


Für die Erstellung großer Sprachmodelle (LLMs) und Diffusionsmodelle, die der generativen KI zugrunde liegen, benötigt man eine umfangreiche Infrastruktur. Am offensichtlichsten ist die Rechenleistung – Hunderte bis Tausende Grafikprozessoren – aber eine ebenso wichtige (und oft übersehene) Komponente ist die Infrastruktur für die Datenspeicherung. Trainingsdatensätze können Terabytes bis Petabytes groß sein, und diese Daten müssen von Tausenden von Prozessen parallel gelesen werden. Außerdem müssen während eines Trainingslaufs häufig Modell-Checkpoints gespeichert werden. Bei LLMs können diese Checkpoints jeweils Hunderte Gigabyte groß sein!
Um Speicherkosten und Skalierbarkeit in den Griff zu bekommen, haben viele Machine-Learning-Teams auf Objektspeicher umgestellt, um ihre Datensätze und Checkpoints zu hosten. Leider verwenden die meisten Anbieter von Objektspeichern Egress-Kosten, um Nutzer an ihre Plattform „zu binden“. Dadurch wird es sehr schwierig, GPU-Kapazitäten über mehrere Cloud-Anbieter hinweg zu nutzen oder anderswo von niedrigeren / dynamischen Preisen zu profitieren, da es zu teuer ist, die Daten und Modell-Checkpoints zu verschieben. In einer Zeit, in der Cloud-GPUs Mangelware sind und neue Hardware-Optionen auf den Markt kommen, ist es wichtiger denn je, flexibel zu bleiben.
Zusätzlich zu den hohen Egress-Kosten gibt es ein technisches Hindernis für das Training von Machine Learning-Modellen auf der Basis von Objektspeichern. Das Lesen und Schreiben von Daten zwischen Objektspeicher und Compute-Clustern erfordert einen hohen Durchsatz, eine effiziente Nutzung der Netzwerkbandbreite, Determinismus und Elastizität (die Fähigkeit, auf verschiedenen GPUs zu trainieren). Eine Trainingssoftware zu entwickeln, die all dies korrekt und zuverlässig handhabt, ist schwierig!
Heute möchten wir Ihnen zeigen, wie Sie die Tools von MosaicML und Cloudflare R2 gemeinsam nutzen können, um diese Herausforderungen zu meistern. Erstens können Sie mit den Open-Source-Bibliotheken StreamingDataset und Composer ganz einfach Trainingsdaten einspeisen (streamen) und Modell-Checkpoints lesen bzw. wieder auf R2 schreiben. Alles, was Sie brauchen, ist eine Internetverbindung. Zweitens können Sie dank der Zero-Egress-Preise von R2 Aufträge je nach GPU-Verfügbarkeit und Preisen bei verschiedenen Rechenanbietern starten/stoppen/verschieben/vergrößern, ohne Gebühren für die Datenübertragung zu zahlen. Die MosaicML-Trainingsplattform macht es kinderleicht, solche Trainingsaufträge über mehrere Clouds hinweg zu orchestrieren.
