

Here at Cloudflare we're constantly working on improving our service. Our engineers are looking at hundreds of parameters of our traffic, making sure that we get better all the time.
One of the core numbers we keep a close eye on is HTTP request latency, which is important for many of our products. We regard latency spikes as bugs to be fixed. One example is the 2017 story of "Why does one NGINX worker take all the load?", where we optimized our TCP Accept queues to improve overall latency of TCP sockets waiting for accept().
Performance tuning is a holistic endeavor, and we monitor and continuously improve a range of other performance metrics as well, including throughput. Sometimes, tradeoffs have to be made. Such a case occurred in 2015, when a latency spike was discovered in our processing of HTTP requests. The solution at the time was to set tcp_rmem to 4 MiB, which minimizes the amount of time the kernel spends on TCP collapse processing. It was this collapse processing that was causing the latency spikes. Later in this post we discuss TCP collapse processing in more detail.
The tradeoff is that using a low value for tcp_rmem limits TCP throughput over high latency links. The following graph shows the maximum throughput as a function of network latency for a window size of 2 MiB. Note that the 2 MiB corresponds to a tcp_rmem value of 4 MiB due to the tcp_adv_win_scale setting in effect at the time.
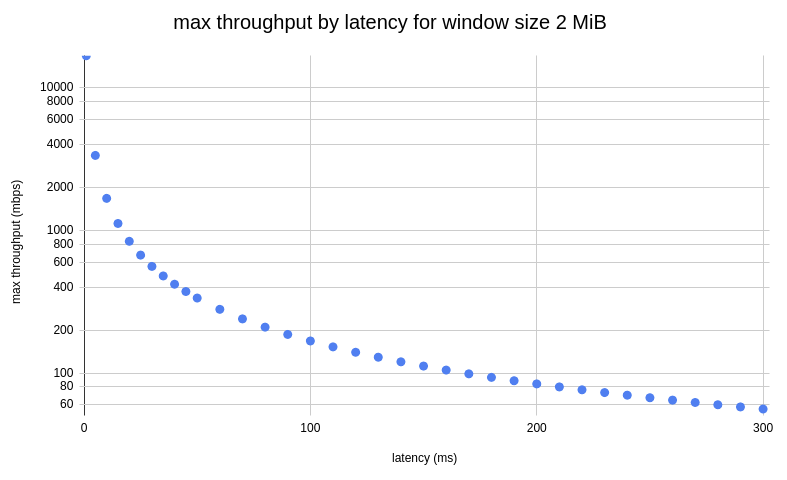
For the Cloudflare products then in existence, this was not a major problem, as connections terminate and content is served from nearby servers due to our BGP anycast routing.
Since then, we have added new products, such as Magic WAN, WARP, Spectrum, Gateway, and others. These represent new types of use cases and traffic flows.
For example, imagine you're a typical Magic WAN customer. You have connected all of your worldwide offices together using the Cloudflare global network. While Time to First Byte still matters, Magic WAN office-to-office traffic also needs good throughput. For example, a lot of traffic over these corporate connections will be file sharing using protocols such as SMB. These are elephant flows over long fat networks. Throughput is the metric every eyeball watches as they are downloading files.
We need to continue to provide world-class low latency while simultaneously providing high throughput over high-latency connections.
Before we begin, let’s introduce the players in our game.
TCP receive window is the maximum number of unacknowledged user payload bytes the sender should transmit (bytes-in-flight) at any point in time. The size of the receive window can and does go up and down during the course of a TCP session. It is a mechanism whereby the receiver can tell the sender to stop sending if the sent packets cannot be successfully received because the receive buffers are full. It is this receive window that often limits throughput over high-latency networks.
net.ipv4.tcp_adv_win_scale is a (non-intuitive) number used to account for the overhead needed by Linux to process packets. The receive window is specified in terms of user payload bytes. Linux needs additional memory beyond that to track other data associated with packets it is processing.
The value of the receive window changes during the lifetime of a TCP session, depending on a number of factors. The maximum value that the receive window can be is limited by the amount of free memory available in the receive buffer, according to this table:
| tcp_adv_win_scale | TCP window size |
|---|---|
| 4 | 15/16 * available memory in receive buffer |
| 3 | ⅞ * available memory in receive buffer |
| 2 | ¾ * available memory in receive buffer |
| 1 | ½ * available memory in receive buffer |
| 0 | available memory in receive buffer |
| -1 | ½ * available memory in receive buffer |
| -2 | ¼ * available memory in receive buffer |
| -3 | ⅛ * available memory in receive buffer |
We can intuitively (and correctly) understand that the amount of available memory in the receive buffer is the difference between the used memory and the maximum limit. But what is the maximum size a receive buffer can be? The answer is sk_rcvbuf.
sk_rcvbuf is a per-socket field that specifies the maximum amount of memory that a receive buffer can allocate. This can be set programmatically with the socket option SO_RCVBUF. This can sometimes be useful to do, for localhost TCP sessions, for example, but in general the use of SO_RCVBUF is not recommended.
So how is sk_rcvbuf set? The most appropriate value for that depends on the latency of the TCP session and other factors. This makes it difficult for L7 applications to know how to set these values correctly, as they will be different for every TCP session. The solution to this problem is Linux autotuning.
Linux autotuning
Linux autotuning is logic in the Linux kernel that adjusts the buffer size limits and the receive window based on actual packet processing. It takes into consideration a number of things including TCP session RTT, L7 read rates, and the amount of available host memory.
Autotuning can sometimes seem mysterious, but it is actually fairly straightforward.
The central idea is that Linux can track the rate at which the local application is reading data off of the receive queue. It also knows the session RTT. Because Linux knows these things, it can automatically increase the buffers and receive window until it reaches the point at which the application layer or network bottleneck links are the constraint on throughput (and not host buffer settings). At the same time, autotuning prevents slow local readers from having excessively large receive queues. The way autotuning does that is by limiting the receive window and its corresponding receive buffer to an appropriate size for each socket.
The values set by autotuning can be seen via the Linux “ss” command from the iproute package (e.g. “ss -tmi”). The relevant output fields from that command are:
Recv-Q is the number of user payload bytes not yet read by the local application.
rcv_ssthresh is the window clamp, a.k.a. the maximum receive window size. This value is not known to the sender. The sender receives only the current window size, via the TCP header field. A closely-related field in the kernel, tp->window_clamp, is the maximum window size allowable based on the amount of available memory. rcv_ssthresh is the receiver-side slow-start threshold value.
skmem_r is the actual amount of memory that is allocated, which includes not only user payload (Recv-Q) but also additional memory needed by Linux to process the packet (packet metadata). This is known within the kernel as sk_rmem_alloc.
