
This is a guest post by Igor Krestov and Dan Taylor. Igor is a lead software developer at SALT.agency, and Dan a lead technical SEO consultant, and has also been credited with coining the term “edge SEO”. SALT.agency is a technical SEO agency with offices in London, Leeds, and Boston, offering bespoke consultancy to brands around the world. You can reach them both via Twitter.
With this post we illustrate the potential applications of Cloudflare Workers in relation to search engine optimization, which is more commonly referred to as ‘SEO’ using our research and testing over the past year making Sloth.
This post is aimed at readers who are both proficient in writing performant JavaScript, as well as complete newcomers, and less technical stakeholders, who haven’t really written many lines of code before.
Endless practical applications to overcome obstacles
Working with various clients and projects over the years we’ve continuously encountered the same problems and obstacles in getting their websites to a point of “technical SEO excellence”. A lot of these problems come from platform restriction at an enterprise level, legacy tech stacks, incorrect builds, and years of patching together various services and infrastructures.
As a team of technical SEO consultants, we can often be left frustrated by these barriers, that often lead to essential fixes and implementations either being not possible or delayed for months (if not years) at a time – and in this time, the business is often losing traffic and revenue.
Workers offers us a hail Mary solution to a lot of common frustrations in getting technical SEO implemented, and we believe in the long run can become an integral part of overcoming legacy issues, reducing DevOps costs, speeding up lead times, all in addition to utilising a globally distributed serverless platform with blazing fast cold start times.
Creating accessibility at scale
When we first started out, we needed to implement simple redirects, which should be easy to create on the majority of platforms but wasn’t supported in this instance.
When the second barrier arose, we needed to inject Hreflang tags, cross-linking an old multi-lingual website on a bespoke platform build to an outdated spec. This required experiments to find an efficient way of implementing the tags without increasing latency or adding new code to the server – in a manner befitting of search engine crawling.
At this point we had a number of other applications for Workers, with arising need for non-developers to be able to modify and deploy new Worker code. This has since become an idea of Worker code generation, via Web UI or command line.
Having established a number of different use cases for Workers, we identified 3 processing phases:
- Incoming request modification – changing origin request URL or adding authorization headers.
- Outgoing response modification - adding security headers, Hreflang header injection, logging.
- Response body modification – injecting/changing content e.g. canonicals, robots and JSON-LD
We wanted to generate lean Worker code, which would enable us to keep each functionality contained and independent of another, and went with an idea of filter chains, which can be used to compose fairly complex request processing.
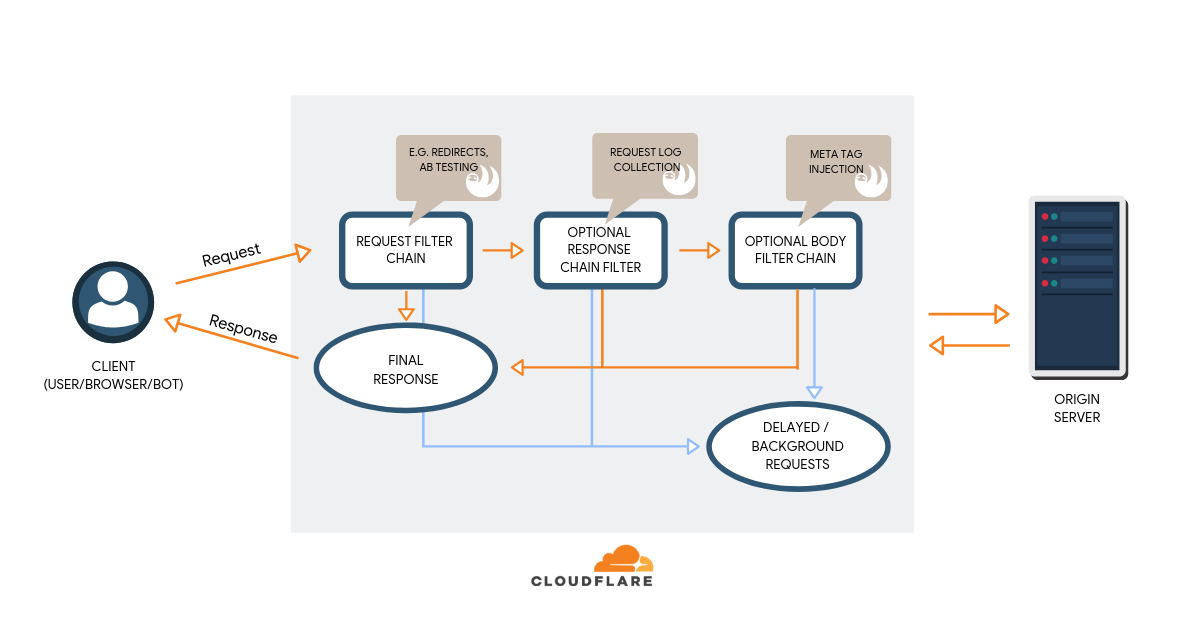
A key accessibility issue we identified from a non-technical perspective was the goal trying of making this serverless technology accessible to all in SEO, because with understanding comes buy-in from stakeholders. In order to do this, we had to make Workers:
