


Entwickler und Entwicklerinnen, die Worker-Anwendungen entwickeln, konzentrieren sich auf die Erstellung ihrer Anwendungen (und nicht auf die erforderliche Infrastruktur) und profitieren von der globalen Reichweite des Cloudflare-Netzwerks. Viele Anwendungen benötigen persistente Daten, von persönlichen Projekten hin zu geschäftskritischen Workloads. Workers bietet verschiedene Datenbank- und Speicheroptionen, die auf die Bedürfnisse der Entwickler und Entwicklerinnen zugeschnitten sind, wie Schlüssel-Werte-Datenbanken und Objektspeicher.
Relationale Datenbanken sind heute das Rückgrat vieler Anwendungen. D1, die relationale Datenbankergänzung von Cloudflare, ist jetzt allgemein verfügbar. Bei der Weiterentwicklung von der Alpha-Version Ende 2022 bis zur GA-Version im April 2024 konzentrierten wir uns darauf, Entwicklern und Entwicklerinnen die Möglichkeit zu geben, Workloads in einer Produktionsumgebung mit der Vertrautheit von relationalen Daten und SQL zu erstellen.
Was ist D1?
D1 ist die integrierte, serverlose relationale Datenbank von Cloudflare. Für Worker-Anwendungen bietet D1 die Ausdruckskraft von SQL, indem es den SQL-Dialekt von SQLite nutzt, und die Integration von Entwicklertools, einschließlich objektrelationaler Mapper (ORMs) wie Drizzle ORM. D1 ist über Workers oder über eine HTTP-API zugänglich.
Serverless bedeutet keine Bereitstellung erforderlich, standardmäßige Notfallwiederherstellung mit Time Travel und nutzungsbasierte Preise. D1 umfasst eine großzügige kostenlose Tarifstufe, die es Entwicklern und Entwicklerinnen ermöglicht, mit D1 zu experimentieren und diese Versuche dann in eine Produktionsumgebung zu überführen.
Wie macht man Daten global?
D1 GA (allgemeine Verfügbarkeit) hat sich auf die Zuverlässigkeit und die Erfahrung der Entwickler und Entwicklerinnen konzentriert. Jetzt planen wir, D1 zu erweitern, um global verteilte Anwendungen besser zu unterstützen.
Im Workers-Modell ruft eine eingehende Anfrage die serverlose Ausführung im nächstgelegenen Rechenzentrum auf. Eine Worker-Anwendung kann global mit den Anfragen der Nutzer skalieren. Die Anwendungsdaten bleiben jedoch in zentralen Datenbanken gespeichert, und der globale Traffic der Nutzer muss die Hin- und Rückreise zu den Datenstandorten berücksichtigen. Eine D1-Datenbank zum Beispiel befindet sich heute an einem einzigen Ort.
Workers unterstützen Smart Placement, um die Lokalisierung von Daten zu berücksichtigen, auf die häufig zugegriffen wird. Smart Placement ruft einen Worker näher an zentralisierten Backend-Diensten wie Datenbanken auf, um die Latenz zu verringern und die Anwendungsperformance zu verbessern. Wir haben uns mit der Platzierung von Workers in globalen Anwendungen befasst, müssen aber noch die Thematik der Platzierung von Daten lösen.
Die Frage ist also, wie D1, die integrierte Datenbanklösung von Cloudflare, die Datenplatzierung für globale Anwendungen besser unterstützen kann. Die Antwort: asynchrone Lesereplikation.
Was ist asynchrone Lesereplikation?
In einem serverbasierten Datenbankmanagementsystem wie Postgres, MySQL, SQL Server oder Oracle ist ein Lesereplikat ein separater Datenbankserver, der als schreibgeschützte, nahezu aktuelle Kopie des primären Datenbankservers dient. Ein Administrator erstellt ein Lesereplikat, indem er einen neuen Server aus einem Snapshot des primären Servers startet und den primären Server so konfiguriert, dass er Updates asynchron an den Replikat-Server sendet. Da die Aktualisierungen asynchron erfolgen, kann das Lesereplikat hinter dem aktuellen Status des Primärservers zurückbleiben. Die Differenz zwischen dem Primärserver und einem Replikat wird als Verzögerung des Replikats („replica lag“) bezeichnet. Es ist möglich, mehr als ein Lesereplikat zu haben.
