

Depuis la découverte de CRIME, BREACH, TIME, LUCKY-13, etc., les attaques par canal auxiliaire basées sur la longueur ont été considérées comme concrètes. Même si les paquets étaient chiffrés, les acteurs malveillants ont pu déduire des informations concernant le texte en clair sous-jacent en analysant les métadonnées telles que la longueur ou les informations temporelles des paquets.
Cloudflare a récemment été contactée par un groupe de chercheurs de l'Université Ben Gourion du Néguev, qui a rédigé un article intitulé « What Was Your Prompt? A Remote Keylogging Attack on AI Assistants », dans lequel il décrit « un nouveau canal auxiliaire pouvant être utilisé pour lire les réponses chiffrées provenant d'assistants IA via le web ».
Les équipes de Workers AI et AI Gateway ont travaillé en étroite collaboration avec ces chercheurs en sécurité dans le cadre de notre programme public de primes aux bugs, et ont découvert et intégralement corrigé une vulnérabilité affectant les fournisseurs de LLM (grands modèles de langage). Vous pouvez consulter le document de recherche détaillé ici.
Depuis que nous avons été informés de cette vulnérabilité, nous avons mis en œuvre une mesure d'atténuation afin de contribuer à sécuriser l'ensemble des clients Workers AI et AI Gateway. Selon les résultats de notre évaluation, les clients de Workers AI et AI Gateway n'en ont pas été victimes.
Comment se déroule une attaque par canal auxiliaire ?
Dans la publication, les auteurs décrivent une méthode permettant d'intercepter le flux d'une session de discussion avec un fournisseur de LLM, d'utiliser les en-têtes de paquets réseau afin de déduire la longueur de chaque jeton, d'en extraire et d'en segmenter la séquence, puis d'utiliser leurs propres LLM dédiés pour déduire la réponse.
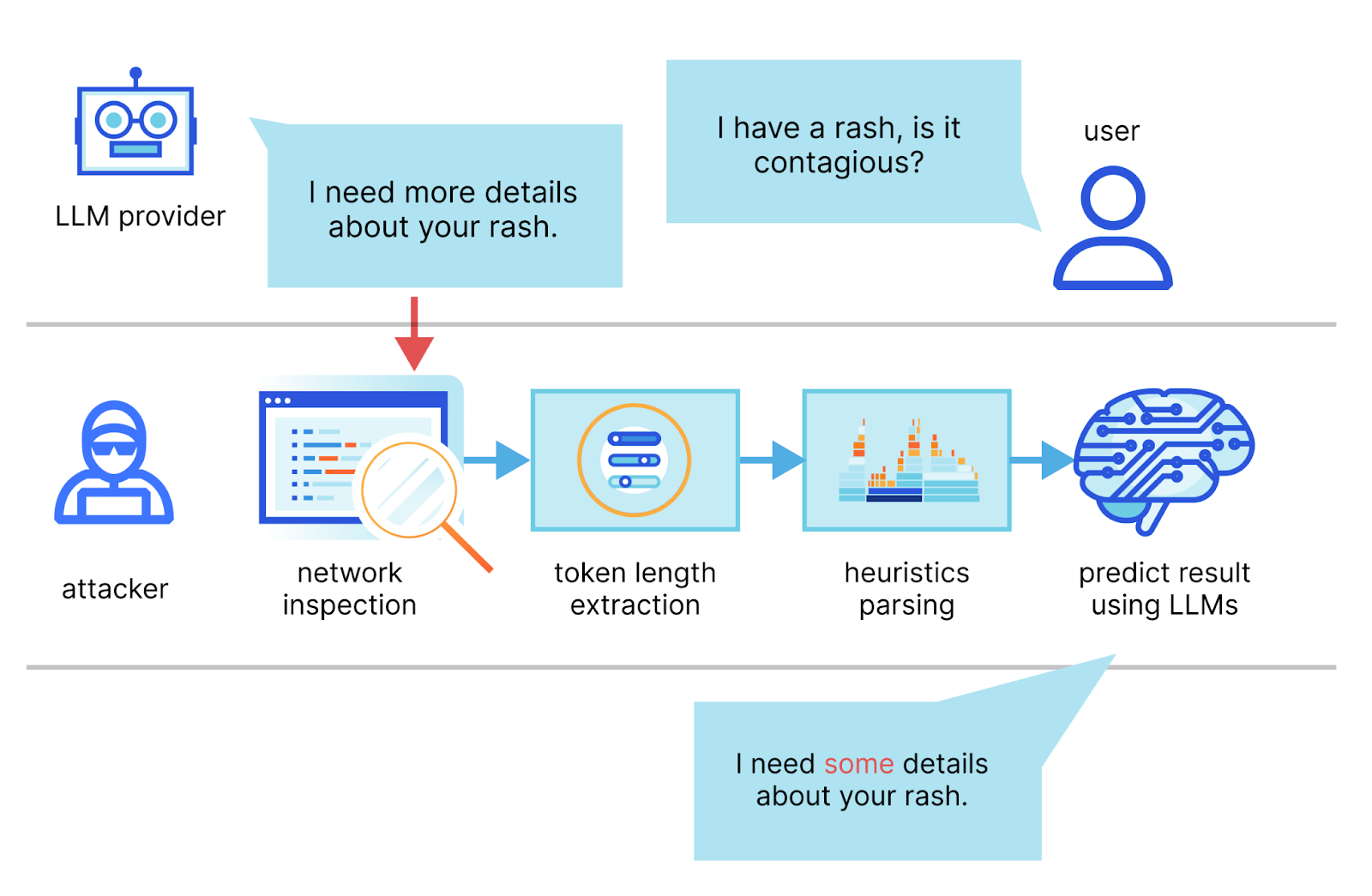
Les deux exigences principales déterminant le succès d'une attaque sont un client de chat basé sur l'IA exécuté en mode streaming (diffusion en continu) et un acteur malveillant capable de capturer le trafic réseau entre le client et le service de chat basé sur l'IA. En mode streaming, les jetons du LLM sont émis séquentiellement, introduisant un canal auxiliaire de la longueur du jeton. Des acteurs malveillants peuvent espionner des paquets via des réseaux publics ou sur le réseau d'un FAI.
