

Seit der Entdeckung von CRIME, BREACH, TIME, Lucky-13 usw. gelten längenbasierte Seitenkanalangriffe als praktikabel. Trotz verschlüsselter Pakete konnten Angreifer durch die Analyse von Metadaten wie der Paketlänge oder Zeitangaben Informationen über den zugrunde liegenden Klartext ableiten.
Cloudflare wurde kürzlich von einer Gruppe von Forschenden der Ben-Gurion-Universität kontaktiert, die eine Arbeit mit dem Titel „What Was Your Prompt? A Remote Keylogging Attack on AI Assistants“ verfasst haben. Dabei geht es um einen neuartigen Seitenkanal, mit dem sich verschlüsselte Antworten von KI-Assistenten über das Web auslesen lassen.
Das Workers AI- und AI Gateway-Team hat im Rahmen unseres Public Bug Bounty-Programms eng mit diesen Sicherheitsforschenden zusammengearbeitet und eine die Anbieter von LLM (Large Language Models) betreffende Sicherheitslücke entdeckt und vollständig gepatcht. Den ausführlichen Forschungsbericht finden Sie hier.
Nachdem wir über diese Sicherheitslücke informiert wurden, haben wir eine Abwehrmaßnahme implementiert, um alle Kunden von Workers AI und AI Gateway zu schützen. Unserer Einschätzung nach besteht für diese nun kein weiteres Risiko mehr.
Wie läuft ein solcher Seitenkanalangriff ab?
