


Le temps passe. La vulnérabilité Heartbleed a été découverte il y a un peu plus de cinq ans et demi. Heartbleed a acquis une notoriété mondiale non seulement parce qu'il a été l'un des premiers bugs à posséder sa propre page Web et son propre logo, mais aussi parce qu'il a révélé la fragilité d'Internet dans son ensemble. Avec Heartbleed, un petit bug dans une bibliothèque de chiffrement a exposé les données personnelles des utilisateurs de presque tous les sites Web en ligne.
{kind=link}
Heartbleed fait partie d'une catégorie de bugs sous-estimée : les vulnérabilités de divulgation de mémoire à distance. Parmi les exemples très médiatisés autres que Heartbleed, citons Cloudbleed et, plus récemment, NetSpectre. Ces vulnérabilités permettent aux pirates de récupérer les informations secrètes des serveurs en leur envoyant simplement des paquets spécialement conçus à cet effet. Cloudflare a récemment achevé un projet mené depuis plusieurs années visant à rendre notre plate-forme plus résistante à cette catégorie de bugs.
Depuis cinq ans, le secteur est aux prises avec les conséquences du modèle de conception qui a permis à Heartbleed d'avoir un tel impact. Dans ce billet de blog, nous allons parler de la sécurité de la mémoire et de la façon dont nous avons reconceptualisé le produit principal de Cloudflare pour protéger les clés privées contre le prochain Heartbleed.
Divulgation de mémoire
On ne peut garantir un niveau de sécurité sans faille pour les entreprises présentes sur Internet. L'histoire nous a montré que, quelle que soit la puissance de leur système de sécurité, il suffit d'un exploit imprévu pour que celle-ci soit compromise. L'un des incidents récents de ce type les plus célèbres est Heartbleed, une vulnérabilité dans une bibliothèque de chiffrement couramment utilisée appelée OpenSSL qui a exposé les informations internes de millions de serveurs Web à quiconque disposait d'une connexion Internet. Heartbleed a fait les gros titres des journaux du monde entier, a causé des millions de dollars de dégâts et n'a toujours pas été entièrement résolu.
Les services Web classiques ne renvoient des données que via des interfaces publiques bien définies appelées API. Les clients ne voient généralement pas ce qui se passe en coulisse à l'intérieur du serveur, ce qui représenterait un énorme risque pour la confidentialité et la sécurité. Heartbleed a bouleversé ce modèle : il a permis à quiconque sur Internet d'accéder à la mémoire centrale utilisée par les serveurs Web, en révélant des données privilégiées habituellement non exposées via l'API. Heartbleed pouvait être utilisé pour extraire le résultat de données envoyées précédemment au serveur, y compris des mots de passe et des numéros de cartes de crédit. Il a pu également révéler le fonctionnement interne et les secrets cryptographiques utilisés à l'intérieur du serveur, dont des clés privées de certificats TLS.
Heartbleed a permis aux pirates de voir ce qui se cachait derrière le rideau sans toutefois aller trop loin. Des données sensibles ont pu être extraites, mais tout ce qui se trouvait sur le serveur n'a pas été menacé. Par exemple, Heartbleed n’a pas permis aux pirates de voler le contenu des bases de données hébergées sur le serveur. Vous vous demandez peut-être pourquoi certaines données ont été menacées, alors que d'autres ne l'ont pas été. La raison est à rechercher dans la manière dont sont conçus les systèmes d'exploitation modernes.