Note that there are other buffers associated with a socket, so skmem_r does not represent the total memory that a socket might have allocated. Those other buffers are not involved in the issues presented in this post.
skmem_rb is the maximum amount of memory that could be allocated by the socket for the receive buffer. This is higher than rcv_ssthresh to account for memory needed for packet processing that is not packet data. Autotuning can increase this value (up to tcp_rmem max) based on how fast the L7 application is able to read data from the socket and the RTT of the session. This is known within the kernel as sk_rcvbuf.
rcv_space is the high water mark of the rate of the local application reading from the receive buffer during any RTT. This is used internally within the kernel to adjust sk_rcvbuf.
Earlier we mentioned a setting called tcp_rmem. net.ipv4.tcp_rmem consists of three values, but in this document we are always referring to the third value (except where noted). It is a global setting that specifies the maximum amount of memory that any TCP receive buffer can allocate, i.e. the maximum permissible value that autotuning can use for sk_rcvbuf. This is essentially just a failsafe for autotuning, and under normal circumstances should play only a minor role in TCP memory management.
It’s worth mentioning that receive buffer memory is not preallocated. Memory is allocated based on actual packets arriving and sitting in the receive queue. It’s also important to realize that filling up a receive queue is not one of the criteria that autotuning uses to increase sk_rcvbuf. Indeed, preventing this type of excessive buffering (bufferbloat) is one of the benefits of autotuning.
What’s the problem?
The problem is that we must have a large TCP receive window for high BDP sessions. This is directly at odds with the latency spike problem mentioned above.
Something has to give. The laws of physics (speed of light in glass, etc.) dictate that we must use large window sizes. There is no way to get around that. So we are forced to solve the latency spikes differently.
A brief recap of the latency spike problem
Sometimes a TCP session will fill up its receive buffers. When that happens, the Linux kernel will attempt to reduce the amount of memory the receive queue is using by performing what amounts to a “defragmentation” of memory. This is called collapsing the queue. Collapsing the queue takes time, which is what drives up HTTP request latency.
We do not want to spend time collapsing TCP queues.
Why do receive queues fill up to the point where they hit the maximum memory limit? The usual situation is when the local application starts out reading data from the receive queue at one rate (triggering autotuning to raise the max receive window), followed by the local application slowing down its reading from the receive queue. This is valid behavior, and we need to handle it correctly.
Selecting sysctl values
Before exploring solutions, let’s first decide what we need as the maximum TCP window size.
As we have seen above in the discussion about BDP, the window size is determined based upon the RTT and desired throughput of the connection.
Because Linux autotuning will adjust correctly for sessions with lower RTTs and bottleneck links with lower throughput, all we need to be concerned about are the maximums.
For latency, we have chosen 300 ms as the maximum expected latency, as that is the measured latency between our Zurich and Sydney facilities. It seems reasonable enough as a worst-case latency under normal circumstances.
For throughput, although we have very fast and modern hardware on the Cloudflare global network, we don’t expect a single TCP session to saturate the hardware. We have arbitrarily chosen 3500 mbps as the highest supported throughput for our highest latency TCP sessions.
The calculation for those numbers results in a BDP of 131MB, which we round to the more aesthetic value of 128 MiB.
Recall that allocation of TCP memory includes metadata overhead in addition to packet data. The ratio of actual amount of memory allocated to user payload size varies, depending on NIC driver settings, packet size, and other factors. For full-sized packets on some of our hardware, we have measured average allocations up to 3 times the packet data size. In order to reduce the frequency of TCP collapse on our servers, we set tcp_adv_win_scale to -2. From the table above, we know that the max window size will be ¼ of the max buffer space.
We end up with the following sysctl values:
net.ipv4.tcp_rmem = 8192 262144 536870912
net.ipv4.tcp_wmem = 4096 16384 536870912
net.ipv4.tcp_adv_win_scale = -2
A tcp_rmem of 512MiB and tcp_adv_win_scale of -2 results in a maximum window size that autotuning can set of 128 MiB, our desired value.
Disabling TCP collapse
Patient: Doctor, it hurts when we collapse the TCP receive queue.
Doctor: Then don’t do that!
Generally speaking, when a packet arrives at a buffer when the buffer is full, the packet gets dropped. In the case of these receive buffers, Linux tries to “save the packet” when the buffer is full by collapsing the receive queue. Frequently this is successful, but it is not guaranteed to be, and it takes time.
There are no problems created by immediately just dropping the packet instead of trying to save it. The receive queue is full anyway, so the local receiver application still has data to read. The sender’s congestion control will notice the drop and/or ZeroWindow and will respond appropriately. Everything will continue working as designed.
At present, there is no setting provided by Linux to disable the TCP collapse. We developed an in-house patch to the kernel to disable the TCP collapse logic.
Kernel patch – Attempt #1
The kernel patch for our first attempt was straightforward. At the top of tcp_try_rmem_schedule(), if the memory allocation fails, we simply return (after pred_flag = 0 and tcp_sack_reset()), thus completely skipping the tcp_collapse and related logic.
It didn’t work.
Although we eliminated the latency spikes while using large buffer limits, we did not observe the throughput we expected.
One of the realizations we made as we investigated the situation was that standard network benchmarking tools such as iperf3 and similar do not expose the problem we are trying to solve. iperf3 does not fill the receive queue. Linux autotuning does not open the TCP window large enough. Autotuning is working perfectly for our well-behaved benchmarking program.
We need application-layer software that is slightly less well-behaved, one that exercises the autotuning logic under test. So we wrote one.
A new benchmarking tool
Anomalies were seen during our “Attempt #1” that negatively impacted throughput. The anomalies were seen only under certain specific conditions, and we realized we needed a better benchmarking tool to detect and measure the performance impact of those anomalies.
This tool has turned into an invaluable resource during the development of this patch and raised confidence in our solution.
It consists of two Python programs. The reader opens a TCP session to the daemon, at which point the daemon starts sending user payload as fast as it can, and never stops sending.
The reader, on the other hand, starts and stops reading in a way to open up the TCP receive window wide open and then repeatedly causes the buffers to fill up completely. More specifically, the reader implemented this logic:
- reads as fast as it can, for five seconds
- this is called fast mode
- opens up the window
- calculates 5% of the high watermark of the bytes reader during any previous one second
- for each second of the next 15 seconds:
- this is called slow mode
- reads that 5% number of bytes, then stops reading
- sleeps for the remainder of that particular second
- most of the second consists of no reading at all
- steps 1-3 are repeated in a loop three times, so the entire run is 60 seconds
This has the effect of highlighting any issues in the handling of packets when the buffers repeatedly hit the limit.
Revisiting default Linux behavior
Taking a step back, let’s look at the default Linux behavior. The following is kernel v5.15.16.
