


Time flies. The Heartbleed vulnerability was discovered just over five and a half years ago. Heartbleed became a household name not only because it was one of the first bugs with its own web page and logo, but because of what it revealed about the fragility of the Internet as a whole. With Heartbleed, one tiny bug in a cryptography library exposed the personal data of the users of almost every website online.
{kind=link}
Heartbleed is an example of an underappreciated class of bugs: remote memory disclosure vulnerabilities. High profile examples other than Heartbleed include Cloudbleed and most recently NetSpectre. These vulnerabilities allow attackers to extract secrets from servers by simply sending them specially-crafted packets. Cloudflare recently completed a multi-year project to make our platform more resilient against this category of bug.
For the last five years, the industry has been dealing with the consequences of the design that led to Heartbleed being so impactful. In this blog post we’ll dig into memory safety, and how we re-designed Cloudflare’s main product to protect private keys from the next Heartbleed.
Memory Disclosure
Perfect security is not possible for businesses with an online component. History has shown us that no matter how robust their security program, an unexpected exploit can leave a company exposed. One of the more famous recent incidents of this sort is Heartbleed, a vulnerability in a commonly used cryptography library called OpenSSL that exposed the inner details of millions of web servers to anyone with a connection to the Internet. Heartbleed made international news, caused millions of dollars of damage, and still hasn’t been fully resolved.
Typical web services only return data via well-defined public-facing interfaces called APIs. Clients don’t typically get to see what’s going on under the hood inside the server, that would be a huge privacy and security risk. Heartbleed broke that paradigm: it enabled anyone on the Internet to get access to take a peek at the operating memory used by web servers, revealing privileged data usually not exposed via the API. Heartbleed could be used to extract the result of previous data sent to the server, including passwords and credit cards. It could also reveal the inner workings and cryptographic secrets used inside the server, including TLS certificate private keys.
Heartbleed let attackers peek behind the curtain, but not too far. Sensitive data could be extracted, but not everything on the server was at risk. For example, Heartbleed did not enable attackers to steal the content of databases held on the server. You may ask: why was some data at risk but not others? The reason has to do with how modern operating systems are built.