Une vision simplifiée de l'isolement des processus
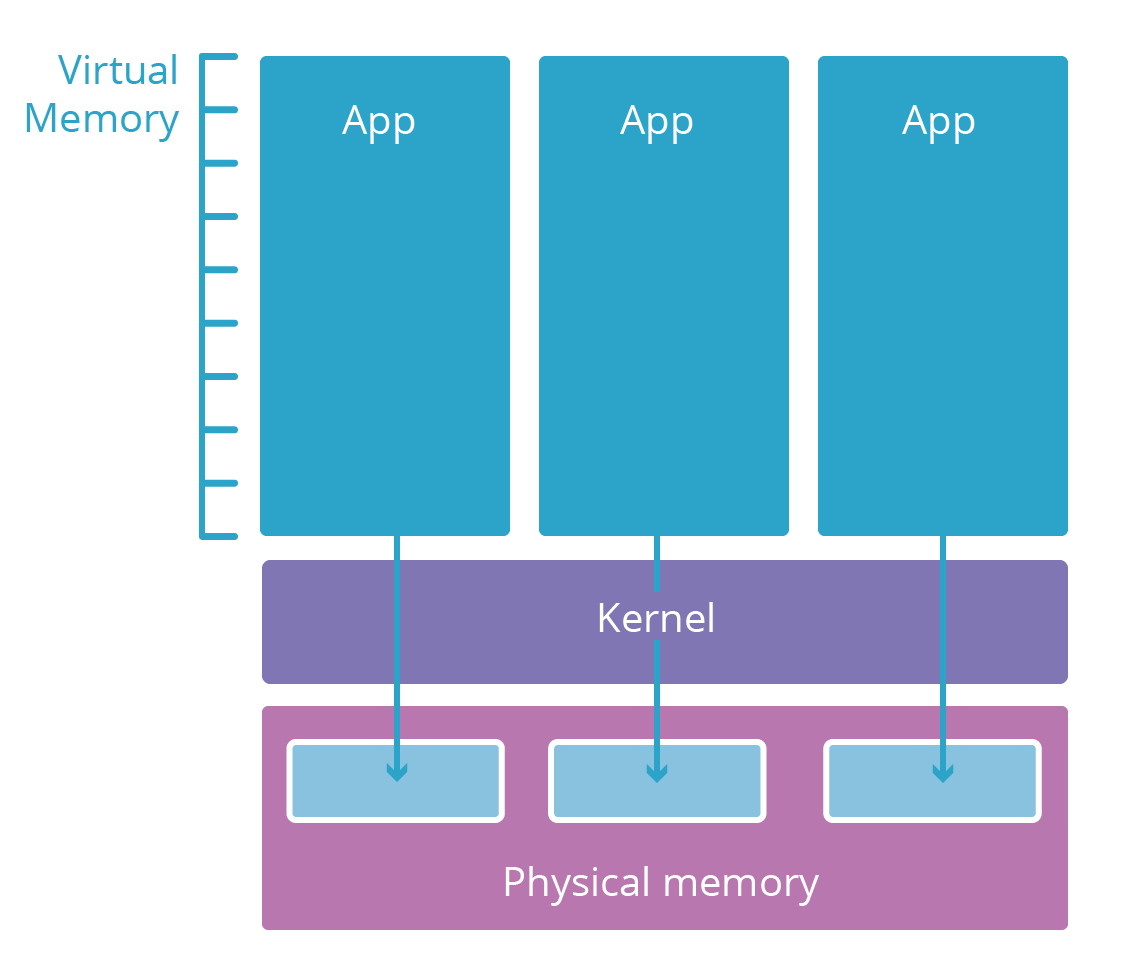
La plupart des systèmes d'exploitation modernes sont divisés en plusieurs couches. Ces couches sont semblables aux niveaux d'habilitation de sécurité. Les applications de l’espace utilisateur (comme votre navigateur) se trouvent généralement dans une couche peu sécurisée appelée espace utilisateur. Elles n'ont accès aux ressources informatiques (mémoire, CPU, réseau) que si les couches inférieures, présentant à un niveau d'identification plus élevé, les y autorisent.
Les applications de l’espace utilisateur ont besoin de ressources pour fonctionner. Par exemple, elles ont besoin de mémoire pour stocker leur code et leur mémoire de travail pour effectuer des calculs. Cependant, il serait risqué de donner à une application un accès direct à la RAM physique de l'ordinateur sur lequel elle est exécutée. Au lieu de cela, les éléments de calcul bruts sont limités à une couche inférieure appelée noyau du système d'exploitation. Le noyau n'exécute que des applications spécialement conçues pour gérer ces ressources de manière sécurisée et faciliter leur accès aux applications de l’espace utilisateur.
Lorsqu'un nouveau processus d'application utilisateur est lancé, le noyau lui donne un espace de mémoire virtuel. Cet espace de mémoire virtuelle fonctionne comme de la mémoire réelle pour l'application mais est en fait une couche de translation sécurisée que le noyau utilise pour protéger la mémoire réelle. L'espace mémoire virtuel de chaque application est en quelque sorte un univers parallèle dédié à cette application. Un seul processus ne peut donc pas afficher ou modifier celle d'un autre processus, les applications ne sont tout simplement pas compatibles entre elles.
Heartbleed, Cloudbleed et la limite des processus
Heartbleed était une vulnérabilité de la bibliothèque OpenSSL, qui faisait partie de nombreuses applications de serveur Web. Ces serveurs Web s'exécutent dans l'espace utilisateur, comme toutes les applications courantes. Cette vulnérabilité a amené le serveur Web à renvoyer jusqu'à 2 kilo-octets de sa mémoire en réponse à une requête entrante spécialement élaborée à cet effet.
Cloudbleed était également un bug de divulgation de mémoire, mais spécifique à Cloudflare, qui doit son nom à sa ressemblance avec Heartbleed. Dans le cas de Cloudbleed, la vulnérabilité ne se situait pas dans OpenSSL, mais plutôt dans une application de serveur Web secondaire utilisée pour l'analyse HTML. Après avoir analysé une certaine séquence HTML, ce code insérait de la mémoire de processus dans la page Web qu'il desservait.
