

In the previous post we described the Firewall Rules architecture and how the different components are integrated together. We also mentioned that we created a configurable Rust library for writing and executing Wireshark®-like filters in different parts of our stack written in Go, Lua, C, C++ and JavaScript Workers.
With a mixed set of requirements of performance, memory safety, low memory use, and the capability to be part of other products that we’re working on like Spectrum, Rust stood out as the strongest option.
We have now open-sourced this library under our Github account: https://github.com/cloudflare/wirefilter. This post will dive into its design, explain why we didn’t use a parser generator and how our execution engine balances security, runtime performance and compilation cost for the generated filters.
Parsing Wireshark syntax
When building a custom Domain Specific Language (DSL), the first thing we need to be able to do is parse it. This should result in an intermediate representation (usually called an Abstract Syntax Tree) that can be inspected, traversed, analysed and, potentially, serialised.
There are different ways to perform such conversion, such as:
- Manual char-by-char parsing using state machines, regular expression and/or native string APIs.
- Parser combinators, which use higher-level functions to combine different parsers together (in Rust-land these are represented by nom, chomp, combine and others).
- Fully automated generators which, provided with a grammar, can generate a fully working parser for you (examples are peg, pest, LALRPOP, etc.).
Wireshark syntax
But before trying to figure out which approach would work best for us, let’s take a look at some of the simple official Wireshark examples, to understand what we’re dealing with:
ip.len le 1500udp contains 81:60:03sip.To contains "a1762"http.request.uri matches "gl=se$"eth.dst == ff:ff:ff:ff:ff:ffip.addr == 192.168.0.1ipv6.addr == ::1
You can see that the right hand side of a comparison can be a number, an IPv4 / IPv6 address, a set of bytes or a string. They are used interchangeably, without any special notion of a type, which is fine given that they are easily distinguishable… or are they?
Let’s take a look at some IPv6 forms on Wikipedia:
2001:0db8:0000:0000:0000:ff00:0042:83292001:db8:0:0:0:ff00:42:83292001:db8::ff00:42:8329
So IPv6 can be written as a set of up to 8 colon-separated hexadecimal numbers, each containing up to 4 digits with leading zeros omitted for convenience. This appears suspiciously similar to the syntax for byte sequences. Indeed, if we try writing out a sequence like 2f:31:32:33:34:35:36:37, it’s simultaneously a valid IPv6 and a byte sequence in terms of Wireshark syntax.
There is no way of telling what this sequence actually represents without looking at the type of the field it’s being compared with, and if you try using this sequence in Wireshark, you’ll notice that it does just that:
ipv6.addr == 2f:31:32:33:34:35:36:37: right hand side is parsed and used as an IPv6 addresshttp.request.uri == 2f:31:32:33:34:35:36:37: right hand side is parsed and used as a byte sequence (will match a URL"/1234567")
Are there other examples of such ambiguities? Yup - for example, we can try using a single number with two decimal digits:
tcp.port == 80: matches any traffic on the port 80 (HTTP)http.file_data == 80: matches any HTTP request/response with body containing a single byte (0x80)
We could also do the same with ethernet address, defined as a separate type in Wireshark, but, for simplicity, we represent it as a regular byte sequence in our implementation, so there is no ambiguity here.
Choosing a parsing approach
This is an interesting syntax design decision. It means that we need to store a mapping between field names and types ahead of time - a Scheme, as we call it - and use it for contextual parsing. This restriction also immediately rules out many if not most parser generators.
We could still use one of the more sophisticated ones (like LALRPOP) that allow replacing the default regex-based lexer with your own custom code, but at that point we’re so close to having a full parser for our DSL that the complexity outweighs any benefits of using a black-box parser generator.
Instead, we went with a manual parsing approach. While (for a good reason) this might sound scary in unsafe languages like C / C++, in Rust all strings are bounds checked by default. Rust also provides a rich string manipulation API, which we can use to build more complex helpers, eventually ending up with a full parser.
This approach is, in fact, pretty similar to parser combinators in that the parser doesn’t have to keep state and only passes the unprocessed part of the input down to smaller, narrower scoped functions. Just as in parser combinators, the absence of mutable state also allows to easily test and maintain each of the parsers for different parts of the syntax independently of the others.