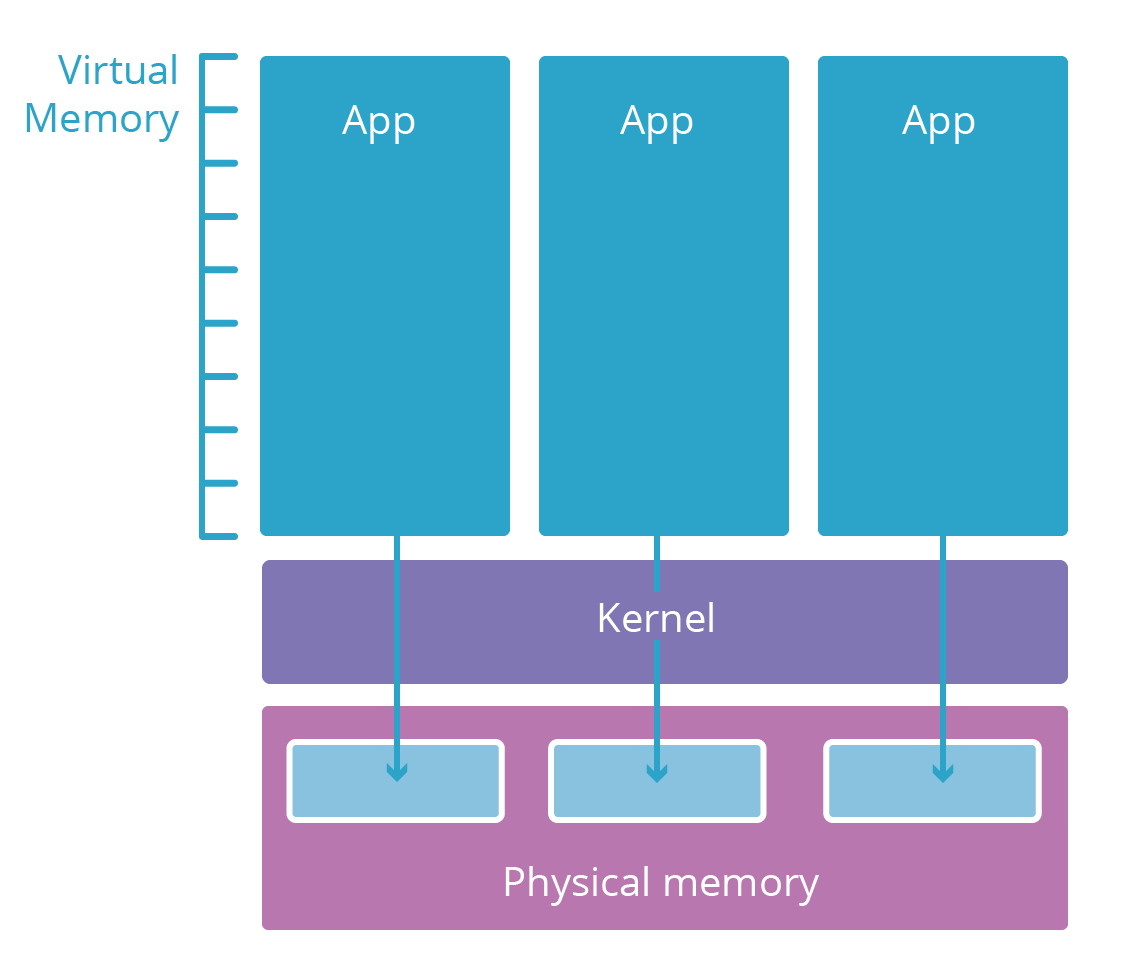
A simplified view of process isolation
Most modern operating systems are split into multiple layers. These layers are analogous to security clearance levels. So-called user-space applications (like your browser) typically live in a low-security layer called user space. They only have access to computing resources (memory, CPU, networking) if the lower, more credentialed layers let them.
User-space applications need resources to function. For example, they need memory to store their code and working memory to do computations. However, it would be risky to give an application direct access to the physical RAM of the computer they’re running on. Instead, the raw computing elements are restricted to a lower layer called the operating system kernel. The kernel only runs specially-designed applications designed to safely manage these resources and mediate access to them for user-space applications.
When a new user space application process is launched, the kernel gives it a virtual memory space. This virtual memory space acts like real memory to the application but is actually a safely guarded translation layer the kernel uses to protect the real memory. Each application’s virtual memory space is like a parallel universe dedicated to that application. This makes it impossible for one process to view or modify another’s, the other applications are simply not addressable.
Heartbleed, Cloudbleed and the process boundary
Heartbleed was a vulnerability in the OpenSSL library, which was part of many web server applications. These web servers run in user space, like any common applications. This vulnerability caused the web server to return up to 2 kilobytes of its memory in response to a specially-crafted inbound request.
Cloudbleed was also a memory disclosure bug, albeit one specific to Cloudflare, that got its name because it was so similar to Heartbleed. With Cloudbleed, the vulnerability was not in OpenSSL, but instead in a secondary web server application used for HTML parsing. When this code parsed a certain sequence of HTML, it ended up inserting some process memory into the web page it was serving.
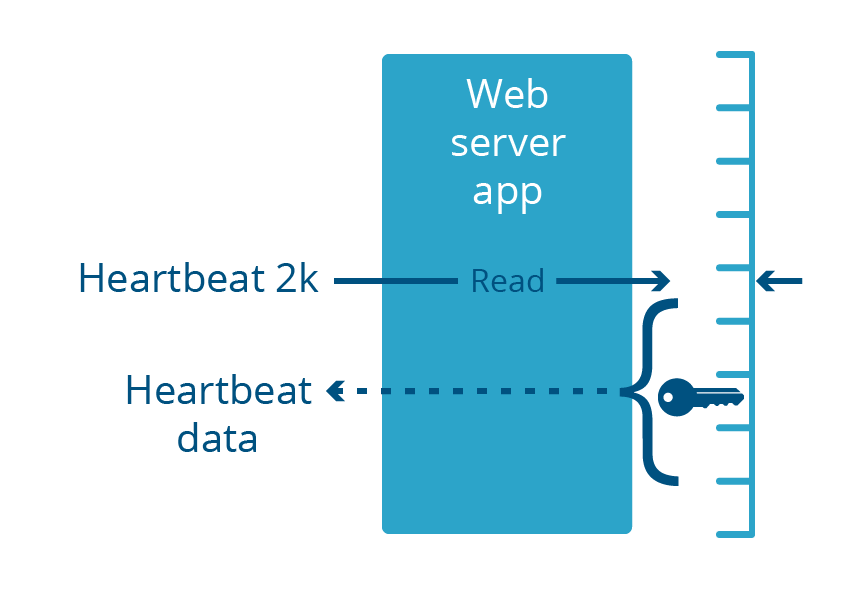
It’s important to note that both of these bugs occurred in applications running in user space, not kernel space. This means that the memory exposed by the bug was necessarily part of the virtual memory of the application. Even if the bug were to expose megabytes of data, it would only expose data specific to that application, not other applications on the system.