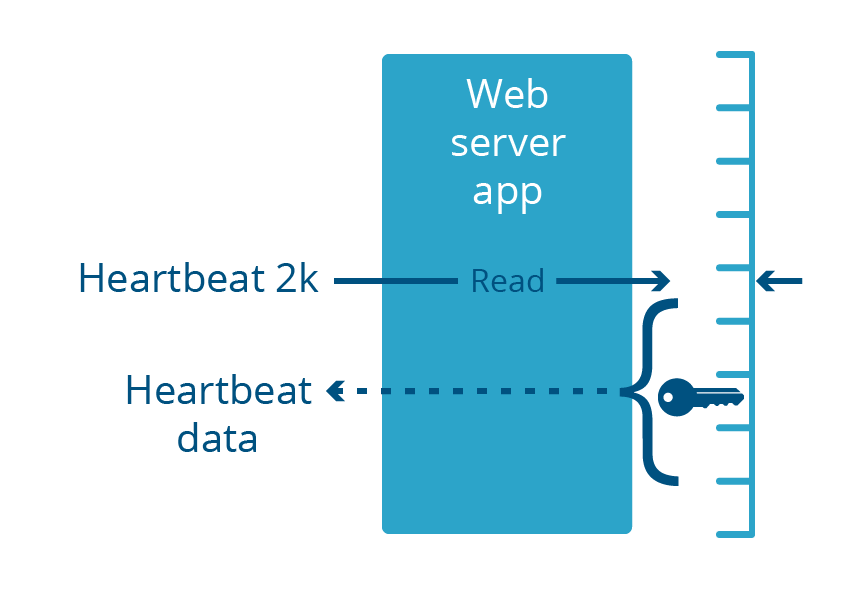
Il convient de noter que ces deux bugs se sont produits dans des applications fonctionnant dans l'espace utilisateur, et non dans l'espace noyau. Cela signifie que la mémoire exposée par le bug faisait nécessairement partie de la mémoire virtuelle de l'application. Même si le bug dévoilait plusieurs mégaoctets de données, il n'exposait que les données propres à cette application, et non celles des autres applications du système.
Pour qu'un serveur Web puisse acheminer le trafic via le protocole HTTPS chiffré, il doit avoir accès à la clé privée du certificat, qui est généralement conservée dans la mémoire de l'application. Ces clés ont été dévoilées sur Internet par Heartbleed. La vulnérabilité Cloudbleed a affecté un processus différent, l'analyseur HTML, qui ne gère pas HTTPS et ne garde donc pas la clé privée en mémoire. Cela signifiait que les clés HTTPS étaient sûres, même si d'autres données dans l'espace de mémoire de l'analyseur HTML ne l'étaient pas.
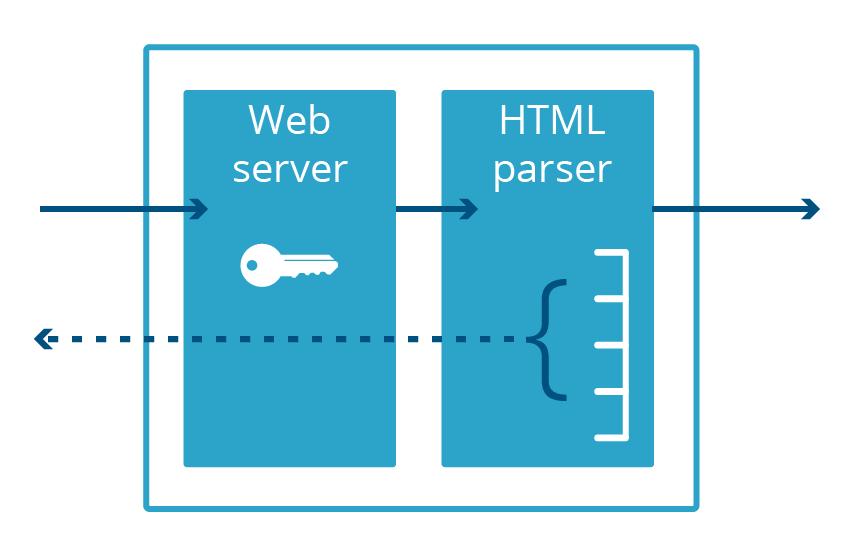
Le fait que l'analyseur HTML et le serveur Web étaient des applications différentes nous a évité d'avoir à révoquer et à réémettre les certificats TLS de nos clients. Cependant, si on découvre dans le serveur Web une autre vulnérabilité susceptible d’entraîner une divulgation de la mémoire, ces clés seront de nouveau en danger.
