

Bei großflächigem Einsatz behindert die IP-Adressierung die Innovation im Bereich netzwerk- und weborientierte Dienste. Bei jeder architektonischen Anpassung und natürlich bei der Entwicklung neuer Systeme müssen wir uns als Erstes die folgenden Fragen stellen:
- Welchen Block von IP-Adressen müssen oder können wir verwenden?
- Haben wir ausreichend Adressen in IPv4? Wenn nicht, wo oder wie können wir diese bekommen?
- Wie werden IPv6-Adressen verwendet und hat dies Auswirkungen auf andere Anwendungsmöglichkeiten von IPv6?
- Und schließlich: Welchen sorgfältigen Plan, welche Kontrollen, wie viel Zeit und welche Personen benötigen wir für die Migration?
Es kostet Zeit, Geld und Ressourcen, sich um IP-Adressen kümmern zu müssen. Das mag angesichts der Einführung des visionären und zuverlässigen IP vor über 40 Jahren überraschen. Eigentlich sollten IP-Adressen das Letzte sein, worüber man sich bei einem Netzwerk Gedanken machen muss. Wenn das Internet jedoch eines gezeigt hat, dann, dass kleine oder scheinbar unwichtige Schwachstellen – die zum Zeitpunkt der Entwicklung oft unsichtbar oder unmöglich zu erkennen sind – bei ausreichend großem Maßstab immer zum Vorschein kommen.
Eines wissen wir jedoch: Mit mehr Adressen lässt sich dem Problem nicht beikommen. Bei IPv4 trägt diese Denkweise nur zur Verknappung der Adressen bei und treibt ihre Marktpreise weiter in die Höhe. IPv6 ist absolut notwendig, aber nur ein Teil der Lösung. Bei IPv6 besagt die bewährte Praxis beispielsweise, dass die kleinste Zuteilung, nur für den persönlichen Gebrauch, /56 ist – das sind 272 oder etwa 4.722.000.000.000.000.000.000 Adressen. Über so große Zahlen kann ich sicherlich nicht nachdenken. Können Sie das?
In diesem Blogbeitrag erläutern wir, warum die IP-Adressierung für Webdienste ein Problem darstellt und welche Ursachen dem zugrunde liegen. Anschließend beschreiben wir eine innovative Lösung, die wir agile Adressierung (Addressing Agility) nennen, sowie die Lehren, die wir daraus gezogen haben. Der beste Aspekt daran sind vielleicht die neuen Systeme und Architekturen, die durch die agile Adressierung ermöglicht werden. Alle Einzelheiten finden Sie in unserem aktuellen Paper für ACM SIGCOMM 2021. Als Vorgeschmack hier eine Zusammenfassung einiger unserer Erkenntnisse:

Ja, es stimmt wirklich! Es gibt keine Begrenzung für die Anzahl der Namen, die auf einer einzelnen Adresse erscheinen können; die Adresse eines jeden Namens kann sich bei jeder neuen Abfrage ändern, überall. Adressänderungen können zudem aus jedem beliebigen Grund vorgenommen werden, beispielsweise für die Bereitstellung von Diensten, für Richtlinien- oder Performancebewertungen oder aus anderen Erwägungen heraus, die wir noch nicht kennen ...
Im Folgenden wird erläutert, warum dies so ist, wie wir darauf kommen und warum diese Erkenntnisse für HTTP- und TLS-Dienste jeder Größe von Bedeutung sind. Unsere wichtigste Erkenntnis: Beim Entwurf des Internet Protocol (IP), ähnlich wie beim globalen Postsystem, wurden, werden und sollten niemals Adressen benötigt werden, um Namen zu repräsentieren. Wir behandeln Adressen nur manchmal so, als ob sie das täten. Stattdessen zeigt diese Arbeit, dass alle Namen alle ihre Adressen, eine beliebige Menge ihrer Adressen oder sogar nur eine Adresse teilen sollten.
Das enge Korsett ist eine Schleuse, aber auch ein Nadelöhr
Jahrzehnte alte Konventionen binden IP-Adressen künstlich an Namen und Ressourcen. Dies ist verständlich, da sich die Architektur und die Software, die das Internet steuern, aus einer Umgebung entwickelt haben, in der ein Computer einen Namen und (meistens) eine Netzwerkkarte hatte. Es wäre also selbstverständlich, dass sich das Internet so entwickelt, dass eine IP-Adresse mit Namen und Softwareprozessen verknüpft wird.
Bei Endkunden und Netzbetreibern, bei denen wenig Bedarf an Namen und weniger Bedarf am Abhören von IP-Adressen besteht, haben diese IP-Bindungen kaum Auswirkungen. Die Namens- und Prozesskonventionen schränken jedoch das Hosting und jegliche Verteilung von Inhalten sowie die Anbieter von Inhaltsdiensten (Content-Service Provider – CSPs) stark ein. Sobald sie Namen, Schnittstellen und Sockets zugewiesen sind, werden die Adressen weitgehend statisch. Ihre Änderung erfordert dann Aufwand, Planung und Sorgfalt, sofern sie überhaupt möglich ist.
Das „enge Korsett“ des IP hat das Internet möglich gemacht, aber ähnlich wie TCP für Transportprotokolle und HTTP für Anwendungsprotokolle hat ist das IP zu einem lähmenden Innovationshemmnis geworden. Die Idee wird in der folgenden Abbildung dargestellt. Darin ist zu sehen, dass ansonsten getrennte Kommunikationsbindungen (mit Namen) und Verbindungsbindungen (mit Schnittstellen und Sockets) transitive Beziehungen untereinander herstellen.