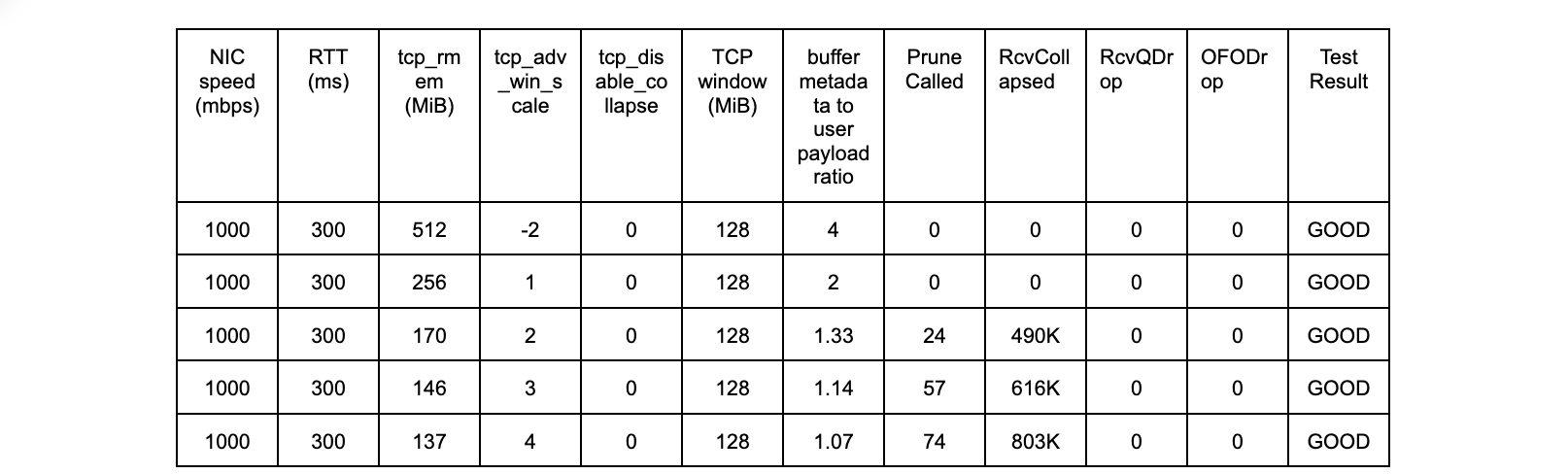
The Linux kernel is effective at freeing up space in order to make room for incoming packets when the receive buffer memory limit is hit. As documented previously, the cost for saving these packets (i.e. not dropping them) is latency.
However, the latency spikes, in milliseconds, for tcp_try_rmem_schedule(), are:
tcp_rmem 170 MiB, tcp_adv_win_scale +2 (170p2):
@ms:
[0] 27093 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[1] 0 |
[2, 4) 0 |
[4, 8) 0 |
[8, 16) 0 |
[16, 32) 0 |
[32, 64) 16 |
tcp_rmem 146 MiB, tcp_adv_win_scale +3 (146p3):
@ms:
(..., 16) 25984 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[16, 20) 0 |
[20, 24) 0 |
[24, 28) 0 |
[28, 32) 0 |
[32, 36) 0 |
[36, 40) 0 |
[40, 44) 1 |