Zusammen geben Cloudflare und MosaicML Ihnen die Freiheit, LLMs auf jedem beliebigen Compute-Anbieter zu trainieren, überall auf der Welt, ohne Wechselkosten. Das bedeutet schnellere und billigere Trainingsläufe und keine Bindung an einen bestimmten Anbieter :)
Mit der MosaicML-Trainingsplattform können Kunden R2 effizient als dauerhaftes Storage-Backend für das Training von LLMs auf jedem Compute-Anbieter ohne Egress-Gebühren nutzen. KI-Unternehmen kämpfen oft mit horrenden Cloud-Kosten und suchen darum nach Tools, die ihnen die Geschwindigkeit und Flexibilität bieten, um ihr bestes Modell zum günstigsten Preis zu trainieren.“
– Naveen Rao, CEO und Mitbegründer, MosaicML
Daten von R2 mit StreamingDataset lesen
Um Daten von R2 effizient und deterministisch zu lesen, können Sie die StreamingDataset-Bibliothek von MosaicML verwenden. Schreiben Sie zunächst Ihre Trainingsdaten (Bilder, Text, Video, alles!) in `.mds` Shard-Dateien mit Hilfe der bereitgestellten Python-API:
import numpy as np
from PIL import Image
from streaming import MDSWriter
# Local or remote directory in which to store the compressed output files
data_dir = 'path-to-dataset'
# A dictionary mapping input fields to their data types
columns = {
'image': 'jpeg',
'class': 'int'
}
# Shard compression, if any
compression = 'zstd'
# Save the samples as shards using MDSWriter
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
Nachdem Ihr Datensatz konvertiert wurde, können Sie ihn zu R2 hochladen. Im Folgenden demonstrieren wir dies mit dem Kommandozeilentool `awscli`, doch Sie können auch `wrangler` oder jedes andere S3-kompatible Tool Ihrer Wahl verwenden. StreamingDataset wird bald auch das direkte Schreiben in die R2-Cloud unterstützen!
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/folder --endpoint-url $S3_ENDPOINT_URL
Schließlich können Sie die Daten auf jedem Gerät lesen, das Lesezugriff auf Ihren R2-Bucket hat. Sie können einzelne Stichproben abrufen, eine Schleife über den Datensatz laufen lassen und ihn in einen standardmäßigen PyTorch-Datenlader einspeisen.
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/folder'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
StreamingDataset bietet von Haus aus eine hohe Performance, elastischen Determinismus, schnelle Wiederaufnahme und Unterstützung für mehrere Mitarbeiter. Es verwendet außerdem intelligentes Shuffling und Verteilung, um sicherzustellen, dass die Download-Bandbreite minimiert wird. Bei einer Vielzahl von Workloads wie LLMs und Diffusionsmodellen haben wir festgestellt, dass es keine Auswirkungen auf den Durchsatz an Trainingsdaten gibt (kein Engpass im Datenlader), wenn das Training aus Objektspeichern wie R2 erfolgt. Weitere Informationen finden Sie im Blog-Beitrag zur Ankündigung von StreamingDataset!
Lesen/Schreiben von Modell-Checkpoints in R2 mit Composer
Das Einspeisen von Daten in Ihre Trainingsschleife löst die Hälfte des Problems, aber wie laden/speichern Sie Ihre Modell-Checkpoints? Wenn Sie eine Trainingsbibliothek wie Composer verwenden, ist das zum Glück ein Kinderspiel: Sie müssen nur auf einen R2-Pfad verweisen!
from composer import Trainer
...
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
trainer = Trainer(
run_name='mpt-7b',
model=model,
train_dataloader=train_loader,
...
save_folder=s3://my-bucket/mpt-7b/checkpoints,
save_interval='1000ba',
# load_path=s3://my-bucket/mpt-7b-prev/checkpoints/ep0-ba100-rank0.pt,
)
Composer verwendet asynchrone Uploads, um die Wartezeit zu minimieren, da die Checkpoints während des Trainings gespeichert werden. Es funktioniert auch sofort mit Multi-GPU- und Multi-Node-Training und benötigt kein gemeinsames Dateisystem. Das bedeutet, dass Sie die Einrichtung eines teuren EFS/NFS-Systems für Ihren Compute-Cluster überspringen können und so Tausende von Dollar oder mehr pro Monat in öffentlichen Clouds sparen. Alles, was Sie brauchen, ist eine Internetverbindung und entsprechende Anmeldedaten – Ihre Checkpoints kommen sicher in Ihrem R2-Bucket an und bieten Ihnen skalierbaren und sicheren Speicher für Ihre privaten Modelle.
Mit MosaicML und R2 können Sie überall effizient trainieren
Die Verwendung der oben genannten Tools zusammen mit Cloudflare R2 ermöglicht es Nutzern, Trainings-Workloads auf jedem Compute-Provider auszuführen, und zwar völlig frei und ohne Wechselkosten.
