

This post is also available in 简体中文, 繁體中文.
We recently announced Privacy Gateway, a fully managed, scalable, and performant Oblivious HTTP (OHTTP) relay. Conceptually, OHTTP is a simple protocol: end-to-end encrypted requests and responses are forwarded between client and server through a relay, decoupling who from what was sent. This is a common pattern, as evidenced by deployed technologies like Oblivious DoH and Apple Private Relay. Nevertheless, OHTTP is still new, and as a new protocol it’s imperative that we analyze the protocol carefully.
To that end, we conducted a formal, computer-aided security analysis to complement the ongoing standardization process and deployment of this protocol. In this post, we describe this analysis in more depth, digging deeper into the cryptographic details of the protocol and the model we developed to analyze it. If you’re already familiar with the OHTTP protocol, feel free to skip ahead to the analysis to dive right in. Otherwise, let’s first review what OHTTP sets out to achieve and how the protocol is designed to meet those goals.
Decoupling who from what was sent
OHTTP is a protocol that combines public key encryption with a proxy to separate the contents of an HTTP request (and response) from the sender of an HTTP request. In OHTTP, clients generate encrypted requests and send them to a relay, the relay forwards them to a gateway server, and then finally the gateway decrypts the message to handle the request. The relay only ever sees ciphertext and the client and gateway identities, and the gateway only ever sees the relay identity and plaintext.
In this way, OHTTP is a lightweight application-layer proxy protocol. This means that it proxies application messages rather than network-layer connections. This distinction is important, so let’s make sure we understand the differences. Proxying connections involves a whole other suite of protocols typically built on HTTP CONNECT. (Technologies like VPNs and WireGuard, including Cloudflare WARP, can also be used, but let’s focus on HTTP CONNECT for comparison.)
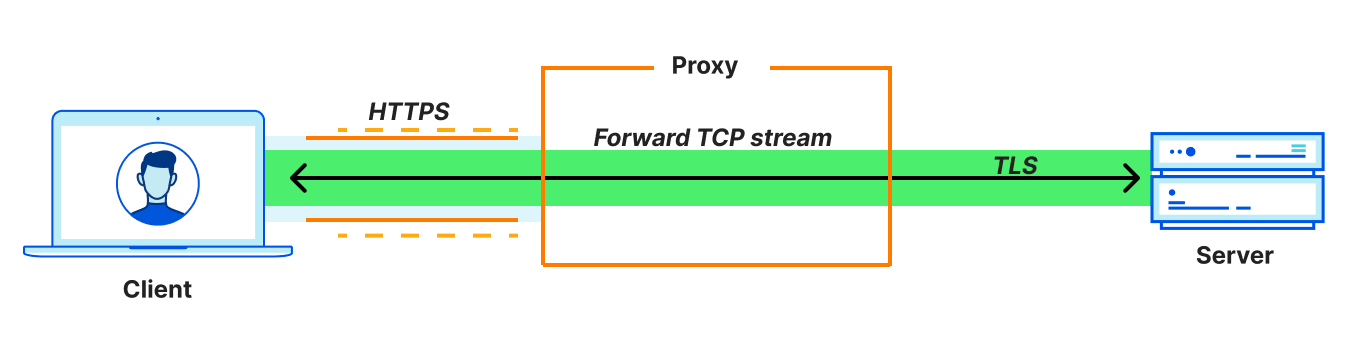
Since the entire TCP connection itself is proxied, connection-oriented proxies are compatible with any application that uses TCP. In effect, they are general purpose proxy protocols that support any type of application traffic. In contrast, proxying application messages is compatible with application use cases that require transferring entire objects (messages) between a client and server.
