
Heute kam es bei CenturyLink/Level(3), einem der größten ISP und Internet-Bandbreitenanbieter, zu einem erheblichen Ausfall. Dieser beeinträchtigte einige Cloudflare-Kunden sowie eine beträchtliche Anzahl anderer Dienste und Anbieter im Internet. Während wir auf ein Post Mortem von CenturyLink/Level(3) selbst warten, möchte ich dokumentieren, was wir von unserer Seite aus beobachtet haben. Ich zeige auf, wie Cloudflare das Problem umschifft hat, warum einige unserer Kunden auch trotz unserer Abhilfemaßnahmen betroffen waren und wie das Problem wahrscheinlich entstanden ist.
Zunahme von Fehlern
Ab 10:03 UTC registrierten unsere Überwachungssysteme eine zunehmende Anzahl von Fehlern, die die Ursprungsserver unserer Kunden erreichten. Diese wurden als „Fehler 522“ angezeigt. Fehler 522 weist darauf hin, dass es ein Problem bei der Verbindung vom Cloudflare-Netzwerk zu dem Ort gibt, an dem die Anwendungen des Kunden gehostet werden.
CenturyLink/Level(3) ist nur einer von vielen ganz unterschiedlichen Netzwerk-Providern, mit denen Cloudflare vernetzt ist. Wenn wir eine Zunahme von Fehlern bei einem Provider feststellen, versuchen unsere Systeme automatisch, die Anwendungen der Kunden über alternative Provider zu erreichen. Angesichts der großen Anzahl unserer Provider sind wir normalerweise in der Lage, den Traffic weiterzurouten, selbst wenn bei einem Provider ein Problem auftritt.