Voici un exemple de requête vulnérable à une attaque par canal auxiliaire :
curl -X POST \
https://api.cloudflare.com/client/v4/accounts/<account-id>/ai/run/@cf/meta/llama-2-7b-chat-int8 \
-H "Authorization: Bearer <Token>" \
-d '{"stream":true,"prompt":"tell me something about portugal"}'
Utilisons Wireshark pour inspecter les paquets réseau de la session de chat du LLM pendant la diffusion en continu :
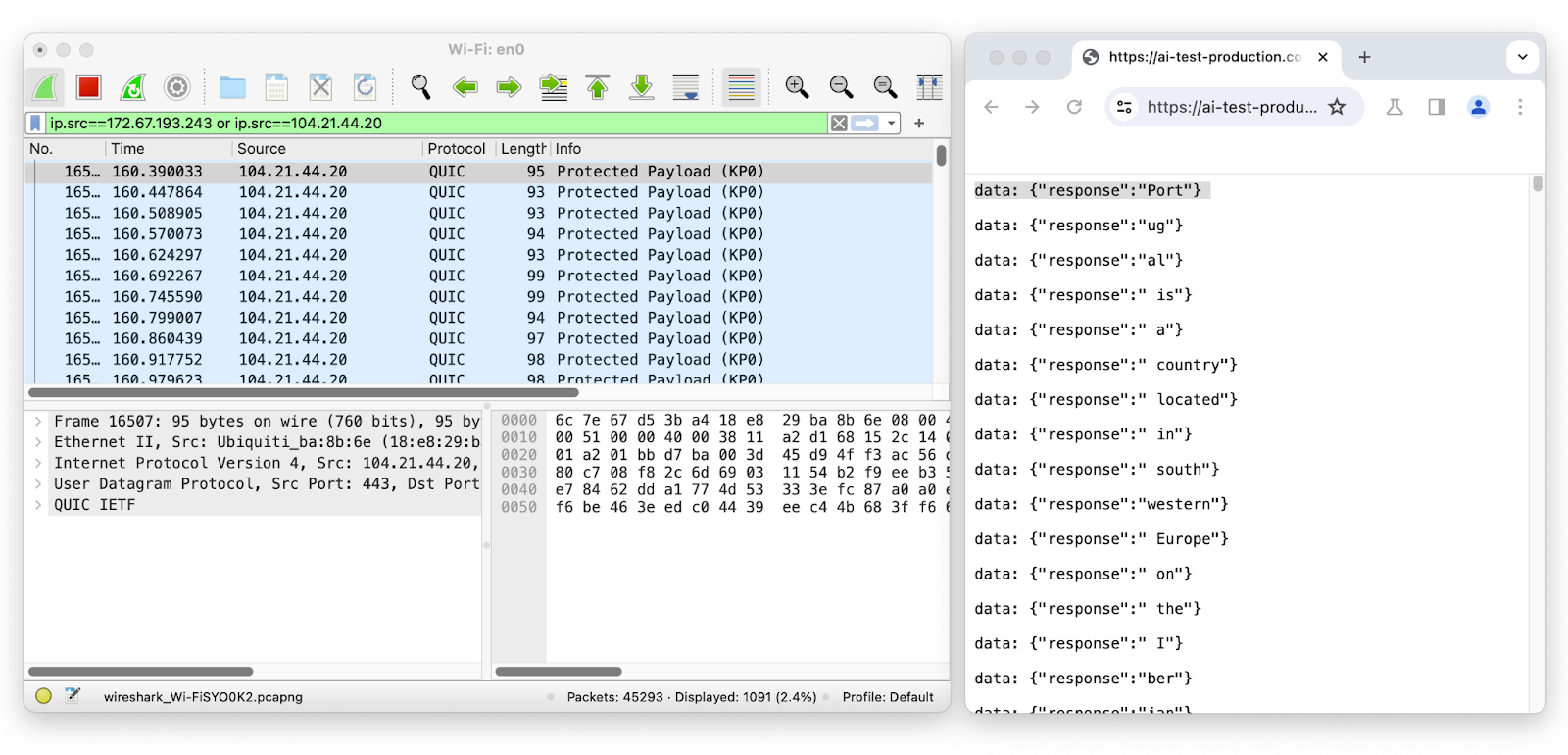
La longueur du premier paquet est 95 ; il correspond au jeton « Port », dont la longueur est de 4. La longueur du deuxième paquet est de 93 ; il correspond au jeton « ug », dont la longueur est de 2, et ainsi de suite. En supprimant l'enveloppe de jeton probable de la longueur du paquet réseau, il est facile de déduire le nombre de jetons transmis, ainsi que leur séquence et leur longueur individuelle, en interceptant simplement les données réseau chiffrées.
Puisque l'acteur malveillant a besoin de connaître la séquence de la longueur de jeton individuelle, cette vulnérabilité affecte uniquement les modèles de génération de texte utilisant la diffusion en continu. Cela signifie que les fournisseurs d'inférence IA qui utilisent la diffusion en continu (c'est-à-dire le moyen le plus courant d'interagir avec les LLM), comme Workers AI, sont potentiellement vulnérables.
Cette méthode nécessite que l'acteur malveillant se trouve sur le même réseau ou qu'il soit en mesure d'observer le trafic de communication, et sa précision dépend de la connaissance du style d'écriture du LLM cible. Dans des conditions idéales, les chercheurs affirment que leur système « peut reconstruire 29 % des réponses d'un assistant IA et déduire avec succès le sujet à partir de 55 % de ces réponses ». Il est également important de noter que, contrairement à d'autres attaques par canal auxiliaire, dans ce cas, l'acteur malveillant n'a aucun moyen d'évaluer sa prédiction par rapport à « la réalité du terrain ». Cela signifie que nous avons autant de chances d'obtenir une phrase avec une précision quasi-parfaite que d'obtenir une phrase dans laquelle les seuls éléments correspondants sont des conjonctions.