[44, 48) 6 |
[48, 52) 6 |
[52, 56) 3 |
tcp_rmem 137 MiB, tcp_adv_win_scale +4 (137p4):
@ms:
(..., 16) 37222 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[16, 20) 0 |
[20, 24) 0 |
[24, 28) 0 |
[28, 32) 0 |
[32, 36) 0 |
[36, 40) 1 |
[40, 44) 8 |
[44, 48) 2 |
These are the latency spikes we cannot have on the Cloudflare global network.
Kernel patch – Attempt #2
So the “something” that was not working in Attempt #1 was that the receive queue memory limit was hit early on as the flow was just ramping up (when the values for sk_rmem_alloc and sk_rcvbuf were small, ~800KB). This occurred at about the two second mark for 137p4 test (about 2.25 seconds for 170p2).
In hindsight, we should have noticed that tcp_prune_queue() actually raises sk_rcvbuf when it can. So we modified the patch in response to that, added a guard to allow the collapse to execute when sk_rmem_alloc is less than the threshold value.
net.ipv4.tcp_collapse_max_bytes = 6291456
The next section discusses how we arrived at this value for tcp_collapse_max_bytes.
The patch is available here.
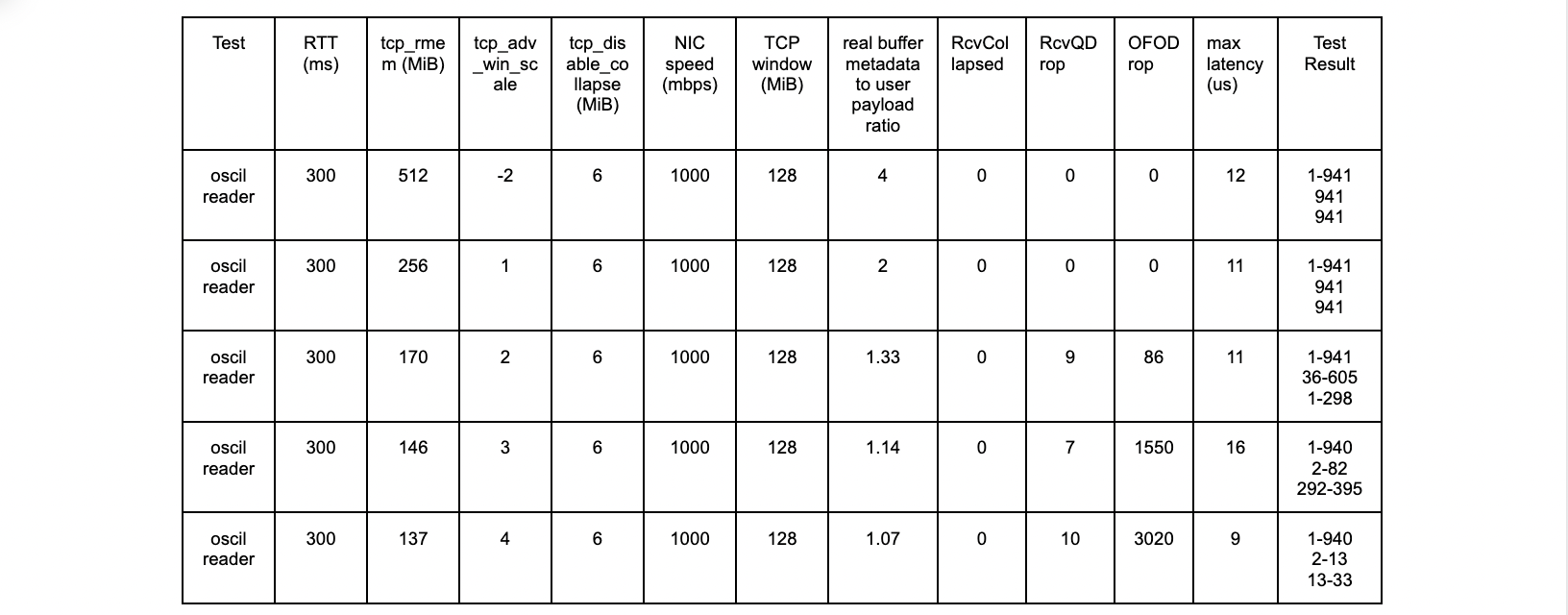
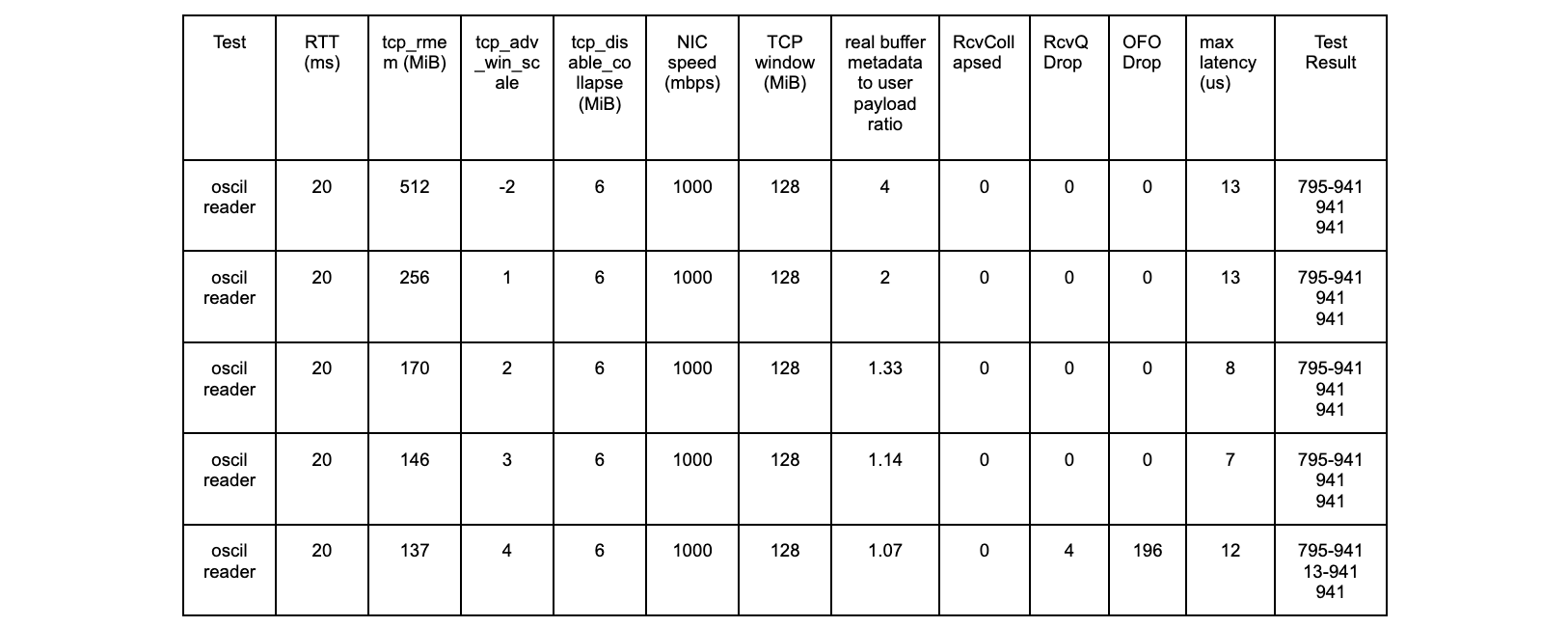
The results with the new patch are as follows:
oscil – 300ms tests
oscil – 20ms tests
oscil – 0ms tests
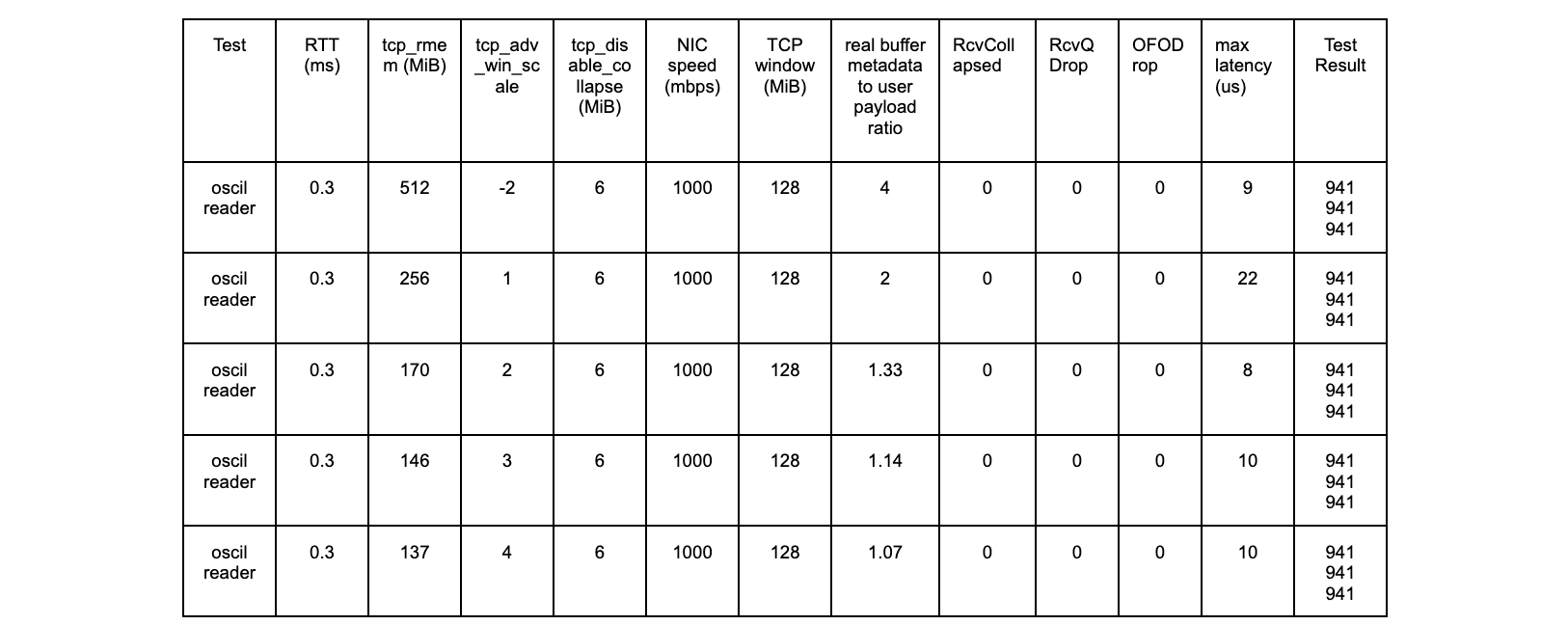
iperf3 – 300 ms tests
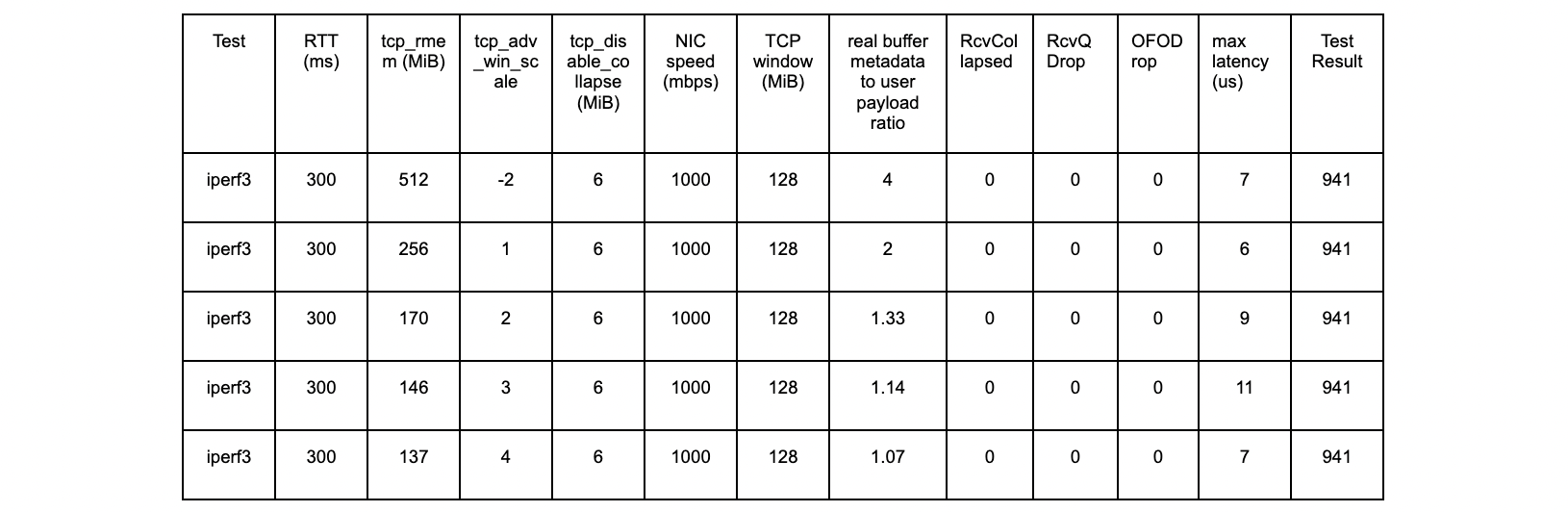
iperf3 – 20 ms tests
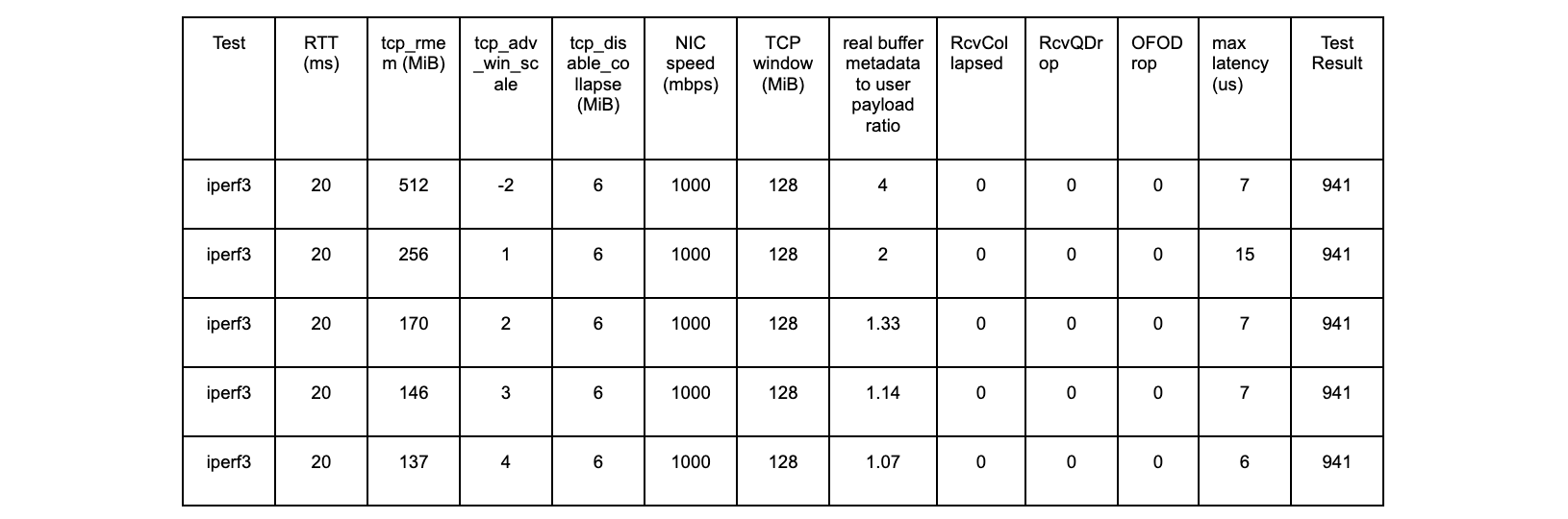
iperf3 – 0ms tests
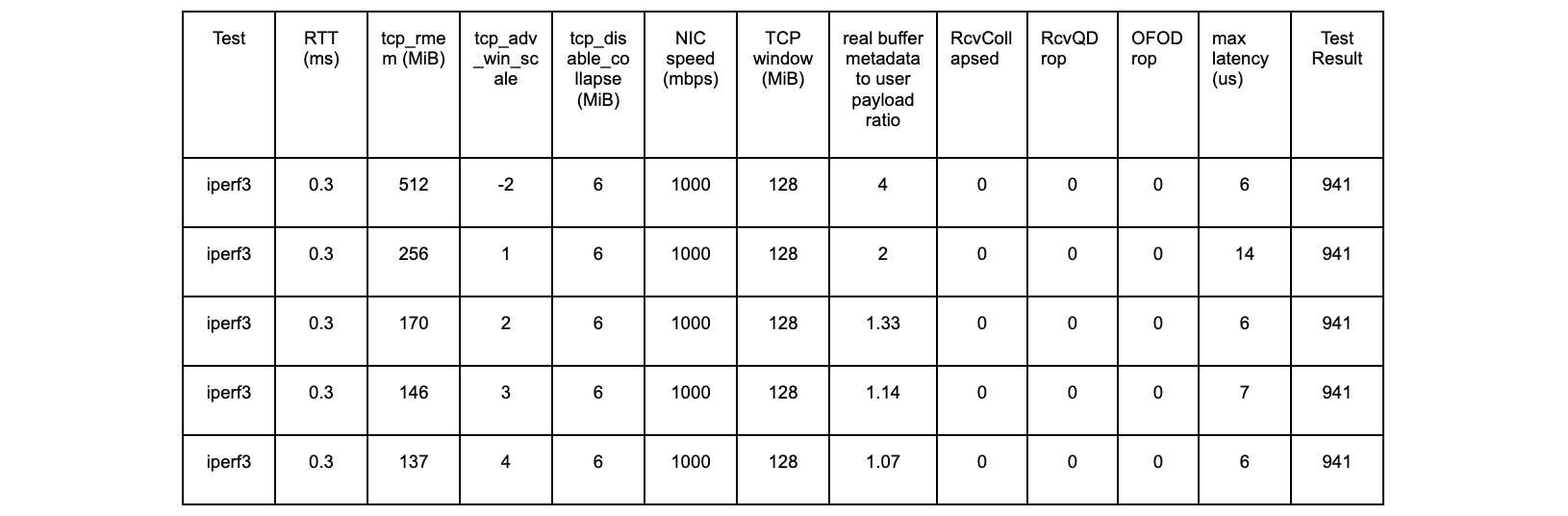
All tests are successful.