In order for a web server to serve traffic over the encrypted HTTPS protocol, it needs access to the certificate’s private key, which is typically kept in the application’s memory. These keys were exposed to the Internet by Heartbleed. The Cloudbleed vulnerability affected a different process, the HTML parser, which doesn’t do HTTPS and therefore doesn’t keep the private key in memory. This meant that HTTPS keys were safe, even if other data in the HTML parser’s memory space wasn’t.
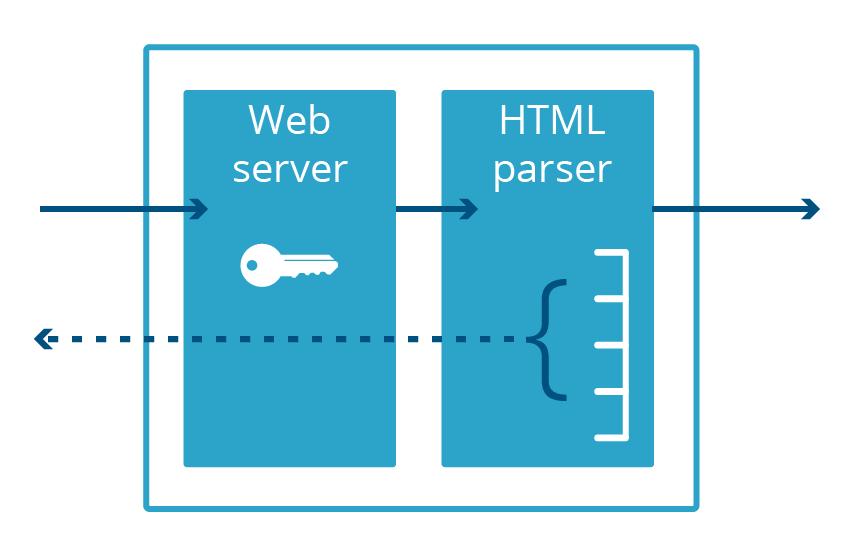
The fact that the HTML parser and the web server were different applications saved us from having to revoke and re-issue our customers’ TLS certificates. However, if another memory disclosure vulnerability is discovered in the web server, these keys are again at risk.
Moving keys out of Internet-facing processes
Not all web servers keep private keys in memory. In some deployments, private keys are held in a separate machine called a Hardware Security Module (HSM). HSMs are built to withstand physical intrusion and tampering and are often built to comply with stringent compliance requirements. They can often be bulky and expensive. Web servers designed to take advantage of keys in an HSM connect to them over a physical cable and communicate with a specialized protocol called PKCS#11. This allows the web server to serve encrypted content while being physically separated from the private key.
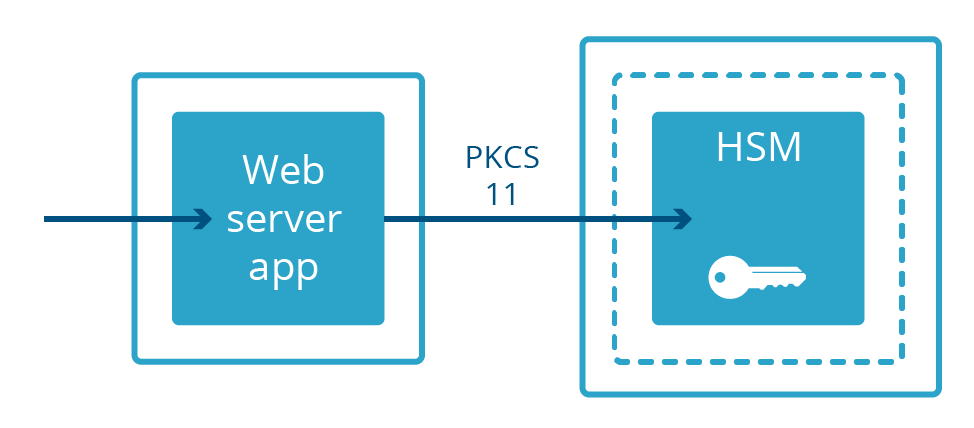
At Cloudflare, we built our own way to separate a web server from a private key: Keyless SSL. Rather than keeping the keys in a separate physical machine connected to the server with a cable, the keys are kept in a key server operated by the customer in their own infrastructure (this can also be backed by an HSM).