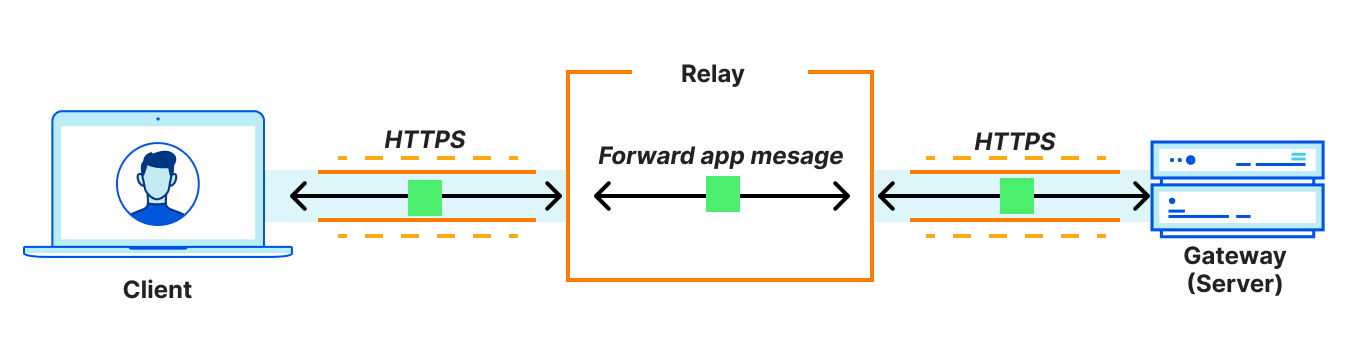
Examples include DNS requests and responses, or, in the case of OHTTP, HTTP requests and responses. In other words, OHTTP is not a general purpose proxy protocol: it’s fit for purpose, aimed at transactional interactions between clients and servers (such as app-level APIs). As a result, it is much simpler in comparison.
Applications use OHTTP to ensure that requests are not linked to either of the following:
- Client identifying information, including the IP address, TLS fingerprint, and so on. As a proxy protocol, this is a fundamental requirement.
- Future requests from the same client. This is necessary for applications that do not carry state across requests.
These two properties make OHTTP a perfect fit for applications that wish to provide privacy to their users without compromising basic functionality. It’s served as the foundation for a widespread deployment of Oblivious DoH for over a year now, and as of recently, serves as the foundation for Flo Health Inc.’s Anonymous Mode feature.
It’s worth noting that both of these properties could be achieved with a connection-oriented protocol, but at the cost of a new end-to-end TLS connection for each message that clients wish to transmit. This can be prohibitively expensive for all entities that participate in the protocol.
So how exactly does OHTTP achieve these goals? Let’s dig deeper into OHTTP to find out.
Oblivious HTTP protocol design
A single transaction in OHTTP involves the following steps:
- A client encapsulates an HTTP request using the public key of the gateway server, and sends it to the relay over a client<>relay HTTPS connection.
- The relay forwards the request to the server over its own relay<>gateway HTTPS connection.
- The gateway decapsulates the request, forwarding it to the target server which can produce the resource.
- The gateway returns an encapsulated response to the relay, which then forwards the result to the client.
Observe that in this transaction the relay only ever sees the client and gateway identities (the client IP address and the gateway URL, respectively), but does not see any application data. Conversely, the gateway sees the application data and the relay IP address, but does not see the client IP address. Neither party has the full picture, and unless the relay and gateway collude, it stays that way.
The HTTP details for forwarding requests and responses in the transaction above are not technically interesting – a message is sent from sender to receiver over HTTPS using a POST – so we’ll skip over them. The fascinating bits are in the request and response encapsulation, which build upon HPKE, a recently ratified standard for hybrid public key encryption.
Let’s begin with request encapsulation, which is hybrid public key encryption. Clients first transform their HTTP request into a binary format, called Binary HTTP, as specified by RFC9292. Binary HTTP is, as the name suggests, a binary format for encoding HTTP messages. This representation lets clients encode HTTP requests to binary-encoded values and for the gateway to reverse this process, recovering an HTTP request from a binary-encoded value. Binary encoding is necessary because the public key encryption layer expects binary-encoded inputs.
Once the HTTP request is encoded in binary format, it is then fed into HPKE to produce an encrypted message, which clients then send to the relay to be forwarded to the gateway. The gateway decrypts this message, transforms the binary-encoded request back to its equivalent HTTP request, and then forwards it to the target server for processing.
