


LoRAを用いたファインチューニング済みLLMからの推論がオープンベータ版に
本日、Workers AI上でLoRAによるファインチューニング済み推論を実行できるようになったことを発表します。この機能はオープンベータ版で、Mistral、Gemma、またはLlama 2で使用するための学習済みLoRAアダプタで利用可能ですが、いくつかの制限があります。BYO (Bring Your Own) LoRA機能の概要については、製品発表のブログ記事をご覧ください。
この記事では、ファインチューニングとLoRAとは何かを深く掘り下げ、当社のWorkers AIプラットフォームでの使い方を紹介し、プラットフォームでの実装方法についての技術的な詳細を掘り下げます。
ファインチューニングとは?
ファインチューニングとは、データを追加して学習を継続することで、AIモデルを修正することの総称です。ファインチューニングの目的は、生成がデータセットに類似する確率を高めることです。モデルをゼロからトレーニングすることは、かかる費用と時間を考えると多くのユースケースでは現実的ではありません。既存の学習済みモデルをファインチューニングすることで、その能力を活用しながら目的のタスクを達成することができます。低ランク適応(Low-Rank Adaptation:LoRA)は、LLMだけでなくさまざまなモデルアーキテクチャに適用できる特定のファインチューニング手法です。従来のファインチューニング手法では、学習済みモデルの重みを直接修正したり、追加したファインチューニングの重みと融合させたりするのが一般的です。一方、LoRAでは、ファインチューニングの重みと学習済みモデルは分離されたままであり、学習済みモデルは変更されません。その結果、コードを生成する、特定の性格を持つ、特定のスタイルで画像を生成するなど、特定のタスクでより正確なモデルをトレーニングすることができます。既存のLLMをファインチューニングして、特定のトピックに関する追加情報を理解することもできます。
元のベースモデルの重みを維持するというアプローチは、比較的少ない計算で新しいファインチューニングの重みを作成できることを意味します。既存の基盤モデル(Llama、Mistral、Gemmaなど)を活用し、ニーズに合わせて適応させることができるのです。
ファインチューニングの仕組みは?
ファインチューニングと、LoRAがなぜこれほど効果的なのかをよりよく理解するためには、一歩下がってAIモデルがどのように機能するのかを理解する必要があります。(LLMのような)AIモデルは、ディープラーニング技術によって訓練されたニューラルネットワークです。ニューラルネットワークでは、モデルのドメイン知識の数学的表現として機能するパラメータセットがあり、重みとバイアス、簡単に言えば数字で構成されています。これらのパラメータは通常、数値の大きな行列として表されます。パラメータが多ければ多いほど、モデルは大きくなります。ですから、llama-2-7bのようなモデルを見たとき、「7b」と読むと、そのモデルには70億個のパラメータがあることがわかります。
モデルのパラメータは、その挙動を定義します。モデルをゼロから訓練する場合、これらのパラメータは通常、乱数として始まります。データセットでモデルを訓練する際、これらのパラメータは、モデルがデータセットを反映して正しい挙動を示すまで、少しずつ調整されます。あるパラメータは他のパラメータよりも重要であるため、重みを適用し、その重みで重要性の高低を示します。重みは、訓練されるデータのパターンと関係を捉えるためのモデルの能力において重要な役割を果たします。
従来のファインチューニングでは、学習済みモデルのすべてのパラメータを新しい重みのセットで調整します。そのため、ファインチューニングされたモデルには、元のモデルと同じ量のパラメータを提供する必要があります。つまり、完全にファインチューニングされたモデルの学習と推論の実行には、多くの時間と計算が必要になるのです。その上、最先端モデルや既存モデルの新しいバージョンが定期的にリリースされるため、完全にファインチューニングされたモデルは、トレーニング、メンテナンス、保存にコストがかかることになります。