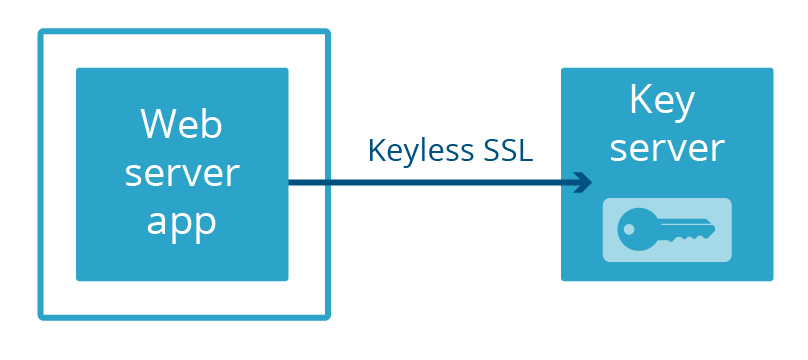
More recently, we launched Geo Key Manager, a service that allows users to store private keys in only select Cloudflare locations. Connections to locations that do not have access to the private key use Keyless SSL with a key server hosted in a datacenter that does have access.
In both Keyless SSL and Geo Key Manager, private keys are not only not part of the web server’s memory space, they’re often not even in the same country! This extreme degree of separation is not necessary to protect against the next Heartbleed. All that is needed is for the web server and the key server to not be part of the same application. So that’s what we did. We call this Keyless Everywhere.
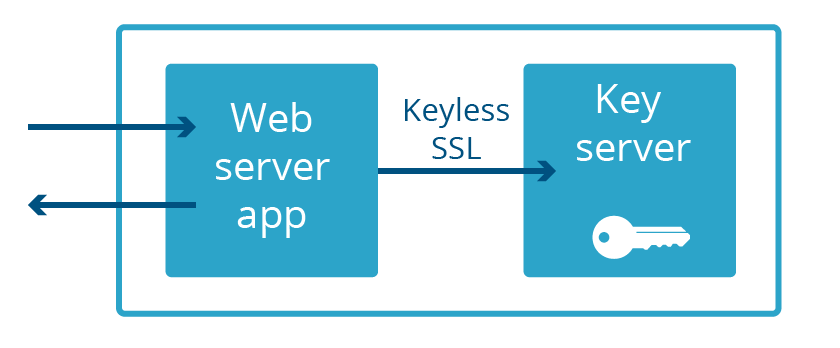
Keyless SSL is coming from inside the house
Repurposing Keyless SSL for Cloudflare-held private keys was easy to conceptualize, but the path from ideation to live in production wasn't so straightforward. The core functionality of Keyless SSL comes from the open source gokeyless which customers run on their infrastructure, but internally we use it as a library and have replaced the main package with an implementation suited to our requirements (we've creatively dubbed it gokeyless-internal).
As with all major architecture changes, it’s prudent to start with testing out the model with something new and low risk. In our case, the test bed was our experimental TLS 1.3 implementation. In order to quickly iterate through draft versions of the TLS specification and push releases without affecting the majority of Cloudflare customers, we re-wrote our custom nginx web server in Go and deployed it in parallel to our existing infrastructure. This server was designed to never hold private keys from the start and only leverage gokeyless-internal. At this time there was only a small amount of TLS 1.3 traffic and it was all coming from the beta versions of browsers, which allowed us to work through the initial kinks of gokeyless-internal without exposing the majority of visitors to security risks or outages due to gokeyless-internal.
The first step towards making TLS 1.3 fully keyless was identifying and implementing the new functionality we needed to add to gokeyless-internal. Keyless SSL was designed to run on customer infrastructure, with the expectation of supporting only a handful of private keys. But our edge must simultaneously support millions of private keys, so we implemented the same lazy loading logic we use in our web server, nginx. Furthermore, a typical customer deployment would put key servers behind a network load balancer, so they could be taken out of service for upgrades or other maintenance. Contrast this with our edge, where it’s important to maximize our resources by serving traffic during software upgrades. This problem is solved by the excellent tableflip package we use elsewhere at Cloudflare.
