
This post describes how to use Cloudflare's IPFS gateway to set up a website which is end-to-end secure, while maintaining the performance and reliability benefits of being served from Cloudflare’s edge network. If you'd rather read an introduction to the concepts behind IPFS first, you can find that in our announcement. Alternatively, you could skip straight to the developer docs to learn how to set up your own website.
By 'end-to-end security', I mean that neither the site owner nor users have to trust Cloudflare to serve the correct documents, like they do now. This is similar to how using HTTPS means you don't have to trust your ISP to not modify or inspect traffic.
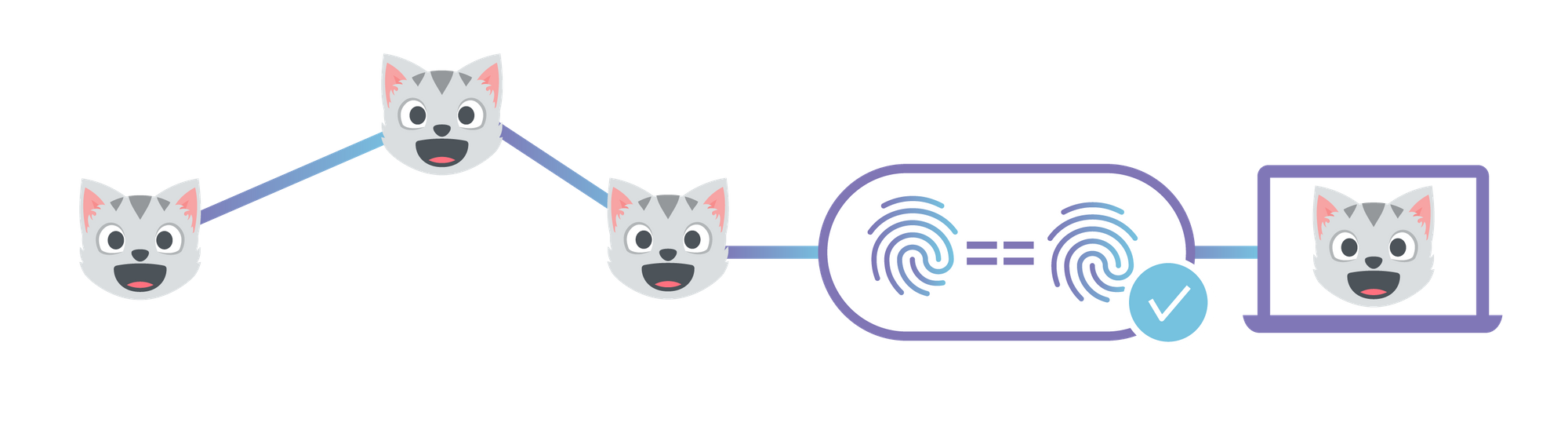
CNAME Setup with Universal SSL
The first step is to choose a domain name for your website. Websites should be given their own domain name, rather than served directly from the gateway by root hash, so that they are considered a distinct origin by the browser. This is primarily to prevent cache poisoning, but there are several functional advantages as well. It gives websites their own instance of localStorage and their own cookie jar which are sandboxed from inspection and manipulation by malicious third-party documents. It also lets them run Service Workers without conflict, and request special permissions of the user like access to the webcam or GPS. But most importantly, having a domain name makes a website easier to identify and remember.
Now that you've chosen a domain, rather than using it as-is, you’ll need to add "ipfs-sec" as the left-most subdomain. So for example, you'd use "ipfs-sec.example.com" instead of just "example.com". The ipfs-sec subdomain is special because it signals to the user and to their browser that your website is capable of being served with end-to-end integrity.
In addition to that, ipfs-sec domains require DNSSEC to be properly setup to prevent spoofing. Unlike with standard HTTPS, where DNS spoofing can't usually result in a on-path attacker attack, this is exactly what DNS spoofing does to IPFS because the root hash of the website is stored in DNS. Many registrars make enabling DNSSEC as easy as the push of a button, though some don't support it at all.
With the ipfs-sec domain, you can now follow the developer documentation on how to serve a generic static website from IPFS. Note that you'll need to use a CNAME setup and retain control of your DNS, rather than the easier method of just signing up for Cloudflare. This helps maintain a proper separation between the party managing the DNSSEC signing keys and the party serving content to end-users. Keep in mind that CNAME setups tend to be problematic and get into cases that are difficult to debug, which is why we reserve them for technically sophisticated customers.