Compared with popular parser combinator libraries in Rust, one of the differences is that our parsers are not standalone functions but rather types that implement common traits:
pub trait Lex<'i>: Sized {
fn lex(input: &'i str) -> LexResult<'i, Self>;
}
pub trait LexWith<'i, E>: Sized {
fn lex_with(input: &'i str, extra: E) -> LexResult<'i, Self>;
}
The lex method or its contextual variant lex_with can either return a successful pair of (instance of the type, rest of input) or a pair of (error kind, relevant input span).

The Lex trait is used for target types that can be parsed independently of the context (like field names or literals), while LexWith is used for types that need a Scheme or a part of it to be parsed unambiguously.
A bigger difference is that, instead of relying on higher-level functions for parser combinators, we use the usual imperative function call syntax. For example, when we want to perform sequential parsing, all we do is call several parsers in a row, using tuple destructuring for intermediate results:
let input = skip_space(input);
let (op, input) = CombinedExpr::lex_with(input, scheme)?;
let input = skip_space(input);
let input = expect(input, ")")?;
And, when we want to try different alternatives, we can use native pattern matching and ignore the errors:
if let Ok(input) = expect(input, "(") {
...
(SimpleExpr::Parenthesized(Box::new(op)), input)
} else if let Ok((op, input)) = UnaryOp::lex(input) {
...
} else {
...
}
Finally, when we want to automate parsing of some more complicated common cases - say, enums - Rust provides a powerful macro syntax:
lex_enum!(#[repr(u8)] OrderingOp {
"eq" | "==" => Equal = EQUAL,
"ne" | "!=" => NotEqual = LESS | GREATER,
"ge" | ">=" => GreaterThanEqual = GREATER | EQUAL,
"le" | "<=" => LessThanEqual = LESS | EQUAL,
"gt" | ">" => GreaterThan = GREATER,
"lt" | "<" => LessThan = LESS,
});
This gives an experience similar to parser generators, while still using native language syntax and keeping us in control of all the implementation details.
Execution engine
Because our grammar and operations are fairly simple, initially we used direct AST interpretation by requiring all nodes to implement a trait that includes an execute method.
trait Expr<'s> {
fn execute(&self, ctx: &ExecutionContext<'s>) -> bool;
}
The ExecutionContext is pretty similar to a Scheme, but instead of mapping arbitrary field names to their types, it maps them to the runtime input values provided by the caller.
As with Scheme, initially ExecutionContext used an internal HashMap for registering these arbitrary String -> RhsValue mappings. During the execute call, the AST implementation would evaluate itself recursively, and look up each field reference in this map, either returning a value or raising an error on missing slots and type mismatches.
This worked well enough for an initial implementation, but using a HashMap has a non-trivial cost which we would like to eliminate. We already used a more efficient hasher - Fnv - because we are in control of all keys and so are not worried about hash DoS attacks, but there was still more we could do.
Speeding up field access
If we look at the data structures involved, we can see that the scheme is always well-defined in advance, and all our runtime values in the execution engine are expected to eventually match it, even if the order or a precise set of fields is not guaranteed:
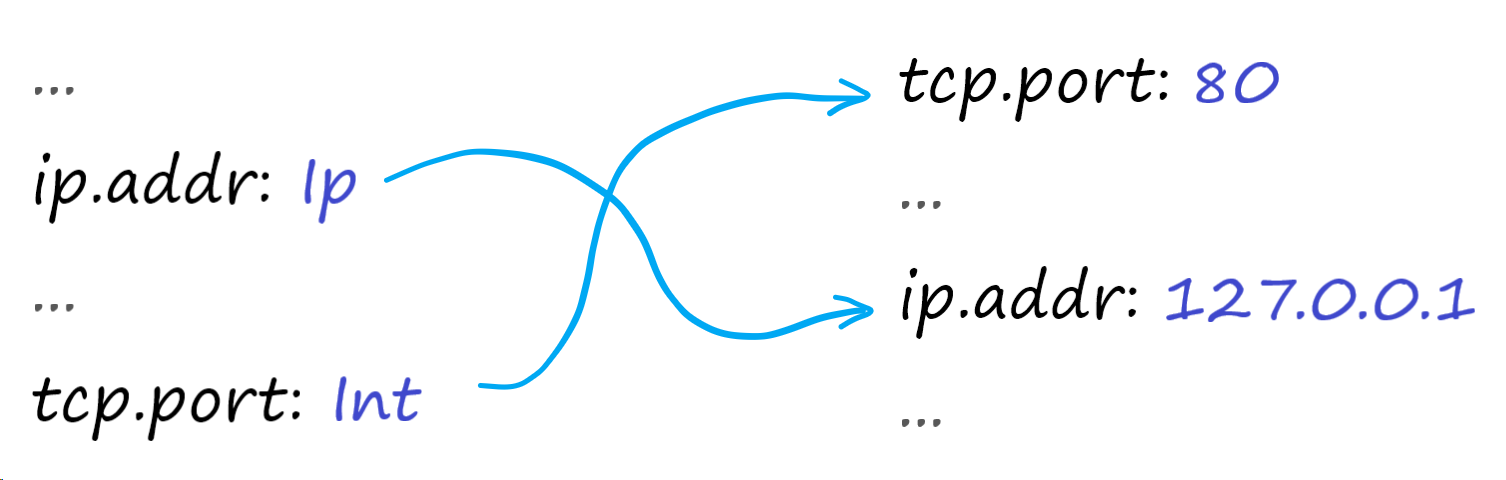