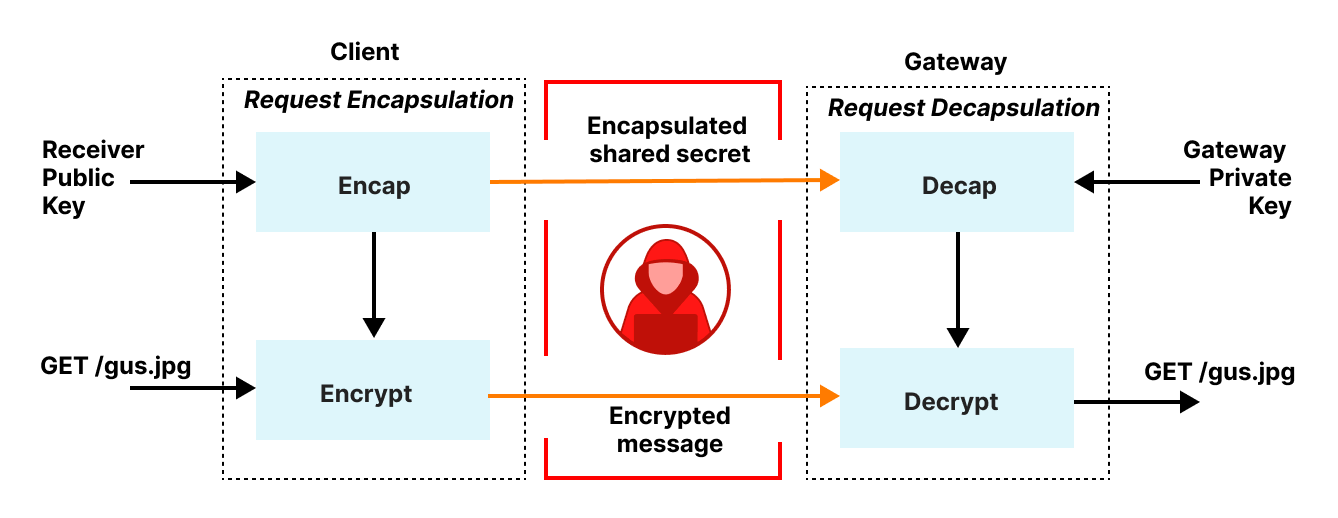
Responses from the gateway are encapsulated back to the client in a very similar fashion. The gateway first encodes the response in an equivalent binary HTTP message, encrypts it using a symmetric key known only to the client and gateway, and then returns it to the relay to be forwarded to the client. The client decrypts and transforms this message to recover the result.
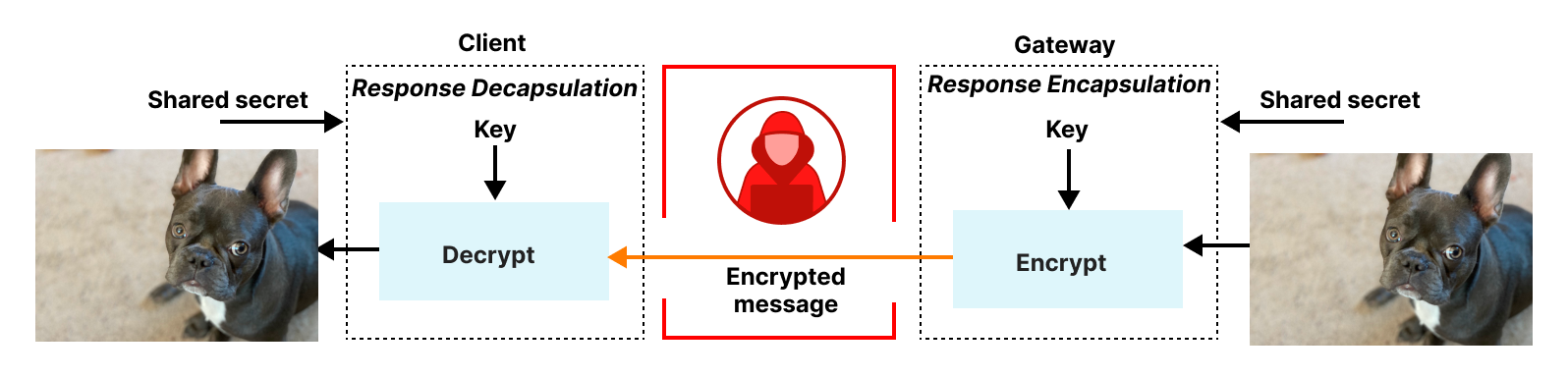
Simplified model and security goals
In our formal analysis, we set out to make sure that OHTTP’s use of encryption and proxying achieves the desired privacy goals described above.