In dem Bericht beschreiben die Autoren eine Methode, mit der sie den Stream einer Chat-Sitzung mit einem LLM-Anbieter abfangen, aus den Headern der Netzwerkpakete die Länge der einzelnen Token ableiten, ihre Sequenz extrahieren und segmentieren, und schließlich mithilfe ihres eigenen speziellen LLM die Antwort ableiten.
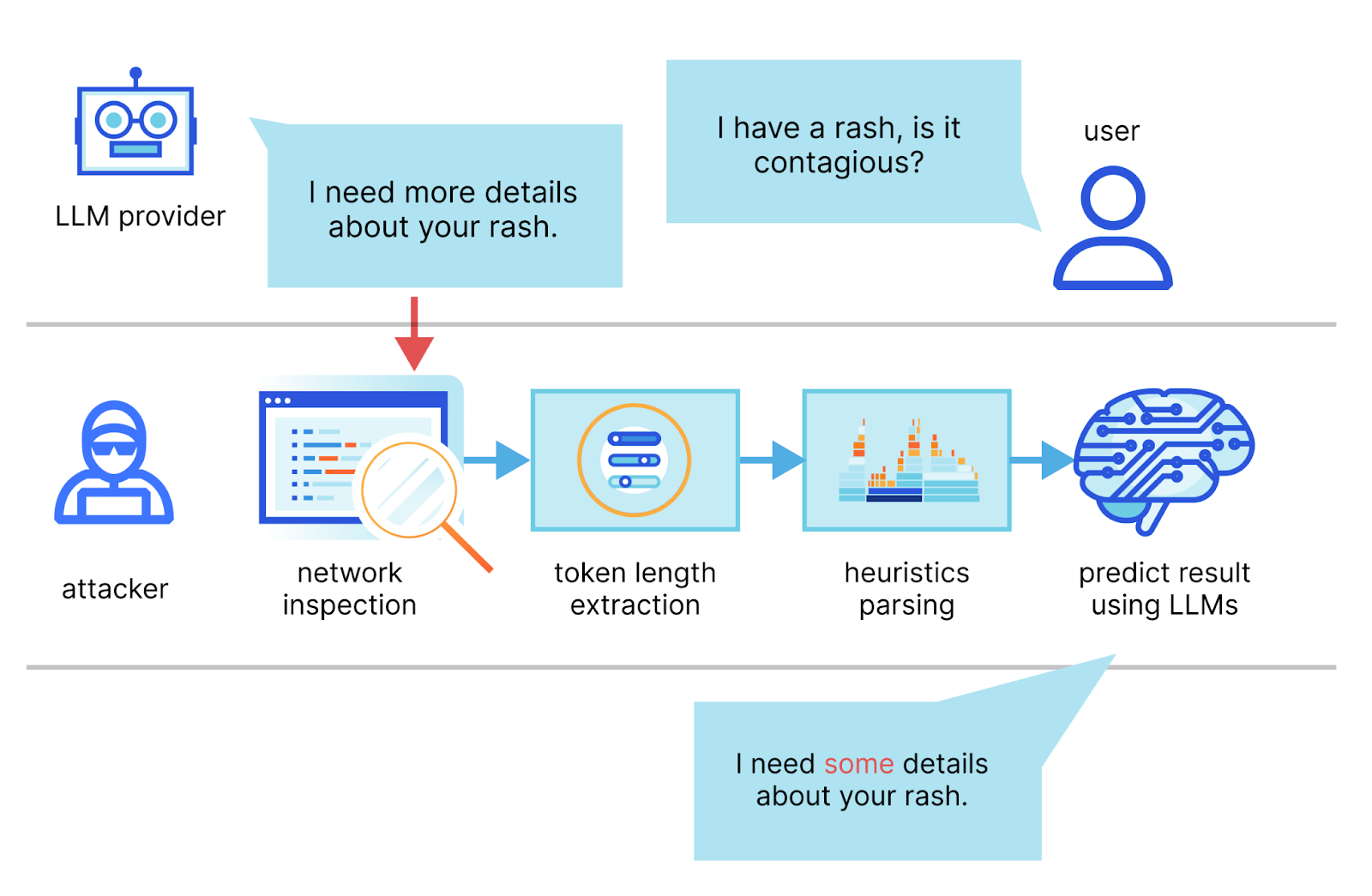
Die beiden wichtigsten Voraussetzungen für einen erfolgreichen Angriff sind ein im Streaming-Modus laufender KI-Chat-Client und ein Angreifer, der den Netzwerk-Traffic zwischen dem Client und dem KI-Chat-Dienst abfangen kann. Im Streaming-Modus werden die LLM-Token nacheinander ausgegeben, wodurch ein auf der Token-Länge basierender Seitenkanal geschaffen wird. Angreifer könnten Pakete über öffentliche Netzwerke oder innerhalb eines ISP ausspionieren.
Eine für einen Seitenkanalangriff anfällige Anfrage könnte beispielsweise wie folgt aussehen:
curl -X POST \
https://api.cloudflare.com/client/v4/accounts/<account-id>/ai/run/@cf/meta/llama-2-7b-chat-int8 \
-H "Authorization: Bearer <Token>" \
-d '{"stream":true,"prompt":"tell me something about portugal"}'
Um die Netzwerk-Pakete in der Chat-Session des LLM während des Streamens zu untersuchen, nutzen wir Wireshark:
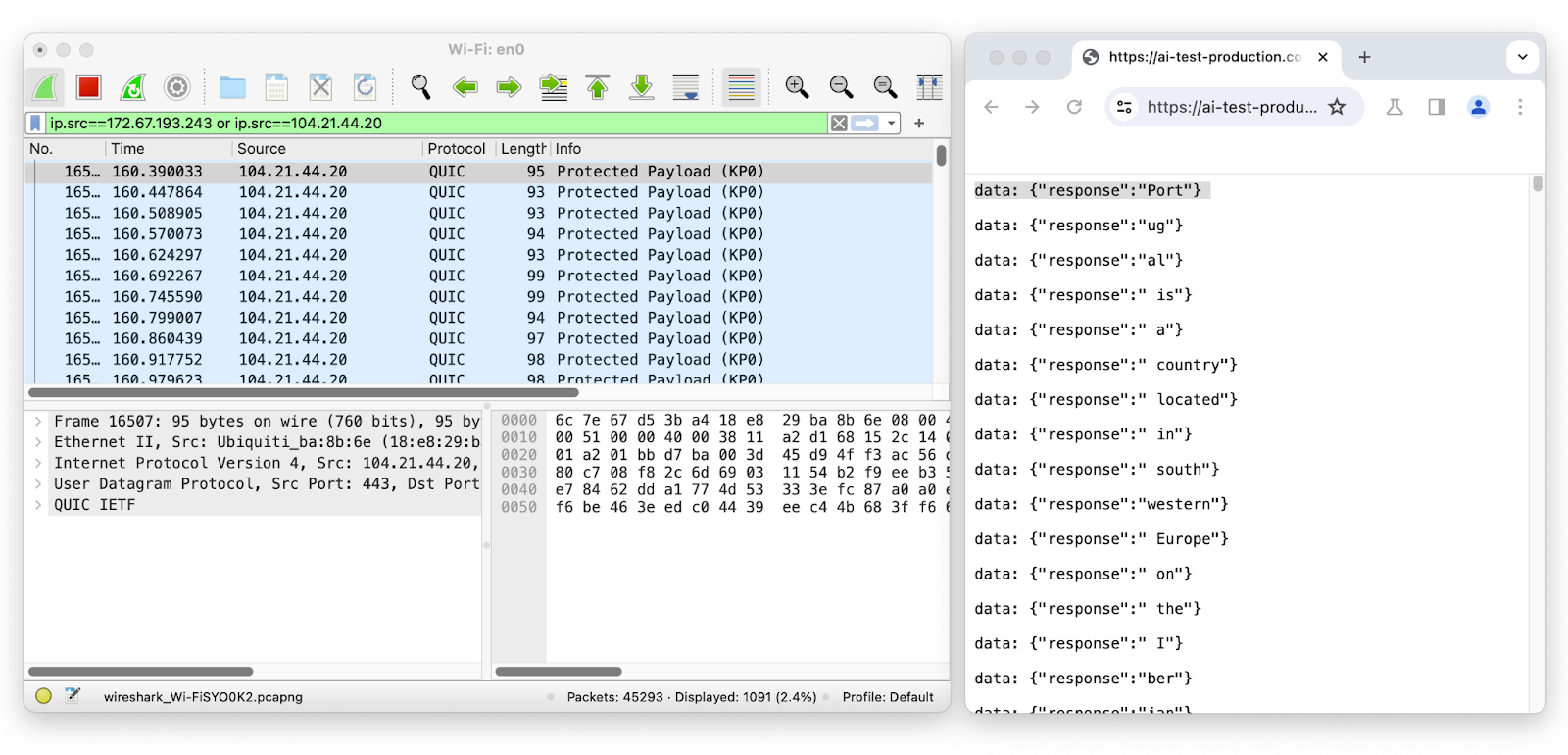