So what if we ditch the second map altogether and instead use a fixed-size array of values? Array indexing should be much cheaper than looking up in a map, so it might be well worth the effort.
How can we do it? We already know the number of items (thanks to the predefined scheme) so we can use that for the size of the backing storage, and, in order to simulate HashMap “holes” for unset values, we can wrap each item an Option<...>:
pub struct ExecutionContext<'e> {
scheme: &'e Scheme,
values: Box<[Option<LhsValue<'e>>]>,
}
The only missing piece is an index that could map both structures to each other. As you might remember, Scheme still uses a HashMap for field registration, and a HashMap is normally expected to be randomised and indexed only by the predefined key.
While we could wrap a value and an auto-incrementing index together into a custom struct, there is already a better solution: IndexMap. IndexMap is a drop-in replacement for a HashMap that preserves ordering and provides a way to get an index of any element and vice versa - exactly what we needed.
After replacing a HashMap in the Scheme with IndexMap, we can change parsing to resolve all the parsed field names to their indices in-place and store that in the AST:
impl<'i, 's> LexWith<'i, &'s Scheme> for Field<'s> {
fn lex_with(mut input: &'i str, scheme: &'s Scheme) -> LexResult<'i, Self> {
...
let field = scheme
.get_field_index(name)
.map_err(|err| (LexErrorKind::UnknownField(err), name))?;
Ok((field, input))
}
}
After that, in the ExecutionContext we allocate a fixed-size array and use these indices for resolving values during runtime:
impl<'e> ExecutionContext<'e> {
/// Creates an execution context associated with a given scheme.
///
/// This scheme will be used for resolving any field names and indices.
pub fn new<'s: 'e>(scheme: &'s Scheme) -> Self {
ExecutionContext {
scheme,
values: vec![None; scheme.get_field_count()].into(),
}
}
...
}
This gave significant (~2x) speed ups on our standard benchmarks:
Before:
test matching ... bench: 2,548 ns/iter (+/- 98)
test parsing ... bench: 192,037 ns/iter (+/- 21,538)After:
test matching ... bench: 1,227 ns/iter (+/- 29)
test parsing ... bench: 197,574 ns/iter (+/- 16,568)This change also improved the usability of our API, as any type errors are now detected and reported much earlier, when the values are just being set on the context, and not delayed until filter execution.
[not] JIT compilation
Of course, as with any respectable DSL, one of the other ideas we had from the beginning was “...at some point we’ll add native compilation to make everything super-fast, it’s just a matter of time...”.
In practice, however, native compilation is a complicated matter, but not due to lack of tools.
First of all, there is question of storage for the native code. We could compile each filter statically into some sort of a library and publish to a key-value store, but that would not be easy to maintain:
- We would have to compile each filter to several platforms (x86-64, ARM, WASM, …).
- The overhead of native library formats would significantly outweigh the useful executable size, as most filters tend to be small.
- Each time we’d like to change our execution logic, whether to optimise it or to fix a bug, we would have to recompile and republish all the previously stored filters.
- Finally, even if/though we’re sure of the reliability of the chosen store, executing dynamically retrieved native code on the edge as-is is not something that can be taken lightly.
