


À la fin du mois d'août, le service client de Cloudflare a commencé à recevoir des plaintes évoquant des pannes de sites se trouvant sur notre réseau en Autriche. Notre équipe a réagi immédiatement pour tenter d'identifier la source de ce qui d'extérieur ressemblait à une panne partielle d'Internet en Autriche. Nous avons rapidement compris que le problème concernait les fournisseurs d'accès Internet locaux autrichiens.
L'interruption de service n'était toutefois pas liée à un problème technique. Comme nous l'avons découvert ultérieurement dans la presse, c'est une décision de justice qui était à l'origine de tout cela. Sans que Cloudflare soit mis au courant, un tribunal autrichien avait ordonné aux fournisseurs d'accès Internet (FAI) autrichiens de bloquer 11 adresses IP de Cloudflare.
Par cette décision de bloquer 14 sites Web accusés de violations de droits d'auteur par les détenteurs de ces droits , l'ordonnance de blocage d'adresse IP a rendu des milliers de sites Web inaccessibles aux utilisateurs ordinaires d'Internet en Autriche pendant deux jours. Quel était le tort des milliers d'autres sites ? Aucun. Ils ont été les victimes temporaires de l'incapacité à former des recours et des systèmes juridiques qui correspondent réellement à l'architecture d'Internet.
Aujourd'hui, nous allons engager une discussion concernant le blocage d'adresses IP : pourquoi il existe, de quoi il s'agit, ses effets, les personnes affectées et les raisons pour lesquelles ce moyen de traiter le contenu en ligne est problématique.
Effets collatéraux, petits et grands
Le plus incroyable dans ce type de blocage c'est qu'il s'en produit régulièrement, dans le monde entier. Cependant, à moins qu'ils se produisent à grande échelle comme ce fut le cas en Autriche ou que quelqu'un décide d'attirer l'attention sur ces blocages, ils passent généralement inaperçus aux yeux du monde. Même Cloudflare, forte de son expertise technique et d'une solide compréhension du fonctionnement de ces blocages, n'est pas en mesure de découvrir systématiquement qu'une adresse IP est bloquée.
Pour les utilisateurs d'Internet, la situation est encore plus opaque. Ils ne savent généralement pas pourquoi ils ne peuvent pas se connecter à un site Web particulier, d'où vient le problème de connexion ni comment y remédier. Ils savent simplement qu'ils ne peuvent pas accéder au site qu'ils essaient de consulter. Et il peut être difficile de documenter l'événement lorsque les sites deviennent inaccessibles en raison d'un blocage d'adresse IP.
Par ailleurs, les pratiques de blocage sont très répandues. Dans son rapport « Freedom on the Net », Freedom House a récemment expliqué que sur les 70 pays que l'organisation a analysés (parmi lesquels figurent des pays tels que la Russie, l'Iran et l'Égypte mais aussi des démocraties occidentales telles que le Royaume-Uni et l'Allemagne), 40 ont connu des formes de blocage de site Web. Si le rapport n'explique pas en détail les modalités de blocage par ces pays, il apparaît qu'une grande partie a recours au blocage d'adresse IP, ce qui provoque potentiellement les mêmes effets que ce à quoi nous avons assisté en Autriche, à savoir un arrêt partiel d'Internet.
Il n'est peut-être pas facile d'évaluer l'étendue des dommages collatéraux du blocage d'IP, mais nous avons connaissance d'exemples pour lesquels des organisations ont tenté de les quantifier. En lien avec une affaire portée devant la Cour européenne des droits de l'homme, l'Institut européen de la société de l'information, un organisme à but non lucratif basé en Slovaquie, a étudié le blocage des sites Web par le régime russe en 2017. La Russie a exclusivement utilisé les adresses IP quand elle voulait bloquer du contenu. L'Institut a conclu que le blocage des adresses IP avait conduit à un « blocage collatéral de sites Web à grande échelle » et a relevé qu'au 28 juin 2017, « 6 522 629 ressources Internet avaient été bloquées en Russie, dont 6 335 850, soit 97 %, l'avaient été de manière collatérale, c'est-à-dire sans justification légale. »
Au Royaume-Uni, le blocage excessif a incité l'organisation à but non lucratif Open Rights Group à créer le site Web Blocked.org.uk. Le site Web dispose d'un outil qui permet aux utilisateurs et aux propriétaires de sites de signaler les situations de surblocage et de demander aux FAI de lever les blocages. Le groupe compte également de centaines de témoignages individuels qui relatent les conséquences du blocage sur ceux dont les sites Web ont été bloqués de manière inappropriée, des organisations caritatives aux propriétaires de petites entreprises. Les méthodes de blocage utilisées ne sont pas toujours claires, toutefois, le simple fait qu'il soit nécessaire de créer un tel site illustre l'ampleur du surblocage. Imaginez un couturier, un horloger ou un concessionnaire automobile cherchant à faire la publicité de ses services et à attirer de nouveaux clients potentiels grâce à son site Web. Cela ne fonctionne que si les utilisateurs locaux peuvent accéder au site.