To motivate the analysis, consider the following simplified model where there exists two clients C1 and C2, one relay R, and one gateway, G. OHTTP assumes an attacker that can observe all network activity and can adaptively compromise either R or G, but not C1 or C2. OHTTP assumes that R and G do not collude, and so we assume only one of R and G is compromised. Once compromised, the attacker has access to all session information and private key material for the compromised party. The attacker is prohibited from sending client-identifying information, such as IP addresses, to the gateway. (This would allow the attacker to trivially link a query to the corresponding client.)
In this model, both C1 and C2 send OHTTP requests Q1 and Q2, respectively, through R to G, and G provides answers A1 and A2. The attacker aims to link C1 to (Q1, A1) and C2 to (Q2, A2), respectively. The attacker succeeds if this linkability is possible without any additional interaction. OHTTP prevents such linkability. Informally, this means:
- Requests and responses are known only to clients and gateways in possession of the corresponding response key and HPKE keying material.
- The gateway cannot distinguish between two identical requests generated from the same client, and two identical requests generated from different clients, in the absence of unique per-client keys.
And informally it might seem clear that OHTTP achieves these properties. But we want to prove this formally, which means that the design, if implemented perfectly, would have these properties. This type of formal analysis is distinct from formal verification, where you take a protocol design and prove that some code implements it correctly. Whilst both are useful they are different processes, and in this blog post we’ll be talking about the former. But first, let’s give some background on formal analysis.
Formal analysis programming model
In our setting, a formal analysis involves producing an algebraic description of the protocol and then using math to prove that the algebraic description has the properties we want. The end result is proof that shows that our idealized algebraic version of the protocol is “secure”, i.e. has the desired properties, with respect to an attacker we want to defend against. In our case, we chose to model our idealized algebraic version of OHTTP using a tool called Tamarin, a security-focused theorem prover and model checker. Tamarin is an intimidating tool to use, but makes intuitive sense once you get familiar with it. We’ll break down the various parts of a Tamarin model in the context of our OHTTP model below.
Modeling the Protocol Behavior
Tamarin uses a technique known as multiset rewriting to describe protocols. A protocol description is formed of a series of “rules” that can “fire” when certain requirements are met. Each rule represents a discrete step in the protocol, and when a rule fires that means the step was taken. For example, we have a rule representing the gateway generating its long-term public encapsulation key, and for different parties in the protocol establishing secure TLS connections. These rules can be triggered pretty much any time as they have no requirements.

Tamarin represents these requirements as “facts”. A rule can be triggered when the right facts are available. Tamarin stores all the available facts in a “bag” or multiset. A multiset is similar to an ordinary set, in that it stores a collection of objects in an unordered fashion, but unlike an ordinary set, duplicate objects are allowed. This is the “multiset” part of “multiset rewriting”.