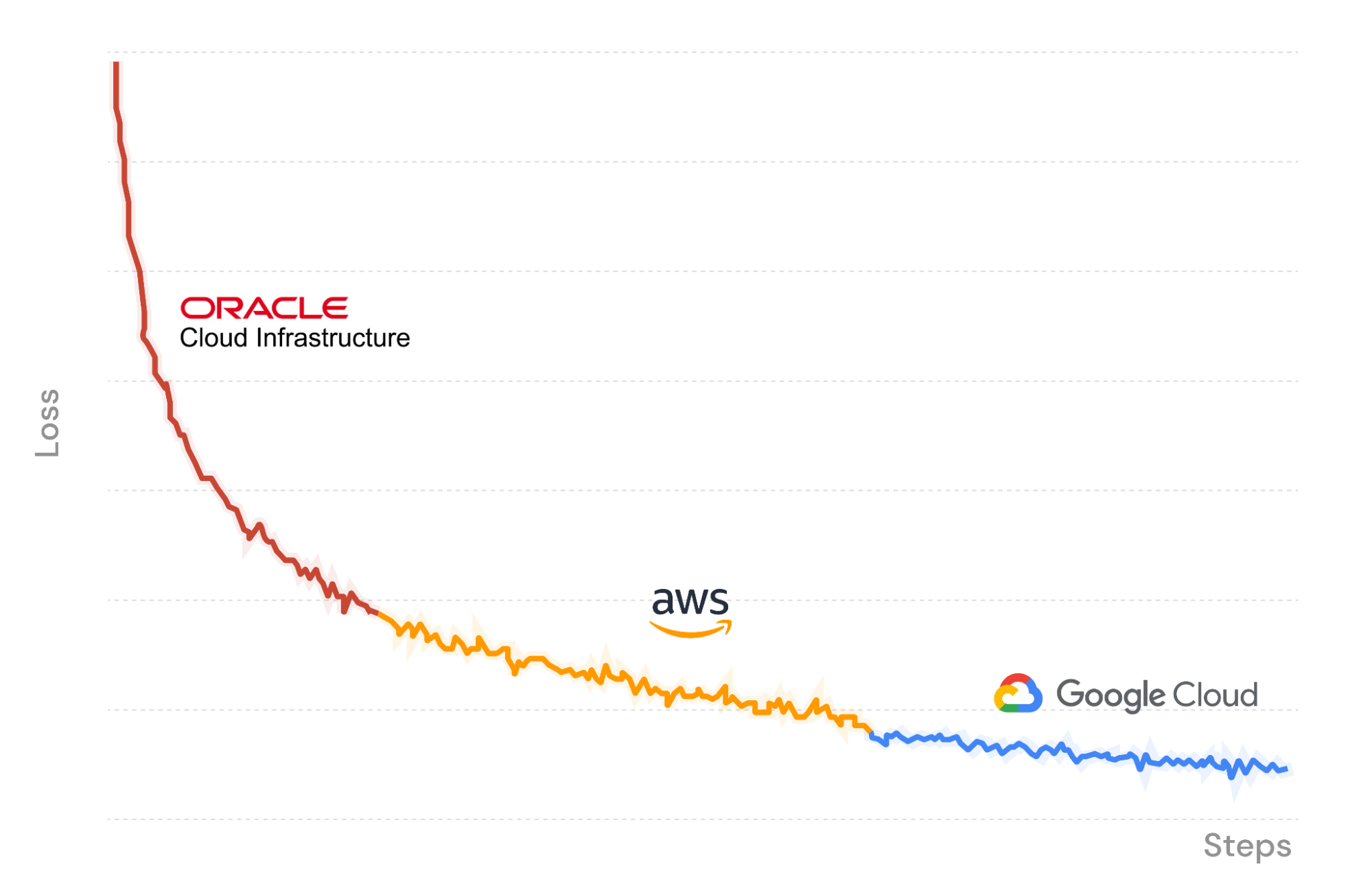
Zur Veranschaulichung verwenden wir in Abbildung X die MosaicML-Trainingsplattform, um einen LLM-Trainingsauftrag zu starten, der auf der Oracle Cloud Infrastructure beginnt, wobei Daten eingespeist und Checkpoints zurück auf R2 hochgeladen werden. Auf halbem Weg halten wir den Job an und setzen ihn nahtlos auf einem anderen Satz von GPUs bei Amazon Web Services fort. Composer lädt die Gewichtungen des Modells vom letzten gespeicherten Checkpoint in R2, und der Streaming-Datenlader fährt sofort mit dem richtigen Batch fort. Das Training wird deterministisch fortgesetzt. Schließlich wechseln wir wieder zu Google Cloud, um den Trainingslauf zu beenden.
