


El tiempo vuela. La vulnerabilidad Heartbleed fue descubierta hace poco más de cinco años y medio. Heartbleed se convirtió en un nombre familiar, no solo porque fue uno de los primeros errores de programación con su propia página web y logotipo, sino por lo que reveló sobre la fragilidad de Internet como un conjunto. Con Heartbleed, un pequeño error en una biblioteca de criptografía expuso los datos personales de los usuarios de casi todos los sitios web en línea .
{kind=link}
Heartbleed es un ejemplo de una clase menos apreciada de errores: vulnerabilidades de divulgación de memoria remota. Los ejemplos de alto perfil distintos a Heartbleed incluyen Cloudbleed y más recientemente, NetSpectre. Estas vulnerabilidades permiten a los atacantes extraer secretos de los servidores simplemente enviándoles paquetes especialmente diseñados. Cloudflare completó recientemente un proyecto de varios años para hacer que nuestra plataforma sea más resistente contra este tipo de error.
Durante los últimos cinco años, la industria ha estado lidiando con las consecuencias del diseño que llevó a Heartbleed a ser tan impactante. En esta entrada del blog profundizaremos en la seguridad de la memoria y en cómo rediseñamos el producto principal de Cloudflare para proteger las claves privadas del próximo Heartbleed.
Divulgación de la memoria
La seguridad perfecta no es posible para las empresas con un componente en línea. La historia nos ha demostrado que no importa cuán robusto sea su programa de seguridad, un exploit inesperado puede dejar a una empresa totalmente expuesta. Uno de los incidentes recientes más famosos de este tipo es Heartbleed, una vulnerabilidad en una biblioteca de criptografía de uso común llamada OpenSSL que expuso los detalles internos de millones de servidores web a cualquier persona con conexión a Internet. Heartbleed fue noticia internacional, causó daños por millones de dólares y aún no se ha resuelto por completo.
Los servicios web típicos solo devuelven datos a través de interfaces públicas bien definidas llamadas API. Los clientes no suelen ver lo que sucede debajo de la cubierta dentro del servidor, eso sería un gran riesgo para la privacidad y la seguridad. Heartbleed rompió ese paradigma: permitió a cualquier persona en Internet tener acceso para echar un vistazo a la memoria operativa utilizada por los servidores web, revelando datos privilegiados que generalmente no están expuestos a través de la API. Heartbleed podría usarse para extraer el resultado de datos anteriores enviados al servidor, incluidas contraseñas y tarjetas de crédito. También podría revelar el funcionamiento interno y los secretos criptográficos utilizados dentro del servidor, incluidas las claves privadas del certificado TLS.