- Accessible to users who don’t understand how to write JavaScript / Performant JavaScript
- Process of implementation can complement existing deployment processes
- Process of implementation is secure (internally and externally)
- Process of implementation is compliant with data and privacy policies
- Implementations must be able to be verified through existing processes and practices (BAU)
Before we dive into actual filters, here are partial TypeScript interfaces to illustrate filter APIs:
interface FilterExecutor<Type, Context, ReturnType extends Type | void> {
apply(filterChain: { next: (c: Context, obj: Type) => ReturnType | Promise<ReturnType> }>, context: Context, obj: Type): ReturnType | Promise<ReturnType>;
}
interface RequestFilterContext {
// Request URL
url: URL;
// Short-circuit request filters
respondWith(response: Response | Promise<Response>): void;
// Short-circuit all filters
respondWithAndStop(response: Response | Promise<Response>): void;
// Add additonal response filter
appendResponseFilter(filter: ResponseFilter): void;
// Add body filter
appendBodyFilter(filter: BodyFilter): void;
}
interface RequestFilter extends FilterExecutor<Request, RequestFilterContext, Request> { };
interface ResponseFilterContext {
readonly startMs: number;
readonly endMs: number;
readonly url: URL;
waitUntil(promise: Promise<any>): void;
respondWith(response: Response | Promise<Response>): void;
respondWithAndStop(response: Response | Promise<Response>): void;
appendBodyFilter(filter: BodyFilter): void;
}
interface ResponseFilter extends FilterExecutor<Response, ResponseFilterContext, Response> { };
interface BodyFilterContext {
waitUntil(promise: Promise<any>): void;
}
interface ChunkChain {
public next: ChunkChain | null;
public chunk: Uint8Array;
}
interface BodyFilter extends MutableFilterExecutor<ChunkChain | null, BodyFilterContext, ChunkChain | null> { };
Request filter — Simple Redirects
Firstly, we would like to point out that this is very niche use case, if your platform supports redirects natively, you should absolutely do it through your platform, but there are a number of limited, legacy or bespoke platforms, where redirects are not supported or are limited, or are charged for (per line) by your hosting or platform. For example, Github Pages only support redirects via HTML refresh meta tag.
The most basic redirect filter, would look like this:
class RedirectRequestFilter {
constructor(redirects) {
this.redirects = redirects;
}
apply(filterChain, context, request) {
const redirect = this.redirects[context.url.href];
if (redirect)
context.respondWith(new Response('', {
status: 301,
headers: { 'Location': redirect }
}));
else
return filterChain.next(context, request);
}
}
const { requestFilterHandle } = self.slothRequire('./worker.js');
requestFilterHandle.append(new RedirectRequestFilter({
"https://sloth.cloud/old-homepage": "https://sloth.cloud/"
}));
You can see it live in Cloudflare’s playground here.
The one implemented in Sloth supports basic path matching, hostname matching and query string matching, as well as wildcards.
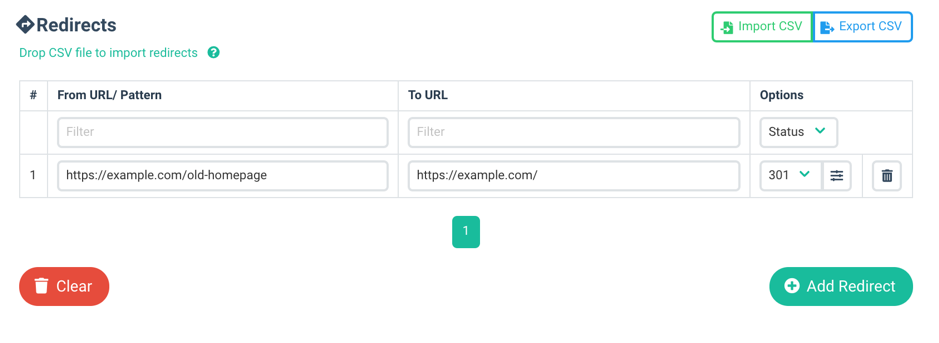
It is all well and good when you do not have a lot of redirects to manage, but what do you do when size of redirects starts to take up significant memory available to Worker? This is where we faced another scaling issue, in taking a small handful of possible redirects, to the tens of thousands.