Automatische Gegenmaßnahmen
Bei dem heutigen Vorfall begannen unsere Systeme schon Sekunden nach dem Anstieg der „Error 522“-Fehlermeldungen damit, den Traffic automatisch von CenturyLink/Level(3) zu alternativen Netzwerk-Providern umzuleiten, darunter Cogent, NTT, GTT, Telia und Tata.
Unser Network Operations Center wurde ebenfalls alarmiert. Ab 10:09 UTC begann unser Team mit zusätzlichen Schritten, um alle Probleme zu bekämpfen, die unsere automatisierten Systeme nicht automatisch beheben konnten. Es ist uns gelungen, den Traffic für die meisten Kunden und Endnutzer in unserem Netzwerk flüssig zu halten, selbst mit dem Verlust von CenturyLink/Level(3) als einem unserer Netzwerk-Provider.
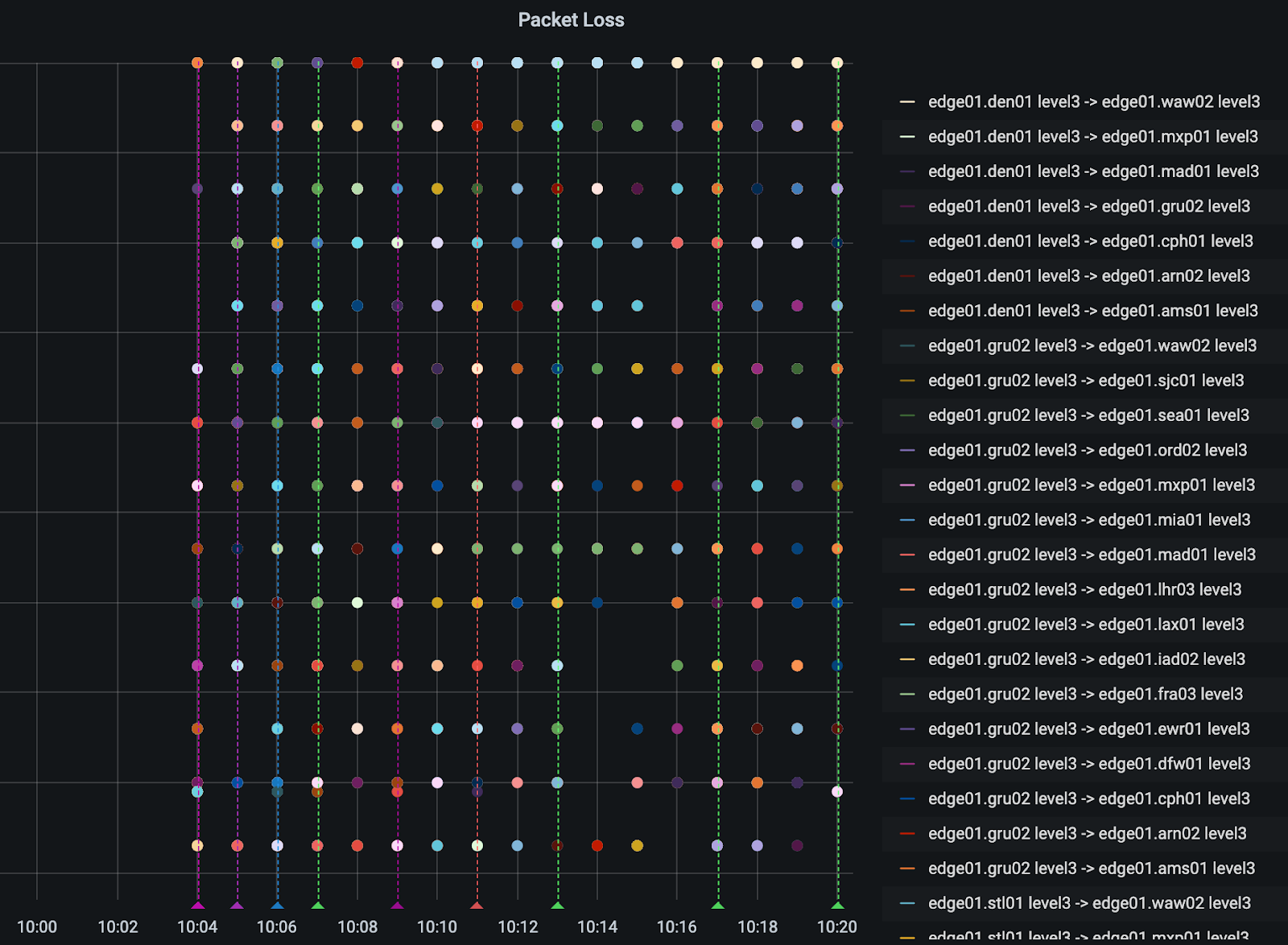
Die folgende Grafik zeigt den Traffic zwischen dem Netzwerk von Cloudflare und sechs großen Tier-1-Netzwerken, die zu unseren Netzwerk-Providern gehören. Der rote Bereich zeigt den CenturyLink/Level(3)-Traffic, der während des Vorfalls fast auf Null sank. Sie können auch sehen, wie wir den Traffic während des Vorfalls automatisch auf andere Netzwerk-Provider verlagert haben, um die Auswirkungen zu mildern und kontinuierlichen Traffic zu gewährleisten.
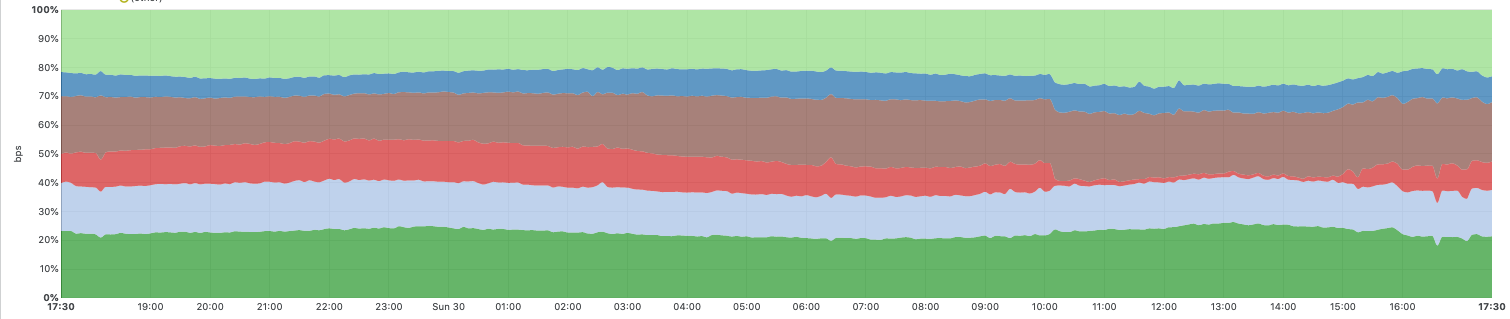
Die nächste Grafik zeigt Fehler 522 in unserem Netzwerk während der Zeit des Vorfalls (was darauf hinweist, dass wir nicht in der Lage waren, Kundenanwendungen zu erreichen).