D'aucuns seraient tentés de répondre « qu'il suffit de vérifier qu'aucun site restreint ne partage une adresse avec des sites non restreints. » Cependant, comme nous l'évoquerons plus en détail, une telle réponse ne tient pas compte de l'énorme différence qu'il y a entre le nombre de noms de domaines possibles et le nombre d'adresses IP disponibles et va à l'encontre des propres spécifications techniques sur lesquelles Internet repose. Qui plus est, la notion de restreints et non restreints n'a pas la même signification selon les régions, les communautés et les organisations. Et quand bien même il serait possible de connaître l'ensemble des restrictions, la manière dont les protocoles (du réseau Internet même) sont conçus indique qu'il est quasiment, si ce n'est totalement, impossible de respecter toutes les contraintes de chaque agence.
Difficultés juridiques et atteintes aux droits humains
Le surblocage des sites Web n'engendre pas uniquement un problème pour les utilisateurs ; les implications sont également d'ordre juridique. Compte tenu des répercussions qui peuvent toucher des citoyens ordinaires cherchant a exercer leurs droits en ligne, les entités gouvernementales (qu'il s'agisse des tribunaux ou des organismes de réglementation) ont l'obligation légale de vérifier que leurs ordonnances sont nécessaires et proportionnées, et n'affectent pas inutilement ceux qui ne contribuent pas au préjudice.
Il serait difficile d'imaginer, par exemple, qu'un tribunal, en réponse à des actes répréhensibles présumés, délivre aveuglément un mandat de perquisition ou une ordonnance sur la seule base d'une adresse sans se soucier de savoir si cette adresse correspond à une maison individuelle, à un immeuble de six logements en copropriété ou à une tour de plusieurs centaines d'habitations distinctes. En revanche, en ce qui concerne les adresses IP ces pratiques semblent généralisées.
En 2020, la Cour européenne des droits de l'homme (CEDH), c'est-à-dire le tribunal qui supervise la mise en œuvre de la Convention européenne des droits de l'homme du Conseil de l'Europe, a instruit un dossier impliquant un site Web qui avait été bloqué en Russie non pas parce qu'il avait été ciblé par le gouvernement russe, mais parce qu'il partageait une adresse IP avec un site Web bloqué. Le propriétaire du site web a intenté un procès pour le blocage. La CEDH a conclu que le blocage indiscriminé était inadmissible, jugeant que le blocage du contenu légitime du site « constituait une ingérence arbitraire dans les droits des propriétaires de tels sites Web. » En d'autres termes, la CEDH a jugé qu'il était inapproprié pour un gouvernement d'émettre des ordonnances entraînant le blocage de sites qui n'étaient pas visés.
Utilisation de l'infrastructure d'Internet pour résoudre des difficultés concernant le contenu
Les utilisateurs ordinaires d'Internet ne se posent pas beaucoup de questions sur la manière dont le contenu auquel ils essayent d'accéder en ligne leur est transmis. Ils partent du principe que lorsqu'ils entrent un nom de domaine dans leur navigateur, le contenu va automatiquement apparaître. Et si ce n'est pas le cas, ils ont tendance à imaginer que le problème vient du site Web lui-même, sauf si l'ensemble de la connexion Internet semble interrompu. Ces suppositions élémentaires ne tiennent pas compte d'une réalité selon laquelle les connexions à un site Web sont parfois utilisées pour limiter l'accès au contenu en ligne.
Pourquoi les pays bloquent-ils les connexions à des sites Web ? Ils souhaitent peut-être limiter l'accès de leurs propres citoyens à ce qu'ils considèrent comme du contenu illégal, par exemple du jeu en ligne ou du matériel sexuellement explicite, par ailleurs autorisé dans d'autres pays. Il est possible qu'ils souhaitent empêcher les sources d'informations étrangères de consulter ce qu'ils estiment être de la désinformation primaire. Ou peut-être encore cherchent-ils à aider les détenteurs de droits d'auteur qui désirent bloquer l'accès à un site Web dans le but de limiter la visualisation d'un contenu qui selon eux relève d'une propriété intellectuelle qui leur appartient.
Soyons clairs, bloquer l'accès à et retirer du contenu d'Internet sont deux actions différentes. II existe un certain nombre d'autorités et d'obligations légales conçues pour autoriser le retrait d'un contenu illégal. En effet, dans de nombreux pays, le droit prévoit que le blocage ne doit être ordonné qu'en dernier recours, une fois que toutes les tentatives de faire retirer le contenu de la source ont été épuisées.
Le blocage n'empêche que certains utilisateurs, ceux dont l'accès Internet dépend du FAI responsable du blocage, d'accéder aux sites Web. Le site lui-même continue d'exister en ligne et d'être accessible pour tous les autres internautes. Toutefois, lorsque le contenu provient d'un autre emplacement et ne peut pas être facilement retiré, le blocage peut se présenter comme la meilleure, voire la seule option possible pour un pays.
Nous sommes conscients des motivations qui poussent parfois les pays à mettre en place le blocage. Cependant, par principe, nous estimons qu'il est important que les utilisateurs soient informés de ce que le site Web auquel ils tentent d'accéder a été bloqué, et, dans la mesure du possible, qu'ils sachent qui est à l'origine du blocage et pourquoi. Et il est essentiel que toute restriction appliquée à du contenu soit la plus limitée possible à ce qui est nécessaire pour empêcher un préjudice, afin d'éviter d'entraver les droits des autres.
Le blocage d'adresse IP par force brute ne le permet pas toujours. Il est totalement opaque pour les utilisateurs. Cette pratique a des conséquences imprévues et inévitables sur d'autres contenus. Et en raison de la structure même d'internet, il n'existe aucune manière d'identifier les autres sites Web qui pourraient être affectés, ni avant, ni après le blocage.