The usual flexible alternative that addresses most of these issues is Just-in-Time (JIT) compilation.
When you compile code directly on the target machine, you get to re-verify the input (still expressed as a restricted DSL), you can compile it just for the current platform in-place, and you never need to republish the actual rules.
Looks like a perfect fit? Not quite. As with any technology, there are tradeoffs, and you only get to choose those that make more sense for your use cases. JIT compilation is no exception.
First of all, even though you’re not loading untrusted code over the network, you still need to generate it into the memory, mark that memory as executable and trust that it will always contain valid code and not garbage or something worse. Depending on your choice of libraries and complexity of the DSL, you might be willing to trust it or put heavy sandboxing around, but, either way, it’s a risk that one must explicitly be willing to take.
Another issue is the cost of compilation itself. Usually, when measuring the speed of native code vs interpretation, the cost of compilation is not taken into the account because it happens out of the process.
With JIT compilers though, it’s different as you’re now compiling things the moment they’re used and cache the native code only for a limited time. Turns out, generating native code can be rather expensive, so you must be absolutely sure that the compilation cost doesn’t offset any benefits you might gain from the native execution speedup.
I’ve talked a bit more about this at Rust Austin meetup and, I believe, this topic deserves a separate blog post so won’t go into much more details here, but feel free to check out the slides: https://www.slideshare.net/RReverser/building-fast-interpreters-in-rust. Oh, and if you’re in Austin, you should pop into our office for the next meetup!
Let’s get back to our original question: is there anything else we can do to get the best balance between security, runtime performance and compilation cost? Turns out, there is.
Dynamic dispatch and closures to the rescue
Introducing Fn trait!
In Rust, the Fn trait and friends (FnMut, FnOnce) are automatically implemented on eligible functions and closures. In case of a simple Fn case the restriction is that they must not modify their captured environment and can only borrow from it.
Normally, you would want to use it in generic contexts to support arbitrary callbacks with given argument and return types. This is important because in Rust, each function and closure implements a unique type and any generic usage would compile down to a specific call just to that function.
fn just_call(me: impl Fn(), maybe: bool) {
if maybe {
me()
}
}
Such behaviour (called static dispatch) is the default in Rust and is preferable for performance reasons.
However, if we don’t know all the possible types at compile-time, Rust allows us to opt-in for a dynamic dispatch instead:
fn just_call(me: &dyn Fn(), maybe: bool) {
if maybe {
me()
}
}
Dynamically dispatched objects don't have a statically known size, because it depends on the implementation details of particular type being passed. They need to be passed as a reference or stored in a heap-allocated Box, and then used just like in a generic implementation.
In our case, this allows to create, return and store arbitrary closures, and later call them as regular functions:
trait Expr<'s> {
fn compile(self) -> CompiledExpr<'s>;
}
pub(crate) struct CompiledExpr<'s>(Box<dyn 's + Fn(&ExecutionContext<'s>) -> bool>);
impl<'s> CompiledExpr<'s> {
/// Creates a compiled expression IR from a generic closure.
pub(crate) fn new(closure: impl 's + Fn(&ExecutionContext<'s>) -> bool) -> Self {
CompiledExpr(Box::new(closure))
}
/// Executes a filter against a provided context with values.
pub fn execute(&self, ctx: &ExecutionContext<'s>) -> bool {
self.0(ctx)
}
}
The closure (an Fn box) will also automatically include the environment data it needs for the execution.
