


LoRA를 통해 미세 조정된 LLM으로부터의 추론이 현재 오픈 베타 버전으로 제공됩니다
오늘, 이제 Workers AI에서 LoRA로 미세 조정된 추론을 실행할 수 있게 되었다는 기쁜 소식을 알려드립니다. 이 기능은 오픈 베타 버전으로 사전 학습된 LoRA 어댑터에서 Mistral, Gemma, Llama 2와 함께 사용할 수 있으며, 몇 가지 제약이 있습니다. 제품 발표 블로그 게시물에서 BYO(Bring Your Own) LoRA 기능에 대한 간략한 개요를 살펴보세요.
이 게시물에서는 미세 조정과 LoRA가 무엇인지 자세히 살펴보고, Workers AI 플랫폼에서 이를 사용하는 방법을 소개한 다음, 이를 저희 플랫폼에서 구현한 방법에 대한 기술적 세부 사항을 자세히 알아보겠습니다.
미세 조정이란?
미세 조정은 추가 데이터로 계속 학습시켜 AI 모델을 수정하는 것을 가리키는 일반적인 용어입니다. 미세 조정의 목표는 데이터 세트와 유사한 세대가 생성될 확률을 높이는 것입니다. 모델을 처음부터 학습시키는 것은 학습에 많은 비용과 시간이 소요될 수 있으므로 많은 사용 사례에서 실용적이지 않습니다. 기존의 사전 학습된 모델을 미세 조정하면 모델의 기능을 활용하면서 원하는 작업을 수행할 수 있습니다. Low-Rank Adaptation(LoRA)은 LLM뿐만 아니라 다양한 모델 아키텍처에 적용할 수 있는 특정 미세 조정 방법입니다. 기존의 미세 조정 방법에서는 사전 학습된 모델 가중치를 직접 수정하거나 추가 미세 조정 가중치를 융합하는 것이 일반적입니다. 반면 LoRA에서는 미세 조정 가중치와 사전 학습된 모델이 분리된 상태로 유지되며, 사전 학습된 모델은 변경되지 않습니다. 그 결과 코드 생성, 특정 성격, 특정 스타일의 이미지 생성 등 특정 작업을 더 정확하게 수행하도록 모델을 학습시킬 수 있습니다. 특정 주제에 대한 추가 정보를 이해하도록 기존 LLM을 미세 조정할 수도 있습니다.
원래의 기본 모델 가중치를 유지하는 방식은 상대적으로 적은 연산으로 새로운 미세 조정 가중치를 생성할 수 있다는 것을 의미합니다. 기존의 기본 모델(예: Llama, Mistral, Gemma)을 활용하고 필요에 맞게 조정할 수 있습니다.
미세 조정은 어떻게 이루어질까요?
미세 조정과 LoRA가 그처럼 효과적인 이유를 더 잘 이해하려면 AI 모델의 작동 방식을 한 걸음 뒤로 물러나서 이해해야 합니다. AI 모델(LLM과 같은)은 딥러닝 기법을 통해 학습된 신경망입니다. 신경망에는 모델의 도메인 지식을 수학적으로 표현하는 역할을 하는 일련의 매개변수가 있으며, 이는 가중치와 편향성(쉽게 말해 숫자)으로 구성됩니다. 이러한 매개변수는 일반적으로 큰 숫자 행렬로 표현됩니다. 모델에 매개변수가 많을수록 모델의 크기가 커지므로 llama-2-7b와 같은 모델을 볼 때 "7b"를 읽으면 이 모델에 70억 개의 매개변수가 있음을 알 수 있습니다.
모델의 매개변수는 모델의 동작을 정의합니다. 모델을 처음부터 학습시킬 때 이들 매개 변수는 일반적으로 임의의 숫자로 시작합니다. 데이터 세트에 대해 모델을 학습시키면 모델이 데이터 세트를 반영하고 올바른 동작을 보일 때까지 이러한 매개변수가 조금씩 조정됩니다. 어떤 매개변수는 다른 매개변수보다 더 중요할 수 있으므로 우리는 가중치를 적용하여 그 가중치를 중요도를 표시하는 데 사용합니다. 가중치는 학습 대상 데이터의 패턴과 관계를 포착하는 모델의 능력에 중요한 역할을 합니다.