You should now be able to access your website over HTTP and HTTPS, backed by our gateway.
Verifying what the Gateway Serves
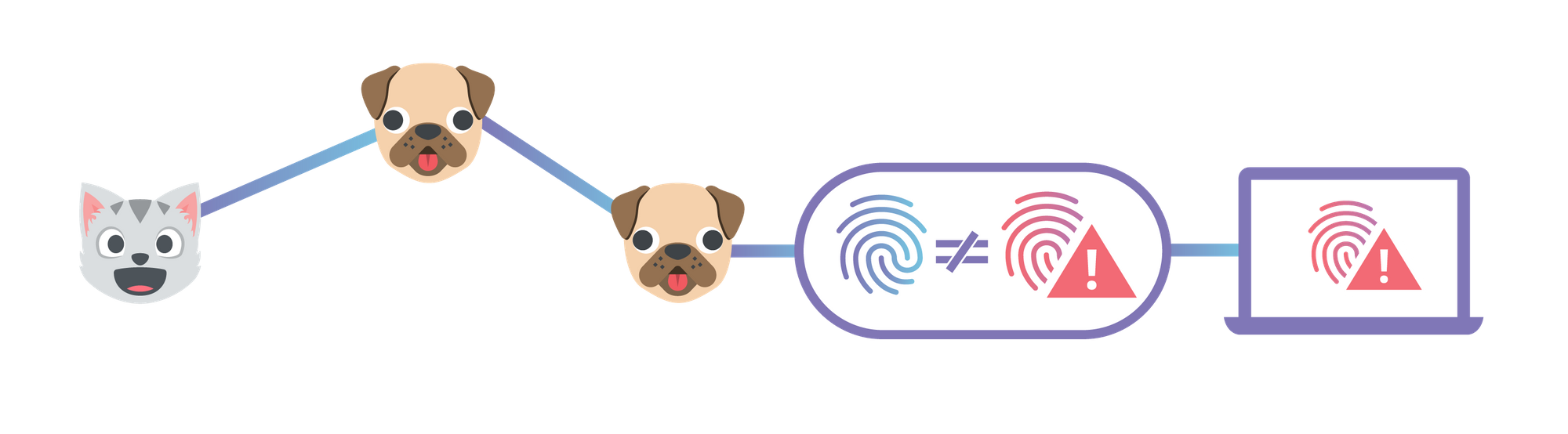
HTTPS helps makes sure that nobody between the user and Cloudflare's edge network has tampered with the connection, but it does nothing to make sure that Cloudflare actually serves the content the user asked for. To solve this, we built two connected projects: a modified gateway service and a browser extension.
First, we forked the go-ipfs repository and gave it the ability to offer cryptographic proofs that it was serving content honestly, which it will do whenever it sees requests with the HTTP header X-Ipfs-Secure-Gateway: 1. The simplest case for this is when users request a single file from the gateway by its hash -- all the gateway has to do is serve the content and any metadata that might be necessary to re-compute the given hash.
A more complicated case is when users request a file from a directory. Luckily, directories in IPFS are just files containing a mapping from file name to the hash of the file, and very large directories can be transparently split up into several smaller files, structured into a search tree called a Hash Array Mapped Trie (HAMT). To convince the client that the gateway is serving the contents of the correct file, the gateway first serves the file corresponding to the directory, or every node in the search path if the directory is a HAMT. The client can hash this file (or search tree node), check that it equals the hash of the directory they asked for, and look up the hash of the file they want from within the directory's contents. The gateway then serves the contents of the requested file, which the client can now verify because it knows the expected hash.
Finally, the most complicated case by far is when the client wants to access content by domain name. It's complicated because the protocol for authenticating DNS, called DNSSEC, has very few client-side implementations. DNSSEC is also not widely deployed, even though some registrars make it even easier than setting up HTTPS. In the end, we ended up writing our own simple DNSSEC-validating resolver that's capable of outputting a cryptographically-convincing proof that it did some lookup correctly.