Da wir unser LLM bei drei Cloud-Anbietern trainieren, zahlen wir nur die Kosten für die GPU-Rechenleistung und die Datenspeicherung. Keine Egress-Kosten oder Lock-Ins dank Cloudflare R2!
$ mcli get clusters
NAME PROVIDER GPU_TYPE GPUS INSTANCE NODES
mml-1 MosaicML │ a100_80gb 8 │ mosaic.a100-80sxm.1 1
│ none 0 │ cpu 1
gcp-1 GCP │ t4 - │ n1-standard-48-t4-4 -
│ a100_40gb - │ a2-highgpu-8g -
│ none 0 │ cpu 1
aws-1 AWS │ a100_40gb ≤8,16,...,32 │ p4d.24xlarge ≤4
│ none 0 │ cpu 1
oci-1 OCI │ a100_40gb 8,16,...,64 │ oci.bm.gpu.b4.8 ≤8
│ none 0 │ cpu 1
$ mcli create secret s3 --name r2-creds --config-file path/to/config --credentials-file path/to/credentials
✔ Created s3 secret: r2-creds
$ mcli create secret env S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
✔ Created environment secret: s3-endpoint-url
$ mcli run -f mpt-125m-r2.yaml --follow
✔ Run mpt-125m-r2-X2k3Uq started
i Following run logs. Press Ctrl+C to quit.
Cloning into 'llm-foundry'...
Verwendung des MCLI-Befehlszeilentools zur Verwaltung von Compute-Clustern, Secrets und Durchläufen zur Übermittlung.
### mpt-125m-r2.yaml ###
# set up secrets once with `mcli create secret ...`
# and they will be present in the environment in any subsequent run
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: main
pip_install: -e .[gpu]
image: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
cd llm-foundry/scripts
composer train/train.py train/yamls/mpt/125m.yaml \
data_remote=s3://bucket/path-to-data \
max_duration=100ba \
save_folder=s3://checkpoints/mpt-125m \
save_interval=20ba
run_name: mpt-125m-r2
gpu_num: 8
gpu_type: a100_40gb
cluster: oci-1 # can be any compute cluster!
Eine MCLI-Auftragsvorlage. Geben Sie einen Namen für den Trainingslauf, ein Docker-Image, eine Reihe von Befehlen und einen Compute-Cluster an, auf dem die Ausführung erfolgen soll.
Steigen Sie noch heute ein!
Die MosaicML-Plattform ist ein unschätzbares Werkzeug, um Ihr Training einmal mehr zu verbessern. In diesem Beitrag haben wir uns angesehen, wie Sie mit Cloudflare R2 Modelle auf Ihren eigenen Daten trainieren können, und zwar mit jedem beliebigen Compute-Anbieter – oder mit allen. Durch das Wegfallen von Egress-Kosten ist der R2-Speicher eine außerordentlich kosteneffiziente Ergänzung zum MosaicML-Training und bietet ein Höchstmaß an Autonomie und Kontrolle. Mit dieser Kombination können Sie im Laufe der Zeit zwischen verschiedenen Cloud-Service-Anbietern wechseln, um den Anforderungen Ihres Unternehmens gerecht zu werden.
Um mehr darüber zu erfahren, wie Sie MosaicML zum Trainieren von maßgeschneiderter, hochmoderner KI auf Ihren eigenen Daten verwenden können, besuchen Sie uns hier oder kontaktieren Sie uns.