neues Speichersubsystem unter Last (und in der realen Nutzung) beobachtet haben, bevor wir es standardmäßig für alle `d1 create` – Befehle einsetzen. Wir legen die Messlatte für Haltbarkeit und Verfügbarkeit hoch, selbst für eine „Beta“, und wir wissen auch, dass der Zugang zu Backups (Time Travel) wichtig ist, damit die Benutzer einer neuen Datenbank vertrauen. Schauen Sie in den kommenden Wochen regelmäßig in den Cloudflare-Blog, um weitere Neuigkeiten zu erfahren!
- Größere Datenbanken: Wir sind uns bewusst, dass sich viele Nutzer diese Funktion besonders dringend wünschen. Wir arbeiten auch schon hart an der Implementierung. Entwickler mit dem Workers Paid-Tarif werden in naher Zukunft Zugang zu 1 GB großen Datenbanken erhalten, und wir werden die maximale Größe pro Datenbank im Laufe der Zeit weiter erhöhen.
- Metriken und Beobachtbarkeit: Sie können das Gesamtabfragevolumen nach Datenbank, fehlgeschlagenen Abfragen, verbrauchtem Speicherplatz und Lese-/Schreibeinheiten sowohl über das D1-Dashboard als auch über unsere GraphQL-API einsehen, sodass Sie einfacher Probleme beheben und Ausgaben verfolgen können.
- Automatische Lese-Replikation: Unser neues Speichersubsystem wurde mit Blick auf die Replikation entwickelt, und wir arbeiten daran, dass unsere Replikationsschicht sowohl schnell als auch zuverlässig ist, bevor wir sie für Entwickler bereitstellen. Die Replikation von Lesevorgängen soll nicht nur die Abfragelatenz verbessern, indem Kopien – Replikate – Ihrer Daten an mehreren Orten in der Nähe Ihrer Nutzer gespeichert werden, sondern sie ermöglicht uns auch die horizontale Skalierung von D1-Datenbanken für diejenigen, die größere Arbeitslasten haben.
In der Zwischenzeit können Sie mit D1 Prototypen erstellen und experimentieren, unser D1 + Drizzle + Remix Beispielprojekt erkunden, oder dem #d1 channel im Cloudflare Developers Discord Server beitreten, um sich direkt mit dem D1-Team und anderen, die an D1 arbeiten, auszutauschen.