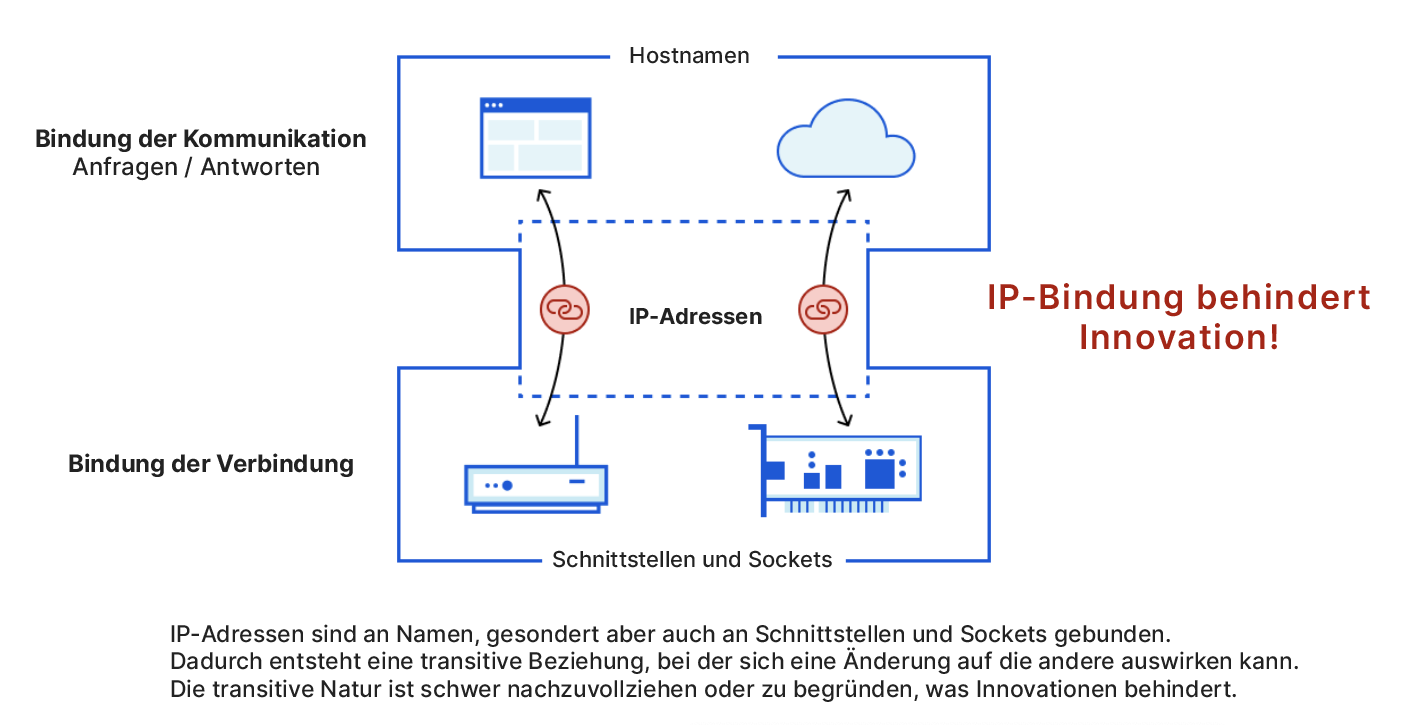
Die transitive Verknüpfung ist schwer aufzubrechen, da eine Änderung in einem der beiden Bereiche Auswirkungen auf den anderen haben kann. Darüber hinaus verwenden Service-Provider oft IP-Adressen, um Richtlinien und Service-Levels zu repräsentieren, die selbst unabhängig von Namen existieren. Letztendlich sind die IP-Bindungen eine weitere Sache, über die man sich Gedanken machen muss – und das ohne guten Grund.
Lassen Sie es uns anders formulieren. Wenn man über neue Entwürfe, neue Architekturen oder einfach eine bessere Ressourcenzuweisung nachdenkt, sollte die erste Frage niemals lauten: „Welche IP-Adressen verwenden wir?“ oder „Haben wir IP-Adressen dafür?“. Fragen wie diese und ihre Antworten bremsen Weiterentwicklung und Innovation.
Wir gelangten zu der Erkenntnis, dass IP-Bindungen nicht nur künstlich, sondern nach den ursprünglichen visionären RFCs und Normen auch falsch sind. Tatsächlich widerspricht die Vorstellung, dass IP-Adressen für etwas anderes als die Erreichbarkeit stehen, dem eigentlichen Konzept. In der ursprünglichen RFC und zugehörigen Entwurfspapieren sagen die Architekten ausdrücklich: „Es wird zwischen Namen, Adressen und Routen unterschieden. Ein Name gibt an, wonach wir suchen. Eine Adresse gibt an, wo sich das Gesuchte befindet. Eine Route gibt an, wie man dorthin gelangt.“ Jede Verknüpfung von Informationen wie SNI oder HTTP-Host in Protokollen höherer Layer mit IP ist ein klarer Verstoß gegen das Layer-Prinzip.
Natürlich steht unsere Arbeit nicht für sich allein. Sie vervollständigt jedoch eine langjährige Entwicklung zur Entkopplung der IP-Adressen von ihrer herkömmlichen Verwendung, eine Entwicklung, die darin besteht, dass wir auf den Schultern von Riesen stehen.
Die Entwicklungen der Vergangenheit ...
Wenn man auf die letzten 20 Jahre zurückblickt, ist leicht zu erkennen, dass das Streben nach Agilität bei der Adressierung schon lange besteht und dass sich Cloudflare in diesem Bereich stark einbringt.
Die jahrzehntealte Eins-zu-eins-Bindung zwischen IP und Netzwerkkartenschnittstellen wurde erstmals vor einigen Jahren aufgebrochen, als Maglev von Google Equal Cost MultiPath (ECMP) und konsistentes Hashing kombinierte, um den Traffic von einer „virtuellen“ IP-Adresse auf viele Server zu verteilen. Nebenbei bemerkt ist diese Verwendung des IP laut den ursprünglichen Internet Protocol-RFCs verboten und hat nichts Virtuelles an sich.
Seither sind viele ähnliche Systeme bei GitHub, Facebook und anderswo aufgetaucht, darunter auch unser eigenes Unimog. Vor kurzem hat Cloudflare eine neue programmierbare Socket-Architektur namens bpf_sk_lookup entwickelt, um IP-Adressen von Sockets und Prozessen zu entkoppeln.
Doch was ist nun mit diesen Namen? Der Wert des „virtuellen Hostings“ wurde 1997 zementiert, als HTTP 1.1 das Host-Feld als obligatorisch definierte. Dies war die erste offizielle Bestätigung, dass mehrere Namen auf einer einzigen IP-Adresse koexistieren können, und wurde notwendigerweise von TLS im Feld „Server Name Indication“ wiedergegeben. Es handelt sich um absolute Anforderungen, da die Zahl der möglichen Namen größer ist als die Zahl der IP-Adressen.
... deuten auf eine agile Zukunft hin
Shakespeare war also seiner Zeit voraus, als er weise die Frage stellte: „What's in a Name?“, also „Was ist ein Name?“. Wenn das Internet sprechen könnte, würde es vielleicht sagen: „Dieser Name, den wir mit einer anderen Adresse bezeichnen, wäre genauso gut erreichbar.“
Hätte Shakespeare stattdessen gefragt: „Was ist eine Adresse?", dann würde das Internet in ähnlicher Weise antworten: „Die Adresse, die wir mit einem anderen Namen versehen, wäre genauso gut erreichbar.“
Die Wahrhaftigkeit dieser Antworten bringt eine starke Implikation mit sich: Die Zuordnung zwischen Namen und Adressen ist beliebig. Wenn dies der Fall ist, kann jede Adresse verwendet werden, um einen Namen zu erreichen, solange ein Name unter einer Adresse erreichbar ist.