The next project to go Keyless was Spectrum, which launched with default support for gokeyless-internal. With these small victories in hand, we had the confidence necessary to attempt the big challenge, which was porting our existing nginx infrastructure to a fully keyless model. After implementing the new functionality, and being satisfied with our integration tests, all that’s left is to turn this on in production and call it a day, right? Anyone with experience with large distributed systems knows how far "working in dev" is from "done," and this story is no different. Thankfully we were anticipating problems, and built a fallback into nginx to complete the handshake itself if any problems were encountered with the gokeyless-internal path. This allowed us to expose gokeyless-internal to production traffic without risking downtime in the event that our reimplementation of the nginx logic was not 100% bug-free.
When rolling back the code doesn’t roll back the problem
Our deployment plan was to enable Keyless Everywhere, find the most common causes of fallbacks, and then fix them. We could then repeat this process until all sources of fallbacks had been eliminated, after which we could remove access to private keys (and therefore the fallback) from nginx. One of the early causes of fallbacks was gokeyless-internal returning ErrKeyNotFound, indicating that it couldn’t find the requested private key in storage. This should not have been possible, since nginx only makes a request to gokeyless-internal after first finding the certificate and key pair in storage, and we always write the private key and certificate together. It turned out that in addition to returning the error for the intended case of the key truly not found, we were also returning it when transient errors like timeouts were encountered. To resolve this, we updated those transient error conditions to return ErrInternal, and deployed to our canary datacenters. Strangely, we found that a handful of instances in a single datacenter started encountering high rates of fallbacks, and the logs from nginx indicated it was due to a timeout between nginx and gokeyless-internal. The timeouts didn’t occur right away, but once a system started logging some timeouts it never stopped. Even after we rolled back the release, the fallbacks continued with the old version of the software! Furthermore, while nginx was complaining about timeouts, gokeyless-internal seemed perfectly healthy and was reporting reasonable performance metrics (sub-millisecond median request latency).
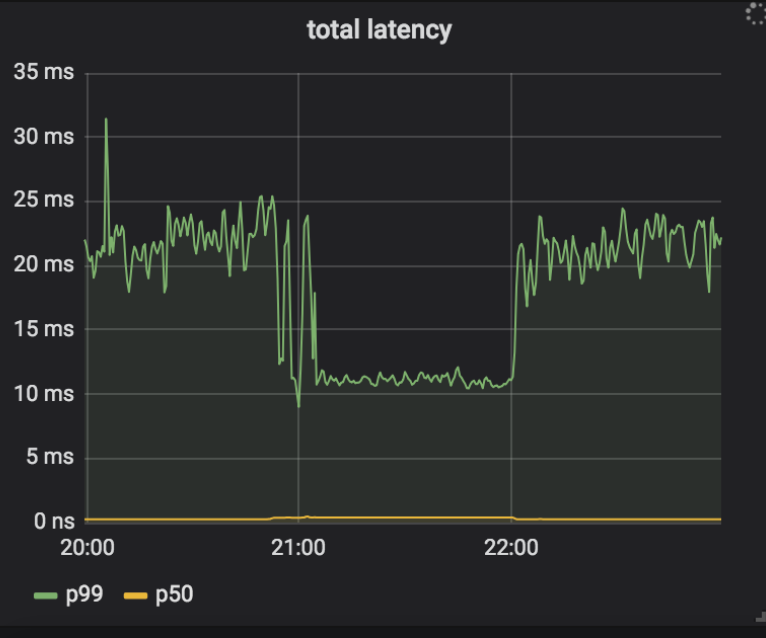
To debug the issue, we added detailed logging to both nginx and gokeyless, and followed the chain of events backwards once timeouts were encountered.