It works the same way as certificate validation in HTTPS: we start at the bottom, with a signature from some authority claiming to be example.com over the DNS records they want us to serve. We then lookup a delegation (DS record) from an authority claiming to be .com, that says "example.com is the authority with these public keys" which is in turn signed by the .com authority's private key. And finally, we lookup a delegation from the root authority, ICANN (whose public keys we already have), attesting to the public keys used by the .com authority. All of these lookups bundled together form an authenticated chain starting at ICANN and ending at the exact records we want to serve. These constitute the proof.
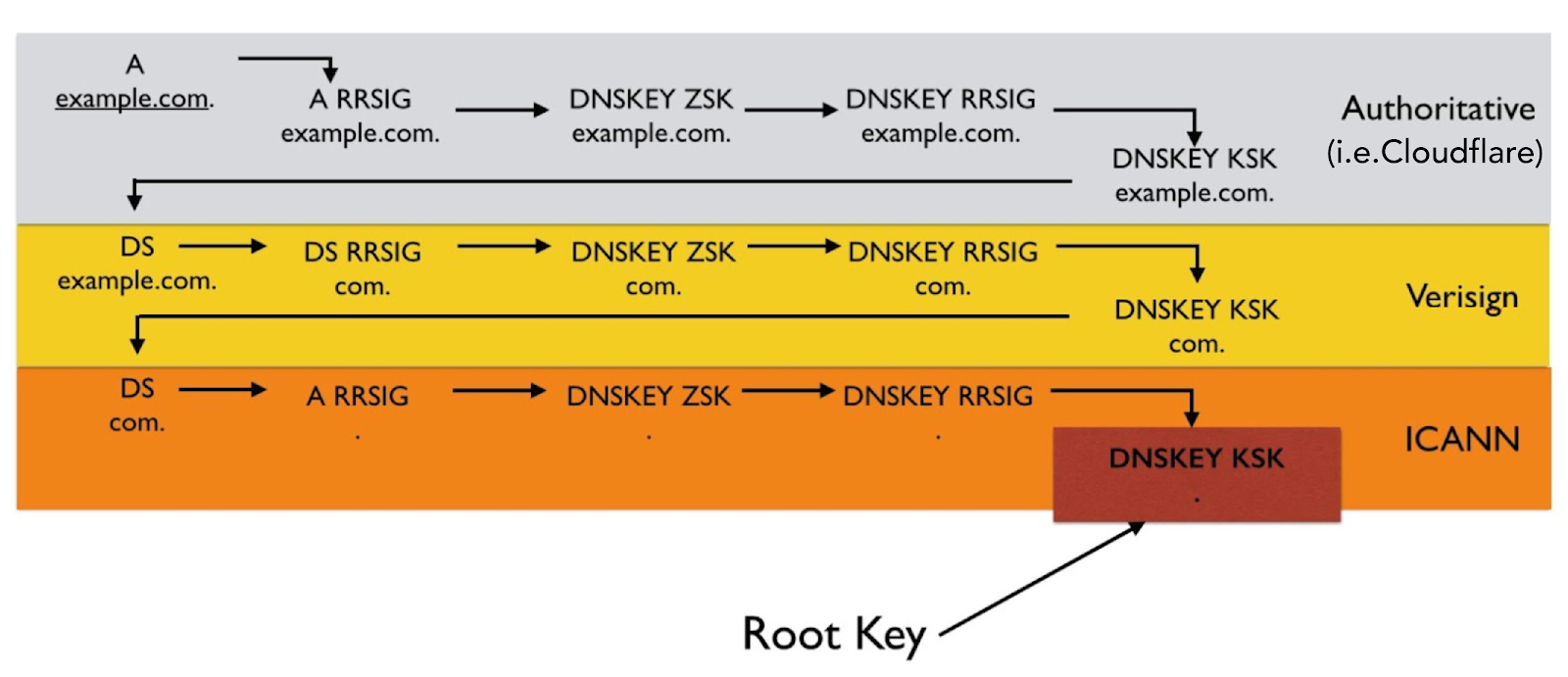
The second project we built out was a browser extension that requests these proofs from IPFS gateways and ipfs-sec domains, and is capable of verifying them. The extension uses the webRequest API to sit between the browser's network stack and its rendering engine, preventing any unexpected data from being show to the user or unexpected code from being executed. The code for the browser extension is available on Github, and can be installed through Firefox's add-on store. We’re excited to add support for Chrome as well, but that can’t move forward until this ticket in their bug tracker is addressed.