Heartbleed dejó que los atacantes se asomaran detrás de la cortina, pero no muy lejos. Se podían extraer datos confidenciales, pero no todo en el servidor estaba en riesgo. Por ejemplo, Heartbleed no permitió a los atacantes robar el contenido de las bases de datos almacenadas en el servidor. La pregunta sería: ¿por qué algunos datos estaban en riesgo, pero otros no? La razón tiene que ver con cómo se construyen los sistemas operativos modernos.
Una visión simplificada del aislamiento del proceso
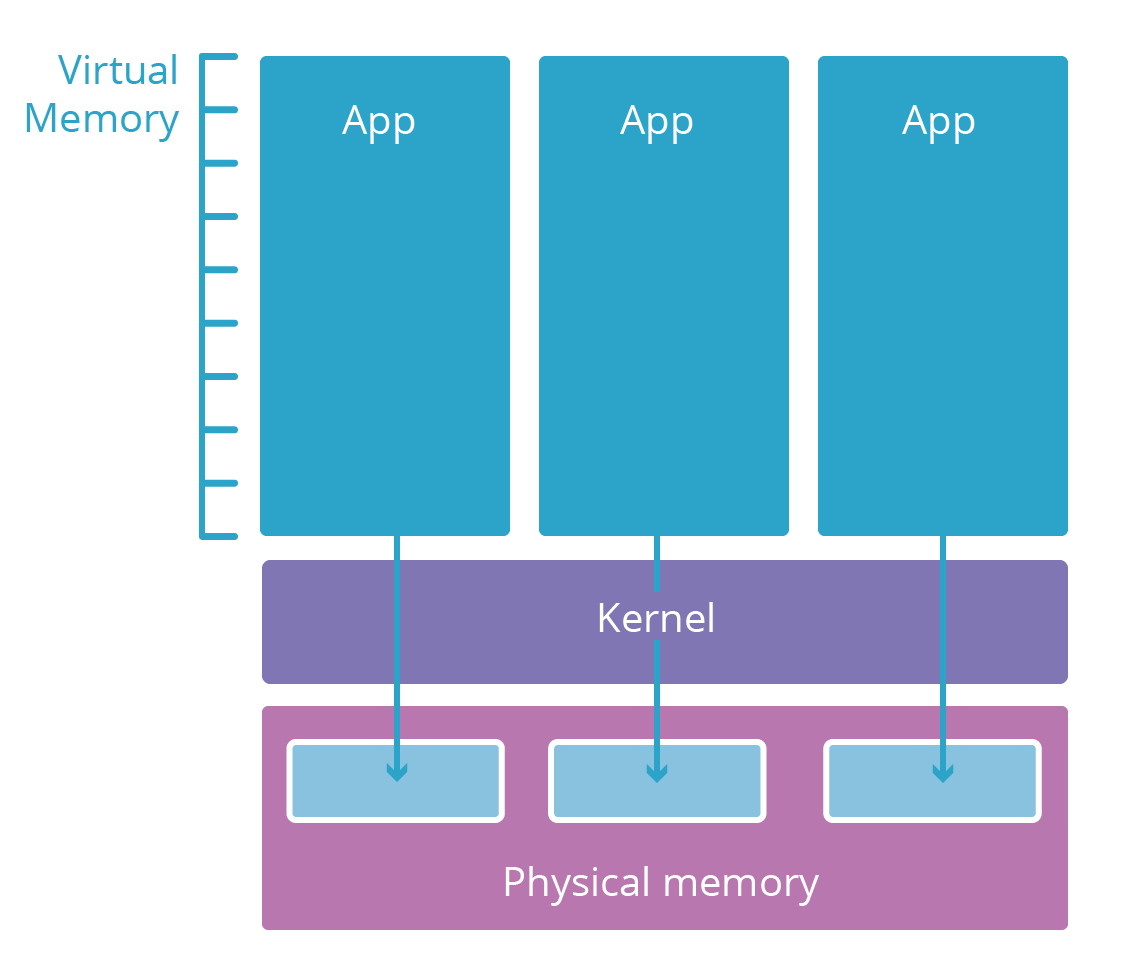
La mayoría de los sistemas operativos modernos se dividen en varias capas. Estas capas son análogas a los niveles de autorización de seguridad. Las llamadas aplicaciones de espacio de usuario (como su navegador) suelen vivir en una capa de baja seguridad denominada espacio de usuario. Solo tienen acceso a recursos informáticos (memoria, CPU, redes) si las capas inferiores y con más credenciales lo permiten.
Las aplicaciones de espacio de usuario necesitan recursos para funcionar. Por ejemplo, necesitan memoria para almacenar su código y memoria de trabajo para hacer cálculos. Sin embargo, sería arriesgado dar a una aplicación acceso directo a la RAM física del equipo en el que se está ejecutando. En cambio, los elementos informáticos sin procesar están restringidos a una capa inferior llamada núcleo del sistema operativo. El núcleo solo ejecuta aplicaciones especialmente diseñadas para administrar de manera segura estos recursos y mediar el acceso a ellos para aplicaciones de espacio de usuario.
Cuando se inicia un nuevo proceso de aplicación de espacio de usuario, el núcleo le da un espacio de memoria virtual. Este espacio de memoria virtual actúa como memoria real para la aplicación, pero en realidad es una capa de traducción protegida de forma segura que el núcleo utiliza para proteger la memoria real. El espacio de memoria virtual de cada aplicación es como un universo paralelo dedicado a esa aplicación. Esto hace que sea imposible para un proceso ver o modificar otros, las otras aplicaciones simplemente no son direccionables.
Heartbleed, Cloudbleed y el límite del proceso
Heartbleed era una vulnerabilidad en la biblioteca OpenSSL, que formaba parte de muchas aplicaciones de servidor web. Estos servidores web se ejecutan en el espacio del usuario, como cualquier aplicación común. Esta vulnerabilidad causó que el servidor web devolviera hasta 2 kilobytes de su memoria en respuesta a una solicitud de entrada especialmente diseñada.
Cloudbleed también fue un error de divulgación de memoria, aunque fue específico de Cloudflare, que recibió su nombre porque era muy similar a Heartbleed. Con Cloudbleed, la vulnerabilidad no estaba en el OpenSSL, sino en una aplicación de servidor web secundario utilizada para el análisis HTML. Cuando este código analizó una cierta secuencia de HTML, terminó insertando cierta memoria de proceso en la página web que estaba sirviendo.