LoRAはファインチューニングの効率的な方法
非常に単純に言えば、LoRAでは学習済みモデルのパラメータを調整することを避け、代わりに少数の追加パラメータを適用することができます。これらの追加パラメータはベースモデルに一時的に適用され、モデルの挙動を効果的に制御します。従来のファインチューニング手法に比べ、LoRAアダプタと呼ばれるこれらの追加パラメータのトレーニングに必要な時間と計算量が大幅に削減されます。トレーニング後、LoRAアダプタを別個のモデルファイルとしてパッケージ化し、トレーニング元のベースモデルにプラグインできるようにします。完全にファインチューニングされたモデルは数十ギガバイトのサイズになることもありますが、これらのアダプタは通常、わずか数メガバイトです。これにより配信が非常に簡単になり、LoRAでファインチューニングされた推論を提供しても、推論にかかる合計時間にはミリ秒の遅延しか追加されません。
なぜLoRAがこれほど効果的なのかを理解したい方は、気を引き締めて、まず最初に、線形代数の簡単なレッスンを受けてください。大学時代から考えたことのない用語かもしれませんが、これから説明しますのでご心配なく。
数学のレッスン
従来のファインチューニングでは、モデルの重み(W0)を取り出し、それを微調整して新しい重みのセットを出力することができます。そのため、元のモデルの重みと新しい重みの差はΔWとなり、重みの変化を表します。したがって、調整されたモデルは、元のモデルの重みに重みの変化分W0 + ΔWを加えた新しい重みのセットを持つことになります。
これらのモデルの重みはすべて、実際には大きな数値の行列として表現されることを覚えておいてください。数学では、どの行列にもランク(r)と呼ばれる性質があり、これは行列内の線形独立な列や行の数を表します。行列のランクが低い場合、「重要」な列や行はわずかしかないため、実際には最も重要なパラメータを持つ2つの小さな行列に分解または分割することができます(代数学における因数分解のようなものだと考えてください)。このテクニックはランク分解と呼ばれ、最も重要なビットを保ちながら行列を大幅に縮小、単純化することができます。ファインチューニングの文脈では、ランクは元のモデルから変更されるパラメータの数を決定します。ランクが高いほどファインチューニングが強くなり、出力に対してよりきめ細かさが増します。
LoRAの原論文によると、研究者はモデルが低ランクの場合、重みの変化を表す行列も低ランクであることを発見しました。したがって、重みの変化ΔWを表す行列にランク分解を適用して、小さな2つの行列A、B(ΔW = BA)を作成することができます。これで、モデルの変化を2つの小さな低ランク行列で表すことができるのです。これが、このファインチューニングの方法が低ランク適応と呼ばれる理由です。
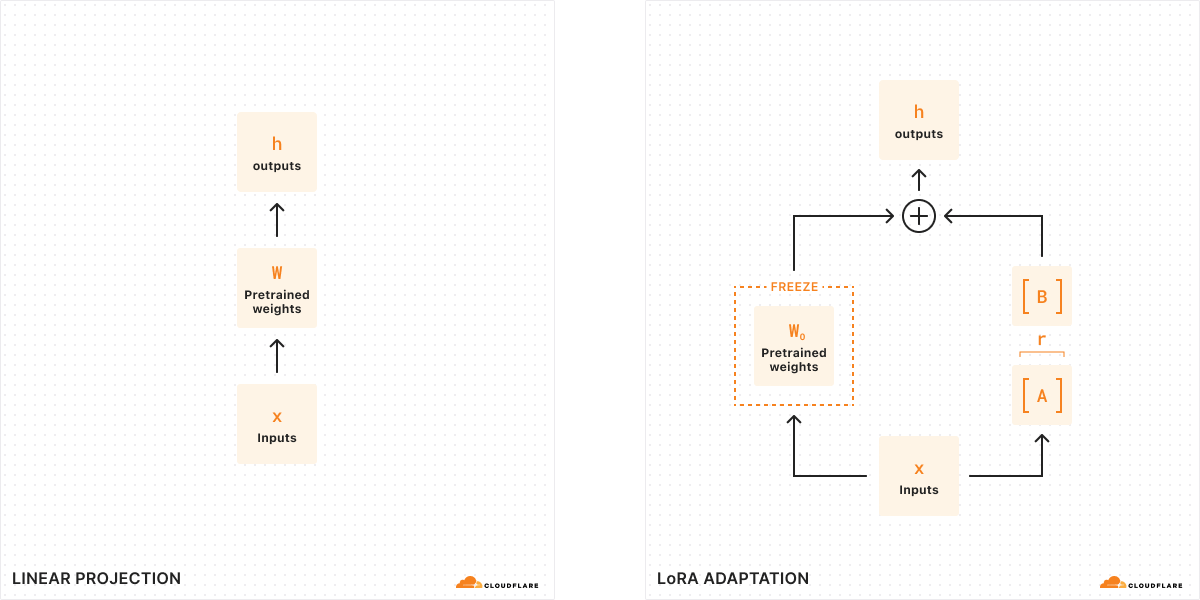
推論を実行するとき、モデルの挙動を変えるために必要なのは、より小さな行列A、Bだけです。A、Bのモデルの重みがLoRAアダプタを構成します(設定ファイルとともに)。実行時に、元のモデル(W0)とLoRAアダプタ(A、B)を組み合わせて、モデルの重みを足し合わせます。足し算と引き算は簡単な数学的操作です。つまり、W0からA、Bを足したり引いたりすることで、さまざまなLoRAアダプタをすばやく入れ替えることができます。元のモデルの重みを一時的に調整することで、モデルの挙動と出力を修正し、その結果、最小限の遅延の追加でファインチューニングされた推論を得ることができるのです。
LoRAの原論文によると、「LoRAは学習可能なパラメータ数を10,000分の1に、GPUのメモリ必要量を3分の1に削減できる」そうです。このため、LoRAは、完全にファインチューニングされたモデルよりも計算コストがはるかに低く、推論時間を増やすことなく、より小さくポータブルであるため、ファインチューニングの最も一般的な手法の1つとなっています。
Workers AIでLoRAをどのように使用するか