Pour comprendre ce qui s'est passé en Autriche et c'est qui se passe dans de nombreux autres pays du monde qui cherchent à bloquer du contenu avec une méthode aussi grossière que celle du blocage d'adresses IP, nous devons comprendre ce qui se passe en arrière-plan. Cela implique d'entrer dans les détails techniques.
L'identité est associée aux noms, jamais aux adresses
Avant même de nous lancer dans la description des aspects techniques du blocage, il convient de préciser que la première et meilleure option lorsqu'il s'agit de traiter du contenu est de le faire à la source. Un propriétaire de site Web ou un fournisseur d'hébergement a la possibilité de retirer du contenu au niveau granulaire, sans qu'il soit nécessaire de mettre à l'arrêt l'ensemble du site Web. Sous un angle le plus technique, un registre de noms de domaine peut potentiellement supprimer intégralement d'Internet un nom de domaine, et par conséquent un site Web.
Mais comment bloquer l'accès à un site Web si, pour quelque raison que ce soit un propriétaire de contenu ou une source de contenu n'est pas en mesure ou n'accepte pas de le retirer d'Internet ? Il n'existe que trois points de contrôle possibles.
Le premier passe par le DNS (système de noms de domaine), qui traduit les noms de domaine en adresses IP afin que le site puisse être trouvé. Au lieu de renvoyer une adresse IP valide pour un nom de domaine, le résolveur DNS pourrait mentir et répondre avec un code, NXDOMAIN, signifiant que « ce nom n'existe pas ». Il serait préférable d'utiliser un des numéros d'erreur honnêtes normalisés en 2020, mentionnant erreur 15 pour un blocage, erreur 16 pour une censure, 17 pour un filtrage ou 18 pour une interdiction ; ils ne sont toutefois pas encore très utilisés.
Curieusement, la précision et l'efficacité d'un DNS comme point de contrôle varient selon que le résolveur DNS est privé ou public. Les résolveurs DNS privés ou internes sont appliqués par les FAI ou les environnements d'entreprise pour leurs propres clients connus, ce qui signifie que les opérateurs peuvent être plus précis lorsqu'ils appliquent des restrictions de contenu. En revanche, le niveau de précision n'est pas disponible pour les résolveurs ouverts ou publics, principalement parce dans la carte d'Internet, le routage et l'adressage se font de manière globale et changent constamment, à la grande différence des adresses postales et des routes sur une carte géographique. Par exemple, les résolveurs DNS privés peuvent être en mesure de bloquer l'accès à des sites Web au sein de régions géographiques spécifiques avec un certain niveau de précision dont les résolveurs DNS publics sont privés. Il s'agit d'une différence extrêmement importante si l'on considère la disparité (et l'hétérogénéité) des régimes à l'origine des blocages dans le monde.
La deuxième méthode consiste à bloquer individuellement les requêtes en connexion vers un nom de domaine restreint. Lorsqu'un utilisateur ou un client souhaite consulter un site Web, une connexion est établie du client vers un nom de serveur, par exemple le nom de domaine. Si un réseau ou un appareil sur le chemin d'accès est en mesure d'observer le nom du serveur, il peut être mis un terme à la connexion. À la différence du DNS, il n'existe aucun mécanisme pour informer l'utilisateur que le nom de serveur a été bloqué et lui préciser pourquoi.
La troisième solution est de bloquer l'accès à une adresse IP qui contient le nom de domaine. Cela revient à bloquer la livraison de l'ensemble du courrier à destination d'une adresse physique. Imaginez par exemple que l'adresse soit un gratte-ciel dans lequel résident de nombreux occupants indépendants et qui n'ont aucun rapport les uns avec les autres. L'interruption de la livraison du courrier à l'adresse de l'immeuble provoque des dommages collatéraux dans la mesure où tous les habitants sans distinction sont concernés. Il en va de même pour les adresses IP.
Concrètement, l'adresse IP est la seule des trois options qui n'est associée à aucun nom de domaine. Le nom de domaine du site Web n'est pas nécessaire pour le routage et la distribution des paquets de données ; en réalité, il est totalement ignoré. Un site Web peut être disponible sur n'importe quelle adresse IP, voire sur plusieurs, et ce, simultanément. Et l'ensemble d'adresses IP sur lequel réside un site Web change à tout moment. Il ne peut pas être connu de manière définitive en interrogeant le DNS, qui est capable de renvoyer n'importe quelle adresse valide, quels que soient le moment et le motif, et ce, depuis 1995.
L'idée qu'une adresse puisse être représentative d'une identité est totalement contraire à la conception d'Internet ; en effet, le découplage de l'adresse et du nom est profondément ancré dans les protocoles et normes d'Internet, comme il est expliqué ensuite
Internet est un ensemble de protocoles et non une politique ou une perspective
De nombreuses personnes continuent, à tort, de penser qu'une adresse IP représente un site Web unique. Nous avons précédemment indiqué que l'association entre les noms et les adresses était compréhensible dans la mesure où les premiers éléments connectés sur Internet ont été un ordinateur, une interface, une adresse ou un nom. Cette association « un pour un » était un artefact de l'écosystème dans lequel le protocole Internet avait été déployé, et cela correspondait bien aux besoins de l'époque.