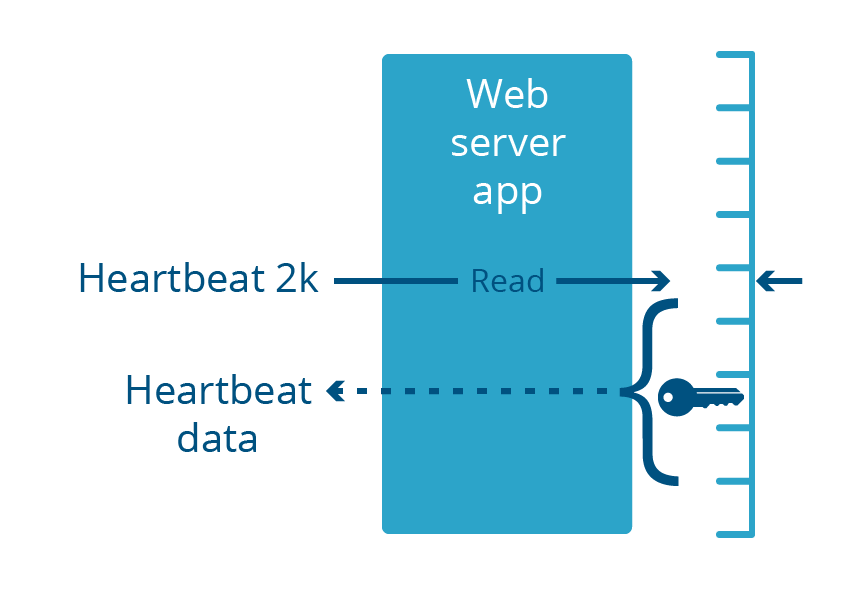
Es importante tener en cuenta que ambos errores se produjeron en aplicaciones que se ejecutan en el espacio de usuario y no en el espacio del núcleo. Esto significa que la memoria expuesta por el error era necesariamente parte de la memoria virtual de la aplicación. Incluso si el error expusiera megabytes de datos, solo lo haría con datos específicos de esa aplicación, no otras aplicaciones del sistema.
Para que un servidor web sirva el tráfico a través del protocolo HTTPS encriptado, necesita acceso a la clave privada del certificado, que, por lo general, se mantiene en la memoria de la aplicación. Heartbleed expuso estas claves a Internet. La vulnerabilidad Cloudbleed afectó a un proceso diferente, el analizador HTML, que no realiza HTTPS y, por lo tanto, no mantiene la clave privada en la memoria. Esto significaba que las claves HTTPS eran seguras, incluso si otros datos en el espacio de memoria del analizador HTML no lo estaban.
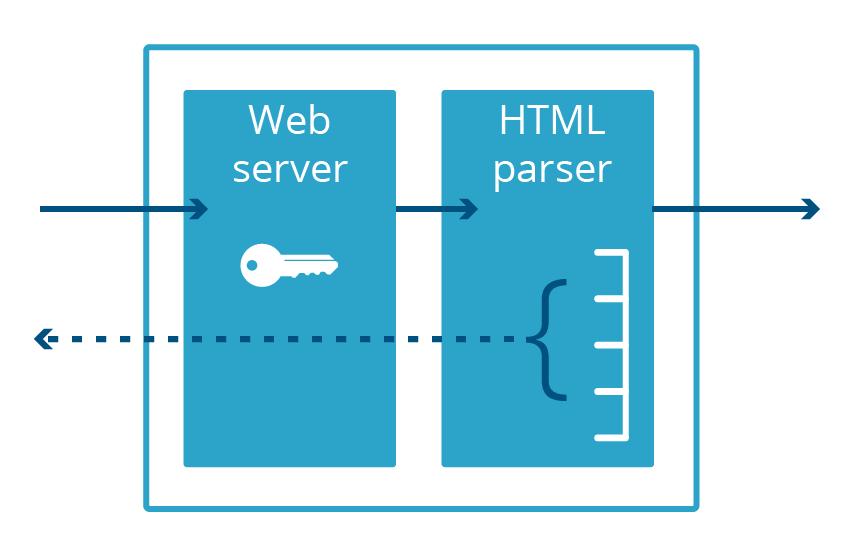
El hecho de que el analizador HTML y el servidor web fueran aplicaciones diferentes nos evitó tener que revocar y volver a emitir los certificados TLS de nuestros clientes. Sin embargo, si se descubre otra vulnerabilidad de divulgación de memoria en el servidor web, estas claves vuelven a estar en riesgo.