Tatsächlich ist seit Einführung der DNS-basierten Lastverteilung im Jahr 1995 eine Version mit vielen Adressen für einen Namen verfügbar. Warum dann nicht alle Adressen für alle Namen, oder jede beliebige Adresse zu einem bestimmten Zeitpunkt für alle Namen? Oder – wie wir bald feststellen werden – eine Adresse für alle Namen! Aber lassen Sie uns zunächst über die Art und Weise sprechen, in der die agile Adressierung erreicht wird.
Agilität bei der Adressierung erreichen: Namen ignorieren, Richtlinien abbilden
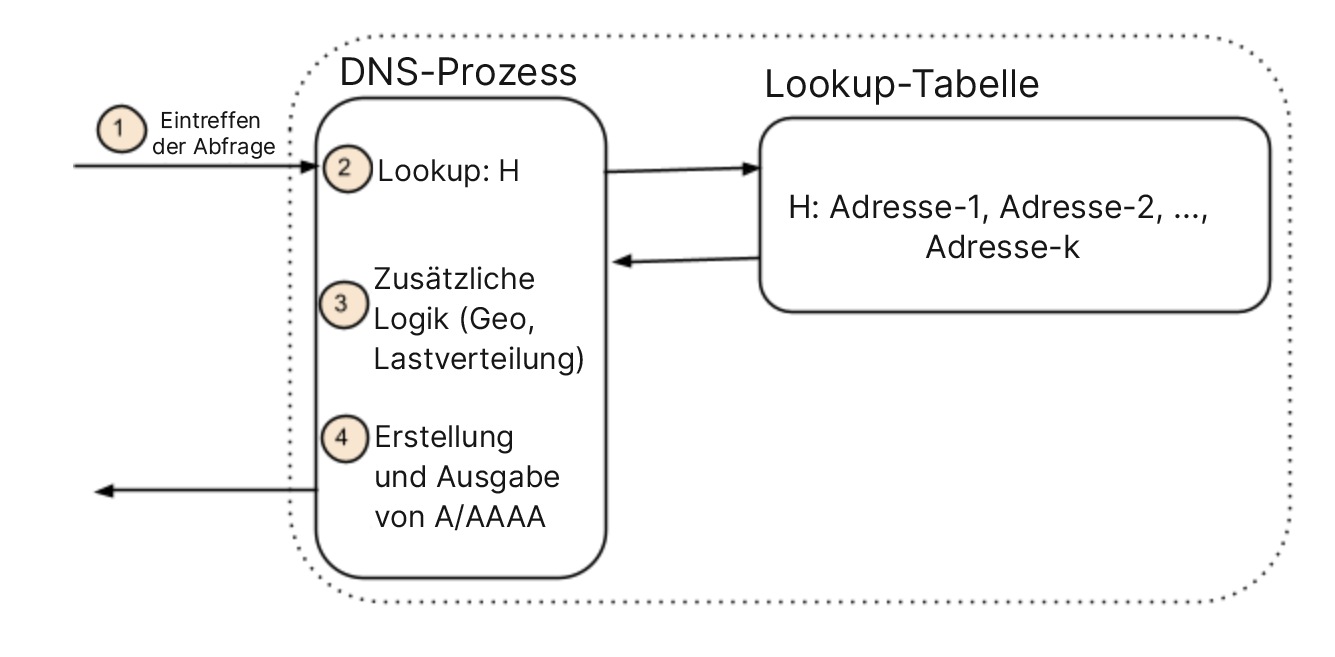
Der Schlüssel zur agilen Adressierung liegt im autoritativen DNS – aber nicht in den statischen Zuordnungen von Namen zu IP-Adressen, die in einer Art Datensatz oder Lookup-Tabelle gespeichert sind. Bedenken Sie, dass die Bindung aus Sicht eines Kunden nur bei der Abfrage erscheint. Für alle praktischen Verwendungszwecke der Zuordnung ist die Antwort auf die Abfrage der letztmögliche Zeitpunkt im Lebenszyklus einer Abfrage, an dem ein Name an eine Adresse gebunden werden kann.
Dies führt zu der Feststellung, dass die Namenszuordnung nicht in einer Datensatz- oder Zonendatei erfolgt, sondern in dem Moment, in dem die Antwort ausgegeben wird. Das ist ein feiner, aber wichtiger Unterschied. Heutige DNS-Systeme verwenden einen Namen, um eine Reihe von Adressen zu suchen, und entscheiden dann manchmal anhand von Richtlinien, welche Adresse ausgegeben werden soll. Das Konzept ist in der nachstehenden Abbildung dargestellt. Wenn eine Abfrage eingeht, werden die mit diesem Namen verbundenen Adressen ermittelt und eine oder mehrere dieser Adressen zurückgegeben. Häufig werden zusätzliche Richtlinien- oder Logikfilter verwendet, um die Adressauswahl einzuschränken, z. B. nach Service-Level oder geografischer Abdeckung. Wichtig ist, dass die Adressen zuerst mit einem Namen identifiziert werden und die Richtlinien erst danach angewendet werden.