Peu importe la pratique de nommage un pour un en vigueur aux débuts d'Intérêt, il a toujours été possible d'attribuer plusieurs noms à un serveur (ou « hôte »). Par exemple, un serveur était (et est toujours) souvent configuré avec des noms évoquant l'offre de services tels que « mail.example.com » et « www.example.com », mais ceux-ci partageaient un nom de domaine de base. Il y avait peu de raison de préférer des noms de domaine totalement différents jusqu'au moment où il a fallu placer ensemble des sites Web totalement différents sur un serveur unique. Cette pratique a été facilitée en 1997 par l'en-tête Host dans HTTP/1.1, une fonctionnalité conservée par le champ SNI dans une extension TLS en 2003.
Au fil de ces modifications, le protocole Internet et, séparément, le protocole DNS, non seulement ont suivi le rythme mais ils sont également restés inchangés. C'est exactement ce qui a permis à Internet de prendre de l'ampleur et d'évoluer, car il s'agit d'adresses, d'accessibilité et de rapports entre un nom arbitraire et une adresse IP.
Les conceptions d'IP et de DNS sont également entièrement indépendantes, ce qui renforce l'idée selon laquelle les noms sont distincts des adresses. Un examen minutieux des éléments de conception des protocoles met en lumière la perception erronée des politiques qui conduisent aux pratiques actuellement courantes de contrôle d'accès au contenu en bloquant les adresses IP.
L'IP a été conçu exclusivement pour l'accessibilité
À l'instar des projets d'ingénierie civile publique qui reposent sur des codes de construction et des pratiques recommandées, Internet a été conçu à partir d'un ensemble de normes et spécifications ouvertes inspirées par l'expérience et qui font l'objet d'un consensus international. Ces normes Internet qui connectent les appareils physiques et les applications sont publiées par l'Internet Engineering Task Force (IETF) sous la forme de « Requests for Comment » (RFC), nommée ainsi non pas pour suggérer qu'elles ne sont pas terminées, mais plutôt qu'elles doivent être capables d'évoluer en même temps que les connaissances et l'expérience. L'IETF et ses RFC sont inscrits dans la structure même des communications, par exemple avec le premier RFC 1 publié en 1969. La spécification de protocole Internet (IP) a obtenu le statut RFC en 1981.
Parallèlement aux organisations de normalisation, une idée fondamentale a contribué au succès d'Internet. Il s'agit du principe end-to-end (e2e) ou bout en bout, également codifié en 1981, après des années d'expérience reposant sur une suite d'essais et d'erreurs. Le principe de bout en bout est une abstraction puissante qui, bien qu'elle ait pris de nombreuses formes, exprime une notion essentielle de la spécification du protocole Internet : l'unique responsabilité du réseau est d'établir l'accessibilité et toute autre fonctionnalité possible comporte un coût ou un risque.
L'idée « d'accessibilité » dans le protocole Internet est également entérinée dans la conception des adresses IP elles-mêmes. Si l'on consulte la spécification du protocole Internet, RFC 791, l'extrait suivant de la Section 2.3 est explicite concernant l'absence de lien entre les adresses IP et les noms, interfaces et autres éléments.
Adressage
Une distinction est établie entre les noms, les adresses et les itinéraires [4]. Un nom indique ce que nous cherchons. Une adresse indique où le trouver. Un itinéraire explique comment s'y rendre. Dans le protocole Internet il est essentiellement question d'adresses. Il revient aux protocoles de niveau supérieur (par exemple protocole d'hôte à hôte ou application) d'établir la correspondance ou le mappage entre les noms et les adresses. Le module d'Internet mappe les adresses Internet avec les adresses réseau locales. Il revient aux procédures de niveau inférieur (par exemple le réseau local ou les passerelles) d'établir la correspondance entre les adresses réseau locales et les itinéraires.
[ RFC 791, 1981 ]
À l'instar des adresses postales pour les grands immeubles du monde physique, les adresses IP ne sont rien de plus que des noms de rue inscrits sur un morceau de papier. Et comme dans le cas des adresses postales inscrites sur ce papier, personne ne peut savoir avec certitude quelle entité ou organisation existe derrière une adresse IP. Dans un réseau tel que celui de Cloudflare, n'importe quelle adresse IP unique représente des milliers de serveurs et peut compter encore plus de sites Web et de services (dans certains cas cela se chiffre en millions) précisément parce que le protocole Internet est conçu pour le permettre.
Voici une question intéressante : est-il possible pour nous, ou n'importe quel fournisseur service avec contenu, de faire en sorte que chaque adresse IP ne corresponde qu'à un seul et unique nom ? La réponse est sans équivoque non, et ici aussi, cela tient à un aspect de la conception du protocole, plus précisément le DNS.
Le nombre de noms dans un DNS dépasse toujours celui des adresses disponibles
Il est impossible de parvenir à un rapport un pour un entre les noms et les adresses étant données les spécifications d'Internet, et ce, pour les mêmes raisons que dans le monde physique. En admettant un instant que les personnes et les organisations ne puissent jamais changer d'adresse. La réalité fondamentale est telle que le nombre de personnes et d'organisations dépasse le nombre d'adresses postales. Internet doit comporter plus de noms que d'adresses, non seulement nous le souhaitons, mais nous en avons besoin.