Sacar las claves de los procesos orientados a Internet
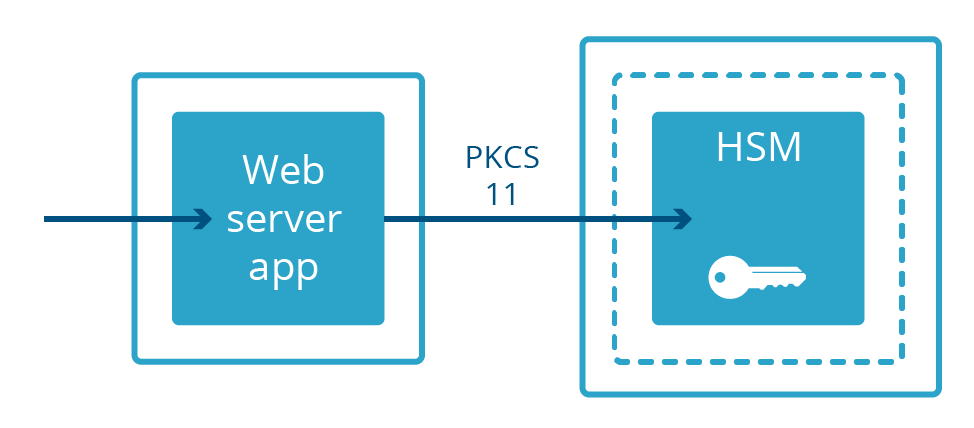
No todos los servidores web mantienen claves privadas en la memoria . En algunas implementaciones, las claves privadas se guardan en una máquina separada llamada módulo de seguridad de hardware (Hardware Security Module, HSM). Los HSM están diseñados para resistir la intrusión física y la manipulación y, a menudo, para cumplir con los estrictos requisitos de cumplimiento. Con frecuencia pueden ser voluminosos y costosos. Los servidores web diseñados para aprovechar las claves en un HSM se conectan a ellos a través de un cable físico y se comunican con un protocolo especializado llamado PKCS # 11. Esto permite que el servidor web sirva contenido cifrado mientras está físicamente separado de la clave privada.
En Cloudflare, creamos nuestra propia manera de separar un servidor web de una clave privada: Keyless SSL. En lugar de mantener las claves en una máquina física separada conectada al servidor con un cable, las claves se guardan en un servidor de claves operado por el cliente en su propia infraestructura (esto también puede ser respaldado por un HSM).
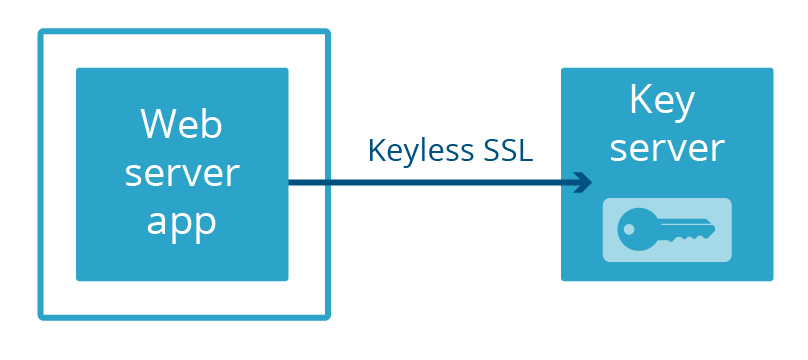
Más recientemente, lanzamos Geo Key Manager, un servicio que permite a los usuarios almacenar claves privadas solo en ubicaciones seleccionadas de Cloudflare. Las conexiones a ubicaciones que no tienen acceso a la clave privada utilizan SSL sin clave con un servidor de claves alojado en un centro de datos que sí tiene acceso.
Tanto en Keyless SSL como en Geo Key Manager, las claves privadas no solo no son parte del espacio de memoria del servidor web, ¡a menudo ni siquiera están en el mismo país! Este grado extremo de separación no es necesario para proteger contra el próximo Heartbleed. Todo lo que se necesita es que el servidor web y el servidor de claves no formen parte de la misma aplicación. Así que eso fue lo que hicimos. A esto lo llamamos Keyless Everywhere.
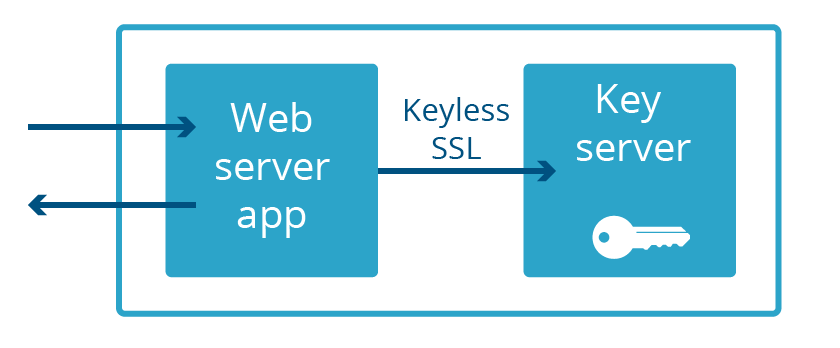
Keyless SSL viene del interior de la casa
La reutilización de Keyless SSL para claves privadas controladas por Cloudflare fue fácil de conceptualizar, pero el camino desde la creación hasta la producción no fue tan sencillo. La funcionalidad principal de Keyless SSL proviene del código abierto gokeyless, que los clientes ejecutan en su infraestructura, pero internamente lo usamos como una biblioteca y hemos reemplazado el paquete principal con una implementación adecuada a nuestros requisitos (lo hemos denominado creativamente gokeyless-internal, en español sin clave interna).