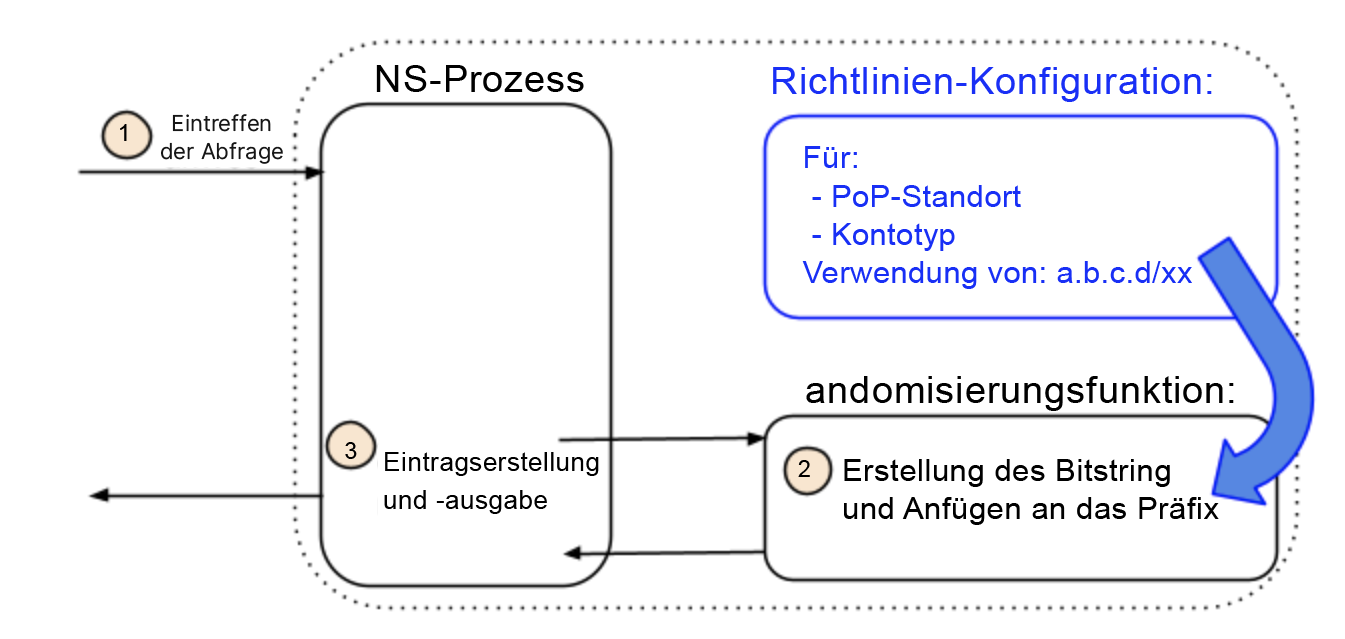
Eine agile Adressierung wird durch die Umkehrung dieser Beziehung erreicht. Anstelle von IP-Adressen, die bereits einem Namen zugeordnet sind, beginnt unsere Architektur mit einer Richtlinie, die einen Namen enthalten kann (in unserem Fall aber nicht enthält). So kann eine Richtlinie beispielsweise durch Attribute wie Standort und Kontotyp dargestellt werden, während der Name ignoriert wird (was wir bei unserer Implementierung getan haben). Die Attribute identifizieren einen Pool von Adressen, die mit dieser Richtlinie verbunden sind. Der Pool selbst kann für diese Richtlinie isoliert sein oder Elemente mit anderen Pools und Richtlinien gemeinsam haben. Außerdem sind alle Adressen des Pools gleichwertig. Das bedeutet, dass jede beliebige Adresse ausgegeben oder sogar zufällig ausgewählt werden kann, ohne dass der DNS-Abfragename überprüft wird.
Halten Sie jetzt einen Moment inne, denn es gibt zwei wirklich bemerkenswerte Implikationen, die sich aus den Antworten pro Abfrage ergeben:
i. IP-Adressen können zur Laufzeit oder zur Abfragezeit berechnet und zugewiesen werden – und genau das werden sie auch.
ii. Die Dauer der IP-zu-Namen-Zuordnung entspricht entweder der anschließenden Verbindungsdauer oder der TTL in nachgelagerten Caches – je nachdem, welche größer ist.
Das Ergebnis ist beeindruckend und bedeutet, dass die Bindung selbst ansonsten vergänglich ist und ohne Rücksicht auf frühere Bindungen, Resolver, Clients oder den Zweck geändert werden kann. Auch die Skalierbarkeit ist kein Problem, und wir wissen das, weil wir die Lösung an der Edge eingesetzt haben.
IPv6 – Altbekanntes in neuem Gewand
Bevor wir über unsere Implementierung sprechen, wollen wir zunächst den sprichwörtlichen Elefanten im Raum ansprechen: IPv6. Zunächst ist klarzustellen, dass wirklich alles, was hier im Zusammenhang mit IPv4 besprochen wurde, auch für IPv6 gilt. Wie beim globalen Postsystem sind Adressen Adressen, ob in Kanada, Kambodscha, Kamerun, Katar oder Kenia – und das schließt ihre relativ statische, unflexible Natur ein.
Trotz der Gleichwertigkeit bleibt die offensichtliche Frage bestehen: Sind nicht alle Gründe, die für agile Adressierung sprechen, durch den Wechsel zu IPv6 erfüllt? So widersinnig es auch sein mag, die Antwort ist ein klares, absolutes Nein! IPv6 mag die Erschöpfung der Adressen verringern, zumindest für die Lebenszeit aller heute lebenden Menschen, aber die Fülle der IPv6-Präfixe und -Adressen macht es schwierig, über die Bindung an Namen und Ressourcen nachzudenken.
Die Fülle der IPv6-Adressen birgt auch die Gefahr der Ineffizienz, da die Betreiber die Bitlänge und die Präfixgrößen nutzen können, um eine Bedeutung in die IP-Adresse einzubetten. Dies ist eine leistungsstarke Funktion von IPv6, bedeutet aber auch, dass unzählige Adressen in jedem Präfix ungenutzt bleiben.
Um es klar zu sagen: Cloudflare ist nachweislich einer der größten Befürworter von IPv6, und das aus guten Gründen – nicht zuletzt, weil die Fülle der Adressen Langlebigkeit gewährleistet. Dennoch ändert IPv6 nur wenig an der Art und Weise, wie Adressen mit Namen und Ressourcen verknüpft sind, während die Agilität einer Adresse über ihre gesamte Lebensdauer hinweg Flexibilität und Reaktionsfähigkeit gewährleistet.
Eine Randnotiz: Agilität ist für alle da
Eine letzte Bemerkung zur Architektur und ihrer Übertragbarkeit – die agile Adressierung ist für jeden autoritatives DNS betreibenden Dienst nutzbar, ja sogar erstrebenswert. Das gilt offensichtlich für andere inhaltsorientierte Service-Provider, aber auch für kleinere Betreiber. Universitäten, Unternehmen und Behörden sind nur einige Beispiele für Organisationen, die ihre eigenen autoritativen Dienste betreiben können. Solange die Betreiber in der Lage sind, Verbindungen über die zurückgemeldeten IP-Adressen zu akzeptieren, sind alle potenzielle Nutznießer der agilen Adressierung.
Richtlinienbasierte randomisierte Adressen – in großem Maßstab
Seit Juni 2020 arbeiten wir bei Produktions-Traffic live an der Edge mit agiler Adressierung, und zwar folgendermaßen:
- Mehr als 20 Millionen Hostnamen und Dienste
- Alle Rechenzentren in Kanada (mit einer angemessenen Bevölkerungszahl und mehreren Zeitzonen)
- /20 (4096 Adressen) in IPv4 und /44 in IPv6
- /24 (256 Adressen) in IPv4 von Januar bis Juni 2021
- Für jede Abfrage wird ein zufälliger Host-Abschnitt innerhalb des Präfixes erzeugt
Schließlich ist der wahre Test der Agilität am extremsten, wenn für jede Abfrage, die bei unseren Servern eingeht, eine Zufallsadresse generiert wird. Dann haben wir beschlossen, die Idee wirklich auf die Probe zu stellen. Im Juni 2021 wurden in unserem Rechenzentrum in Montreal und kurz darauf in Toronto alle über 20 Millionen Zonen einer einzigen Adresse zugeordnet.