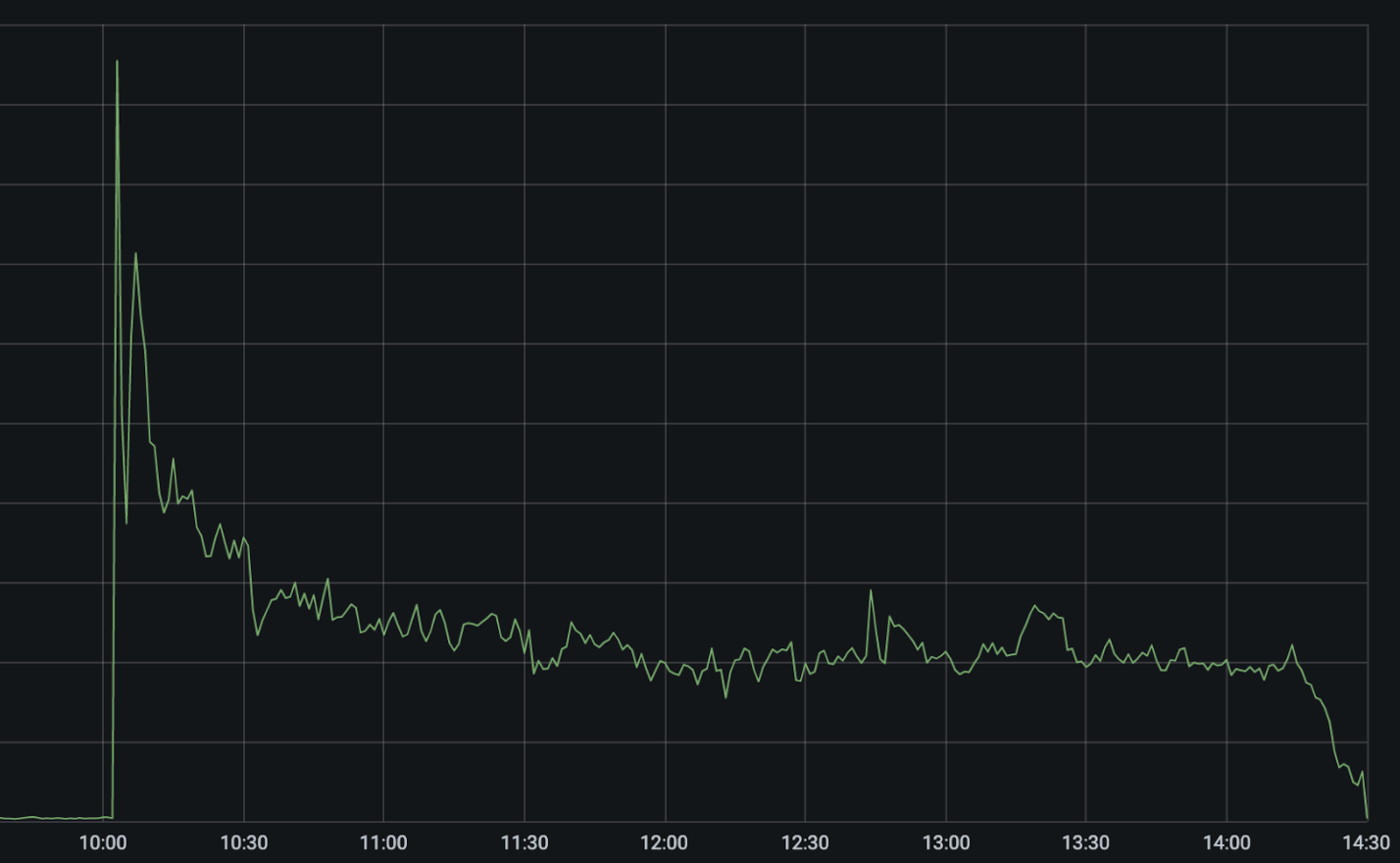
Der steile Anstieg um 10:03 UTC ist der Ausfall des CenturyLink/Level(3)-Netzwerks. Unsere automatisierten Systeme setzten sofort ein und versuchten, den Traffic über alternative Netzwerk-Provider umzuleiten und neu auszubalancieren. Das führte dazu, dass sich die Fehler sofort halbierten und dann auf etwa 25 Prozent des Spitzenwertes fielen, da diese Pfade automatisch optimiert wurden.
Zwischen 10:03 UTC und 10:11 UTC deaktivierten unsere Systeme CenturyLink/Level(3) automatisch in den 48 Städten, in denen wir mit dem Provider verbunden sind, und routeten den Traffic über alternative Netzwerk-Provider um. Dabei berücksichtigen unsere Systeme die Kapazität anderer Provider, bevor sie den Traffic auslagern, um kaskadierende Ausfälle zu verhindern. Aus diesem Grund erfolgt das Failover zwar automatisch, aber nicht an allen Standorten gleichzeitig. Durch zusätzliche manuelle Abhilfemaßnahmen war unser Team in der Lage, die Fehlerquote um weitere 5 Prozent zu reduzieren.