Al igual que con todos los cambios importantes en la arquitectura, es prudente comenzar probando el modelo con algo nuevo y de bajo riesgo. En nuestro caso, el banco de pruebas fue nuestra implementación experimental TLS 1.3. Con el fin de iterar rápidamente a través de versiones preliminares de la especificación TLS y hacer lanzamientos sin afectar a la mayoría de los clientes de Cloudflare, reescribimos nuestro servidor web nginx personalizado en Go y lo implementamos en paralelo a nuestra infraestructura existente. Este servidor fue diseñado para nunca tener claves privadas desde el principio y solo aprovecha gokeyless-internal. En este momento, solo había una pequeña cantidad de tráfico TLS 1.3 y todo provenía de las versiones beta de los navegadores, lo que nos permitió trabajar a través de los problemas iniciales de gokeyless-internal sin exponer a la mayoría de los visitantes a riesgos de seguridad o interrupciones debidas a gokeyless-internal.
El primer paso para hacer que TLS 1.3 sea completamente keyless (sin clave) fue identificar e implementar la nueva funcionalidad que necesitábamos agregar a gokeyless-internal. Keyless SSL se diseñó para ejecutarse en la infraestructura del cliente, con la expectativa de admitir solo un puñado de claves privadas. Pero nuestro acceso debe admitir simultáneamente millones de claves privadas, por lo que implementamos la misma lógica de carga diferida que usamos en nuestro servidor web, nginx. Además, una implementación típica del cliente tendría el soporte de un equilibrador de carga de red para los servidores de claves, por lo que podría ponerse fuera de servicio para actualizaciones u otras tareas de mantenimiento. Compara esto con nuestro perímetro, donde es importante maximizar nuestros recursos al prestar el servicio de tráfico durante las actualizaciones de software. Este problema se resuelve con el excelente paquete tableflip que utilizamos en otros lugares de Cloudflare.
El siguiente proyecto de acceso sin clave fue Spectrum, que se lanzó con soporte predeterminado para gokeyless-internal. Tras estas pequeñas victorias, tuvimos la confianza necesaria para intentar el gran desafío, que consistía en migrar nuestra infraestructura nginx existente a un modelo sin ningún tipo de clave. Después de implementar la nueva funcionalidad, y de estar satisfechos con nuestras pruebas de integración, todo lo que queda es activar esto y detener el problema, ¿verdad? Toda persona con experiencia en grandes sistemas conoce la diferencia entre “trabajo en desarrollo” y “finalizado”, y esto no es diferente. Afortunadamente, anticipamos los problemas y desarrollamos una función de retroceso en nginx para completar el protocolo de enlace en sí, si se encontrara algún problema en la ruta de acceso de gokeyless-internal. Esto nos permitió exponer gokeyless-internal al tráfico de producción sin riesgo de inactividad en el caso de que nuestra reimplementación de la lógica nginx no estuviera 100 % libre de errores.
Cuando revertir el código no revierte el problema
Nuestro plan de implementación era habilitar Keyless Everywhere, encontrar las causas más comunes de los retrocesos y solucionarlos. Luego podríamos repetir este proceso hasta que se eliminaran todas las causas de retrocesos, después de lo cual podríamos eliminar el acceso a las claves privadas (y por lo tanto el retroceso) de nginx. Una de las primeras causas de los retrocesos era el error recurrente de gokeyless-internal ErrKeyNotFound, que indica que no se pudo encontrar la clave privada solicitada en el almacenamiento. Esto no debería haber sido posible, ya que nginx solo hace una solicitud a gokeyless-internal después de encontrar el certificado y el par de claves almacenadas, y siempre escribimos juntos la clave privada y el certificado. Resultó que, además de devolver el mensaje de error para el caso previsto de la clave no encontrada, también lo estábamos devolviendo cuando se encontraron errores pasajeros como tiempos de espera. Para resolver este problema, actualizamos esas condiciones de error pasajero para devolver ErrInternal e implementarlos en nuestros centros de datos de valores controlados (canary). Curiosamente, descubrimos que una serie de instancias en un único centro de datos comenzaron a encontrar altas tasas de retrocesos, y los registros de nginx indicaron que se debía a un tiempo de espera entre nginx y gokeyless-internal. Los tiempos de espera no se produjeron de inmediato, pero una vez que un sistema comenzó a registrar tiempos de espera nunca se detuvo. Incluso después de revertir el lanzamiento, los retrocesos continuaron con la versión anterior del software. Además, mientras nginx se quejaba de los tiempos de espera, gokeyless-internal parecía en perfecto estado e informaba métricas de rendimiento razonables (latencia de solicitud media de menos milisegundos).