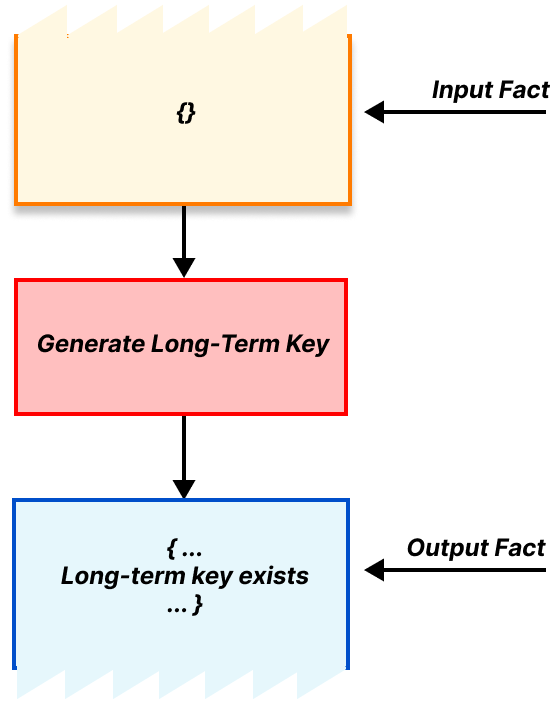
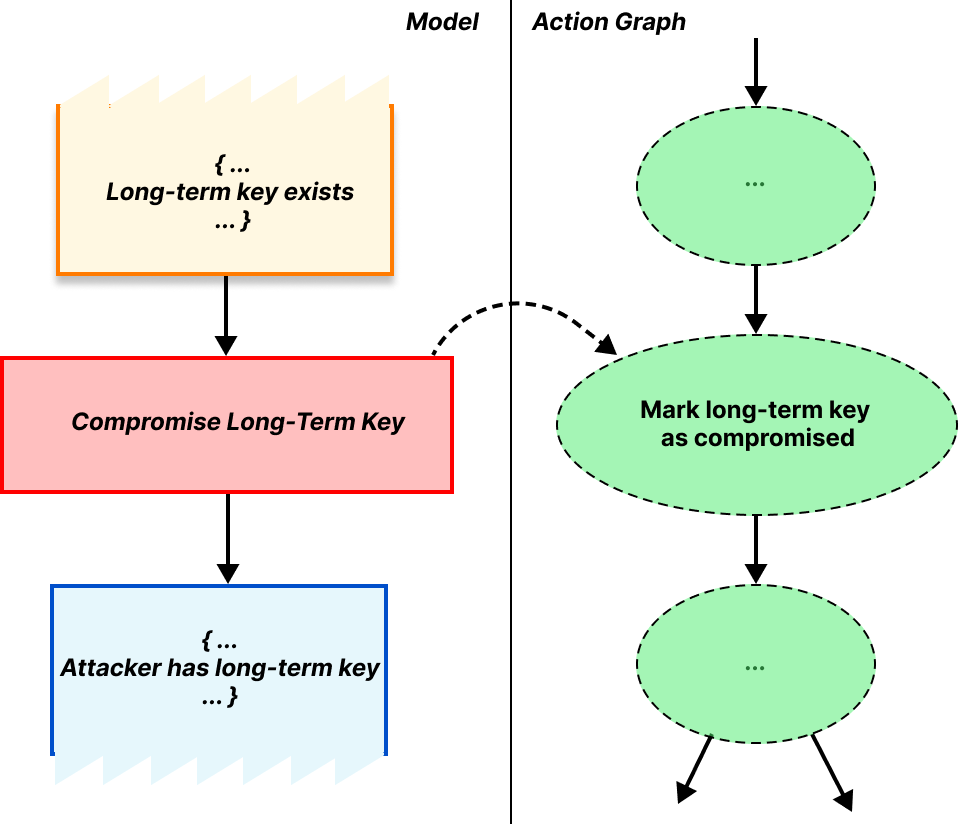
The rewriting part refers to the output of our rules. When a rule triggers it takes some available facts out of the bag and, when finished, inserts some new facts into the bag. These new facts might fulfill the requirements of some other rule, which can then be triggered, producing even more new facts, and so on1. In this way we can represent progress through the protocol. Using input and output facts, we can describe our rule for generating long-term public encapsulation keys, which has no requirements and produces a long-term key as output, as follows.
A rule requirement is satisfied if there exist output facts that match the rule’s input facts. As an example, in OHTTP, one requirement for the client rule for generating a request is that the long-term public encapsulation key exists. This matching is shown below.