Im Laufe eines Jahres erhielt jede Abfrage nach einer von der Richtlinie erfassten Domain eine zufällig ausgewählte Adresse – zunächst 4096, dann 256 und schließlich eine. Intern bezeichnen wir den Adressensatz von eins als Ao1, worauf wir später zurückkommen werden.
Das Maß des Erfolgs: „Hier gibt es nichts zu sehen“
Es mag eine Reihe von Fragen geben, die sich unsere Leser im Stillen stellen:
- Was wurde dadurch im Internet angerichtet?
- Welche Auswirkungen hatte dies auf die Cloudflare-Systeme?
- Was würde ich sehen, wenn das möglich wäre?
Die kurze Antwort auf jede der obigen Fragen lautet: nichts. Aber – und das ist wichtig – die Randomisierung von Adressen deckt Schwachstellen in der Konzeption von Systemen auf, die auf das Internet angewiesen sind. Die Schwachstellen treten immer (jede einzelne!) deswegen auf, weil die Entwickler den IP-Adressen eine andere Bedeutung als die der Erreichbarkeit zuschreiben. (Und jede dieser Schwachstellen wird, wenn auch nur nebenbei, durch die Verwendung einer Adresse, oder „Ao1“, umgangen).
Um das Wesen des „Nichts“ besser zu verstehen, sollten wir die obigen Fragen vom Ende der Liste aus beantworten.
Was würde ich sehen, wenn das möglich wäre?
Die Antwort zeigt das Beispiel in der folgenden Abbildung. Von allen Rechenzentren im „Rest der Welt“ außerhalb unserer Implementierung liefert eine Abfrage nach einer Zone die gleichen Adressen (da so das globale Anycast-System von Cloudflare funktioniert). Im Gegensatz dazu erhält jede Abfrage, die in einem Rechenzentrum, in der die Implementierung umgesetzt wurde, eine zufällige Adresse. Diese sind unten in aufeinanderfolgenden dig-Befehlen an zwei verschiedene Rechenzentren zu sehen.

Falls Sie jetzt vielleicht an den nachfolgenden Anfrage-Traffic denken: Ja, das bedeutet, dass die Server so konfiguriert sind, dass sie Verbindungsanfragen für jede der über 20 Millionen Domains zu allen Adressen im Adresspool annehmen.
Gut, aber die umgebenden Systeme von Cloudflare mussten doch sicherlich geändert werden?
Nein. Dies ist eine transparente Änderung der Datenpipeline für autoritatives DNS. Weder bei Routing-Präfix-Ankündigungen in BGP, der DDoS-Abwehr, dem Load Balancing oder dem verteilten Cache noch bei einem anderem System mussten Änderungen vorgenommen werden.