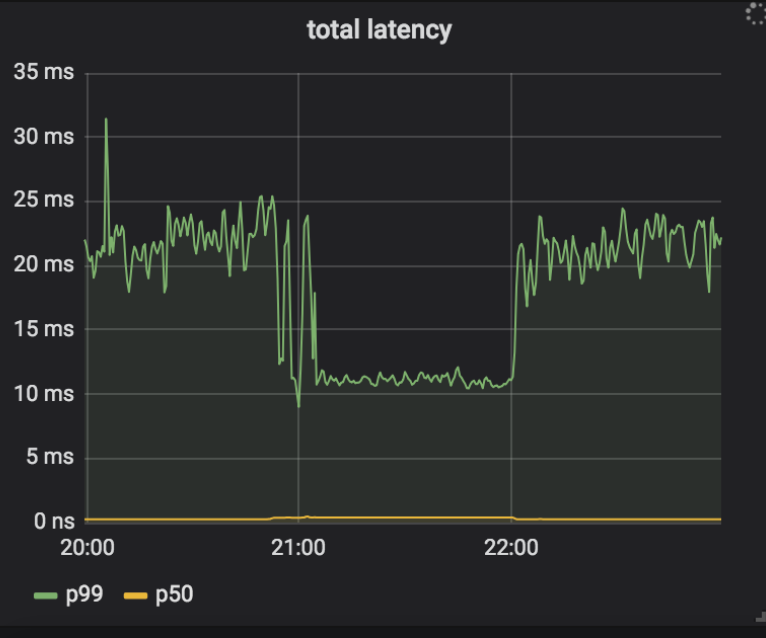
Para eliminar el problema, agregamos el registro detallado a nginx y gokeyless, y remontamos la cadena de sucesos hacia atrás una vez que se encontraron los tiempos de espera.
➜ ~ grep 'timed out' nginx.log | grep Keyless | head -5
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015157 Keyless SSL request/response timed out while reading Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015231 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015271 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:49.000 29m41 2018/07/25 05:30:49 [error] 4525#0: *1015280 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
2018-07-25T05:30:50.000 29m41 2018/07/25 05:30:50 [error] 4525#0: *1015289 Keyless SSL request/response timed out while waiting for Keyless SSL response, keyserver: 127.0.0.1
Puedes observar que la primera solicitud para registrar un tiempo de espera tenía la identificación 1015157. También resulta interesante que la primera línea de registro fue "timed out while reading" (se agotó el tiempo de espera de lectura), pero todas las demás son "timed out while waiting" (se agotó el tiempo de espera), y este último mensaje es el que continúa para siempre. Aquí está la solicitud que coincide con el registro gokeyless:
➜ ~ grep 'id=1015157 ' gokeyless.log | head -1
2018-07-25T05:30:39.000 29m41 2018/07/25 05:30:39 [DEBUG] connection 127.0.0.1:30520: worker=ecdsa-29 opcode=OpECDSASignSHA256 id=1015157 sni=announce.php?info_hash=%a8%9e%9dc%cc%3b1%c8%23%e4%93%21r%0f%92mc%0c%15%89&peer_id=-ut353s-%ce%ad%5e%b1%99%06%24e%d5d%9a%08&port=42596&uploaded=65536&downloaded=0&left=0&corrupt=0&key=04a184b7&event=started&numwant=200&compact=1&no_peer_id=1 ip=104.20.33.147
¡Ajá! Claramente, ese valor de identificación de nombre de servidor (SNI) es inválido (las SNI son como encabezados de host, es decir, son dominios, no rutas de URL), y también es bastante largo. Nuestro sistema de almacenamiento indexa certificados en función de dos índices: según la SNI a la que corresponden y según las direcciones IP a las que corresponden (para clientes más antiguos que no son compatibles con la SNI). Nuestra interfaz de almacenamiento utiliza el protocolo memcached, y la biblioteca del cliente que utiliza gokeyless-internal rechaza las solicitudes de claves de más de 250 caracteres (longitud máxima de clave de memcached), mientras que la lógica nginx es simplemente ignorar la SNI no válida y tratar la solicitud como si solo tuviera una IP. El cambio en nuestra nueva versión había cambiado esta condición de ErrKeyNotFound a ErrInternal, lo que desencadenó problemas en cascada en nginx. Los "tiempos de espera" en realidad se produjeron al descartar todas las solicitudes en proceso multiplexadas en una conexión que hizo que ErrInternalfor devolviera una sola solicitud. Estas solicitudes se reintentaron, pero una vez que se activó esta condición, nginx se sobrecargó por la cantidad de solicitudes reintentadas más la secuencia continua de solicitudes nuevas que llegan con la SNI incorrecta y sin posibilidad de recuperarse. Esto explica por qué revertir gokeyless-internal no solucionó el problema.