La différence de magnitude entre les noms et les adresses est également codifiée dans les spécifications. Les adresses IPv4 comptent 32 bits, les adresses IPv6 128 bits. La taille d'un nom de domaine pouvant être interrogé par le DNS peut aller jusqu'à 253 octets, ou 2 024 bits (Section 2.3.4 du RFC 1035, publié en 1987). Le tableau ci-dessous met ces différences en perspective :
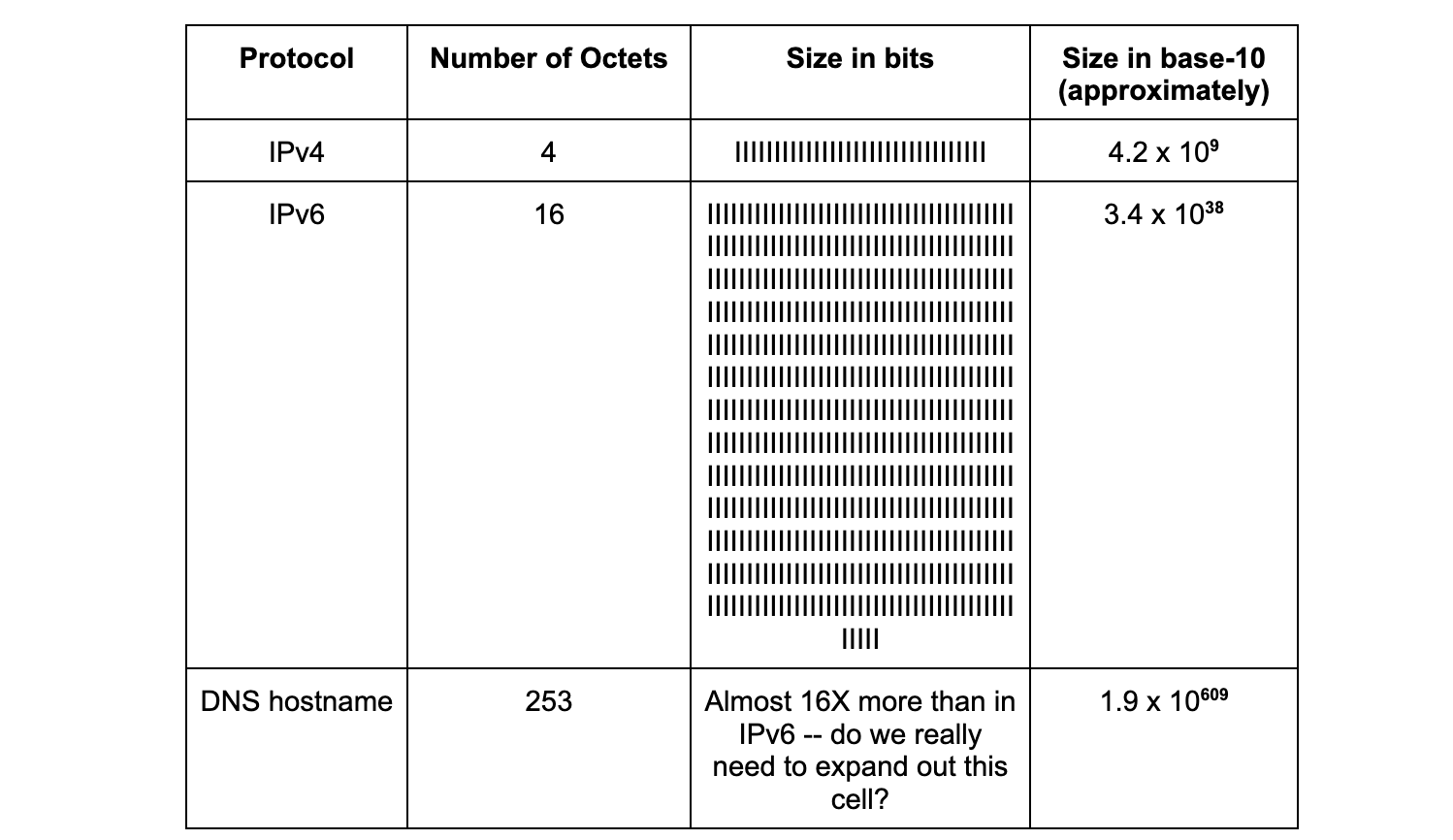
Le 15 novembre 2022, l'organisation des Nations Unies annonçait que la population mondiale dépassait les huit milliards de personnes. En toute logique, nous savons qu'il est impossible d'avoir autant d'adresses postales sur terre. Le nombre de noms possibles sur la planète, et de la même façon sur Internet, dépasse le nombre d'adresses disponibles.
Tenons-nous-en aux preuves !
Maintenant que ces deux principes concernant les adresses IP et les noms DNS dans les normes internationales sont compris - à savoir que l'adresse IP et les noms de domaine servent des objectifs distincts et que le rapport entre les deux ne peut pas être de un pour un - examinons un cas récent de blocage de contenu à l'aide d'adresses IP qui pourrait nous aider à comprendre en quoi cela peut poser des problèmes. Prenez, par exemple, l'incident de blocage d'adresses IP survenu en Autriche fin août 2022. L'objectif était de restreindre l'accès à 14 domaines cibles, en bloquant 11 adresses IP (source : RTR.Telekom publié via Internet Archive). La différence entre ces deux nombres aurait dû alerter sur le fait que le blocage IP risquait d'être différent de celui escompté.