기존의 미세 조정은 학습된 모델의 모든 매개변수를 새로운 가중치 세트로 조정합니다 . 따라서 미세 조정된 모델은 원래 모델과 동일한 양의 매개변수를 제공해야 하므로 완전히 미세 조정된 모델을 학습하고 추론을 실행하는 데 많은 시간과 계산이 소요될 수 있습니다. 게다가 새로운 최신 모델 또는 기존 모델의 버전이 정기적으로 출시되므로 완전히 미세 조정된 모델을 학습, 유지, 저장하려면 많은 비용이 들 수 있습니다.
LoRA는 효율적인 미세 조정 방법입니다
간단히 말해, LoRA는 사전 학습된 모델에서 매개변수를 조정하지 않고 대신 소수의 추가 매개변수를 적용할 수 있습니다. 이러한 추가 매개변수는 모델 동작을 효과적으로 제어하기 위해 기본 모델에 일시적으로 적용됩니다. LoRA 어댑터라고 하는 이러한 추가 매개변수를 학습하는 데 필요한 시간과 컴퓨팅은 기존의 미세 조정 방식에 비해 훨씬 줄어듭니다. 학습이 끝나면 LoRA 어댑터를 별도의 모델 파일로 패키지화하여 학습한 기본 모델에 연결할 수 있습니다. 완전히 미세 조정된 모델은 크기가 수십 기가바이트에 달할 수 있지만, 이러한 어댑터는 일반적으로 몇 메가바이트에 불과합니다. 따라서 배포가 훨씬 쉬워지며, LoRA로 미세 조정된 추론을 제공하면 총 추론 시간에 대기 시간이 몇 ms만 추가됩니다.
LoRA가 왜 효과적인지 궁금하면 먼저 선형 대수학에 대한 간단한 강의를 들어보시기 바랍니다. 대학 시절부터 접해 본 용어가 아니더라도 걱정하지 마세요. 자세히 설명해 드립니다.
수학 살펴보기
기존의 미세 조정을 사용하면 모델의 가중치(W0)를 가져와 조정하여 새로운 가중치 집합을 출력할 수 있으므로 원래 모델 가중치와 새 가중치 사이의 차이는 ΔW가 되며 이는 가중치의 변화를 나타냅니다. 따라서 조정된 모델은 새로운 가중치 집합을 가지게 되며, 이는 원래 모델 가중치와 가중치 변화(W0 + ΔW)로 표현할 수 있습니다.
이러한 모든 모델 가중치는 실제로는 큰 숫자 행렬로 표현된다는 점을 기억하세요. 수학에서 모든 행렬에는 행렬에서 선형적으로 독립적인 열 또는 행의 수를 나타내는 랭크(r)라는 속성이 있습니다. 행렬의 랭크가 낮으면 "중요한" 열이나 행이 몇 개 밖에 없으므로 실제로 가장 중요한 매개변수를 사용하여 행렬을 두 개의 작은 행렬로 분해하거나 분할할 수 있습니다(대수에서 인수분해하는 것처럼 생각하세요). 이 기술을 랭크 분해라고 하는데, 이를 통해 가장 중요한 비트는 유지하면서 행렬을 크게 줄이고 단순화할 수 있습니다. 미세 조정의 맥락에서 랭크는 원래 모델에서 변경되는 매개변수의 수를 결정하며, 랭크가 높을수록 미세 조정이 더 강력해져 출력에 대한 세분성이 더 커집니다.
원래 LoRA 논문에 따르면 , 연구자들은 모델이 낮은 랭크인 경우 가중치의 변화를 나타내는 행렬도 낮은 랭크라는 사실을 발견했습니다. 따라서 가중치의 변화를 나타내는 행렬 ΔW에 랭크 분해를 적용하여 ΔW = BA인 두 개의 작은 행렬 A, B를 만들 수 있습니다 . 이제 모델의 변화는 랭크가 더 낮은 두 개의 행렬로 표현할 수 있습니다. 이것이 바로 이 미세 조정 방법을 Low-Rank Adaptation이라고 부르는 이유입니다.