➜ ~ grep 'timed out' nginx.log | grep Keyless | head -5
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015157 Keyless SSL request/response timed out while reading Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015231 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015271 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015280 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:50.000 29m41 2018/07/25 05:30:50 [error] 4525#0: *1015289 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
You can see the first request to log a timeout had id 1015157. Also interesting that the first log line was "timed out while reading," but all the others are "timed out while waiting," and this latter message is the one that continues forever. Here is the matching request in the gokeyless log:
➜ ~ grep 'id=1015157 ' gokeyless.log | head -1
2018-07-25T05:30:39.000 29m41 2018/07/25 05:30:39 [DEBUG] connection 127.0.0.1:30520: worker=ecdsa-29 opcode=OpECDSASignSHA256 id=1015157 sni=announce.php?info_hash=%a8%9e%9dc%cc%3b1%c8%23%e4%93%21r%0f%92mc%0c%15%89&peer_id=-ut353s-%ce%ad%5e%b1%99%06%24e%d5d%9a%08&port=42596&uploaded=65536&downloaded=0&left=0&corrupt=0&key=04a184b7&event=started&numwant=200&compact=1&no_peer_id=1 ip=104.20.33.147
Aha! That SNI value is clearly invalid (SNIs are like Host headers, i.e. they are domains, not URL paths), and it’s also quite long. Our storage system indexes certificates based on two indices: which SNI they correspond to, and which IP addresses they correspond to (for older clients that don’t support SNI). Our storage interface uses the memcached protocol, and the client library that gokeyless-internal uses rejects requests for keys longer than 250 characters (memcached’s maximum key length), whereas the nginx logic is to simply ignore the invalid SNI and treat the request as if only had an IP. The change in our new release had shifted this condition from ErrKeyNotFound to ErrInternal, which triggered cascading problems in nginx. The “timeouts” it encountered were actually a result of throwing away all in-flight requests multiplexed on a connection which happened to return ErrInternalfor a single request. These requests were retried, but once this condition triggered, nginx became overloaded by the number of retried requests plus the continuous stream of new requests coming in with bad SNI, and was unable to recover. This explains why rolling back gokeyless-internal didn’t fix the problem.
This discovery finally brought our attention to nginx, which thus far had escaped blame since it had been working reliably with customer key servers for years. However, communicating over localhost to a multitenant key server is fundamentally different than reaching out over the public Internet to communicate with a customer’s key server, and we had to make the following changes:
- Instead of a long connection timeout and a relatively short response timeout for customer key servers, extremely short connection timeouts and longer request timeouts are appropriate for a localhost key server.
- Similarly, it’s reasonable to retry (with backoff) if we timeout waiting on a customer key server response, since we can’t trust the network. But over localhost, a timeout would only occur if gokeyless-internal were overloaded and the request were still queued for processing. In this case a retry would only lead to more total work being requested of gokeyless-internal, making the situation worse.
- Most significantly, nginx must not throw away all requests multiplexed on a connection if any single one of them encounters an error, since a single connection no longer represents a single customer.
Implementations matter
CPU at the edge is one of our most precious assets, and it’s closely guarded by our performance team (aka CPU police). Soon after turning on Keyless Everywhere in one of our canary datacenters, they noticed gokeyless using ~50% of a core per instance. We were shifting the sign operations from nginx to gokeyless, so of course it would be using more CPU now. But nginx should have seen a commensurate reduction in CPU usage, right?