Les analogies et les normes internationales pourraient expliquer les raisons pour lesquelles il convient d'éviter le blocage d'IP. Nous pouvons toutefois constater l'étendue du problème en observant les données à l'échelle d'Internet. Pour mieux comprendre et expliquer la gravité du blocage d'IP, nous avons décidé de générer une vue globale des noms de domaine et des adresses IP (il nous faut remercier et saluer le travail de notre chercheur doctorant Sudheesh Singanamalla). En septembre 2022, nous avons utilisé des fichiers de zone faisant autorité pour les domaines de niveau supérieur (TLD) .com, .net, .info, et .org, avec des listes issues du million de sites Web les plus importants, et nous avons obtenu un total de 255 315 270 noms uniques. Nous avons ensuite interrogé le DNS de chacune des cinq régions et enregistré l'ensemble des adresses IP renvoyées. Le tableau suivant dresse une synthèse de nos conclusions :
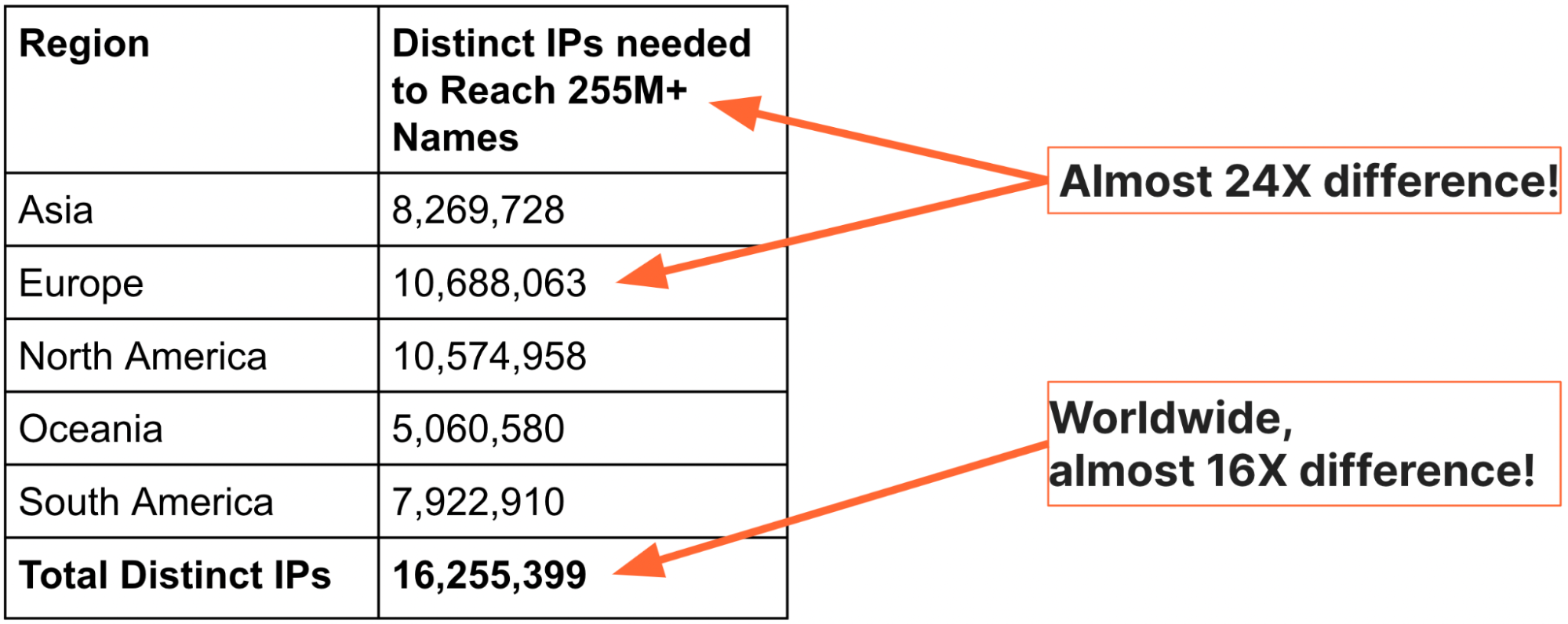
À la lecture de ce tableau, la constatation est claire, il suffit de 10,7 millions d'adresses pour obtenir 255 315 270 de noms issus de toutes les régions de la planète et l'ensemble des adresses IP, quel qu'en soit l'emplacement, pour ces noms tourne autour de 16 millions. La proportion de noms pour les adresses IP est de presque 24 fois plus en Europe et 16 fois plus au niveau mondial.
Il reste un détail important à mentionner concernant ces chiffres : les adresses IP représentent le total des adresses IPv4 et IPv6, ce qui signifie que le nombre d'adresses nécessaires pour atteindre l'ensemble des 255 millions de sites est bien inférieur.
Nous avons également analysé les données sous différents angles, ce qui nous a permis de dégager des observations intéressantes. Par exemple, la figure ci-dessus illustre la distribution cumulée de la proportion des sites Web qui peuvent être visités pour chaque adresse IP supplémentaire. L'axe des Y correspond à la proportion des sites Web qui peuvent être atteints avec un certain nombre d'adresses IP. Dans l'axe des X, les 16 millions d'adresses IP sont classées selon qu'elles correspondent à plus ou moins de domaines, de gauche à droite. Remarque : n'importe quelle adresse IP dans cet ensemble est une réponse du DNS et doit disposer d'au moins un nom de domaine, mais les nombres le plus élevés de domaines dans les adresses IP de l'ensemble se trouvent dans les millions à 8 chiffres.