Die asynchrone Lesereplikation ist eine bewährte Lösung, um die Performance von Datenbanken zu verbessern:
- Es ist möglich, den Durchsatz zu erhöhen, indem die Last auf mehrere Replikate verteilt wird.
- Es ist möglich, die Abfragelatenz zu verringern, wenn sich die Replikate in der Nähe der abfragenden Nutzer befinden.
Beachten Sie, dass einige Datenbanksysteme auch synchrone Replikation anbieten. In einem synchron replizierten System müssen Schreibvorgänge warten, bis alle Replikate den Schreibvorgang bestätigt haben. Synchron replizierte Systeme können nur so schnell laufen wie das langsamste Replikat und kommen zum Stillstand, wenn ein Replikat ausfällt. Wenn wir versuchen, die Performance auf globaler Ebene zu verbessern, sollten wir synchrone Replikation so gut wie möglich vermeiden!
Konsistenzmodelle & Lesereplikate
Die meisten Datenbanksysteme bieten je nach Konfiguration Read-Committed-, Snapshot-Isolation- oder Serializable Konsistenzmodelle. Postgres beispielsweise ist standardmäßig auf Read-Committed eingestellt, kann aber so konfiguriert werden, dass es stärkere Modi verwendet. SQLite bietet Snapshot-Isolation im WAL-Modus. Stärkere Modi wie Snapshot-Isolation oder Serializable sind einfacher zu programmieren, da sie die zulässigen Parallelitätsszenarien des Systems und die Art der Parallelität-Rennbedingungen (Race-Conditions) einschränken, um die sich der Programmierer bzw. die Programmiererin kümmern muss.
Lesereplikate werden unabhängig voneinander aktualisiert, sodass die Inhalte der einzelnen Replikate zu jedem Zeitpunkt unterschiedlich sein können. Wenn alle Ihre Abfragen an denselben Server gehen, sei es der Primärserver oder ein Lesereplikat, sollten Ihre Ergebnisse einheitlich sein, je nachdem, welches Konsistenzmodell Ihrer zugrunde liegenden Datenbank konsistent sein. Wenn Sie ein Lesereplikat verwenden, sind die Ergebnisse möglicherweise nur ein wenig veraltet.
In einer serverbasierten Datenbank mit Lesereplikaten ist es wichtig, dass Sie für alle Abfragen in einer Sitzung denselben Server verwenden. Wenn Sie in derselben Sitzung zwischen verschiedenen Lesereplikaten wechseln, gefährden Sie das von Ihrer Anwendung bereitgestellte Konsistenzmodell, was gegen Ihre Annahmen über das Verhalten der Datenbank verstoßen und dazu führen kann, dass Ihre Anwendung falsche Ergebnisse liefert!
Beispiel
Beispiel: Es gibt zwei Replikate, A und B. Replikat A hinkt der primären Datenbank um 100 ms hinterher, Replikat B um 2 s. Angenommen, ein Benutzer möchte:
- Abfrage 1 ausführen
1a. Etwas Datenverarbeitung basierend auf den Ergebnissen von Abfrage 1 durchführen - Abfrage 2 auf der Grundlage der Ergebnisse der Datenverarbeitung in (1a) durchführen
Zum Zeitpunkt t=10 s geht die Abfrage 1 an Replikat A und kehrt zurück. Abfrage 1 zeigt, wie die primäre Datenbank bei t=9,9 s aussah. Angenommen, die Datenverarbeitung dauert 500 ms, sodass Abfrage 2 bei t=10,5 s an Replikat B geht. Denken Sie daran, dass Replikat B der primären Datenbank um 2 s hinterherhinkt, sodass Abfrage 2 bei t=10,5 s sieht, wie die Datenbank bei t=8,5 s aussieht. Für die Anwendung sehen die Ergebnisse von Abfrage 2 so aus, als wäre die Datenbank in der Zeit zurückgereist!