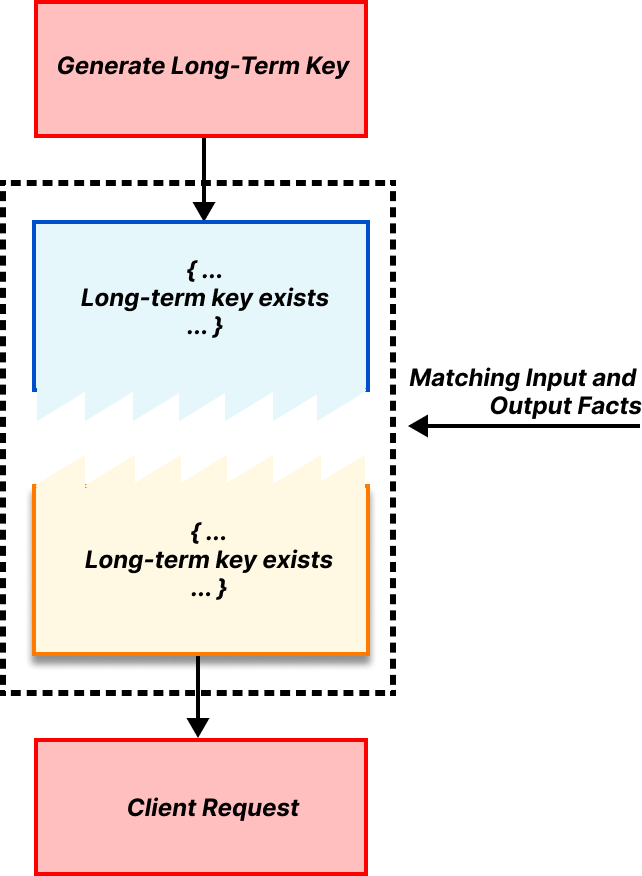
Let’s put some of these pieces together to show a very small but concrete part of OHTTP as an example: the client generating its encapsulated request and sending it to the relay. This step should produce a message for the relay, as well as any corresponding state needed to process the eventual response from the relay. As a precondition, the client requires (1) the gateway public key and (2) a TLS connection to the relay. And as mentioned earlier, generating the public key and TLS connection do not require any inputs, so they can be done at any time.

Modeling events in time
Beyond consuming and producing new facts, each Tamarin rule can also create side effects, called “action facts.” Tamarin records the action facts each time a rule is triggered. An action fact might be something like “a client message containing the contents m was sent at time t.” Sometimes rules can only be triggered in a strict sequence, and we can therefore put their action facts in a fixed time order. At other times multiple rules might have their prerequisites met at the same time, and therefore we can’t put their action facts into a strict time sequence. We can represent this pattern of partially ordered implications as a directed acyclic graph, or DAG for short.
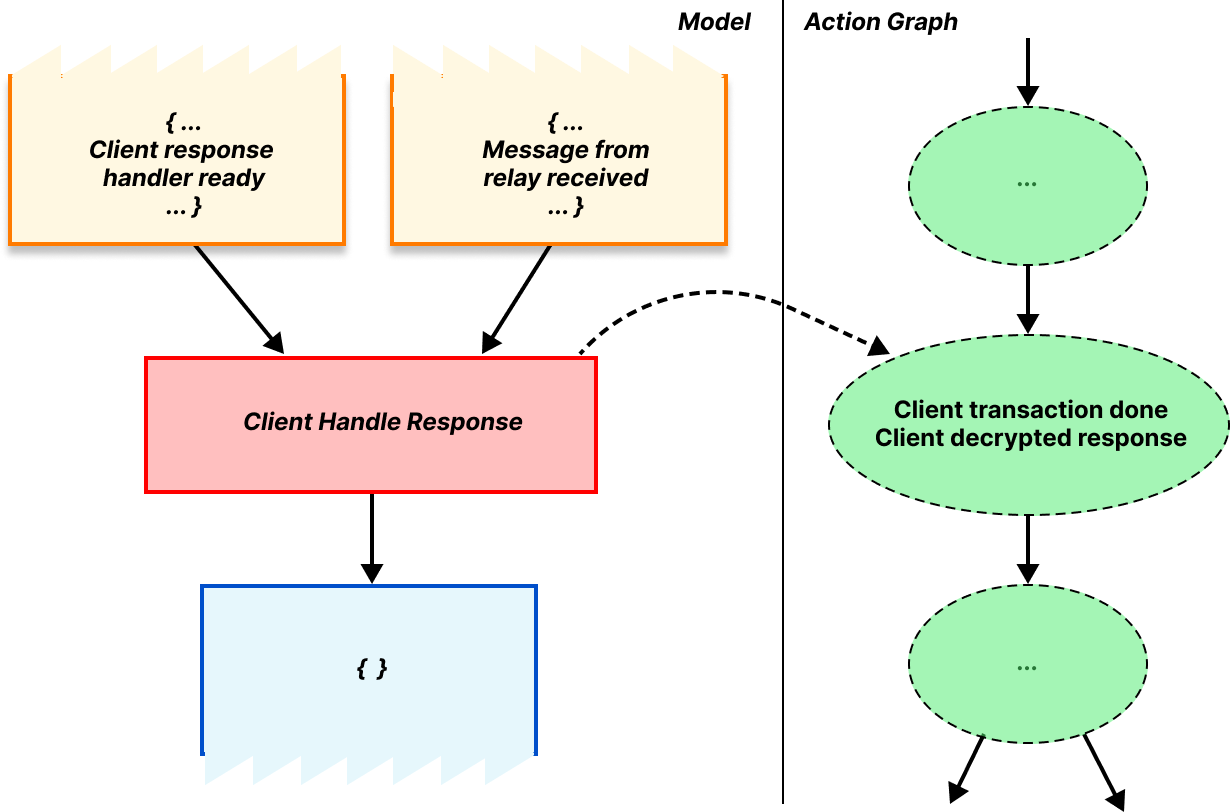
Altogether, multiset rewriting rules describe the steps of a protocol, and the resulting DAG records the actions associated with the protocol description. We refer to the DAG of actions as the action graph. If we’ve done our job well it’s possible to follow these rules and produce every possible combination of messages or actions allowed by the protocol, and their corresponding action graph.
As an example of the action graph, let’s consider what happens when the client successfully finishes the protocol. When the requirements for this rule are satisfied, the rule triggers, marking that the client is done and that the response was valid. Since the protocol is done at this point, there are no output facts produced.
Modeling the attacker