Warum sind die Fehler nicht auf Null gesunken?
Leider gab es nach wie vor eine erhöhte Anzahl von Fehlern, die zeigen, dass wir einige Kunden immer noch nicht erreichen konnten. CenturyLink/Level(3) gehört zu den größten Netzwerk-Providern der Welt. Daher verfügen viele Hosting-Provider nur über eine Single-Home-Verbindung zum Internet, und zwar nur über das CenturyLink/Level(3)-Netzwerk.
Wenn man das immer wieder gerne verwendete Bild des Internets als Datenautobahnheranzieht, dann ist es ganz so, als könnte man eine Stadt nur über eine einzige Ausfahrt erreichen. Ist die Ausfahrt blockiert, kommt man nicht in die Stadt. Diese Tatsache wurde hier in einigen Fällen noch verschlimmert, weil das Netzwerk von CenturyLink/Level(3) zurückgezogenes Routing nicht berücksichtigte und auch nach dem Rückzug weiterhin für Routen zu Netzen wie dem von Cloudflare warb. Im Fall von Kunden, deren einzige Verbindung zum Internet über CenturyLink/Level(3) besteht, oder wenn CenturyLink/Level(3) weiterhin fehlerhafte Routen ankündigte, nachdem sie zurückgezogen worden waren, gab es für uns keine Möglichkeit, ihre Anwendungen zu erreichen. Sie sahen also weiterhin Fehler 522, bis CenturyLink/Level(3) das Problem gegen 14:30 UTC löste.
Das gleiche Problem trat auch auf der anderen Seite des Netzwerks auf. Nutzer brauchten eine Auffahrt auf die Autobahn des Internets. Eine Auffahrt auf das Internet ist im Wesentlichen das, was Ihr ISP anbietet. CenturyLink ist einer der größten ISPs in den USA.
Da in diesem Fall anscheinend das gesamte CenturyLink/Level(3)-Netzwerk ausfiel, hätten CenturyLink-Kunden bis zur Behebung des Problems weder Cloudflare noch irgendeinen anderen Internet-Provider erreichen können. Wir verzeichneten während des Ausfalls einen Rückgang des weltweiten Traffic um 3,5 %. Dieser Umstand ist fast ausschließlich auf einen nahezu vollständigen Ausfall des ISP-Dienstes von CenturyLink in den USA zurückzuführen.
Was könnte hier passiert sein?
Was genau passiert ist werden wir erst wissen, wenn CenturyLink/Level(3) einen Post Mortem herausgibt. Wir erhalten jedoch Hinweise aus BGP-Ankündigungen und wie sie sich während des Ausfalls über das Internet verbreitet haben. BGP steht für „Border Gateway Protocol“. Es ist die Art und Weise, wie sich Router im Internet gegenseitig mitteilen, welche IPs hinter ihnen stehen und welchen Traffic sie empfangen sollen.
Ab 10:04 UTC gab es eine beträchtliche Anzahl von BGP-Updates. Mit einem BGP-Update signalisiert ein Router, dass sich eine Route geändert hat oder nicht mehr verfügbar ist. Unter normalen Bedingungen verzeichnet das Internet etwa 1,5 –2 MB BGP-Updates alle 15 Minuten. Zu Beginn des Vorfalls stieg die Anzahl der BGP-Updates auf mehr als 26 MB BGP-Updates pro 15 Minuten und blieb während des gesamten Vorfalls erhöht.

Diese Updates zeigen die Instabilität der BGP-Routen innerhalb des CenturyLink/Level(3)-Backbones. Die Frage ist aber, was diese Instabilität verursacht hat. Das CenturyLink/Level(3)-Status-Update bietet einige Hinweise und weist auf ein Flowspec-Update als Ursache hin.

Was ist Flowspec?
In seinem Update erwähnt CenturyLink/Level(3), dass eine problematische Flowspec-Regel das Problem verursacht hätte. Was ist nun also Flowspec? Flowspec ist eine Erweiterung des BGP. Es ermöglicht, Firewall-Regeln mithilfe von BGP einfach innerhalb eines Netzwerks –oder sogar zwischen mehreren Netzwerken – zu verteilen. Flowspec ist ein leistungsfähiges Tool. Sie können damit nahezu sofort Regeln effizient über ein ganzes Netzwerk verbreiten. Das ist praktisch, wenn man versucht, schnell auf so etwas wie einen Angriff zu reagieren. Fehler können jedoch gefährlich werden.