Managing Redirects with Workers KV and Cuckoo Filters
Well, here is one way you can solve it by using Workers KV - a key-value data store.
Instead of hard coding redirects inside Worker code, we will store them inside Workers KV. Naive approach would be to check redirect for each URL. But Workers KV, maximum performance is not reached until a key is being read on the order of once-per-second in any given data center.
Alternative could be using a probabilistic data structure, like Cuckoo Filters, stored in KV, possibly split between a couple of keys as KV is limited to 64KB. Such filter flow would be:
- Retrieve frequently read filter key.
- Check whether full url (or only pathname) is in the filter.
- Get redirect from Worker KV using URL as a key.
In our tests, we managed to pack 20 thousand redirects into Cuckoo Filter taking up 128KB, split between 2 keys, verified against 100 thousand active URLs with a false-positive rate of 0.5-1%.
Body filter - Hreflang Injection
Hreflang meta tags need to be placed inside HTML <head> element, so before actually injecting them, we need to find either start or end of the head HTML tag, which in itself is a streaming search problem.
The caveat here is that naive method decoding UTF-8 into JavaScript string, performing search, re-encoding back into UTF-8 is fairly slow. Instead, we attempted pure JavaScript search on bytes strings (Uint8Array), which straight away showed promising results.
For our use case, we picked the Boyer-Moore-Horspool algorithm as a base of our streaming search, as it is simple, has great average case performance and only requires a pre-processing search pattern, with manual prefix/suffix matching at chunk boundaries.
Here is comparison of methods we have tested on Node v10.15.0:
| Chunk Size | Method | Ops/s |
|------------|--------------------------------------|---------------------|
| | | |
| 1024 bytes | Boyer-Moore-Horspool over byte array | 163,086 ops/sec |
| 1024 bytes | **precomputed BMH over byte array** | **424,948 ops/sec** |
| 1024 bytes | decode utf8 into strings & indexOf() | 91,685 ops/sec |
| | | |
| 2048 bytes | Boyer-Moore-Horspool over byte array | 119,634 ops/sec |
| 2048 bytes | **precomputed BMH over byte array** | **232,192 ops/sec** |
| 2048 bytes | decode utf8 into strings & indexOf() | 52,787 ops/sec |
| | | |
| 4096 bytes | Boyer-Moore-Horspool over byte array | 78,729 ops/sec |
| 4096 bytes | **precomputed BMH over byte array** | **117,010 ops/sec** |
| 4096 bytes | decode utf8 into strings & indexOf() | 25,835 ops/sec |Can we do better?
Having achieved decent performance improvement with pure JavaScript search over naive method, we wanted to see whether we can do better. As Workers support WASM, we used rust to build a simple WASM module, which exposed standard rust string search.
| Chunk Size | Method | Ops/s |
|------------|-------------------------------------|---------------------|
| | | |
| 1024 bytes | Rust WASM | 348,197 ops/sec |
| 1024 bytes | **precomputed BMH over byte array** | **424,948 ops/sec** |
| | | |
| 2048 bytes | Rust WASM | 225,904 ops/sec |
| 2048 bytes | **precomputed BMH over byte array** | **232,192 ops/sec** |
| | | |
| 4096 bytes | **Rust WASM** | **129,144 ops/sec** |
| 4096 bytes | precomputed BMH over byte array | 117,010 ops/sec |As rust version did not use precomputed search pattern, it should be significantly faster, if we precomputed and cached search patterns.
In our case, we were searching for a single pattern and stopping once it was found, where pure JavaScript version was fast enough, but if you need multi-pattern, advanced search, WASM is the way to go.
We could not record statistically significant change in latency, between basic worker and one with a body filter deployed to production, due to unstable network latency, with a mean response latency of 150ms and 10% 90th percentile standard deviation.
What’s next?
We believe that Workers and serverless applications can open up new opportunities to overcome a lot of issues faced by the SEO community when working with legacy tech stacks, platform limitations, and heavily congested development queues.
We are also investigating whether Workers can allow us to make a more efficient Tag Manager, which bundles and pushes only matching Tags with their code, to minimize number of external requests caused by trackers and thus reduce load on user browser.
You can experiment with Cloudflare Workers yourself through Sloth, even if you don’t know how to write JavaScript.