Setting tcp_collapse_max_bytes
In order to determine this setting, we need to understand what the biggest queue we can collapse without incurring unacceptable latency.
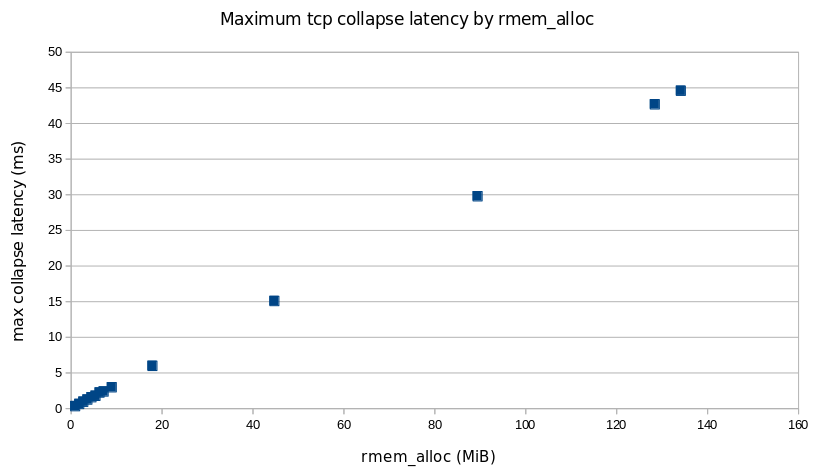
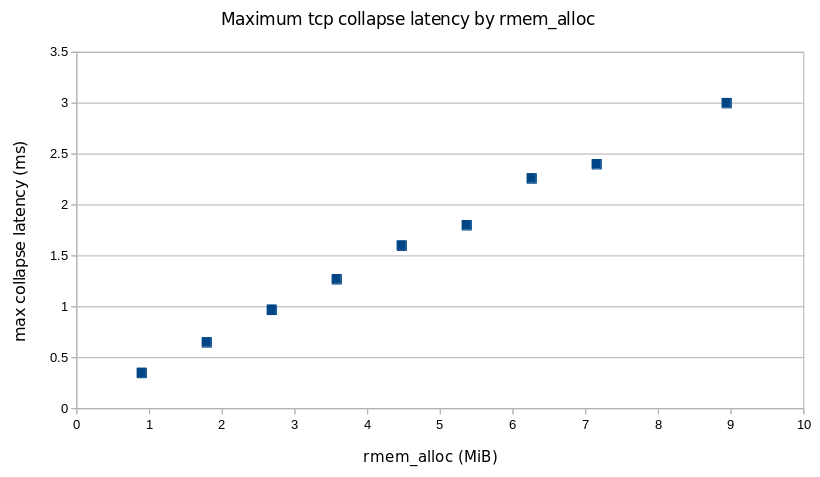
Using 6 MiB should result in a maximum latency of no more than 2 ms.
Cloudflare production network results
Current production settings (“Old”)
net.ipv4.tcp_rmem = 8192 2097152 16777216
net.ipv4.tcp_wmem = 4096 16384 33554432
net.ipv4.tcp_adv_win_scale = -2
net.ipv4.tcp_collapse_max_bytes = 0
net.ipv4.tcp_notsent_lowat = 4294967295
tcp_collapse_max_bytes of 0 means that the custom feature is disabled and that the vanilla kernel logic is used for TCP collapse processing.
New settings under test (“New”)
net.ipv4.tcp_rmem = 8192 262144 536870912
net.ipv4.tcp_wmem = 4096 16384 536870912
net.ipv4.tcp_adv_win_scale = -2
net.ipv4.tcp_collapse_max_bytes = 6291456
net.ipv4.tcp_notsent_lowat = 131072
The tcp_notsent_lowat setting is discussed in the last section of this post.
The middle value of tcp_rmem was changed as a result of separate work that found that Linux autotuning was setting receive buffers too high for localhost sessions. This updated setting reduces TCP memory usage for those sessions, but does not change anything about the type of TCP sessions that is the focus of this post.
For the following benchmarks, we used non-Cloudflare host machines in Iowa, US, and Melbourne, Australia performing data transfers to the Cloudflare data center in Marseille, France. In Marseille, we have some hosts configured with the existing production settings, and others with the system settings described in this post. Software used is perf3 version 3.9, kernel 5.15.32.