Bei Cloudflare haben wir zu Beginn unserer Entwicklung selbst Flowspec verwendet, um Firewall-Regeln zu umgehen und beispielsweise große DDoS-Angriffe auf dem Netzwerk-Layer zu bekämpfen. Wir erlitten unseren eigenen Flowspec-induzierten Ausfall vor mehr als 7 Jahren. Wir selbst verzichten nun auf Flowspec, aber es ist weiterhin ein gängiges Protokoll, um Netzwerk-Firewall-Regeln durchzusetzen.
Wir können nur spekulieren, was bei CenturyLink/Level(3) geschah. Ein plausibles Szenario ist, dass das Unternehmen einen Flowspec-Befehl erteilte, um zu versuchen, einen gegen sein Netzwerk gerichteten Angriff oder anderen Missbrauch zu blockieren. Aus dem Statusbericht geht hervor, dass die Flowspec-Regel die Ankündigung von BGP selbst verhinderte. Wir haben keine Möglichkeit zu erfahren, was diese Flowspec-Regel war, aber hier ist eine im Format von Juniper, die die gesamte BGP-Kommunikation im Netzwerk blockiert hätte.
route DISCARD-BGP {
match {
protocol tcp;
destination-port 179;
}
then discard;
}
Warum so viele Updates?
Ein Rätsel bleibt jedoch, warum die globalen BGP-Updates während des gesamten Vorfalls auf einem hohen Niveau blieben. Wenn die Regel BGP blockierte, dann würde man zunächst einen Anstieg der BGP-Ankündigungen erwarten, die dann wieder auf den Normalzustand zurückfallen würden.
Eine mögliche Erklärung ist, dass die problematische Flowspec-Regel am Ende einer langen Liste von BGP-Updates stand. Wenn das der Fall wäre, könnte es sein, dass jeder Router im Netzwerk von CenturyLink/Level(3) die Flowspec-Regel erhalten würde. Sie würden dann BGP blockieren. Das würde dazu führen, dass sie die Regel nicht mehr erhalten würden. Dann würden sie neu starten und sich durch alle BGP-Regeln durcharbeiten, bis sie wieder bei der problematischen Flowspec-Regel ankämen. BGP würde wieder fallengelassen werden. Die Flowspec-Regel würde nicht mehr empfangen werden. Und das Ganze würde sich ständig wiederholen.
Eine Herausforderung dabei ist, dass sich die Warteschlange der BGP-Updates innerhalb des CenturyLink/Level(3)-Netzwerks bei jedem Zyklus weiter vergrößern würde. Dies hätte letztlich möglicherweise eine Überlastung der Speicher und CPUs der Router verursacht, was eine Reihe zusätzlicher Herausforderungen für die Wiederinbetriebnahme des Netzwerks mit sich gebracht hätte.
Warum hat die Reparatur so lange gedauert?
Es handelte sich um einen bedeutenden globalen Internetausfall, und zweifellos erhielt das CenturyLink/Level(3)-Team sofort eine Warnung. Das Unternehmen ist ein hochentwickelter Netzbetreiber mit einem erstklassigen Network Operations Center (NOC). Warum dauerte die Lösung dann mehr als vier Stunden?
Auch hier können wir nur spekulieren. Erstens könnte die Flowspec-Regel und die erhebliche Last, die eine große Anzahl von BGP-Updates den Routern auferlegte, es dem Unternehmen erschweren, sich in seinen eigenen Interfaces anzumelden. Mehrere der anderen Tier-1-Provider haben (wahrscheinlich auf Anfrage von CenturyLink/Level(3)) Schritte eingeleitet, um ihre Netzwerke von der Peer-Group zu trennen. Damit dürfte sich die Zahl der BGP-Announcements, die beim CenturyLink/Level(3)-Netzwerk eingingen, reduziert haben, sodass das Netz den Rückstand aufholen konnte.
Zweitens wurde die Flowspec-Regel möglicherweise nicht von CenturyLink/Level(3) selbst, sondern von einem seiner Kunden ausgestellt. Viele Netzwerk-Provider lassen Flowspec-Peering zu. Für nachgelagerte Kunden kann das ein leistungsstarkes Tool sein, um Angriffs-Traffic zu blockieren. Es macht es jedoch auch viel schwieriger, eine problematische Flowspec-Regel aufzuspüren, sollte etwas schief laufen.
Und schließlich ist es auch nicht gerade hilfreich, wenn diese Probleme an einem frühen Sonntagmorgen auftreten. Netzwerke von der Größe und dem Umfang von CenturyLink/Level(3) sind extrem komplex. Zwischenfälle passieren. Wir wissen es zu schätzen, dass ihr Team uns während des gesamten Vorfalls auf dem Laufenden gehalten hat. #hugops