Déplacer les clés en dehors des processus accessibles sur Internet
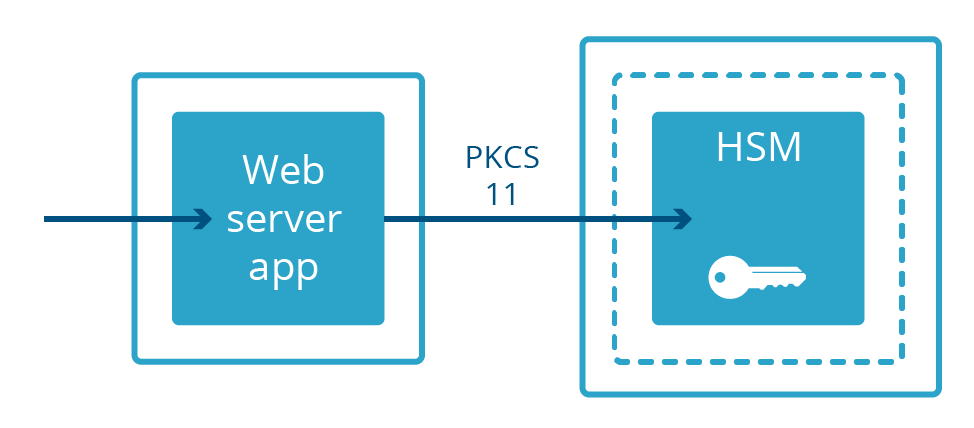
Tous les serveurs Web ne gardent pas les clés privées en mémoire. Dans certains systèmes, les clés privées sont conservées dans une machine distincte appelée Hardware Security Module (HSM). Les HSM sont conçus pour résister aux intrusions physiques et aux falsifications et satisfont souvent à des exigences de conformité strictes. Elles sont souvent lourdes et coûteuses. Les serveurs Web conçus pour bénéficier des clés conservés sur les HSM sont reliés à ces derniers par un câble physique et communiquent avec un protocole spécialisé appelé PKCS 11. Le serveur Web peut ainsi diffuser du contenu chiffré tout en étant matériellement séparé de la clé privée.
Chez Cloudflare, nous avons développé notre propre méthode pour séparer un serveur Web d'une clé privée : Keyless SSL. Plutôt que de conserver les clés dans une machine physique séparée reliée au serveur par un câble, les clés sont conservées dans un serveur de clés géré par le client dans sa propre infrastructure (qui peut également être appuyé par un HSM).
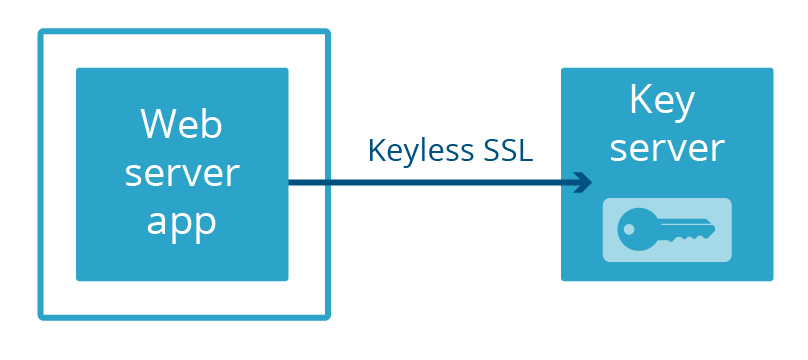
Plus récemment, nous avons lancé Geo Key Manager, un service qui permet aux utilisateurs de stocker des clés privées uniquement dans certains emplacements Cloudflare. Les connexions vers des emplacements qui n’ont pas accès à la clé privée utilisent Keyless SSL avec un serveur de clés hébergé dans un centre de données qui a accès.
Dans Keyless SSL et Geo Key Manager, non seulement les clés privées ne font pas partie de l'espace de mémoire du serveur Web, mais bien souvent elles ne sont même pas dans le même pays ! Ce degré de séparation extrême n'est pas nécessaire pour se prémunir contre le prochain Heartbleed. Il suffit que le serveur Web et le serveur de clés ne fassent pas partie de la même application. C'est donc ce que nous avons fait. C’est ce que nous appelons Keyless Everywhere.