Atténuation des attaques par canal auxiliaire contre les LLM
Puisque ce type d'attaque repose sur la longueur du jeton déduit du paquet, il peut être tout aussi facilement atténué en dissimulant la taille du jeton. Les chercheurs ont suggéré quelques stratégies pour atténuer ces attaques par canal auxiliaire, dont l'une est la plus simple : le remplissage des réponses avec du bruit de longueur aléatoire, afin de masquer la longueur du jeton et ainsi, empêcher que les réponses puissent être déduites du paquet. Bien que nous ayons immédiatement ajouté la solution d'atténuation à notre produit d'inférence, Workers AI, nous voulions aider les clients à sécuriser leurs LLM, quel que soit l'endroit où ils les exécutent, en l'ajoutant à notre solution AI Gateway.
À compter d'aujourd'hui, tous les utilisateurs de Workers AI et d'AI Gateway sont automatiquement protégés contre cette attaque par canal auxiliaire.
Ce que nous avons fait
Lorsque nous avons eu connaissance de ce travail de recherche et de la manière dont l'exploitation de cette technique pourrait potentiellement affecter nos produits d'IA, nous avons fait ce que nous faisons toujours dans des situations comme celle-ci : nous avons réuni une équipe d'ingénieurs système, d'ingénieurs en sécurité et de responsables produits et nous avons commencé à examiner les stratégies d'atténuation des risques et les étapes suivantes. Nous avons également organisé une conférence avec les chercheurs, qui ont eu l'amabilité de participer, de nous présenter leurs conclusions et de répondre aux questions de nos équipes.
L'équipe de recherche a fourni un notebook de test, que nous avons pu utiliser pour valider les résultats de l'attaque. Nous avons pu reproduire les résultats associés aux exemples contenus dans le notebook ; toutefois, nous avons constaté que lors de nos tests, la précision variait considérablement lorsque nous utilisions différents LLM et différentes réponses aux commandes. Néanmoins, l'article a du mérite, et les risques ne sont pas négligeables.