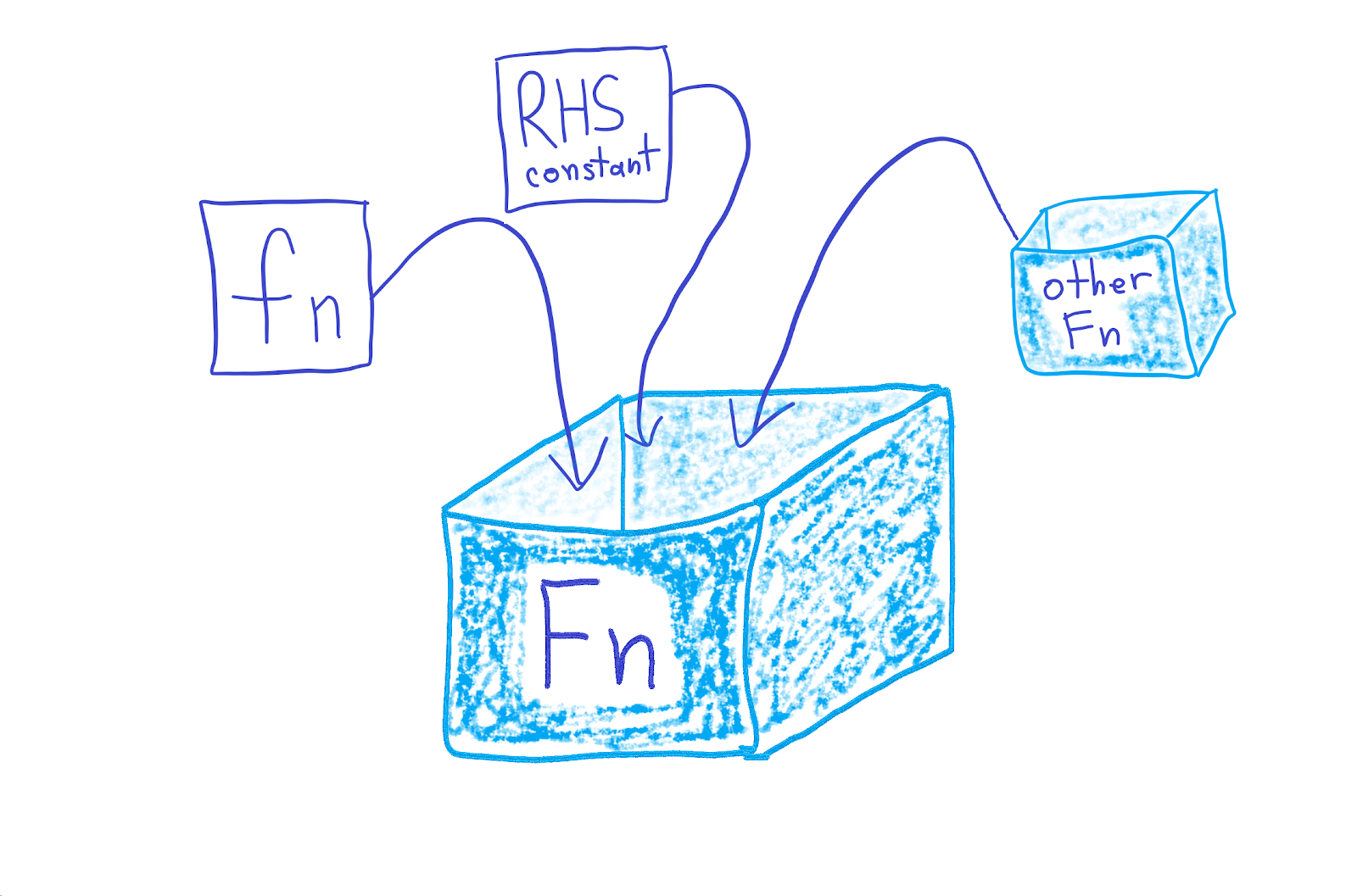
This means that we can optimise the runtime data representation as part of the “compile” process without changing the AST or the parser. For example, when we wanted to optimise IP range checks by splitting them for different IP types, we could do that without having to modify any existing structures:
RhsValues::Ip(ranges) => {
let mut v4 = Vec::new();
let mut v6 = Vec::new();
for range in ranges {
match range.clone().into() {
ExplicitIpRange::V4(range) => v4.push(range),
ExplicitIpRange::V6(range) => v6.push(range),
}
}
let v4 = RangeSet::from(v4);
let v6 = RangeSet::from(v6);
CompiledExpr::new(move |ctx| {
match cast!(ctx.get_field_value_unchecked(field), Ip) {
IpAddr::V4(addr) => v4.contains(addr),
IpAddr::V6(addr) => v6.contains(addr),
}
})
}
Moreover, boxed closures can be part of that captured environment, too. This means that we can convert each simple comparison into a closure, and then combine it with other closures, and keep going until we end up with a single top-level closure that can be invoked as a regular function to evaluate the entire filter expression.