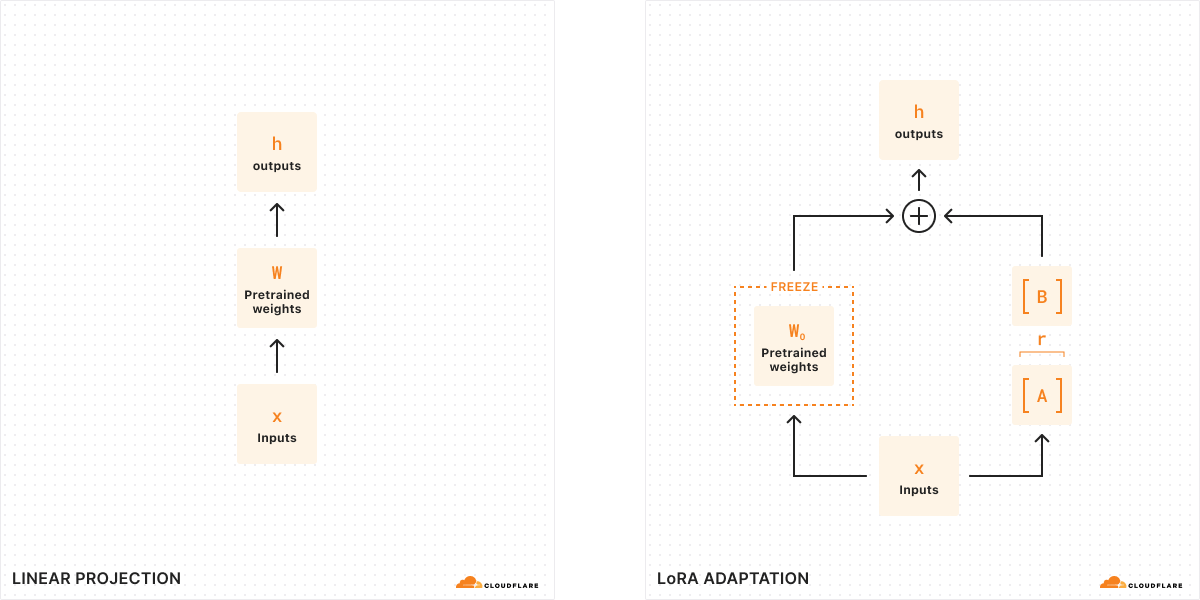
추론을 실행할 때는 모델의 동작을 변경하기 위해 더 작은 행렬 A, B만 필요합니다. A, B의 모델 가중치는 구성 파일과 함께 LoRA 어댑터를 구성합니다. 런타임에 모델 가중치를 합산하여 원래 모델(W0)과 LoRA 어댑터(A, B)를 결합합니다. 더하기와 빼기는 간단한 수학적 연산이므로 A, B를 W0에서 더하고 빼는 방식으로 다른 LoRA 어댑터를 빠르게 교체할 수 있습니다. 원래 모델의 가중치를 일시적으로 조정함으로써 모델의 동작과 출력을 수정하고 그 결과로 대기 시간을 최소화하면서 미세 조정된 추론을 얻을 수 있습니다.
원래 LoRA 논문에 따르면, "LoRA는 학습 가능한 매개변수의 수를 10,000배, GPU 메모리 요구량을 3배까지 줄일 수 있다"고 합니다. 이 때문에 LoRA는 완전히 미세 조정된 모델보다 계산 비용이 훨씬 적게 들고, 자료 추론 시간이 추가되지 않으며, 훨씬 작고 휴대가 간편하므로 가장 많이 사용되는 미세 조정 방법 중 하나입니다.
LoRA를 Workers AI와 함께 사용하는 방법은?
Workers AI는 서버리스 추론을 실행하는 방식 때문에 LoRA를 실행하는 데 매우 적합합니다. 저희 카탈로그에 있는 모델은 항상 GPU에 사전 로드되어 있으므로 요청 시 콜드 스타트 문제가 발생하지 않도록 예열 상태가 유지됩니다. 이는 기본 모델을 항상 사용할 수 있으며 필요에 따라 LoRA 어댑터를 동적으로 로드하고 교체할 수 있음을 의미합니다. 실제로 하나의 기본 모델에 여러 개의 LoRA 어댑터를 연결할 수 있으므로 여러 가지 미세 조정된 추론 요청을 한 번에 제공할 수 있습니다.