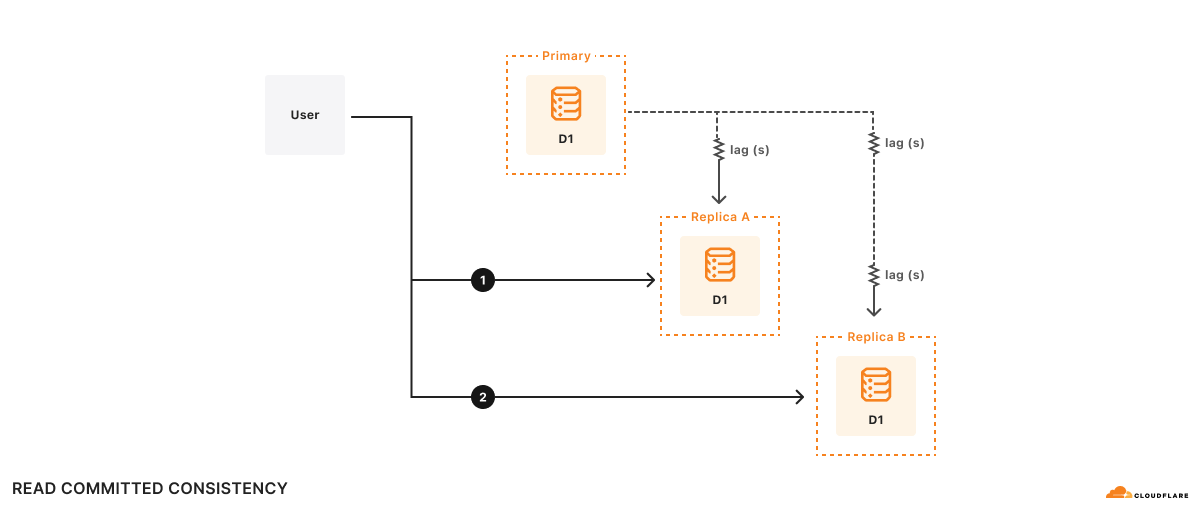
Formal handelt es sich dabei um Read-Committed-Konsistenz, da Ihre Abfragen nur Committed-Daten sehen, aber es gibt keine andere Garantie – nicht einmal, dass Sie Ihre eigenen Schreibvorgänge lesen können. Read-Committed ist zwar ein gültiges Konsistenzmodell, aber es ist schwer, über alle möglichen Rennbedingungen nachzudenken, die das Read-Committed-Modell zulässt, was es schwierig macht, Anwendungen korrekt zu schreiben.
Das Konsistenzmodell von D1 & Lesereplikate
Standardmäßig bietet D1 die Snapshot-Isolation, die SQLite bietet.
Die Snapshot-Isolation ist ein vertrautes Konsistenzmodell, das für die meisten Entwickler und Entwicklerinnen leicht zu handhaben ist. Wir implementieren dieses Konsistenzmodell in D1, indem wir sicherstellen, dass es höchstens eine aktive Kopie der D1-Datenbank gibt und alle HTTP-Anfragen an diese eine Datenbank weitergeleitet werden. Sicherzustellen, dass es höchstens eine aktive Kopie der D1-Datenbank gibt, ist zwar ein schwieriges Problem bei verteilten Systemen, aber wir haben es gelöst, indem wir D1 mit Durable Objects entwickelt haben. Durable Objects garantieren globale Eindeutigkeit. Sobald wir also von Durable Objects abhängig sind, ist das Routing von HTTP-Anfragen einfach: Senden Sie sie einfach an das D1 Durable Object.