Throughput results
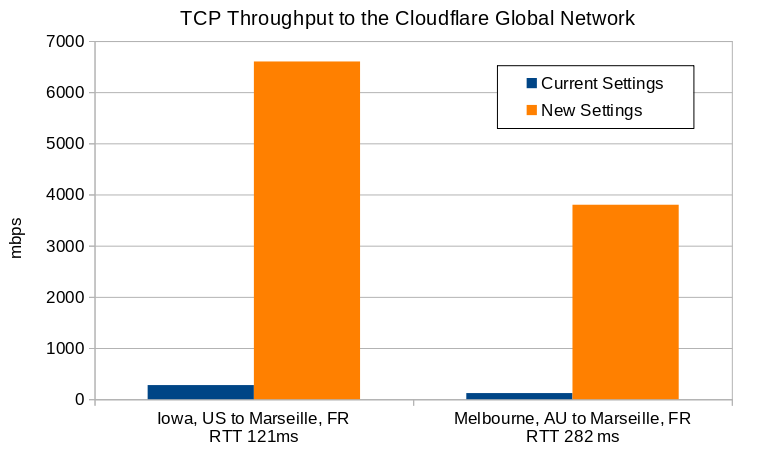
| RTT (ms) | Throughput with Current Settings (mbps) | Throughput with New Settings (mbps) | Increase Factor | |
|---|---|---|---|---|
| Iowa to Marseille | 121 | 276 | 6600 | 24x |
| Melbourne to Marseille | 282 | 120 | 3800 | 32x |
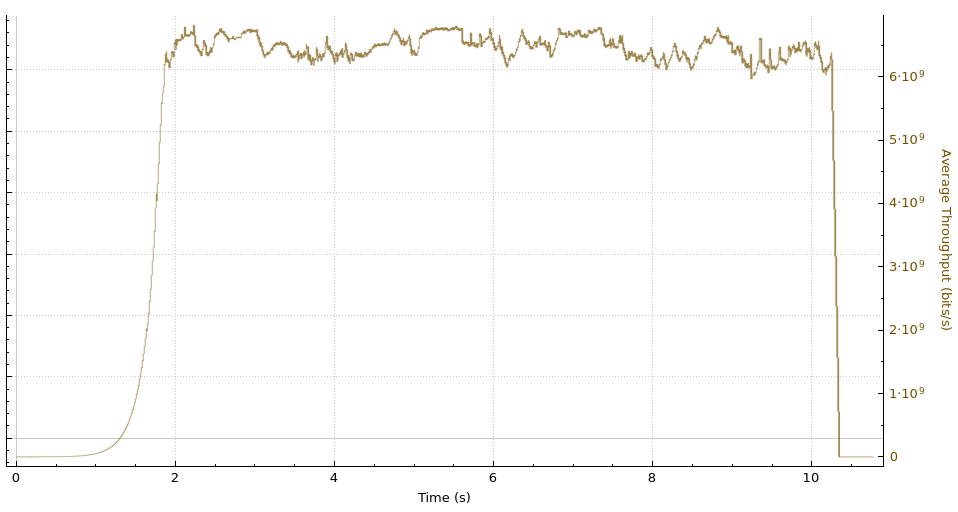
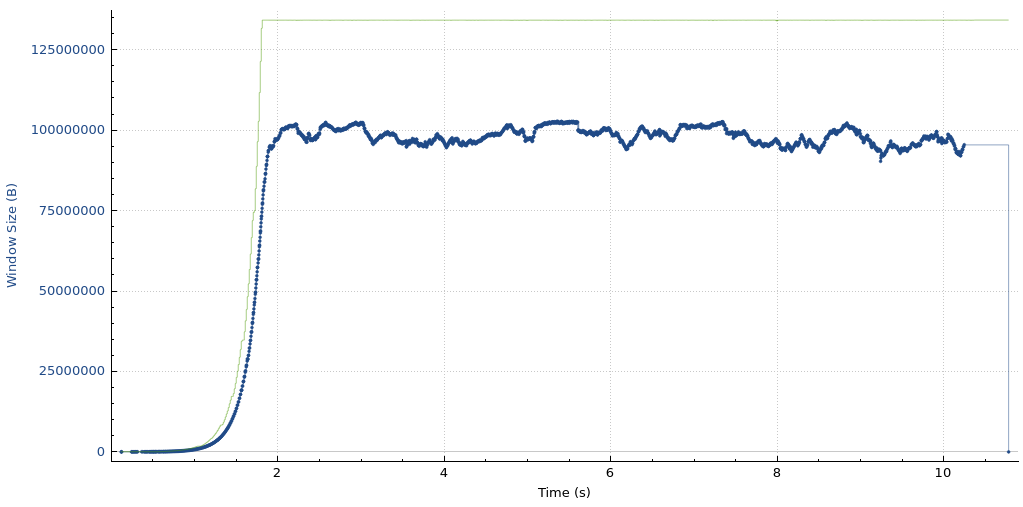
Iowa-Marseille throughput
Iowa-Marseille receive window and bytes-in-flight
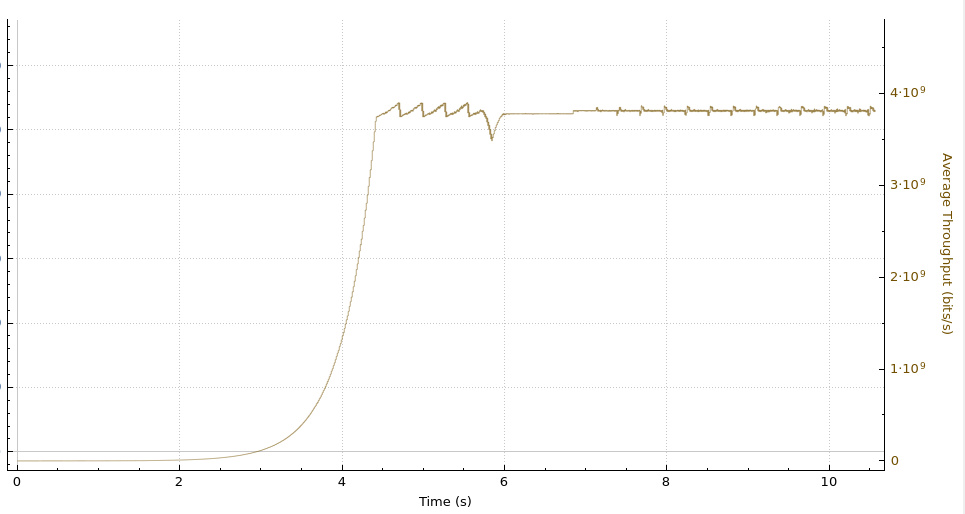
Melbourne-Marseille throughput
Melbourne-Marseille receive window and bytes-in-flight
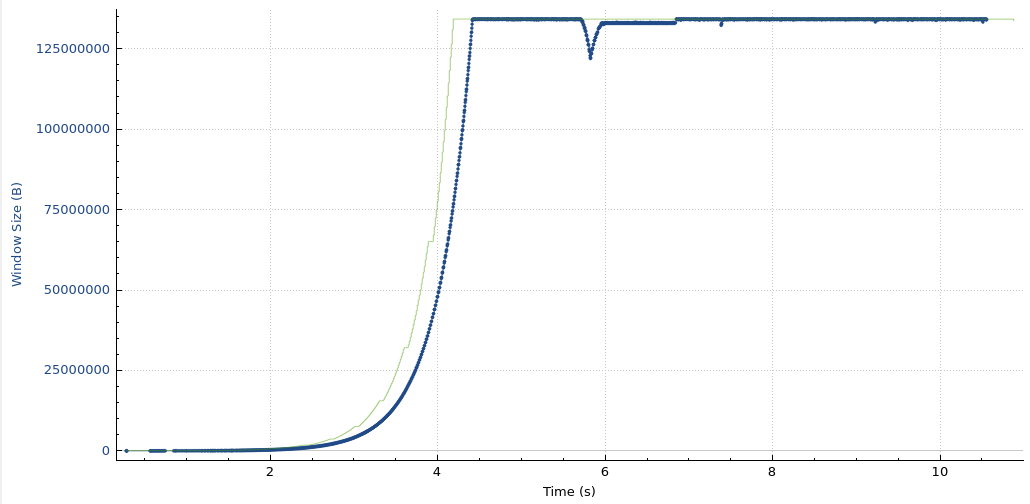
Even with the new settings in place, the Melbourne to Marseille performance is limited by the receive window on the Cloudflare host. This means that further adjustments to these settings yield even higher throughput.