Das erste Paket hat eine Länge von 95 und entspricht dem Token „Port“, der eine Länge von vier hat. Das zweite Paket hat eine Länge von 93 und entspricht dem Token „ug“, der eine Länge von zwei hat, und so weiter. Durch Entfernen der wahrscheinlichen Token -Ummantelung aus der Länge der Netzwerk-Pakete lässt sich durch Ausspähen verschlüsselter Netzwerkdaten leicht die Menge, Reihenfolge und Länge der übertragenen Token ableiten.
Da der Angreifer die Sequenz der individuellen Token-Länge benötigt, betrifft diese Sicherheitslücke nur Textgenerierungsmodelle, die Streaming verwenden. Somit sind Anbieter von KI-Inferenz, die wie Workers AI Streaming – die gängigste Art der Interaktion mit LLM – nutzen, potenziell gefährdet.
Damit diese Methode funktioniert, muss der Angreifer sich im selben Netzwerk befinden oder in der Lage sein, den Kommunikations-Traffic zu beobachten. Je besser man den Schreibstil des anvisierten LLM kennt, desto höher die Treffsicherheit. Den Forschenden zufolge kann ihr System unter idealen Bedingungen 29 % der Antworten eines KI-Assistenten rekonstruieren und bei 55 % erfolgreich das Thema ableiten. Zu beachten ist auch, dass der Angreifer in diesem Fall anders als bei anderen Seitenkanalattacken keine Möglichkeit hat, seine Vorhersage anhand der „Ground Truth“ zu bewerten. Somit ist die Wahrscheinlichkeit, einen Satz mit nahezu perfekter Genauigkeit zu erhalten, genauso hoch wie die, dass in dem Satz nur die Konjunktionen übereinstimmen.