Dieser Trick funktioniert nicht, wenn Sie mehrere aktive Kopien der Datenbank haben, da es keine 100 % zuverlässige Möglichkeit gibt, eine generische eingehende HTTP-Anfrage zu betrachten und sie zu 100 % an dasselbe Replikat weiterzuleiten. Wie wir im Beispiel des vorigen Abschnitts gesehen haben, ist das „Read-Committed“-Modell leider das beste Konsistenzmodell, das wir anbieten können, wenn wir zusammenhängende Anfragen nicht zu 100 % an dasselbe Replikat weiterleiten.
Da es unmöglich ist, ein bestimmtes Replikat einheitlich zu routen, besteht ein anderer Ansatz darin, Anfragen an ein beliebiges Replikat zu routen und sicherzustellen, dass das gewählte Replikat auf Anfragen gemäß einem Konsistenzmodell antwortet, das für den Programmierer „sinnvoll“ ist. Wenn wir bereit sind, einen Lamport-Zeitstempel in unsere Anfragen aufzunehmen, können wir sequenzielle Konsistenz mit jedem Replikat implementieren. Das sequenzielle Konsistenzmodell hat wichtige Eigenschaften wie Read-My-Own-Writes („Lese-meine-eigenen-Schreibvorgänge“) und Writes-Follow-Reads („Schreibvorgänge folgen Lesevorgängen“) sowie eine Gesamtreihenfolge der Schreibvorgänge. Die Gesamtreihenfolge der Schreibvorgänge bedeutet, dass bei jedem Replikat die Transaktionen in der gleichen Reihenfolge übertragen werden, was genau das Verhalten ist, das wir in einem transaktionalen System wünschen. Sequenzielle Konsistenz geht mit dem Vorbehalt einher, dass jede einzelne Entität im System beliebig veraltet sein kann, aber dieser Vorbehalt ist für uns ein Vorteil, da wir so bei der Entwicklung unserer APIs die Verzögerung der Replikate berücksichtigen können.
Der Gedanke dahinter ist, dass, wenn D1 den Anwendungen einen Lamport-Zeitstempel für jede Datenbankabfrage gibt und diese Anwendungen D1 den letzten Lamport-Zeitstempel mitteilen, den sie gesehen haben, wir jedes Replikat bestimmen lassen können, wie die Abfragen gemäß dem sequenziellen Konsistenzmodell funktionieren sollen.
Eine robuste und dennoch einfache Möglichkeit, sequenzielle Konsistenz mit Replikaten zu implementieren, ist die folgende:
- Verknüpfen Sie einen Lamport-Zeitstempel mit jeder einzelnen Anfrage an die Datenbank. Ein monoton ansteigender Commit-Token eignet sich hierfür gut.
- Senden Sie alle Schreibabfragen an die primäre Datenbank, um die Gesamtreihenfolge der Schreibvorgänge zu gewährleisten.
- Senden Sie Leseabfragen an ein beliebiges Replikat, aber lassen Sie das Replikat die Abfrage erst dann bearbeiten, wenn das Replikat Aktualisierungen von der primären Datenbank erhält, die nach dem Lamport-Zeitstempel in der Abfrage liegen.
Das Schöne an dieser Implementierung ist, dass sie in dem häufigen Fall, dass ein an Lesevorgängen reicher Workload immer an dasselbe Replikat geht, schnell ist und auch dann funktioniert, wenn Anforderungen an verschiedene Replikate weitergeleitet werden.
Exklusive Vorschau: Lesereplikation in D1 mit Sessions
Um die Lesereplikation in D1 zu ermöglichen, werden wir die D1-API um ein neues Konzept erweitern: Sessions. Eine Session kapselt alle Abfragen, die eine logische Sitzung für Ihre Anwendung darstellen. Eine Session könnte zum Beispiel alle Anfragen eines bestimmten Webbrowsers oder alle Anfragen einer mobilen Anwendung enthalten. Wenn Sie Sessions verwenden, nutzen Ihre Abfragen die Kopie der D1-Datenbank, die für Ihre Anfrage am sinnvollsten ist, sei es die primäre Datenbank oder ein nahegelegenes Replikat. Die Sessions-Implementierung von D1 stellt die sequenzielle Einheitlichkeit für alle Abfragen in der Session sicher.