LoRA로 미세 조정하면 사용자 지정 모델 가중치( 세이프텐서 형식)와 어댑터 구성 파일(json 형식)의 두 가지 파일이 출력됩니다. 이러한 가중치를 직접 생성하려면 Hugging Face PEFT(매개변수 효율적 미세 조정) 라이브러리와 Hugging Face AutoTrain LLM 라이브러리를 함께 사용하여 자체 데이터에 대해 LoRA를 학습시킬 수 있습니다. Auto Train 및 Google Colab 등의 서비스에서 학습 작업을 실행할 수도 있습니다. 아니면, 현재 Hugging Face에도 다양한 사용 사례를 지원하는 많은 오픈 소스 LoRA 어댑터가 있습니다.
저희는 궁극적으로는 플랫폼에서 LoRA 학습 워크로드를 지원하고자 하지만, 지금 당장 학습된 LoRA 어댑터를 Workers AI에 가져와야 하므로 이 기능을 BYO(Bring Your Own) LoRA라고 부르고 있습니다.
초기 오픈 베타 릴리스에서는 저희 Mistral, Llama, Gemma 모델에서 LoRA를 사용할 수 있도록 허용하고 있습니다. 이러한 모델의 경우 LoRA를 허용하는 버전이 따로 마련되어 있으며, 모델 이름 끝에 `-lora`를 추가하면 액세스할 수 있습니다. 아래 나열된 지원되는 기본 모델 중 하나에서 어댑터를 미세 조정해야 합니다.
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
이 기능은 오픈 베타 버전으로 출시하는 만큼, 현재 몇 가지 제약이 있습니다. 양자화된 LoRA 모델은 아직 지원되지 않고, LoRA 어댑터는 100MB 미만이어야 하며 최대 랭크 8까지만 지원되고, 초기 오픈 베타 버전에서는 계정당 최대 30개의 LoRA를 사용해 볼 수 있습니다. Workers AI에서 LoRA를 시작하려면 개발자 문서를 참조하세요.
항상 그렇듯이, 저희는 고객이 모델별 라이선스 약관에 포함된 모델별 사용 제약을 포함하여 서비스 약관을 염두에 두면서 Workers AI와 새로운 BYO LoRA 기능을 사용하길 기대합니다.
다중 테넌트 LoRA 서비스를 어떻게 구축했을까요?
여러 LoRA 모델을 동시에 서비스하면 GPU 리소스 사용률 측면에서 문제가 발생합니다. 추론 요청을 기본 모델에 일괄 처리할 수는 있지만, 고유한 LoRA 어댑터에 서비스를 제공해야 하는 복잡성이 추가되므로 요청을 일괄 처리하는 것이 훨씬 더 어렵습니다. 이 문제를 해결하기 위해 저희는 글로벌 캐시 최적화와 함께 Punica CUDA 커널 설계를 활용하여 다중 테넌트 LoRA 서비스의 메모리 집약적인 워크로드를 처리하는 동시에 짧은 추론 대기 시간을 제공합니다.
Punica CUDA 커널은 Punica: 다중 테넌트 LoRA 서비스 논문에서 동일한 기본 모델에 적용된 상당히 다른 여러 개의 LoRA 모델을 서비스하는 방법으로 소개되었습니다. 이 방법은 이전의 추론 기법에 비해 처리량과 대기 시간이 크게 개선되었습니다. 이러한 최적화는 부분적으로는 서로 다른 LoRA 어댑터에 서비스를 제공하는 요청 간에도 요청 일괄 처리를 가능하게 함으로써 달성됩니다.
Punica 커널 시스템의 핵심은 Segmented Gather Matrix-Vector Multiplication(SGMV)이라는 새로운 CUDA 커널입니다. SGMV를 사용하면 GPU가 사전 학습된 모델의 사본 하나만 저장하면서 다른 LoRA 모델을 제공할 수 있습니다. Punica 커널 설계 시스템은 고유한 LoRA 모델에 대한 요청을 일괄 처리하여 다양한 요청의 기능 가중치 곱셈을 병렬화함으로써 성능을 개선합니다. 그런 다음 동일한 LoRA 모델에 대한 요청을 그룹화하여 운영 강도를 높입니다. 처음에 GPU는 기본 모델을 로드하면서 대부분의 GPU 메모리를 KV 캐시용으로 예약합니다. 그런 다음 수신 요청에 의해 필요할 때 원격 스토리지(Cloudflare의 캐시 또는 R2)에서 LoRA 구성 요소(A 및 B 행렬)를 온디맨드 방식으로 로드합니다. 이 온디맨드 로딩은 밀리초의 대기 시간만 발생하므로 추론 성능에 미치는 영향을 최소화하면서 여러 개의 LoRA 어댑터를 원활하게 가져와 제공할 수 있습니다. 자주 요청되는 LoRA 어댑터는 최대한 빠른 추론을 위해 캐시됩니다.