The action graph is core to reasoning about the protocol’s security properties. We can check a graph for various properties, e.g. “does the first action taken by the relay happen after the first action taken by the client?”. Our rules allow for multiple runs of the protocol to happen at the same time. This is very powerful. We can look at a graph and ask “did something bad happen here that might break the protocol’s security properties?”
In particular, we can prove (security and correctness) properties by querying this graph, or by asserting various properties about it. For example, we might say “for all runs of the protocol, if the client finishes the protocol and can decrypt the response from the gateway, then the response must have been generated and encrypted by an entity which has the corresponding shared secret.”
This is a useful statement, but it doesn’t say much about security. What happens if the gateway private key is compromised, for example? In order to prove security properties, we need to define our threat model, which includes the adversary and their capabilities. In Tamarin, we encode the threat model as part of the protocol model. For example, when we define messages being passed from the client to the relay, we can add a special rule that allows the attacker to read it as it goes past. This gives us the ability to describe properties such as “for all runs of the protocol in our language the attacker never learns the secret key.”
For security protocols, we typically give the attacker the ability to read, modify, drop, and replay any message. This is sometimes described as “the attacker controls the network”, or a Dolev-Yao attacker. However, the attacker can also sometimes compromise different entities in a protocol, learning state associated with that entity. This is sometimes called an extended Dolev-Yao attacker, and it is precisely the attacker we consider in our model.
Going back to our model, we give the attacker the ability to compromise long-term key pairs and TLS sessions as needed through different rules. These set various action facts that mark the fact that compromise took place.
Putting everything together, we have a way to model the protocol behavior, attacker capabilities, and security properties. Let’s now dive into how we applied these to prove OHTTP secure.