Workers AIは、そのサーバーレス推論の実行方法により、LoRAの実行に非常に適しています。当社のカタログにあるモデルは、常にGPUにプリロードされています。つまり、お客様のリクエストがコールドスタートになることがないよう、GPUをウォーム状態にしています。つまり、ベースモデルは常に利用可能で、必要に応じてLoRAアダプタを動的にロードしたり入れ替えたりすることができます。実際には、1つのベースモデルに複数のLoRAアダプタをプラグインできるので、一度に複数の異なるファインチューニング済みの推論リクエストに対応することができます。
LoRAでファインチューニングを行うと、カスタムモデルの重み(safetensors形式)とアダプタ構成ファイル(json形式)の2つのファイルが出力されます。これらの重みを自分で作成するには、Hugging Face PEFT(Parameter-Efficient Fine-Tuning)ライブラリとHugging Face AutoTrain LLMライブラリを組み合わせて、自分のデータでLoRAをトレーニングすることができます。また、Auto TrainやGoogle Colabのようなサービスでトレーニングタスクを実行することもできます。あるいは、Hugging Face上ではさまざまなユースケースをカバーするオープンソースのLoRAアダプタが利用可能です。
最終的には、私たちのプラットフォームでLoRAのトレーニングワークロードをサポートしたいと考えていますが、現在はトレーニング済みのLoRAアダプタをWorkers AIに持ち込んでいただく必要があります。そのため、この機能をBring Your Own (BYO) LoRAと呼んでいます。
最初のオープンベータ版リリースでは、Mistral、Llama、GemmaのモデルでLoRAを使用できるようにしています。LoRAを許可するこれらのモデルのバージョンには、モデル名の最後に「-lora」を追加することでアクセスできます。アダプタは、以下のサポートされているベースモデルのいずれかから、ファインチューニング済みのものである必要があります。
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
この機能をオープンベータ版で開始するにあたって、現在注意すべき制限がいくつかあります。量子化されたLoRAモデルはまだサポートされていません。LoRAアダプタは100MBより小さく、最大ランクは8までです。オープンベータ版の最初の期間中に、アカウントごとに最大30のLoRAをお試しいただけます。Workers AIでLoRAを開始するには、開発者ドキュメントをお読みください。
通常通り、Workers AIと新しいBYO LoRA機能は、モデルのライセンス条項に含まれるモデル固有の使用制限を含め当社の利用規約を念頭に置いて使用していただくものと想定しています。
マルチテナントのLoRAサービスをどのように構築したのか
複数のLoRAモデルに同時にサービスを提供することは、GPUのリソース使用率という点で課題となります。ベースモデルへの推論リクエストをバッチ処理することは可能ですが、独自のLoRAアダプタを提供する複雑さが加わったリクエストをバッチ処理することは、はるかに困難です。この問題に取り組むため、私たちはPunica CUDAカーネル設計とグローバルキャッシュ最適化の組み合わせを活用し、マルチテナントLoRAサービスのメモリ集中型ワークロードを処理しながら、低い推論遅延を提供します。
Punica CUDAカーネルは論文「Punica: Multi-Tenant LoRA Serving」で、同じベースモデルに適用される複数の大きく異なるLoRAモデルを提供する方法として紹介されました。これまでの推論手法と比較して、この手法はスループットと遅延を大幅に改善します。この最適化は、異なるLoRAアダプタにサービスを提供するリクエスト全体において、リクエストのバッチ処理を可能にすることで実現しています。