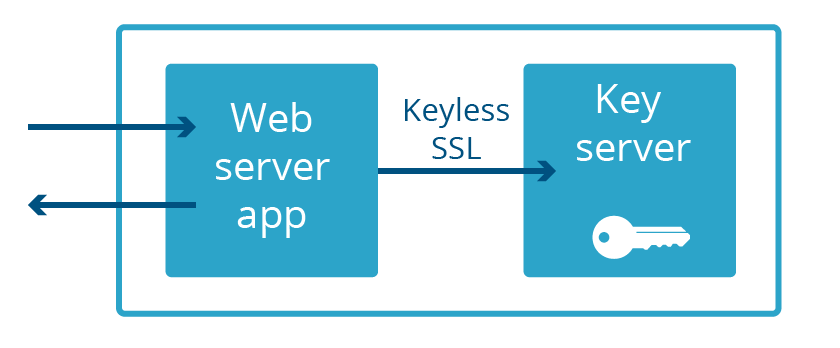
Keyless SSL vient de chez nous
Il fut aisé de redéfinir l'utilisation de KeyLess SSL pour les clés privées détenues par Cloudflare, mais le chemin entre l'idée et la mise en œuvre ne fut pas aussi simple. La principale fonctionnalité de Keyless SSL vient de l'open source gokeyless que les clients exécutent sur leur infrastructure, mais en interne nous l'utilisons comme une bibliothèque et avons remplacé le module principal par une version adaptée à nos besoins (que nous avons appelée gokeyless-internal).
Comme pour tout changement d'architecture important, il est prudent de commencer par tester le modèle avec quelque chose de nouveau et qui présente peu de risques. Dans notre cas, nous avons réalisé le test avec notre application expérimentale TLS 1.3. Afin de pouvoir rapidement mettre en place des versions préliminaires de la spécification TLS et diffuser des versions qui n'affectent la majorité des clients Cloudflare, nous avons réécrit notre serveur Web nginx personnalisé en Go et l'avons déployé parallèlement à notre infrastructure existante. Ce serveur a été conçu pour ne jamais détenir de clés privées dès le départ et pour n'exploiter que gokeyless-internal. À ce moment-là, le trafic TLS 1.3 était très faible et tout provenait des versions bêta des navigateurs, ce qui nous a permis de travailler sur les premières failles de gokeyless-internal sans exposer la majorité des visiteurs à des vulnérabilités ou à des pannes dues à gokeyless-internal.
La première étape pour que TLS 1.3 fonctionne complètement sans clés fut d’identifier et mettre en œuvre les nouvelles fonctionnalités que nous devions ajouter à gokeyless-internal. Keyless SSL a été conçu pour fonctionner sur l'infrastructure client, pour ne gérer qu'un petit nombre de clés privées. Mais notre périphérie doit gérer des millions de clés privées simultanément, c'est pourquoi nous avons donc appliqué la même logique de chargement différé (lazy-loading) que celle que nous utilisons avec notre serveur Web, nginx. De plus, un déploiement client type placerait les serveurs de clés derrière un équilibreur de charge réseau afin de pouvoir être mis hors service lors de mises à niveau ou d'autres opérations de maintenance. Comparez cela avec notre périphérie, où il est important de maximiser nos ressources en acheminant le trafic pendant les mises à jour logicielles. Ce problème est résolu par l'excellent package tableflip que nous utilisons ailleurs au niveau de Cloudflare.
Le projet qui a suivi fut Spectrum, qui fut lancé avec la prise en charge par défaut de gokeyless-internal. Ces petites victoires en poche, nous étions suffisamment confiants pour relever le grand défi qui consistait à faire passer notre infrastructure nginx existante à un modèle entièrement sans clés. Après avoir implémenté la nouvelle fonctionnalité et obtenu des tests d'intégration satisfaisants, il ne restait plus qu'à mettre tout cela en production et le tour était joué, n’est-ce pas ? Quiconque connaît bien les grands systèmes distribués sait qu’il y a souvent loin de la coupe aux lèvres : le « travail de développement » est toujours loin du « travail accompli », et ce fut tout aussi vrai dans notre cas. Heureusement, nous avions anticipé les problèmes, et nous avons incorporé une solution de repli à nginx pour compléter le handshake en cas de problèmes avec le chemin interne gokeyless. Cela nous a permis de faire passer gokeyless-internal en trafic de production sans risquer des temps d'arrêt dans le cas où notre réimplémentation de la logique nginx n’était pas à 100% sans bug.