Da die Sessions-API das Konsistenzmodell von D1 ändert, müssen sich Entwickler und Entwicklerinnen für die neue API entscheiden. Bestehende D1-API-Methoden bleiben unverändert und haben nach wie vor das gleiche Konsistenzmodell für die Snapshot-Isolation wie zuvor. Allerdings werden nur Abfragen, die mit der neuen Sessions-API durchgeführt werden, Replikate verwenden.
Hier ist ein Beispiel für die D1 Sessions-API:
export default {
async fetch(request: Request, env: Env) {
// When we create a D1 Session, we can continue where we left off
// from a previous Session if we have that Session's last commit
// token. This Worker will return the commit token back to the
// browser, so that it can send it back on the next request to
// continue the Session.
//
// If we don't have a commit token, make the first query in this
// session an "unconditional" query that will use the state of the
// database at whatever replica we land on.
const token = request.headers.get('x-d1-token') ?? 'first-unconditional'
const session = env.DB.withSession(token)
// Use this Session for all our Workers' routes.
const response = await handleRequest(request, session)
if (response.status === 200) {
// Set the token so we can continue the Session in another request.
response.headers.set('x-d1-token', session.latestCommitToken)
}
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (pathname === '/api/orders/list') {
// This statement is a read query, so it will execute on any
// replica that has a commit equal or later than `token` we used
// to create the Session.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (pathname === '/api/orders/add') {
const order = await request.json<Order>()
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderName, order.customer, order.value)
.run()
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
// The Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session
.prepare('SELECT COUNT(*) FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}
Die Implementierung von Sessions in D1 verwendet Commit-Token. Commit-Token identifizieren eine bestimmte an die Datenbank übertragene Abfrage. Innerhalb einer Sitzung verwendet D1 Commit-Token, um sicherzustellen, dass die Abfragen der Reihe nach ausgeführt werden. Im obigen Beispiel stellt die D1-Sitzung sicher, dass die „SELECT COUNT(*)“-Abfrage nach dem „INSERT“ der neuen Anforderung erfolgt, selbst wenn wir zwischen den Wartezeiten die Replikate wechseln.
Es gibt mehrere Optionen, wie Sie eine Sitzung in einem Workers-Fetch-Handler starten können. db.withSession(<condition>) akzeptiert diese Argumente:
Es ist möglich, dass eine Sitzung mehrere Anfragen umfasst, indem Sie das Commit-Token der letzten Anfrage der Sitzung verwenden, um eine neue Sitzung zu starten. So können einzelne User Agents, wie z. B. eine Webanwendung oder eine mobile App, sicherstellen, dass alle Abfragen, die der Nutzer sieht, in ihrer Reihenfolge einheitlich sind.
Die Lesereplikation von D1 wird integriert sein, keine zusätzlichen Nutzungs- oder Speicherkosten verursachen und keine Konfiguration der Replikate erfordern. Cloudflare überwacht den D1-Datenverkehr einer Anwendung und erstellt automatisch Datenbankreplikate, um den Nutzer-Traffic auf mehrere Server zu verteilen, die sich in der Nähe der Nutzer befinden. Im Einklang mit unserem Serverless-Modell sollten sich D1-Entwickler und -Entwicklerinnen nicht um die Bereitstellung und Verwaltung von Replikaten kümmern müssen. Stattdessen sollten sich die Entwickler und Entwicklerinnen darauf konzentrieren, Anwendungen für die Replikation und die Kompromisse bei der Datenkonsistenz zu entwerfen.
Wir arbeiten aktiv an der globalen Lesereplikation und der Umsetzung des oben genannten Vorschlags (bitte teilen Sie Ihr Feedback im #d1-Kanal auf unserem Entwickler-Discord). Bis dahin können Sie die aufregenden neuen Ergänzungen der allgemein verfügbaren Version von D1 entdecken.