Finalmente, este descubrimiento concentró nuestra atención en nginx, que hasta ahora no se había considerado como el causante del problema, ya que había funcionado de manera confiable con los servidores de claves de los clientes durante años. Sin embargo, la comunicación a través del localhost a un servidor de claves de múltiples usuarios es fundamentalmente diferente a la conexión a través de la Internet pública para comunicarse con un servidor de claves del cliente. Debemos hacer los siguientes cambios:
- En lugar de un tiempo de espera de conexión largo y un tiempo de espera de respuesta relativamente corto para los servidores de claves del cliente, los tiempos de espera de conexión sumamente cortos y los tiempos de espera de solicitud más largos son adecuados para un servidor de claves de localhost.
- De manera similar, resulta razonable reintentar (con retardo) si se agota el tiempo de espera para una respuesta del servidor de claves del cliente, ya que no podemos confiar en la red. Pero mediante localhost, solo se produciría un tiempo de espera si se sobrecargara gokeyless-internal y la solicitud siguiera en la cola esperando su procesamiento. En este caso, un reintento solamente haría que se solicite un trabajo más completo de gokeyless-internal, lo que empeoraría la situación.
- Lo que es más importante, nginx no debe descartar todas las solicitudes multiplexadas en una conexión si alguna de estas encuentra un error, ya que una sola conexión ya no representa a un solo cliente.
Las implementaciones son importantes
La CPU en el perímetro es uno de nuestros activos más preciados, y está celosamente protegida por nuestro equipo de rendimiento (también conocido como vigilancia de CPU). Poco después de activar Keyless Everywhere en uno de nuestros centros de datos de valores controlados (canary), se advirtió que gokeyless utiliza aproximadamente el 50 % de un núcleo por instancia. Estábamos cambiando las operaciones de suscripción de nginx a gokeyless, por lo tanto, es lógico que ahora se utilice más CPU. Pero nginx debería haber experimentado una reducción proporcional en el uso de CPU, ¿verdad?
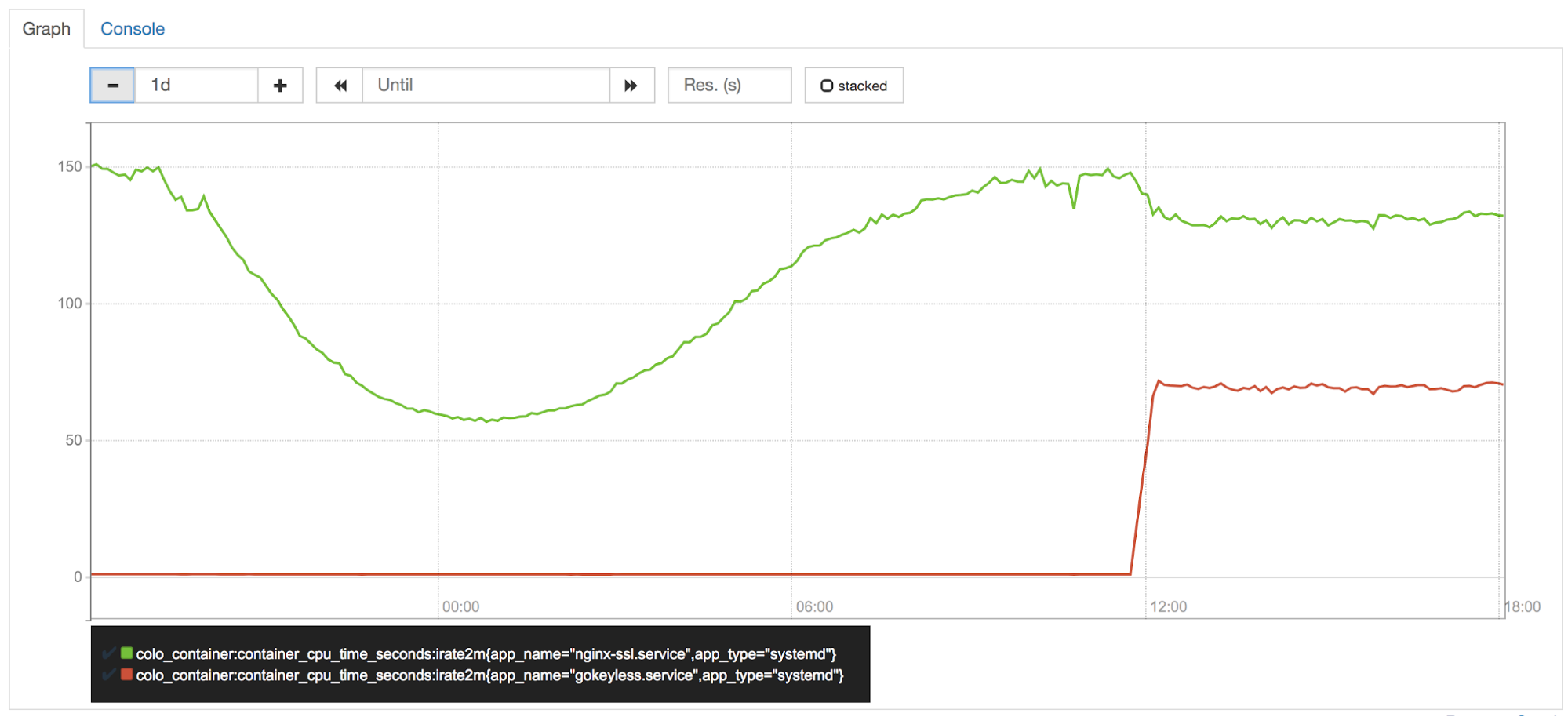
Incorrecto. Las operaciones de curva elíptica son muy rápidas en Go, pero se sabe que lasoperaciones RSA son mucho más lentas que sus equivalentes de BoringSSL.