It’s turtles closures all the way down:
let items = items
.into_iter()
.map(|item| item.compile())
.collect::<Vec<_>>()
.into_boxed_slice();
match op {
CombiningOp::And => {
CompiledExpr::new(move |ctx| items.iter().all(|item| item.execute(ctx)))
}
CombiningOp::Or => {
CompiledExpr::new(move |ctx| items.iter().any(|item| item.execute(ctx)))
}
CombiningOp::Xor => CompiledExpr::new(move |ctx| {
items
.iter()
.fold(false, |acc, item| acc ^ item.execute(ctx))
}),
}
What’s nice about this approach is:
- Our execution is no longer tied to the AST, and we can be as flexible with optimising the implementation and data representation as we want without affecting the parser-related parts of code or output format.
- Even though we initially “compile” each node to a single closure, in future we can pretty easily specialise certain combinations of expressions into their own closures and so improve execution speed for common cases. All that would be required is a separate
matchbranch returning a closure optimised for just that case. - Compilation is very cheap compared to real code generation. While it might seem that allocating many small objects (one
Boxed closure per expression) is not very efficient and that it would be better to replace it with some sort of a memory pool, in practice we saw a negligible performance impact. - No native code is generated at runtime, which means that we execute only code that was statically verified by Rust at compile-time and compiled down to a static function. All that we do at the runtime is call existing functions with different values.
- Execution turns out to be faster too. This initially came as a surprise, because dynamic dispatch is widely believed to be costly and we were worried that it would get slightly worse than AST interpretation. However, it showed an immediate ~10-15% runtime improvement in benchmarks and on real examples.
The only obvious downside is that each level of AST requires a separate dynamically-dispatched call instead of a single inlined code for the entire expression, like you would have even with a basic template JIT.
Unfortunately, such output could be achieved only with real native code generation, and, for our case, the mentioned downsides and risks would outweigh runtime benefits, so we went with the safe & flexible closure approach.
Bonus: WebAssembly support
As was mentioned earlier, we chose Rust as a safe high-level language that allows easy integration with other parts of our stack written in Go, C and Lua via C FFI. But Rust has one more target it invests in and supports exceptionally well: WebAssembly.
Why would we be interested in that? Apart from the parts of the stack where our rules would run, and the API that publishes them, we also have users who like to write their own rules. To do that, they use a UI editor that allows either writing raw expressions in Wireshark syntax or as a WYSIWYG builder.
We thought it would be great to expose the parser - the same one as we use on the backend - to the frontend JavaScript for a consistent real-time editing experience. And, honestly, we were just looking for an excuse to play with WASM support in Rust.
WebAssembly could be targeted via regular C FFI, but in that case you would need to manually provide all the glue for the JavaScript side to hold and convert strings, arrays and objects forth and back.
In Rust, this is all handled by wasm-bindgen. While it provides various attributes and methods for direct conversions, the simplest way to get started is to activate the “serde” feature which will automatically convert types using JSON.parse, JSON.stringify and serde_json under the hood.
In our case, creating a wrapper for the parser with only 20 lines of code was enough to get started and have all the WASM code + JavaScript glue required:
#[wasm_bindgen]
pub struct Scheme(wirefilter::Scheme);
fn into_js_error(err: impl std::error::Error) -> JsValue {
js_sys::Error::new(&err.to_string()).into()
}
#[wasm_bindgen]
impl Scheme {
#[wasm_bindgen(constructor)]
pub fn try_from(fields: &JsValue) -> Result<Scheme, JsValue> {
fields.into_serde().map(Scheme).map_err(into_js_error)
}
pub fn parse(&self, s: &str) -> Result<JsValue, JsValue> {
let filter = self.0.parse(s).map_err(into_js_error)?;
JsValue::from_serde(&filter).map_err(into_js_error)
}
}
And by using a higher-level tool called wasm-pack, we also got automated npm package generation and publishing, for free.
This is not used in the production UI yet because we still need to figure out some details for unsupported browsers, but it’s great to have all the tooling and packages ready with minimal efforts. Extending and reusing the same package, it should be even possible to run filters in Cloudflare Workers too (which also support WebAssembly).
The future
The code in the current state is already doing its job well in production and we’re happy to share it with the open-source Rust community.
This is definitely not the end of the road though - we have many more fields to add, features to implement and planned optimisations to explore. If you find this sort of work interesting and would like to help us by working on firewalls, parsers or just any Rust projects at scale, give us a shout!