Latency results
The Y-axis on these charts are the 99th percentile time for TCP collapse in seconds.
Cloudflare hosts in Marseille running the current production settings
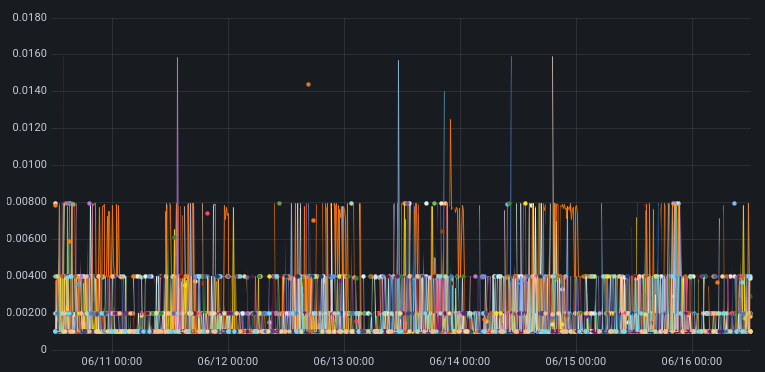
Cloudflare hosts in Marseille running the new settings
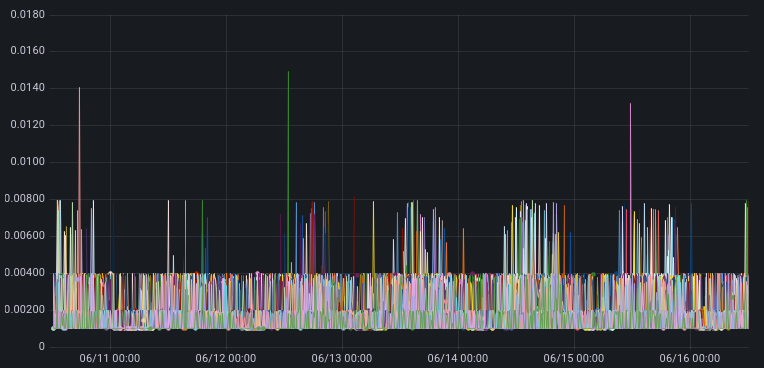
The takeaway in looking at these graphs is that maximum TCP collapse time for the new settings is no worse than with the current production settings. This is the desired result.
Send Buffers
What we have shown so far is that the receiver side seems to be working well, but what about the sender side?
As part of this work, we are setting tcp_wmem max to 512 MiB. For oscillating reader flows, this can cause the send buffer to become quite large. This represents bufferbloat and wasted kernel memory, both things that nobody likes or wants.
Fortunately, there is already a solution: tcp_notsent_lowat. This setting limits the size of unsent bytes in the write queue. More details can be found at https://lwn.net/Articles/560082.
The results are significant:
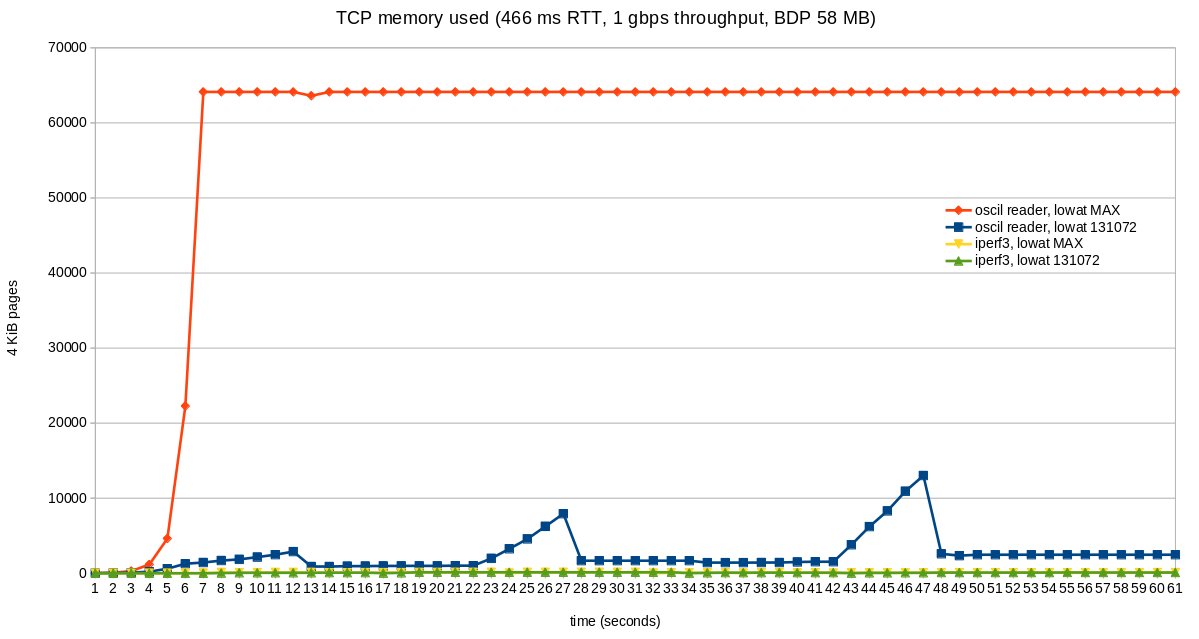
The RTT for these tests was 466ms. Throughput is not negatively affected. Throughput is at full wire speed in all cases (1 Gbps). Memory usage is as reported by /proc/net/sockstat, TCP mem.
Our web servers already set tcp_notsent_lowat to 131072 for its sockets. All other senders are using 4 GiB, the default value. We are changing the sysctl so that 131072 is in effect for all senders running on the server.
Conclusion
The goal of this work is to open the throughput floodgates for high BDP connections while simultaneously ensuring very low HTTP request latency.
We have accomplished that goal.
...
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.To learn more about our mission to help build a better Internet, start here. If you’re looking for a new career direction, check out our open positions.