Si bien Go 1.11 incluye optimizaciones para las operaciones matemáticas RSA, necesitábamos más velocidad. Se necesita un código de ensamblado bien sintonizado para que coincida con el rendimiento de BoringSSL. Para esto, Armando Faz de nuestro equipo de criptografía ayudó a recuperar parte de la CPU mediante la reimplementación de partes del paquete demath/big con ensamblado que depende de la plataforma en una bifurcación interna de Go. La reciente política de ensamblado de Go prefiere el uso del código portátil de Go en lugar del ensamblado, por lo tanto, estas optimizaciones no se cargaron. Aún hay margen para más optimizaciones, y por esa razón todavía estamos considerando la posibilidad de pasar a cgo + BoringSSL para las operaciones de suscripción, pese a que cgo presenta varias desventajas.
Cómo cambiar nuestras herramientas
El aislamiento de procesos es una herramienta poderosa para proteger los secretos en la memoria. Nuestro cambio a Keyless Everywhere demuestra que esta no es una herramienta fácil de aprovechar. El rediseño de un sistema existente como nginx para usar el aislamiento de procesos con el fin de proteger los secretos fue lento y difícil. Otro enfoque para proteger la seguridad de la memoria es utilizar un lenguaje de programación seguro como Rust.
Rust fue desarrollado originalmente por Mozilla, pero se está empezando a utilizar a mucho mayor escala. La principal ventaja de Rust con respecto a C/ C ++ es que tiene características de seguridad de memoria sin un recolector de elementos no utilizados.
Volver a escribir una aplicación existente en un nuevo lenguaje como Rust es una tarea desalentadora. Dicho esto, varias nuevas características de Cloudflare, desde las potentes funciones de las reglas de firewall hasta nuestro 1.1.1.1 con la aplicación WARP, se han escrito con el lenguaje de programación Rust para aprovechar sus potentes propiedades de seguridad de memoria. Hasta ahora estamos muy satisfechos con Rust y pensamos ampliar su uso en el futuro
Conclusión
La industria aprendió una lección a raíz de las terribles consecuencias de Heartbleed que deberían haber sido obvias si lo analizamos en retrospectiva: guardar secretos importantes en aplicaciones a las que se puede acceder de manera remota a través de Internet es una práctica de seguridad arriesgada. En los años siguientes, con mucho trabajo, aprovechamos la separación de procesos y Keyless SSL para garantizar que el próximo Heartbleed no ponga en riesgo las claves de los clientes.
Sin embargo, esta no es la solución definitiva. Recientemente, se han descubierto vulnerabilidades de divulgación de memoria como NetSpectre que pueden eludir los límites del proceso de aplicación, por lo tanto, seguimos investigando para encontrar nuevas formas de mantener la seguridad de las claves.