Nous avons décidé d'intégrer la première suggestion d'atténuation contenue dans le document : l'inclusion d'informations de remplissage aléatoires à chaque message, afin de masquer la longueur réelle des jetons dans le flux, ce qui compliquera les tentatives de déduction d'informations reposant uniquement sur la taille des paquets réseau.
Workers AI, notre produit d'inférence, est désormais protégé
Grâce à notre produit d'inférence en tant que service, n'importe qui peut utiliser la plateforme Workers AI et exécuter des appels d'API vers nos modèles IA pris en charge. Cela signifie que nous supervisons les requêtes d'inférence transmises aux modèles et depuis ceux-ci. À ce titre, nous avons la responsabilité de veiller à ce que le service soit sécurisé et protégé contre les vulnérabilités potentielles. Nous avons immédiatement déployé un correctif dès que nous avons été informés de cette étude, et tous les clients utilisateurs de Workers AI sont désormais automatiquement protégés contre cette attaque par canal auxiliaire. En dehors des tests éthiques réalisés par les chercheurs, nous n'avons observé aucune attaque malveillante exploitant cette vulnérabilité.
Notre solution pour Workers AI est une variante de la stratégie d'atténuation suggérée dans le document de recherche. Puisque nous diffusons en continu des objets JSON, plutôt que le jeton brut, au lieu de remplir le jeton avec des caractères d'espaces blancs, nous avons ajouté une nouvelle propriété, « p » (comme « padding », c'est-à-dire « remplissage »), qui a une valeur de chaîne de longueur aléatoire variable.
Exemple de réponse en continu utilisant la syntaxe SSE :
data: {"response":"portugal","p":"abcdefghijklmnopqrstuvwxyz0123456789a"}
data: {"response":" is","p":"abcdefghij"}
data: {"response":" a","p":"abcdefghijklmnopqrstuvwxyz012"}
data: {"response":" southern","p":"ab"}
data: {"response":" European","p":"abcdefgh"}
data: {"response":" country","p":"abcdefghijklmno"}
data: {"response":" located","p":"abcdefghijklmnopqrstuvwxyz012345678"}
Cette approche présente l'avantage qu'aucune modification du SDK ou du code client n'est requise, que les modifications sont invisibles pour les utilisateurs finaux et qu'aucune action n'est nécessaire de la part de nos clients. En ajoutant une longueur de variable aléatoire aux objets JSON, nous introduisons la même variation au niveau du réseau, et l'acteur malveillant perd essentiellement le signal d'entrée requis. Les clients peuvent continuer à utiliser Workers AI comme ils le font habituellement, tout en bénéficiant de cette protection.
Un pas de plus : AI Gateway protège les utilisateurs de tous les fournisseurs d'inférence
Nous avons ajouté une protection à notre produit d'inférence IA, mais nous disposons également d'un produit qui transmet en proxy les requêtes adressées à n'importe quel fournisseur : AI Gateway. AI Gateway se comporte comme un proxy entre un utilisateur et les fournisseurs d'inférence pris en charge, aidant ainsi les développeurs à améliorer le contrôle, les performances et l'observabilité de leurs applications IA. Conformément à notre mission visant à bâtir un Internet meilleur, nous voulions rapidement déployer un correctif qui aiderait tous nos clients utilisant des IA de génération de texte, indépendamment de leur fournisseur ou de la présence de mesures d'atténuation permettant de prévenir cette attaque. À cette fin, nous avons mis en œuvre une solution similaire, permettant d'ajouter un bruit aléatoire de longueur variable à toutes les réponses diffusées en continu traitées en proxy par l'intermédiaire d'AI Gateway.
Nos clients utilisateurs d'AI Gateway sont désormais automatiquement protégés contre cette attaque par canal auxiliaire, même si les fournisseurs d'inférence en amont n'ont pas encore atténué la vulnérabilité. Si vous n'êtes pas sûr que votre fournisseur d'inférence ait encore corrigé cette vulnérabilité, utilisez AI Gateway pour transmettre vos requêtes en proxy et vous assurer d'être protégé.
Conclusion
Chez Cloudflare, notre mission est de contribuer à construire un Internet meilleur ; nous nous préoccupons donc de tous les citoyens d'Internet, quelle que soit leur pile technologique. Nous sommes fiers de pouvoir améliorer la sécurité de nos produits basés sur l'IA avec fluidité, sans nécessiter d'action de la part de nos clients.
Nous sommes reconnaissants aux chercheurs qui ont découvert cette vulnérabilité et se sont montrés très coopératifs en nous aidant à mieux comprendre le problème. Si vous êtes un chercheur en sécurité et vous souhaitez nous aider à rendre nos produits plus sûrs, consultez notre programme de primes aux bugs à l'adresse hackerone.com/cloudflare.