Lorsque le retour au code précédent ne résout pas le problème
Notre plan de déploiement consistait à permettre à Keyless Everywhere de trouver les causes les plus courantes des fallbacks, puis de les corriger. Nous pourrions alors répéter ce processus jusqu'à ce que tous les fallbacks aient été éliminés, après quoi nous pourrions retirer l'accès aux clés privées (et donc les failles) de nginx. L'une des premières sources de fallbacks fut gokeyless-internal qui renvoyait le message d’erreur ErrKeyNotFound, indiquant qu'il ne parvenait pas à trouver la clé privée demandée en stockage. Cela n'aurait pas dû être possible, puisque nginx n'envoie une requête à gokeyless-internal qu'après avoir trouvé le certificat et la paire de clés en stockage, et que nous écrivons toujours la clé privée et le certificat ensemble. Il s'est avéré qu'en plus de renvoyer l'erreur dans le cas prévu de la clé vraiment introuvable, nous la renvoyions également en cas d'erreurs transitoires telles que des dépassements de délais. Pour résoudre ce problème, nous avons mis à jour ces conditions d'erreur transitoire pour renvoyer ErrInternal, et les avons déployées dans nos datacenters canary. Curieusement, nous avons constaté quelques situations dans un seul centre de données où les taux de fallbacks ont commencé à grimper, et les journaux de nginx indiquaient comme cause un dépassement de délai (timeout) entre nginx et gokeyless-internal. Ces dépassements de délai ne se sont pas produits tout de suite, mais une fois qu'un système a commencé à consigner des dépassements de délai, il ne s'est plus arrêté. Même après avoir annulé la version précédente, les fallbacks ont continué à se produire avec l'ancienne version du logiciel ! De plus, alors que nginx signalait des dépassements de délai, gokeyless-internal semblait en parfaite santé et indiquait des métriques de performance raisonnables (latence médiane des requêtes inférieure à une milliseconde).
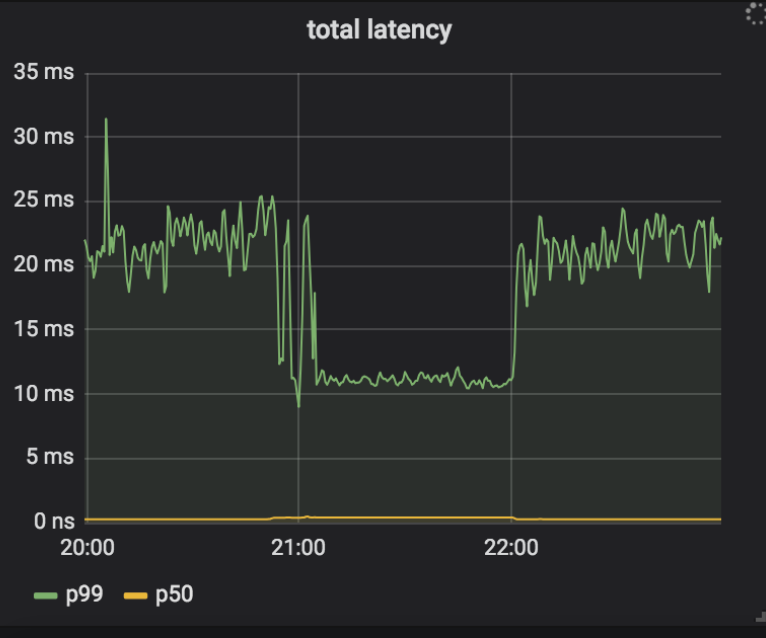
Afin de corriger le problème, nous avons intégré une journalisation détaillée à nginx et gokeyless, et remonté la chaîne des événements à partir des dépassements de délai rencontrés.
➜ ~ grep 'timed out' nginx.log | grep Keyless | head -5
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015157 Keyless SSL request/response timed out while reading Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015231 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015271 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015280 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:50.000 29m41 2018/07/25 05:30:50 [error] 4525#0: *1015289 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
Vous pouvez voir que la première requête enregistre un dépassement de délai portant l’id 1015157. Il est également intéressant de noter que la première ligne du journal est « timed out while reading, », alors que toutes les autres indiquent « timed out while waiting », et que ce dernier message est celui qui se répète indéfiniment. Voici la requête correspondante dans le journal gokeyless :
➜ ~ grep 'id=1015157 ' gokeyless.log | head -1
2018-07-25T05:30:39.000 29m41 2018/07/25 05:30:39 [DEBUG] connection 127.0.0.1:30520: worker=ecdsa-29 opcode=OpECDSASignSHA256 id=1015157 sni=announce.php?info_hash=%a8%9e%9dc%cc%3b1%c8%23%e4%93%21r%0f%92mc%0c%15%89&peer_id=-ut353s-%ce%ad%5e%b1%99%06%24e%d5d%9a%08&port=42596&uploaded=65536&downloaded=0&left=0&corrupt=0&key=04a184b7&event=started&numwant=200&compact=1&no_peer_id=1 ip=104.20.33.147
Aha ! Cette valeur SNI est clairement invalide (les SNI sont comme les en-têtes d'hôte, c'est-à-dire qu'il s'agit de domaines et non de chemins URL), et elle est aussi assez longue. Notre système de stockage indexe les certificats en fonction de deux indices : à quel SNI ils correspondent, et à quelles adresses IP ils correspondent (pour les clients les plus anciens qui ne prennent pas en charge SNI). Notre interface de stockage utilise le protocole memcached, et la bibliothèque client qu'utilise gokeyless-internal rejette les requêtes de clés de plus de 250 caractères (longueur maximale des clés memcached), alors que la logique de nginx consiste simplement à ignorer le SNI invalide et traiter la requête comme si elle n’avait qu’une adresse IP. La modification de notre nouvelle version avait fait passer cette condition de ErrKeyNotFound à ErrInternal, ce qui a déclenché des problèmes en cascade dans nginx. Les « dépassements de délai » rencontrés étaient en fait le résultat du rejet de toutes les requêtes en cours multiplexées sur une connexion qui renvoyait ErrInternalfor pour une seule requête. Ces requêtes ont été retentées, mais une fois cette condition déclenchée, nginx a été dépassé par le nombre de requêtes retentées ainsi que par le flux continu de nouvelles requêtes arrivant avec un mauvais SNI, et n'a pas pu se rétablir. Cela explique pourquoi le retour à la version précédente de gokeyless-internal n'a pas résolu le problème.