Sehen Sie sich D1 GA an
Seit der offenen Beta-Version von D1 im Oktober 2023 haben wir uns auf die Zuverlässigkeit, Skalierbarkeit und Entwicklererfahrung von D1 konzentriert, die für kritische Dienste erforderlich sind. Wir haben in mehrere neue Funktionen investiert, die es Entwicklern und Entwicklerinnen ermöglichen, Anwendungen mit D1 schneller zu erstellen und zu debuggen.
Größeres entwickeln mit größeren DatenbankenBuild bigger with larger databases
Wir haben auf die Wünsche der Entwickler und Entwicklerinnen nach größeren Datenbanken gehört. D1 unterstützt jetzt bis zu 10 GB Datenbanken, mit 50.000 Datenbanken im Workers Paid-Tarif. Mit der horizontalen Skalierung von D1 können Anwendungen nun Anwendungen mit Datenbank-pro-Geschäftseinheit modellieren. Seit der Beta-Phase verarbeiten neue D1-Datenbanken in einem bestimmten Zeitraum 40x mehr Anfragen als D1-Alpha-Datenbanken.
Massenhaftes Importieren & Exportieren von Daten
Entwickler und Entwicklerinnen importieren und exportieren Daten aus verschiedenen Gründen:
- Prüfung von Datenbankmigrationen zu/von verschiedenen Datenbanksystemen
- Datenkopien für lokale Entwicklung oder Tests
- Manuelle Backups für individuelle Anforderungen wie Compliance
Bisher konnten Sie SQL-Dateien gegen D1 ausführen. Jetzt verbessern wir wrangler d1 execute –file=<filename>, um sicherzustellen, dass große Importe atomare Operationen sind, die Ihre Datenbank nie in einem Zwischenzustand belassen. wrangler d1 execute ist jetzt auch standardmäßig auf local-first eingestellt, um Ihre entfernte Produktionsdatenbank zu schützen.
Um unsere Northwind Traders Demo-Datenbank zu importieren, können Sie das Schema und die Daten herunterladen und die SQL-Dateien ausführen.
npx wrangler d1 create northwind-traders
# omit --remote to run on a local database for development
npx wrangler d1 execute northwind-traders --remote --file=./schema.sql
npx wrangler d1 execute northwind-traders --remote --file=./data.sql
D1-Datenbankdaten & Schema, nur Schema oder nur Daten können mit in eine SQL-Datei exportiert werden:
# database schema & data
npx wrangler d1 export northwind-traders --remote --output=./database.sql
# single table schema & data
npx wrangler d1 export northwind-traders --remote --table='Employee' --output=./table.sql
# database schema only
npx wrangler d1 export <database_name> --remote --output=./database-schema.sql --no-data=true
Debuggen der Abfrageperformance
Es ist wichtig, dass man für in der Produktionsumgebung eingesetzte Workloads die Performance von SQL-Abfragen versteht und langsame Abfragen debuggen kann. Wir haben die experimentellen wrangler d1 insights hinzugefügt, um Entwicklern und Entwicklerinnen bei der Analyse von Metriken zur Abfrageperformance zu helfen, die auch über die GraphQL-API verfügbar sind.
# To find top 10 queries by average execution time:
npx wrangler d1 insights <database_name> --sort-type=avg --sort-by=time --count=10
Entwicklungstools
Verschiedene Community-Entwicklungsprojekte unterstützen D1. Neu hinzugekommen ist Prisma ORM in Version 5.12.0, das nun Workers und D1 unterstützt.
Nächste Schritte
Die Funktionen, die jetzt mit GA und unserem globalen Lesereplikationsdesign zur Verfügung stehen, sind nur die ersten Schritte für die Bereitstellung der SQL-Datenbank, die für Entwickleranwendungen benötigt wird. Wenn Sie D1 noch nicht verwendet haben, können Sie jetzt sofort loslegen, die D1-Entwicklerdokumentation besuchen, um sich Anregungen zu holen, oder dem #d1-Kanal in unserem Entwickler-Discord beitreten, um mit anderen D1-Entwicklern und -Entwicklerinnen und unserem Produktentwicklungsteam zu sprechen.