Punicaカーネルシステムの中核は、「セグメント化された集合行列およびベクトルの乗算」(Segmented Gather Matrix-Vector Multiplication:SGMV)と呼ばれる新しいCUDAカーネルです。SGMVは、GPUが異なるLoRAモデルに対応しながら、学習済みモデルのコピーを1つだけ保存することを可能にします。Punicaカーネル設計システムは、ユニークなLoRAモデルに対するリクエストのバッチを統合し、バッチ内の異なるリクエストの特徴量重み乗算を並列化することでパフォーマンスを向上させます。同じLoRAモデルに対するリクエストは、運用強度を高めるためにグループ化されます。最初に、GPUはベースモデルをロードし、GPUメモリの大部分をKVキャッシュ用に確保します。LoRAコンポーネント(AおよびB行列)は、着信リクエストによって要求されると、リモートストレージ(CloudflareのキャッシュまたはR2)からオンデマンドでロードされます。このオンデマンドローディングでは、遅延はミリ秒しか発生しないため、推論パフォーマンスへの影響を最小限に抑えながら、複数のLoRAアダプタをシームレスにフェッチし、サービスを提供することができます。頻繁にリクエストされるLoRAアダプタは、可能な限り最速の推論のためにキャッシュされます。
リクエストされたLoRAがローカルにキャッシュされると、推論に利用できる速度はPCIe帯域幅によってのみ制限されます。それにもかかわらず、各リクエストがそれ自身のLoRAを必要とする可能性があることを考えると、LoRAのダウンロードとメモリコピー操作が非同期で実行されることが重要になります。Punicaスケジューラはこの課題に正確に取り組み、現在GPUメモリで利用可能なLoRAの重みを必要とするリクエストのみをバッチ化し、そうでないリクエストは、必要な重みが利用可能になりリクエストが効率的にバッチに参加できるようになるまでキューに入れられます。
KVキャッシュを効果的に管理し、これらのリクエストをバッチ処理することで、マルチテナントLoRAの大規模なワークロードを処理することができます。さらに重要な最適化は、連続バッチの使用です。一般的なバッチ手法では、同じアダプタへのすべてのリクエストが停止状態に達してから解放される必要があります。連続バッチ処理では、バッチ内のリクエストを早期にリリースすることで、最長のリクエストを待つ必要がなくなります。
CloudflareのネットワークにデプロイされたLLMがグローバルに利用可能であることを考えると、LoRAアダプタモデルも同様に利用可能であることが重要です。近々、Cloudflareのエッジでキャッシュされるリモートモデルファイルを実装し、推論遅延をさらに削減する予定です。
Workers AIでのファインチューニングのためのロードマップ
LoRAアダプタのサポートを開始することは、私たちのプラットフォームのファインチューニングを切り開くための重要なステップです。現在利用可能なLLMのファインチューニングに加えて、より多くのモデルや、画像生成を含むさまざまなタイプのタスクのサポートが可能になる予定です。
Workers AIのビジョンは、開発者がAIワークロードを実行するための最高の場所になることです。最終的には、Workers AI上で直接、ファインチューニングのトレーニングジョブや、完全なファインチューニング済みモデルを実行できるようにしたいと考えています。これにより、特定のタスクに対してよりきめ細かく詳細なモデルを作成できるようになり、AIが組織でより活用できる多くのユースケースを生み出します。
AI Gatewayを使うことで、開発者がプロンプトと応答をログに記録し、本番データを使ってモデルをファインチューニングできるようになります。私たちのビジョンは、AI Gatewayからのログデータを使って(Cloudflare上の)モデルを再トレーニングし、ファインチューニング済みモデルを推論のためにWorkers AIに再展開できる、ワンクリックのファインチューニングサービスを持つことです。これにより、開発者はアプリケーションに合わせてAIモデルをパーソナライズでき、ユーザー単位まで粒度を細かく設定することができます。ファインチューニング済みモデルは、より小さく、より最適化され、ユーザーがAI推論の時間とコストを節約できるようになります。そして、このすべてが私たち独自の開発者プラットフォーム内で実現できるという魅力があります。
BYO LoRAのオープンベータ版をぜひお試しください!詳細は開発者ドキュメントをお読みいただき、Discordでご感想をお聞かせください。