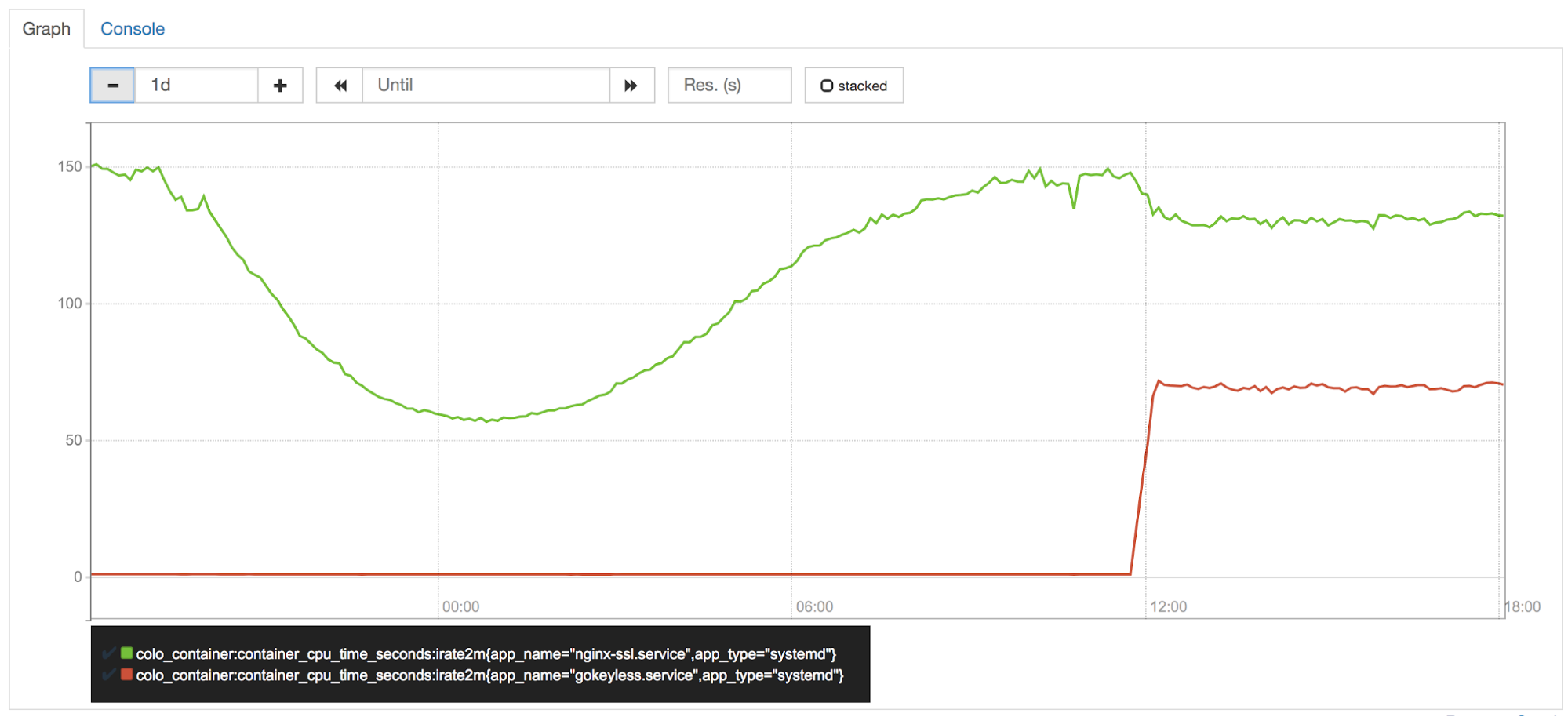
Wrong. Elliptic curve operations are very fast in Go, but it’s known that RSA operations are much slower than their BoringSSL counterparts.
Although Go 1.11 includes optimizations for RSA math operations, we needed more speed. Well-tuned assembly code is required to match the performance of BoringSSL, so Armando Faz from our Crypto team helped claw back some of the lost CPU by reimplementing parts of the math/big package with platform-dependent assembly in an internal fork of Go. The recent assembly policy of Go prefers the use of Go portable code instead of assembly, so these optimizations were not upstreamed. There is still room for more optimizations, and for that reason we’re still evaluating moving to cgo + BoringSSL for sign operations, despite cgo’s many downsides.
Changing our tooling
Process isolation is a powerful tool for protecting secrets in memory. Our move to Keyless Everywhere demonstrates that this is not a simple tool to leverage. Re-architecting an existing system such as nginx to use process isolation to protect secrets was time-consuming and difficult. Another approach to memory safety is to use a memory-safe language such as Rust.
Rust was originally developed by Mozilla but is starting to be used much more widely. The main advantage that Rust has over C/C++ is that it has memory safety features without a garbage collector.
Re-writing an existing application in a new language such as Rust is a daunting task. That said, many new Cloudflare features, from the powerful Firewall Rules feature to our 1.1.1.1 with WARP app, have been written in Rust to take advantage of its powerful memory-safety properties. We’re really happy with Rust so far and plan on using it even more in the future.
Conclusion
The harrowing aftermath of Heartbleed taught the industry a lesson that should have been obvious in retrospect: keeping important secrets in applications that can be accessed remotely via the Internet is a risky security practice. In the following years, with a lot of work, we leveraged process separation and Keyless SSL to ensure that the next Heartbleed wouldn’t put customer keys at risk.
However, this is not the end of the road. Recently memory disclosure vulnerabilities such as NetSpectre have been discovered which are able to bypass application process boundaries, so we continue to actively explore new ways to keep keys secure.