Abwehr von LLM-Seitenkanalangriffen
Da diese Art von Angriff darauf beruht, dass die Token-Länge vom Paket abgeleitet wird, kann er durch die Verschleierung der Token-Größe problemlos durchkreuzt werden. Die Forschenden haben Vorschläge zur Bekämpfung solcher Seitenkanalangriffe gemacht. Die einfachste Strategie besteht darin, die Token-Antworten durch Auffüllen nach dem Zufallsprinzip zu verlängern, sodass ihre echte Länge nicht mehr erkennbar ist. Dann können aus dem Paket die Antworten auch nicht mehr abgeleitet werden. Wir haben diese Abwehrmethode sofort in unser eigenes Inferenzprodukt, Workers AI, integriert. Außerdem haben wir sie in AI Gateway eingebunden, um unseren Kunden dabei zu helfen, ihre LLM unabhängig von deren Einsatzort abzusichern.
Damit sind ab heute alle Nutzer von Workers AI und AI Gateway automatisch vor diesem Seitenkanalangriff geschützt.
Unsere Vorgehensweise
Nachdem wir von diesen Forschungsergebnissen erfahren hatten und uns klargeworden war, wie sich der Missbrauch der Technik potenziell auf unsere KI-Produkte auswirken könnte, haben wir das getan, was wir in solchen Fällen immer tun: Wir haben ein Team aus Systemingenieuren, Sicherheitsingenieuren und Produktmanagern zusammengestellt und gemeinsam überlegt, wie sich die Risiken verringern lassen und welche Schritte als Nächstes unternommen werden sollten. Freundlicherweise waren die Forschenden auch für ein Telefonat bereit, in dessen Rahmen sie ihre Schlussfolgerungen präsentiert und Fragen unserer Teams beantwortet haben.
Das Forschungsteam hat uns auch ein Testnotebook zur Verfügung gestellt, mit dem wir die Ergebnisse des Angriffs überprüfen konnten. Wir waren in der Lage, die Ergebnisse für die Beispiele aus dem Notebook zu reproduzieren. Allerdings stellten wir fest, dass die Genauigkeit bei unseren Tests mit unterschiedlichen Prompt-Antworten und verschiedenen LLM sehr stark variierte. Der Bericht ist trotzdem von Wert und die Risiken sind nicht zu unterschätzen.
Wir haben beschlossen, den ersten Vorschlag aus dem Bericht für die Abwehr solcher Angriffe zu befolgen und zufälliges Padding für jede Nachricht anzuwenden, um die tatsächliche Länge der Token im Stream zu verbergen. Das macht es schwieriger, Informationen ausschließlich auf Grundlage der Größe der Netzwerkpakete abzuleiten.
Unser Inferenzprodukt Workers AI ist jetzt sicher
Mit unserem Inference as a Service-Produkt kann jeder die Workers AI-Plattform nutzen und API-Aufrufe an die von uns unterstützten KI-Modelle richten. Das bedeutet, dass wir die Inferenzanfragen beaufsichtigen, die an die Modelle gestellt werden und von diesen ausgehen. Wir sind dafür verantwortlich, dass der Dienst sicher und vor möglichen Schwachstellen geschützt ist. Deshalb haben wir auch sofort einen Fix veröffentlicht, als wir über die Forschungsergebnisse informiert wurden. Somit sind jetzt alle Workers AI-Kunden automatisch vor diesem Seitenkanalangriff sicher. Abgesehen von Tests durch die Forschenden, die in Einklang mit den ethischen Regeln standen, haben wir keine Angriffe verzeichnet, bei denen diese Schwachstelle ausgenutzt wurde.