Es gibt jedoch einen faszinierenden Nebeneffekt: Die Randomisierung ist für IP-Adressen das, was eine gute Hash-Funktion für eine Hash-Tabelle ist – sie ordnet eine beliebig große Eingabe gleichmäßig einer festen Anzahl von Ausgaben zu. Die Auswirkung wird deutlich, wenn man die Last pro IP vor und nach der Randomisierung betrachtet, wie in den nachstehenden Diagrammen zu sehen ist, wobei die Daten von 1 % der Anfragen in einem Rechenzentrum über eine Zeitraum von sieben Tage stammen.
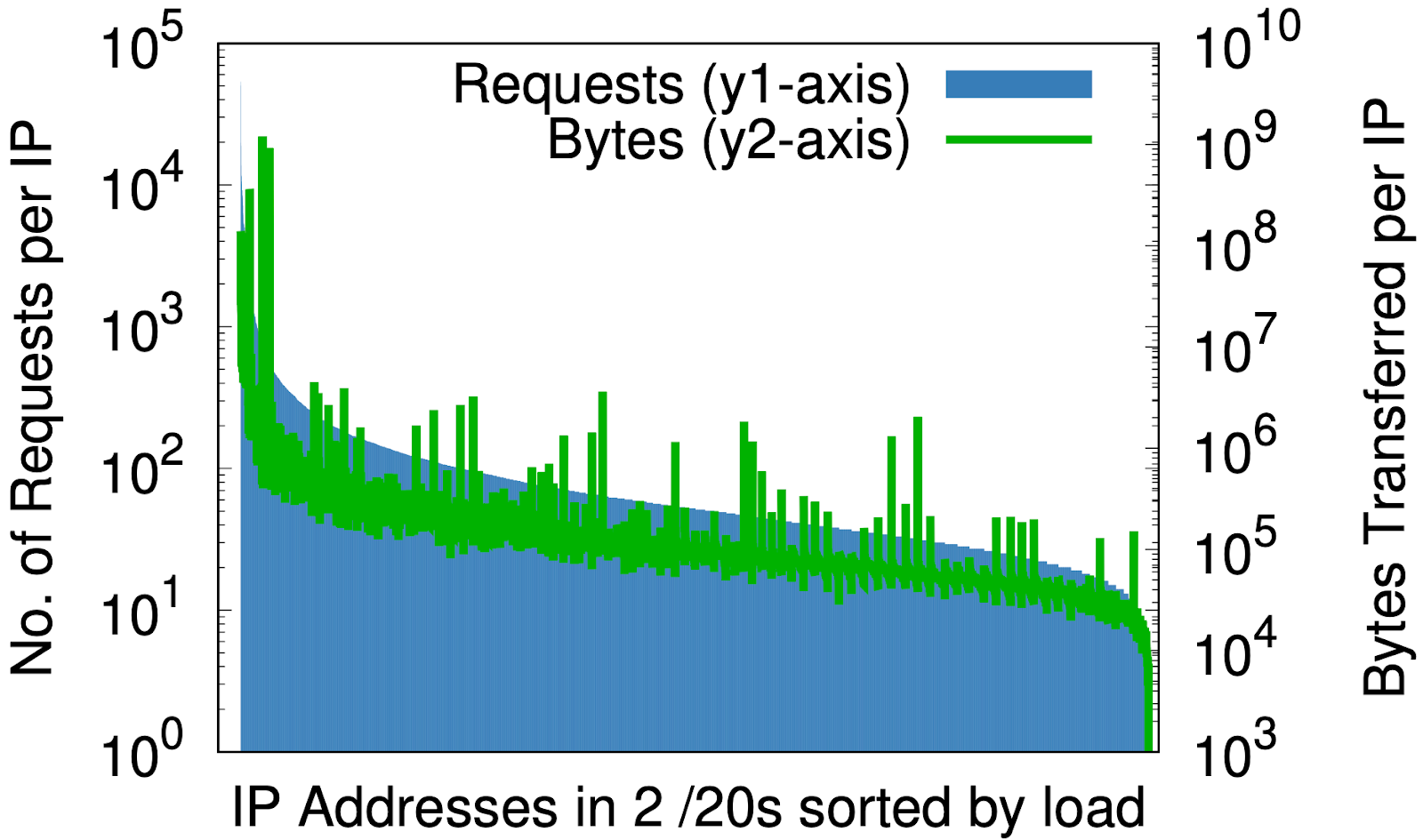
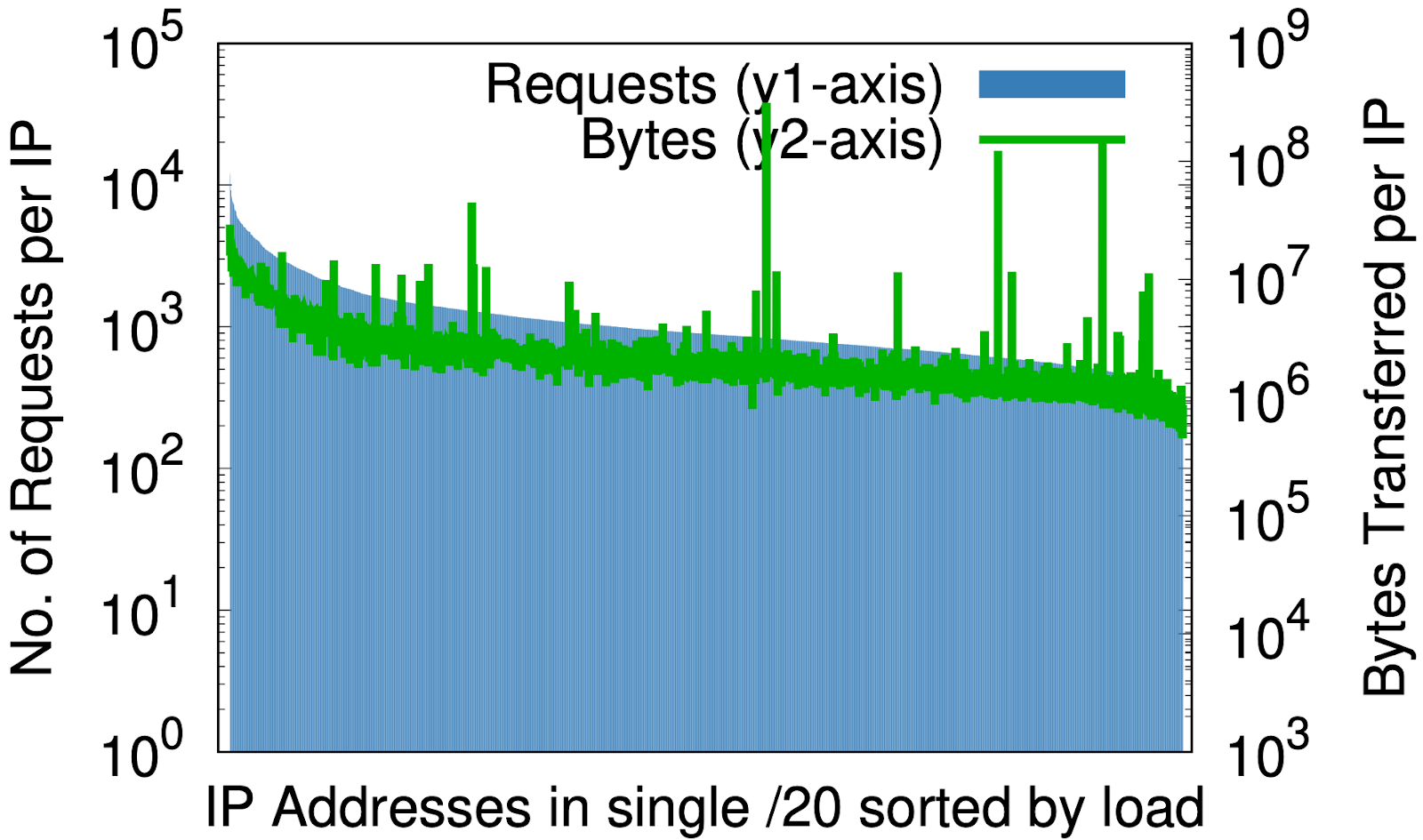
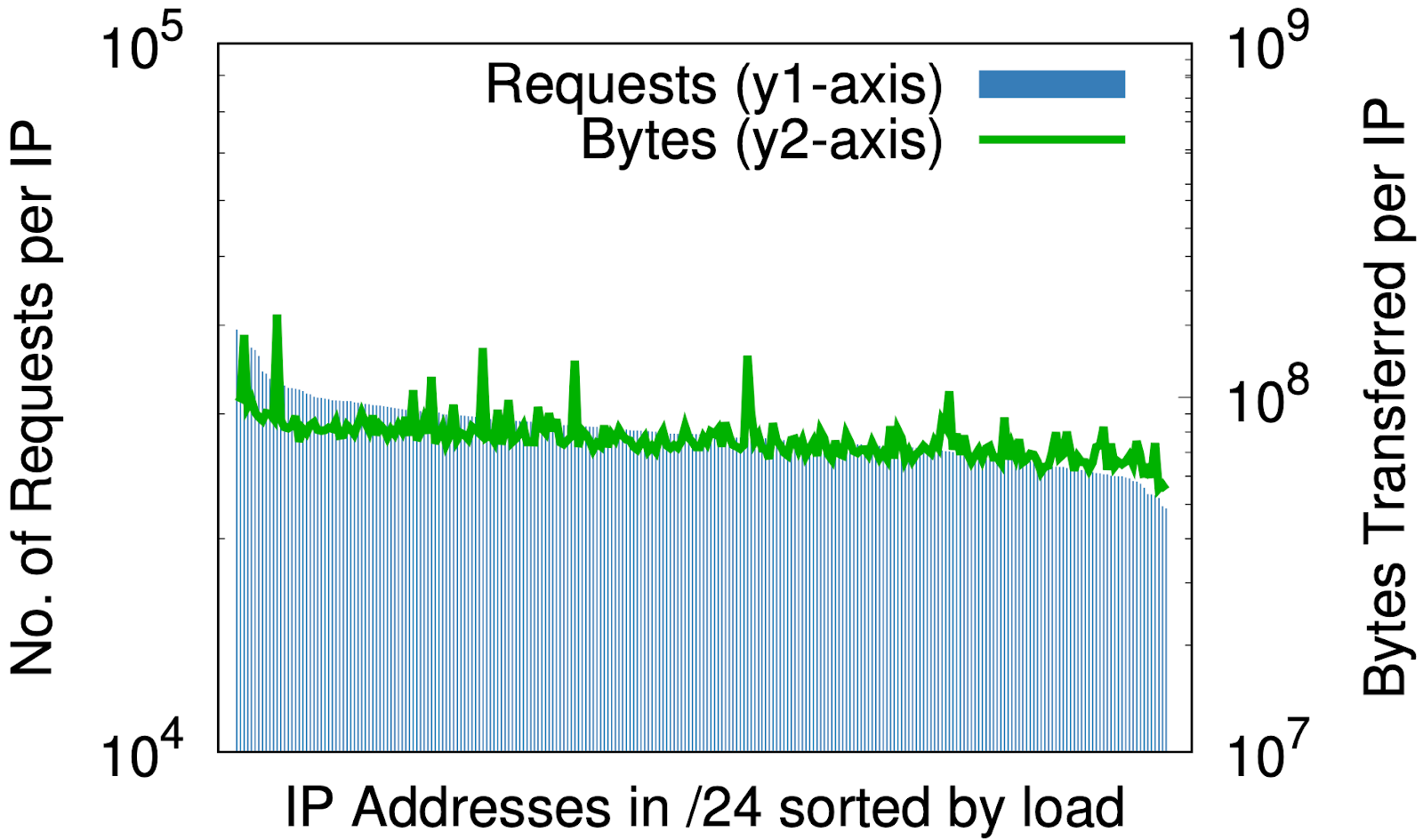
Vor der Randomisierung, nur für einen kleinen Teil des IP-Raums von Cloudflare, (a) beträgt der Unterschied zwischen den meisten und den wenigsten Anfragen pro IP (y1-Achse auf der linken Seite) drei Größenklassen; in ähnlicher Weise beträgt der Unterschied bei den Bytes pro IP (y2-Achse auf der rechten Seite) fast sechs Größenklassen. Nach der Randomisierung, (b) für alle Bereiche auf einem einzigen /20, die zuvor mehrere /20 belegten, reduzieren sich diese auf 2 bzw. 3 Größenklassen. Geht man in (c) noch einen Schritt weiter bis hinunter zu /24, so reduziert die Randomisierung von mehr als 20 Millionen Zonen auf 256 Adressen die Unterschiede in der Last auf kleine konstante Faktoren.
Dies könnte für jeden Content Service-Provider von Bedeutung sein, der die Bereitstellung von Ressourcen nach IP-Adresse in Erwägung zieht. A-priori-Vorhersagen über die von einem Kunden erzeugte Last können schwierig sein. Die obigen Diagramme zeigen, dass der beste Weg darin besteht, alle Adressen an alle Namen zu vergeben.
Das führt doch sicher im weiteren Internet zu Störungen, oder?
Auch hier lautet die Antwort: Nein! Nun, etwas präziser gesagt: „Nein, Randomisierung macht nichts kaputt ... aber sie kann Schwächen in Systemen und deren Aufbau aufdecken.“
Jedes System, das von der Adressrandomisierung betroffen sein könnte, scheint eine bestimmte Voraussetzung zu erfüllen: Der IP-Adresse wird eine Bedeutung zugeschrieben, die über die bloße Erreichbarkeit hinausgeht. Agile Adressierung behält die Semantik von IP-Adressen und die Kernarchitektur des Internets bei und stellt sie sogar wieder her, aber es werden Softwaresysteme gestört, die Annahmen über deren Bedeutung treffen.
Betrachten wir zunächst einige Beispiele und warum sie nicht von Belang sind, um dann auf eine kleine Änderung an der agilen Adressierung einzugehen, mit der die Schwachstellen (durch Verwendung einer einzigen IP-Adresse) umgangen werden:
- HTTP Connection Coalescing ermöglicht es einem Client, bestehende Verbindungen wiederzuverwenden, um Ressourcen von verschiedenen Ursprungsservern anzufordern. Clients wie Firefox, die eine Zusammenführung zulassen, wenn die URI-Autorität mit der Verbindung übereinstimmt, sind davon nicht betroffen. Bei Clients, die verlangen, dass ein URI-Host auf dieselbe IP-Adresse aufgelöst wird wie die angegebene Verbindung, schlägt die Verbindung jedoch fehl.
- Davon können Nicht-TLS- oder Nicht-HTTP-basierte Dienste betroffen sein. Ein Beispiel ist ssh, wo in known_hosts eine Zuordnung von Hostnamen zu IP-Adressen verwaltet wird. Diese Assoziation ist zwar verständlich, aber veraltet und bereits überholt, da viele DNS-Einträge derzeit mehr als eine IP-Adresse ausgeben.
- Nicht-SNI-TLS-Zertifikate erfordern eine eigene IP-Adresse. Die Anbieter sind gezwungen, einen Aufpreis zu verlangen, weil jede Adresse nur ein einziges Zertifikat ohne SNI unterstützen kann. Unabhängig von dem IP ist das größere Problem die Verwendung von TLS ohne SNI. Wir haben Anstrengungen unternommen, um Nicht-SNI zu verstehen, und hoffen, dass dieses unglückliche Erbe beendet wird.
- DDoS-Schutzmaßnahmen, die sich auf Ziel-IPs stützen, können anfangs behindert werden. Wir sind der Meinung, dass die agile Adressierung aus zwei Gründen von Vorteil ist. Erstens wird durch die IP-Randomisierung die Angriffslast auf alle verwendeten Adressen verteilt, sodass sie effektiv als Layer-3-Load Balancer dient. Zweitens arbeiten DoS-Abwehrmaßnahmen oft mit der Änderung von IP-Adressen– eine Möglichkeit, die bei der agilen Adressierung gegeben ist.
Alle für einen und einer für alle
Wir begannen mit mehr als 20 Millionen Zonen, die an Adressen über Zehntausende von Adressen gebunden waren, und stellten sie erfolgreich von 4096 Adressen in einem /20-Satz und dann von 256 Adressen in einem /24-Satz bereit. Diese Entwicklung wirft sicherlich die folgende Frage auf:
Wenn die Randomisierung über n Adressen funktioniert, warum dann nicht auch über 1 Adresse?
Ja, warum nicht? Erinnern Sie sich an die obige Bemerkung über die Randomisierung über IPs, die einer perfekten Hash-Funktion in einer Hash-Tabelle entspricht? Das Besondere an gut durchdachten Hash-Strukturen ist, dass sie ihre Eigenschaften für jede Größe der Struktur beibehalten, sogar für eine Größe von 1. Eine solche Reduktion wäre ein echter Test für die Annahmen, auf denen die agile Adressierung beruht.