OHTTP Tamarin model
In our model, we give the attacker the ability to compromise the server’s long-term keys and the key between the client and the relay. Against this attacker, we aim to prove these two informal statements stated above:
- Requests and responses are known only to clients and gateways in possession of the corresponding response key and HPKE keying material.
- The gateway cannot distinguish between two requests generated from the same client, and two requests generated from different clients, in the absence of unique per-client keys.
To prove these formally, we express them somewhat differently. First, we assert that the protocol actually completes. This is an important step, because if your model has a bug in it where the protocol can’t even run as intended, then Tamarin is likely to say it’s “secure” because nothing bad ever happens.
For the core security properties, we translate the desired goals into questions we ask about the model. In this way, formal analysis only provides us proof (or disproof!) of the questions we ask, not the questions we should have asked, and so this translation relies on experience and expertise. We break down this translation for each of the questions we want to ask below, starting with gateway authentication.
Gateway authentication Unless the attacker has compromised the gateway’s long term keys, if the client completes the protocol and is able to decrypt the gateway’s response, then it knows that: the responder was the gateway it intended to use, the gateway derived the same keys, the gateway saw the request the client sent, and the response the client received is the one the gateway sent.
This tells us that the protocol actually worked, and that the messages sent and received were as they were supposed to be. One aspect of authentication can be that the participants agree on some data, so although this protocol seems to be a bit of a grab bag of properties they’re all part of one authentication property.
Next, we need to prove that the request and response remain secret. There are several ways in which secrecy may be violated, e.g., if encryption or decryption keys are compromised. We do so by proving the following properties.
Request and response secrecy
The request and response are both secret, i.e., the attacker never learns them, unless the attacker has compromised the gateway’s long term keys.
In a sense, request and response secrecy covers the case where the gateway is malicious, because if the gateway is malicious then the “attacker” knows the gateway’s long term keys.
Relay connection security
The contents of the connection between the client and relay are secret unless the attacker has compromised the relay.
We don’t have to worry about the secrecy of the connection if the client is compromised because in that scenario the attacker knows the query before it’s even been sent, and can learn the response by making an honest query itself. If your client is compromised then it’s game over.
AEAD nonce reuse resistance
If the gateway sends a message to the client, and the attacker finds a different message encrypted with the same key and nonce, then either the attacker has already compromised the gateway, or they already knew the query.
In translation, this property means that the response encryption is correct and not vulnerable to attack, such as through AEAD nonce reuse. This would obviously be a disaster for OHTTP, so we were careful to check that this situation never arises, especially as we’d already detected this issue in ODoH.
Finally, and perhaps most importantly, we want to prove that an attacker can’t link a particular query to a client. We prove a slightly different property which effectively argues that, unless the relay and gateway collude, then the attacker cannot link the encrypted query to its decrypted query together. In particular, we prove the following:
Client unlinkability
If an attacker knows the query and the contents of the connection sent to the relay (i.e. the encrypted query), then it must have compromised both the gateway and the relay.
This doesn’t in general prove indistinguishability. There are two techniques an attacker can use to link two queries. Direct inference and statistical analysis. Because of the anonymity trilemma we know that we cannot defend against statistical analysis, so we have to declare it out of scope and move on. To prevent direct inference we need to make sure that the attacker doesn't compromise either the client, or both the relay and the gateway together, which would let it directly link the queries. So is there anything we can protect against? Thankfully there is one thing. We can make sure that a malicious gateway can't identify that a single client sent two messages. We prove that by not keeping any state between connections. If a returning client acts in exactly the same way as a new client, and doesn't carry any state between requests, there's nothing for the malicious gateway to analyze.
And that’s it! If you want to have a go at proving some of these properties yourself our models and proofs are available on our GitHub, as are our ODoH models and proofs. The Tamarin prover is freely available too, so you can double-check all our work. Hopefully this post has given you a flavor of what we mean when we say that we’ve proven a protocol secure, and inspired you to have a go yourself. If you want to work on great projects like this check out our careers page.
1Depending on the model, this process can lead to an exponential blow-up in search space, making it impossible to prove anything automatically. Moreover, if the new output facts do not fulfill the requirements of any remaining rule(s) then the process hangs.