Cette découverte a fini par attirer notre attention sur nginx, qui ne semblait jusqu'à présent responsable de rien, dans la mesure où il avait fonctionné de manière fiable depuis des années avec des serveurs de clés clients. Cependant, communiquer par le biais d'un serveur localhost vers un serveur de clés mutualisé est fondamentalement différent d'utiliser l'Internet public pour communiquer avec le serveur de clés d'un client, et nous avons dû effectuer les changements suivants :
- Au lieu d'un long délai de connexion et d'un délai de réponse relativement court pour les serveurs de clés clients, des délais de connexion extrêmement courts et des délais de requête plus longs conviennent davantage à un serveur de clés localhost.
- De même, il est raisonnable de réessayer (avec interruption) si nous subissons un dépassement de délai en attendant la réponse du serveur de clés client, car nous ne pouvons pas faire confiance au réseau. Mais avec localhost, un dépassement de délai ne se produirait que si gokeyless-internal était en surcharge et que la requête était toujours en attente de traitement. Dans ce cas, un nouvel essai ne ferait qu'entraîner une augmentation de la charge de travail totale demandée à gokeyless-internal, ce qui ne ferait qu'aggraver la situation.
- Plus important encore, nginx ne doit pas rejeter toutes les requêtes multiplexées sur une connexion si l'une d'entre elles rencontre une erreur, car une seule connexion ne représente plus un seul client.
Les implémentations comptent
Le CPU au niveau de notre périphérie est l'un de nos actifs les plus précieux, et il est étroitement surveillé par notre équipe en charge des performances (en sorte la « police du processeur »). Peu de temps après avoir activé Keyless Everywhere dans l'un de nos datacenters canary, des membres de l’équipe ont remarqué que gokeyless utilisait ~50 % d'un noyau par instance. Nous déplacions les opérations de signature de nginx vers gokeyless, il devait donc utiliser maintenant plus de CPU.. Mais nginx aurait dû bénéficier d'une réduction proportionnelle de l'utilisation du CPU, n'est-ce pas ?
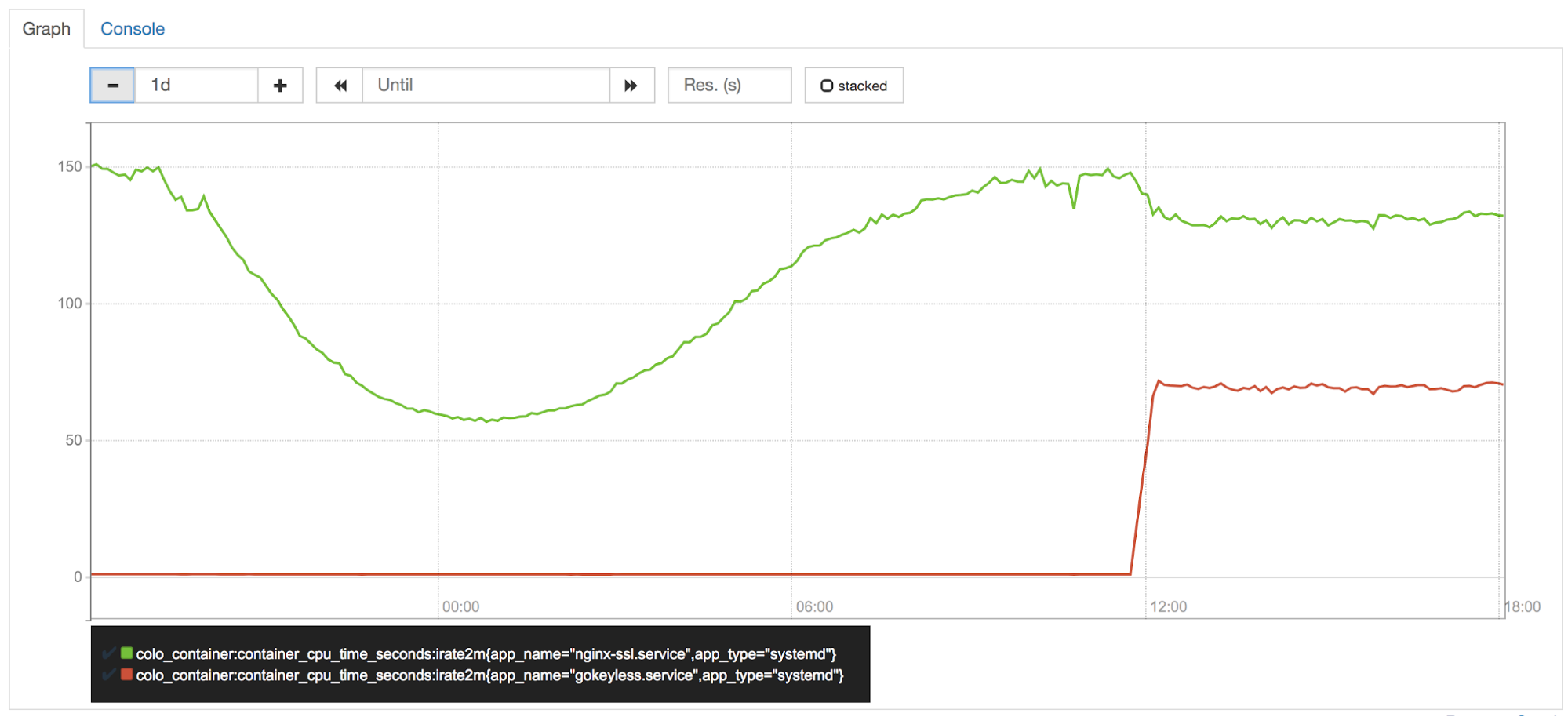
Erreur. Les opérations de courbe elliptique sont très rapides en Go, mais il est bien connu que les opérations RSA sont beaucoup plus lentes que leurs homologues BoringSSL.