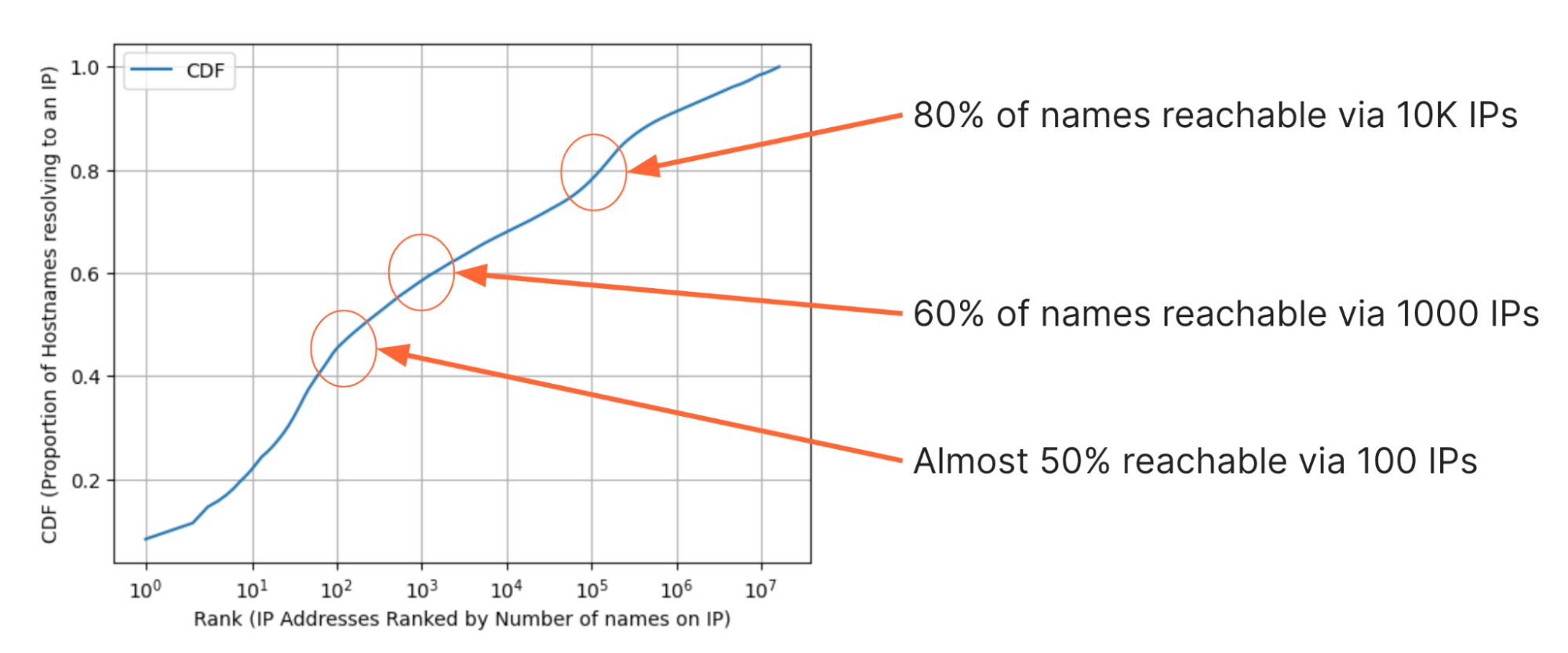
En observant la distribution cumulée, quelques observations sont surprenantes :
- Moins de 10 adresses IP sont nécessaires pour atteindre 20 % (soit environ 51 millions) des domaines de l'ensemble ;
- 100 IP suffisent pour atteindre environ 50 % des domaines ;
- 1000 IP suffisent pour atteindre 60 % des domaines ;
- 10 000 IP suffisent pour atteindre 80 %, soit 204 millions, de domaines.
En réalité, sur l'ensemble des 16 millions d'adresses, moins de la moitié, 7,1 millions (43,7 %), des adresses de l'ensemble de données avaient un seul nom. Sur ce point du « seul » nom, nous devons être encore plus clairs : il nous est impossible d'établir avec certitude qu'il n'y a qu'un seul et unique nom sur ces adresses car il existe beaucoup plus de noms de domaine que ceux contenus uniquement dans .com, .org, .info et .net. ll pourrait donc très bien y avoir d'autres noms sur ces adresses.
Non seulement plusieurs domaines peuvent se trouver sur une adresse IP unique, mais une adresse IP peut changer avec le temps pour n'importe lequel de ces domaines. Il peut être utile de changer régulièrement les adresses IP pour des raisons de sécurité, de performances et pour améliorer la fiabilité des sites Web. Par exemple, l'équilibrage de charge est utilisé dans de nombreuses opérations. Cela signifie que les requêtes de DNS peuvent renvoyer des adresses IP différentes dans le temps, ou à différents emplacements, pour les mêmes sites Web. C'est une autre raison, indépendante, pour laquelle le blocage reposant sur des adresses IP donnera un résultat différent de celui escompté dans le temps.
Enfin, il n'existe aucun moyen fiable de connaître le nombre de domaines existant pour une adresse IP sans examiner l'ensemble des noms dans le DNS, pour chaque emplacement sur terre et à chaque instant, ce qui est tout bonnement irréalisable.
Toute action exercée sur une adresse IP peut provoquer des dommages collatéraux, cela tient à la définition même des protocoles qui régissent et font fonctionner Internet.