Unsere Lösung für Workers AI ist eine Abwandlung der im Forschungsbericht vorgeschlagenen Abwehrstrategie. Da wir nicht die Roh-Token, sondern JSON-Objekte streamen, haben wir die neue Eigenschaft „p“ (für Padding) mit einem Zeichenfolgenwert variabler zufälliger Länge hinzugefügt, anstatt die Token mit Leerzeichen aufzufüllen.
Beispiel für eine Streaming-Antwort mit der SSE-Syntax:
data: {"response":"portugal","p":"abcdefghijklmnopqrstuvwxyz0123456789a"}
data: {"response":" is","p":"abcdefghij"}
data: {"response":" a","p":"abcdefghijklmnopqrstuvwxyz012"}
data: {"response":" southern","p":"ab"}
data: {"response":" European","p":"abcdefgh"}
data: {"response":" country","p":"abcdefghijklmno"}
data: {"response":" located","p":"abcdefghijklmnopqrstuvwxyz012345678"}
Diese Vorgehensweise hat den Vorteil, dass keine Änderungen im SDK oder im Client-Quellcode erforderlich sind, die Änderungen für die Endnutzer nicht sichtbar sind und unsere Kunden nichts unternehmen müssen. Durch das Hinzufügen einer zufälligen variablen Länge zu den JSON-Objekten führen wir die gleiche Variabilität auf Netzwerkebene ein und der Angreifer verliert de facto das erforderliche Eingabesignal. Kunden können Workers AI weiterhin wie gewohnt nutzen und kommen gleichzeitig in den Genuss dieses Schutzes.
Ein Schritt weiter: AI Gateway schützt die Nutzer jedes Inferenzanbieters
Wir schützen also unsere eigene KI-Inferenzlösung. Doch wir verfügen auch über ein Produkt, das Proxy-Anfragen an jeden Provider weiterleitet: AI Gateway. Dieses fungiert als Proxy zwischen einem Nutzer und unterstützten Inferenzanbietern. Es bietet Entwicklern Kontrolle, Performance und Beobachtbarkeit für ihre KI-Anwendung. Im Einklang mit unserem Ziel, ein besseres Internet zu schaffen, wollten wir schnell einen Fix einführen, der allen unseren Kunden, die KI zur Textgenerierung verwenden, helfen kann – unabhängig davon, welchen Provider sie nutzen oder ob sie Mechanismen zur Abwehr dieser Art von Angriff einsetzen. Zu diesem Zweck haben wir eine ähnliche Lösung implementiert, die alle durch AI Gateway geleiteten Streaming-Antworten um zufällige Fülldaten variabler Länge ergänzt.
Unsere AI Gateway-Kunden sind damit jetzt automatisch vor diesem Seitenkanalangriff geschützt, selbst wenn die vorgelagerten Inferenzanbieter die Sicherheitslücke noch nicht geschlossen haben sollten. Wenn Sie sich nicht sicher sind, ob Ihr Inferenzanbieter diese Schwachstelle bereits gepatcht hat, verwenden Sie einfach AI Gateway als Proxy für Ihre Anfragen. So haben Sie die Gewissheit, dass sie geschützt sind.
Fazit
Bei Cloudflare haben wir es uns zur Aufgabe gemacht, ein besseres Internet zu schaffen. Das bedeutet, dass wir uns um jeden kümmern, der im Internet aktiv ist – unabhängig davon, wie dessen Tech-Stack aussieht. Wir sind stolz darauf, die Sicherheit unserer KI-Produkte auf transparente Weise und ohne Zutun unserer Kunden verbessern zu können.
Den Forschenden, die diese Sicherheitslücke entdeckt und uns auf sehr kooperative Weise bei der Durchdringung dieses Problems geholfen haben, sind wir ausgesprochen dankbar. Wenn Sie Sicherheitsforschende(r) sind und Interesse haben, uns dabei zu helfen, unsere Produkte sicherer zu machen, schauen Sie sich doch einmal unser Bug Bounty-Programm bei hackerone.com/cloudflare an.