요청된 LoRA가 로컬에 캐시된 후에는 추론에 사용할 수 있는 속도가 PCIe 대역폭에 따라서만 제한됩니다. 그럼에도 불구하고 각 요청마다 자체 LoRA가 필요할 수 있으므로 LoRA 다운로드 및 메모리 복사 작업이 비동기적으로 수행되는 것이 중요합니다. Punica 스케줄러는 이 문제를 정확히 해결하여 현재 GPU 메모리에서 필요한 LoRA 가중치를 사용할 수 있는 요청만 일괄 처리하고, 필요한 가중치를 사용할 수 있고 요청이 효율적으로 일괄 처리에 참여할 수 있을 때까지 가중치를 사용할 수 없는 요청은 대기열에 대기시킵니다.
KV 캐시를 효과적으로 관리하고 이러한 요청을 일괄 처리하면 상당한 규모의 다중 테넌트 LoRA 서비스 워크로드를 처리할 수 있습니다. 또 다른 중요한 최적화는 연속 일괄 처리를 사용하는 것입니다. 일반적인 일괄 처리 방법은 동일한 어댑터에 대한 모든 요청이 중지 조건에 도달해야 해제됩니다. 연속 일괄 처리를 사용하면 일괄 처리 요청을 조기에 릴리스하여 가장 오래 실행 중인 요청을 기다릴 필요가 없도록 할 수 있습니다.
Cloudflare의 네트워크에 배포된 LLM은 전 세계에 걸쳐 사용 가능하므로, LoRA 어댑터 모델도 전 세계에 걸쳐 사용 가능한지 확인하는 것이 중요합니다. 저희는 조만간 Cloudflare의 에지에서 캐시되는 원격 모델 파일을 구현하여 추론 대기 시간을 더욱 줄일 예정입니다.
Workers AI의 미세 조정을 위한 로드맵
LoRA 어댑터에 대한 지원을 시작하는 것은 플랫폼의 미세 조정을 위한 중요한 단계입니다. 현재 제공되는 LLM 미세 조정 외에도 이미지 생성을 비롯한 더 많은 모델과 다양한 작업 유형을 지원할 수 있기를 기대합니다.
Workers AI의 저희 비전은 개발자가 AI 워크로드를 실행할 수 있는 최고의 공간을 마련하는 것이며, 여기에는 자체 미세 조정 프로세스도 포함됩니다. 궁극적으로는 미세 조정 학습 작업은 물론 완전히 미세 조정된 모델을 Workers AI에서 직접 실행할 계획입니다. 이를 통해 특정 작업에 대해 모델이 더 세분화되고 세부적인 기능을 갖출 수 있도록 지원함으로써 조직에서 AI의 활용도를 높일 수 있는 많은 사용 사례가 열리게 됩니다.
AI Gateway를 통해 개발자가 프롬프트와 응답을 기록하여 프로덕션 데이터로 모델을 미세 조정하는 데 사용할 수 있도록 지원할 수 있습니다. 저희 비전은 AI Gateway의 로그 데이터를 사용하여 모델을 재학습(Cloudflare에서)시킨 다음, 미세 조정된 모델을 추론을 위해 Workers AI에 다시 배포할 수 있는 원클릭 미세 조정 서비스를 제공하는 것입니다. 이를 통해 개발자는 자신의 앱에 맞게 AI 모델을 맞춤화할 수 있으며, 사용자별 수준까지 세분화할 수 있습니다. 이렇게 미세 조정된 모델은 더 작고 최적화되어 사용자가 AI 추론에 소요되는 시간과 비용을 절약할 수 있습니다. 이 모든 것이 저희 개발자 플랫폼내에서 이루어질 수 있다는 점이 가장 큰 장점입니다.
고객들이 BYO LoRA의 오픈 베타를 사용해 보실 수 있게 되어 기쁩니다! 자세한 내용은 개발자 문서를 읽어보시고 Discord에 의견을 남겨주세요.