Manque de transparence sur le blocage des adresses IP
Par conséquent, si nous pensons que le blocage d'une adresse IP pourrait avoir des effets collatéraux, il est généralement convenu que le surblocage lié au blocage d'adresses IP associées à plusieurs domaines est inapproprié, voire légalement inadmissible, par conséquent, pourquoi continue-t-on à en observer ? Aucune certitude n'est possible, par conséquent nous ne pouvons émettre que des spéculations. Parfois, cela tient à un manque de compréhension technique des effets potentiels, en particulier de la part d'entités telles que des magistrats qui ne sont pas des techniciens. Certains gouvernements ignorent tout simplement le dommage collatéral, comme ils le font avec les pannes d'Internet, car ils se contentent de voir que le blocage sert leurs intérêts. Et lorsqu'il y a dommage collatéral, il n'est généralement pas évident pour le reste du monde, donc la pression pour y remédier est souvent minime.
Ce point mérite d'être souligné. Lorsqu'une adresse IP est bloquée, tout ce que voit un utilisateur c'est un échec de connexion. Il ne connaît ni la raison, ni l'origine de cet échec. De l'autre côté, le serveur qui agit au nom du site Web n'est informé du blocage qu'à partir du moment où il commence à recevoir des plaintes parce qu'il est indisponible. Dans la pratique, il n'existe aucune transparence ni redevabilité concernant le surblocage. Et il peut s'avérer compliqué, voire impossible, pour un propriétaire de site Web de résister au blocage ou de tenter de résoudre un blocage injustifié.
Certains gouvernements, parmi lesquels celui de l'Autriche, publient des listes de blocages actifs, ce qui est un progrès notable vers la transparence. Mais pour toutes les raisons que nous avons évoquées, la publication d'une adresse IP ne permet pas de connaître l'ensemble des sites qui ont pu être bloqués involontairement. Cela ne donne pas non plus aux personnes concernées un moyen de contester le surblocage. Pour reprendre l'exemple du monde physique, il est difficile d'imaginer une décision de justice concernant un immeuble qui ne serait pas affichée sur la porte, mais dans l'espace virtuel, il est courant de faire fi de telles exigences de procédure et de notification.
Les pays sont de plus en plus nombreux à tenter de bloquer du contenu en ligne, il nous semble donc plus important que jamais d'évoquer les conséquences négatives engendrées par le blocage d'IP. Malheureusement, les FAI utilisent souvent les blocages d'IP pour mettre en œuvre ces exigences. Il arrive qu'il s'agisse de FAI plus récents ou moins influents que leurs homologues de plus grande envergure, mais les grands FAI se livrent également à cette pratique, ce qui se comprend dans la mesure où le blocage d'IP est la solution qui demande le moins d'efforts et qui est facilement disponible dans la plupart des équipements.
Par ailleurs, les domaines présents sur les mêmes adresses IP étant de plus en plus nombreux, le problème ne pourra aller qu'en s'aggravant.
Prochaines étapes
Que faire ?
Selon nous, il convient avant tout d'intensifier la transparence au sujet du recours au blocage d'IP. Nous ne connaissons pas de moyen exhaustif de documenter les dommages collatéraux causés par le blocage d'IP. Cependant, nous pensons qu'il existe des mesures à prendre en faveur d'une sensibilisation à cette pratique. Nous sommes engagés à travailler à de nouvelles initiatives qui mettront en avant ces informations, comme nous l'avons fait avec le Cloudflare Radar Outage Center.
Nous sommes également conscients de ce qu'il s'agit d'un problème généralisé au niveau d'Internet, et par conséquent cela doit s'inscrire dans le cadre d'un effort plus large. En cas de blocage d'IP, il y a une très forte probabilité que cela engendre une restriction de l'accès à une série de domaines sans rapport (et non ciblés). Personne ne devrait donc céder à cette facilité. C'est pourquoi nous incitons les partenaires de la société civile et les entreprises partageant notre état d'esprit à donner de la voix pour contester l'utilisation du blocage des adresses IP lorsqu'il s'agit de régler des problèmes liés à du contenu et à signaler les dommages collatéraux lorsqu'ils en sont témoins.
Pour être précis, si les pays doivent régler des problèmes de contenu illégal en ligne, il leur faut des mécanismes juridiques qui permettent le retrait ou la limitation d'un contenu dans le respect des droits. Nous pensons que la solution idéale est de s'attaquer à la source du contenu, et elle doit toujours être la première envisagée. Des lois telles que la nouvelle loi sur les services numériques de l'UE ou la loi encadrant le droit d'auteur à l'époque du numérique (Digital Millennium Copyright Act) fournissent des outils qui peuvent être utilisés pour traiter le contenu illégal à la source, tout en respectant d'importants principes de procédure régulière. Les gouvernements doivent se concentrer sur la création et l'application de mécanismes juridiques d'une manière qui aille le moins possible à l'encontre des droits de personnes et qui respecte des droits de l'homme.
Pour résumer le plus simplement possible, ces besoins ne peuvent en aucun cas être satisfaits par le blocage d'adresses IP.
Nous continuerons de chercher de nouvelles façons d'évoquer l'activité du réseau et ses interruptions, en particulier lorsque cela se traduit par des limitations d'accès qui ne sont pas nécessaires. Consultez Cloudflare Radar, vous y trouverez plus d'informations sur ce que nous voyons en ligne.