Deshalb haben wir diesen Test durchgeführt. Von einem /20-Adressensatz, zu einem /24-Satz und dann, ab Juni 2021, zu einem Adressensatz von /32 bzw. einem /128 (Ao1). Das funktioniert nicht einfach nur, es funktioniert richtig gut. Bedenken, die durch die Randomisierung aufgeworfen werden könnten, werden durch Ao1 ausgeräumt. So haben beispielsweise Nicht-TLS- oder Nicht-HTTP-Dienste eine zuverlässige IP-Adresse (oder zumindest eine nicht-zufällige und solange, bis eine Änderung der Richtlinie zur Namensgebung erfolgt). Auch das Zusammenführen von HTTP-Verbindungen fällt wie von selbst weg, und ja, wir sehen ein erhöhtes Maß an Zusammenführung, wenn Ao1 verwendet wird.
Aber warum in IPv6, wo es so viele Adressen gibt?
Ein Argument gegen die Bindung an eine einzige IPv6-Adresse ist, dass dies nicht notwendig ist, da eine Erschöpfung der Adressen unwahrscheinlich ist. Dies ist ein Standpunkt aus der Zeit vor dem CIDR, der unserer Meinung nach im besten Fall gutgläubig und im schlimmsten Fall unverantwortlich ist. Wie bereits erwähnt, kann man aufgrund der Anzahl von IPv6-Adressen nur schwer darüber urteilen. Anstatt zu fragen, warum eine einzige IPv6-Adresse verwendet werden sollte, sollten wir uns fragen: „Warum nicht?“
Gibt es Auswirkungen auf vorgelagerte Bereiche? Ja, und Chancen!
Ao1 zeigt eine ganz andere Reihe von Auswirkungen der IP-Randomisierung auf, die uns wohl einen Blick in die Zukunft des Internet-Routings und der Erreichbarkeit ermöglicht, indem sie die Auswirkungen scheinbar kleiner Handlungen verstärkt.
Warum? Die Anzahl der möglichen Namen mit variabler Länge im Universum wird immer größer sein als die Anzahl der Adressen mit fester Länge. Das bedeutet, dass nach dem Schubfachprinzip eine einzige IP-Adresse von mehreren Namen und verschiedenen Inhalten von nicht verbundenen Parteien gemeinsam genutzt werden muss.
Die möglichen vorgelagerten Effekte, die durch Ao1 verstärkt werden, sind erwähnenswert und werden im Folgenden beschrieben. Bislang haben wir jedoch weder in unseren Bewertungen noch in der Kommunikation mit vorgelagerten Netzen solche Probleme festgestellt.
- Vorgelagerte Routing-Fehler schlagen sich sofort und umfassend nieder. Wenn der gesamte Traffic an einer einzigen Adresse (oder einem Präfix) ankommt, wirken sich vorgelagerte Routing-Fehler auf alle Inhalte gleichermaßen aus. (Dies ist der Grund, warum Cloudflare zwei Adressen in nicht zusammenhängenden Adressbereichen ausgibt.) Dasselbe gilt jedoch auch für das Blockieren von Bedrohungen.
- Vorgelagerte DoS-Schutzmaßnahmen könnten ausgelöst werden. Es ist denkbar, dass die Konzentration von Anfragen und Traffic auf eine einzige vorgelagerte Adresse als DoS-Angriff wahrgenommen wird und eventuell vorhandene Schutzmaßnahmen auslöst.
In beiden Fällen werden die Maßnahmen durch die Fähigkeit der agilen Adressierung, Adressen massenhaft und schnell zu ändern, abgeschwächt. Auch Prävention ist möglich, erfordert aber eine offene Kommunikation und einen offenen Diskurs.
Ein letzter vorgelagerter Effekt bleibt:
- Die Erschöpfung von Ports in IPv4 NAT kann beschleunigt werden. Durch IPv6 wird dieses Problem aber gelöst! Auf der Client-Seite ist die Anzahl der zulässigen gleichzeitigen Verbindungen zu einer Adresse durch die Größe des Port-Feldes eines Transportprotokolls nach oben hin begrenzt, z. B. etwa 65.000 bei TCP.
Bei TCP unter Linux war dies beispielsweise bis vor kurzem ein Problem. (Siehe hierzu Folgendes und SO_BIND_ADDRESS_NO_PORT in ip(7) man page.) Bei UDP bleibt das Problem bestehen. In QUIC können Verbindungskennungen die Erschöpfung von Ports verhindern, aber sie müssen verwendet werden. Bis jetzt haben wir jedoch noch keinen Hinweis darauf gesehen, dass dies ein Problem darstellt.
Dennoch – und das ist das Beste daran – ist dies unseres Wissens nach das einzige Risiko für die Verwendung einer einzigen Adresse und wird durch die Umstellung auf IPv6 auch sofort behoben. (Also, ISPs und Netzwerkadministratoren, lässt euch nicht beirren und implementiert IPv6!)
Und das ist erst der Anfang!
Und so schließen wir, wie wir begonnen haben. Was könnten Sie entwickeln, wenn es keine Obergrenze für die Anzahl der Namen auf einer einzelnen IP-Adresse gäbe und die Möglichkeit bestünde, die Adresse aus jedem beliebigen Grund per Anfrage zu ändern?

Wir stehen in der Tat erst am Anfang! Die durch agile Adressierung ermöglichte Flexibilität und Zukunftsfähigkeit gibt uns die Chance, uns neue Systeme und Architekturen vorzustellen, sie zu entwerfen und aufzubauen. Wir planen BGP Route Leak Detection und Abwehr für Anycast-Systeme, Messplattformen und mehr.
Weitere technische Details zu all dem oben Genannten sowie Danksagungen an so viele, die dazu beigetragen haben, dass dies möglich wurde, finden Sie in diesem Paper und dem kurzen Vortrag. Auch mit diesen neuen Möglichkeiten bleiben Herausforderungen bestehen. Es gibt viele offene Fragen, zu denen unter anderem die folgenden gehören:
- Welche Richtlinien können sinnvollerweise formuliert oder umgesetzt werden?
- Gibt es eine abstrakte Syntax oder Grammatik, mit der sie ausgedrückt werden können?
- Könnten wir formale Methoden und Verifizierung einsetzen, um fehlerhafte oder widersprüchliche Maßnahmen zu verhindern?
Agile Adressierung ist für alle da und sogar notwendig, damit diese Ideen auf breiterer Ebene Erfolg haben. Wir freuen uns über Anregungen und Ideen unter [email protected].
Wenn Sie als Studierender oder Studierende in einem PhD- oder gleichwertigen Forschungsprogramm eingeschrieben sind und für 2022 einen Praktikumsplatz suchen, werden in Sie hier vielleicht fündig: USA oder Kanada und EU oder GB.
Sollten Sie daran interessiert sein, zu Projekten wie diesem beizutragen oder Cloudflare bei der Entwicklung von Traffic- und Adressverwaltungssystemen zu unterstützen: Unser Addressing Engineering Team stellt neue Mitarbeitende ein!