On the other hand, if a user doesn't have the extension installed, the gateway won't see the X-Ipfs-Secure-Gateway header and will serve the page like a normal website, without any proofs. This provides a graceful upgrade path to using IPFS, either through our extension that uses a third-party gateway or perhaps another browser extension that runs a proper IPFS node in-browser.
Example Application
My favorite website on IPFS so far has been the mirror of English Wikipedia put up by the IPFS team at Protocol Labs. It's fast, fun to play with, and above all has practical utility. One problem that stands out though, is that the mirror has no search feature so you either have to know the URL of the page you want to see or try to find it through Google. The Turkish-language mirror has in-app search but it requires a call to a dynamic API on the same host, and doesn't work through Cloudflare's gateway because we only serve static content.
I wanted to provide an example of the kinds of secure, performant applications that are possible with IPFS, and this made building a search engine seem like a prime candidate. Rather than steal Protocol Labs' idea of 'Wikipedia on IPFS', we decided to take the Kiwix archives of all the different StackExchange websites and build a distributed search engine on top of that. You can play with the finished product here: ipfs-sec.stackexchange.cloudflare-ipfs.com.
The way it's built is actually really simple, at least as far as search engines go: We build an inverted index and publish it with the rest of each StackExchange, along with a JavaScript client that can read the index and quickly identify documents that are relevant to a user's query. Building the index takes two passes over the data:
- The first pass decides what words/tokens we want to allow users to search by. Tokens shouldn't be too popular (like the top 100 words in English), because then the list of all documents containing that token is going to be huge and it's not going to improve the search results anyways. They also shouldn't be too rare (like a timestamp with sub-second-precision), because then the index will be full of meaningless tokens that occur in only one document each. You can get a good estimate of the most frequent K tokens, using only constant-space, with the really simple space-saving algorithm from this paper.
- Now that the first pass has given us the tokens we want to track, the second pass through the data actually builds the inverted index. That is, it builds a map from every token to the list of documents that contain that token, called a postings list. When a client wants to find only documents that contain some set of words/tokens, they download the list for each individual token and intersect them. It sounds less efficient than it is -- in reality, the postings lists are unnoticeably small (<30kb) even in the worst case. And the browser can 'pipeline' the requests for the postings lists (meaning, send them all off at once) which makes getting a response to several requests about as fast as getting a response to one.
We also store some simple statistics in each postings list to help rank the results. Essentially, documents that contain a query token more often are ranked higher than those that don't. And among the tokens in a query, those tokens that occur in fewer documents have a stronger effect on ranking than tokens that occur in many documents. That's why when I search for "AES SIV" the first result that comes back is:
while the following is the fourth result, even though it has a higher score and greater number of total hits than first result:
(AES is a very popular and frequently discussed encryption algorithm, while SIV is a lesser-known way of using AES.)
But this is what really makes it special: because the search index is stored in IPFS, the user can convince themselves that no results have been modified, re-arranged, or omitted without having to download the entire corpus. There's one small trick to making this statement hold true: All requests made by the search client must succeed, and if they don't, it outputs an error and no search results.
To understand why this is necessary, think about the search client when it first gets the user's query. It has to tokenize the query and decide which postings lists to download, where not all words in the user's query may be indexed. A naive solution is to try to download the postings list for every word unconditionally, and interpret a non-200 HTTP status code as "this postings list must not exist". In this case, a network adversary could block the search client from being able to access postings lists that lead to undesirable results, causing the client to output misleading search results either through omission or re-arranging.
What we do instead is store the dictionary of every indexed token in a file in the root of the index. The client can download the dictionary once, cache it, and use it for every search afterwards. This way, the search client can consult the dictionary to find out which requests should succeed and only send those.
From Here
We were incredibly excited when we realized the new avenues and types of applications that combining IPFS with Cloudflare open up. Of course, our IPFS gateway and the browser extension we built will need time to mature into a secure and reliable platform. But the ability to securely deliver web pages through third-party hosting providers and CDNs is incredibly powerful, and its something cryptographers and internet security professionals have been working towards for a long time. As much fun as we had building it, we're even more excited to see what you build with it.
Subscribe to the blog for daily updates on our announcements.