Bien que Go 1.11 comprenne des optimisations pour les opérations mathématiques RSA, nous avions besoin de plus de vitesse. Un code assembleur bien réglé est nécessaire pour pouvoir être à la hauteur des performances de BoringSSL, c'est pourquoi Armando Faz, de notre équipe Crypto, a aidé à récupérer une partie de la puissance de calcul perdue en réimplémentant des parties du package math/big avec assemblage dépendant de la plate-forme dans un fork interne de Go. La récente politique d'assemblage de Go privilégie l'utilisation du code portable de Go plutôt que l'assemblage, donc ces optimisations n'ont pas été effectuées en amont. Il reste encore de la place pour d'autres optimisations, et c'est pour cette raison que nous étudions toujours la possibilité de passer à cgo + BoringSSL pour les opérations de signature, malgré les nombreux inconvénients de cgo.
Changer notre outillage
L'isolement de processus est un outil puissant pour protéger les secrets de la mémoire. Notre passage à Keyless Everywhere démontre que ce n'est pas un outil simple à exploiter. La réorganisation de l'architecture d'un système existant tel que nginx pour utiliser l'isolation de processus afin de protéger les secrets a pris beaucoup de temps et a été difficile. Une autre approche concernant la sécurité de la mémoire consiste à utiliser un langage sans danger pour la mémoire comme Rust.
Rust a été développé à l'origine par Mozilla mais commence à être utilisé à une bien plus grande échelle. Le principal avantage de Rust par rapport à C/C++ est qu'il possède des fonctions de protection de la mémoire sans mécanisme de ramasse-miettes (garbage collector).
Réécrire une application existante dans un nouveau langage tel que Rust est un travail fastidieux. Cela dit, de nombreuses nouvelles fonctionnalités Cloudflare, depuis la puissante fonction Firewall Rules à notre 1.1.1.1 avec l'application WARP, ont été écrites en Rust pour tirer parti de ses puissantes propriétés en matière de protection de la mémoire. Nous sommes vraiment satisfaits de Rust jusqu'à présent et nous avons l'intention de l'utiliser encore plus à l'avenir.
Conclusion
Les séquelles douloureuses de Heartbleed nous ont donné une leçon qui semble évidente avec le recul : il est risqué en terme de sécurité de conserver des secrets importants dans des applications accessibles à distance via Internet. Au cours des années suivantes, au prix d'un travail considérable, nous avons utilisé la séparation des processus et Keyless SSL pour faire en sorte que le prochain Heartbleed ne mette pas les clés des clients en danger.
Cependant, les choses ne s'arrêtent pas là. Récemment, des vulnérabilités de divulgation de mémoire telles que NetSpectre ont été découvertes, et elles sont capables de contourner les limites des processus d'applications. Nous continuons donc à étudier activement de nouveaux moyens de protéger les clés.
