
Cloudflare’s network keeps growing, and that growth doesn’t just come from building new data centers in new cities. We’re also upgrading the capacity of existing data centers by adding newer generations of servers — a process that makes our network safer, faster, and more reliable for our users.
Connecting new Cloudflare servers to our network has always been complex, in large part because of the amount of manual effort that used to be required. Members of our Data Center and Infrastructure Operations, Network Operations, and Site Reliability Engineering teams had to carefully follow steps in an extremely detailed standard operating procedure (SOP) document, often copying command-line snippets directly from the document and pasting them into terminal windows.
But such a manual process can only scale so far, and we knew must be a way to automate the installation of new servers.
Here’s how we tackled that challenge by building our own Provisioning-as-a-Service (PraaS) platform and cut by 90% the amount of time our team spent on mundane operational tasks.
Choosing and using an automation framework
When we began our automation efforts, we quickly realized it made sense to replace each of these manual SOP steps with an API-call equivalent and to present them in a self-service web-based portal.
To organize these new automatic steps, we chose Apache Airflow, an open-source workflow management platform. Airflow is built around directed acyclic graphs, or DAGs, which are collections of all the tasks you want to run, organized in a way that reflects their relationships and dependencies.
In this new system, each SOP step is implemented as a task in the DAG. The majority of these tasks are API calls to Salt — software which automates the management and configuration of any infrastructure or application, and which we use to manage our servers, switches, and routers. Other DAG tasks are calls to query Prometheus (systems monitoring and alerting toolkit), Thanos (a highly available Prometheus setup with long-term storage capabilities), Google Chat webhooks, JIRA, and other internal systems.
Here is an example of one of these tasks. In the original SOP, SREs were given the following instructions to enable anycast:
- Login to a remote system.
- Copy and Paste the command in the terminal.
- Replace the router placeholder in the command snippet with the actual value.
- Execute the command.
In our new workflow, this step becomes a single task in the DAG named “enable_anycast”:
enable_anycast = builder.wrap_class(AsyncSaltAPIOperator)(
task_id='enable_anycast',
target='{{ params.netops }}',
function='cmd.run',
fun_kwargs={'cmd': 'salt {{ get_router(params.colo_name) }} '
'anycast.enable --out=json --out-indent=-1'},
salt_conn_id='salt_api',
trigger_rule='one_success')
As you can see, automation eliminates the need for a human operator to login to a remote system, and to figure out the router that will be used to replace the placeholder in the command to be executed.
In Airflow, a task is an implementation of an Operator. The Operator in the automated step is the “AsyncSaltAPIOperator”, a custom operator built in-house. This extensibility is one of the many reasons that made us decide to use Apache Airflow. It allowed us to extend its functionality by writing custom operators that suit our needs.
SREs from various teams have written quite a lot of custom Airflow Operators that integrate with Salt, Prometheus, Bitbucket, Google Chat, JIRA, PagerDuty, among others.
Manual SOP steps transformed into a feature-packed automation
The tasks that replaced steps in the SOP are marvelously feature-packed. Here are some highlights of what they are capable of, on top of just executing a command:
Failure Handling
When a task fails for whatever reason, it automatically retries until it exhausts its maximum retry limit that we set for the task. We employ various retry strategies, including instructing tasks to not retry at all, especially when it’s impractical to retry, or when we deliberately do not want it to retry at all regardless of whether there are any retry attempts remaining, such as when an exception is encountered or a condition that is unlikely to change for the better.
Logging
Each task provides a comprehensive log during executions. We’ve written our tasks to ensure that we log as much information as possible that would help us audit and troubleshoot issues.
Notifications
We’ve written our tasks to send a notification with information such as the name of the DAG, the name of the task, its task state, the number of attempts it took to reach a certain state, and a link to view the task logs.
When a task fails, we definitely want to be notified, so we also set tasks to additionally provide information such as the number of retry attempts and links to view relevant wiki pages or Grafana dashboards.
Depending on the criticality of the failure, we can also instruct it to page the relevant on-call person on the provisioning shift, should it require immediate attention.
Jinja Templating
Jinja templating allows providing dynamic content using code to otherwise static objects such as strings. We use this in combination with macros wherein we provide parameters that can change during the execution, since macros are evaluated while the task gets run.
Macros
Macros are used to pass dynamic information into task instances at runtime. Macros are a way to expose objects to templates. In other words, macros are functions that take input, modify that input, and give the modified output.
Adapting tasks for preconditions and human intervention
There are a few steps in the SOP that require certain preconditions to be met. We use sensors to set dependencies between these tasks, and even between different DAGs, so that one does not run until the dependency has been met.
Below is an example of a sensor that waits until all nodes resolve to their assigned DNS records:
verify_node_dns = builder.wrap_class(DNSSensor)(
task_id='verify_node_dns',
zone=domain,
nodes_from='{{ to_json(run_ctx.globals.import_nodes_via_mpl) }}',
timeout=60 * 30,
poke_interval=60 * 10,
mode='reschedule')
In addition, some of our tasks still require input from a human operator. In these circumstances, we use sensors as blocking tasks that prevent work from starting until certain preconditions are met. We use these to set dependencies between tasks and even DAGs so that one does not run until the dependency has finished successfully.
The code below is a simple example of a task that will send notifications to get the attention of a human operator, and waits until a Change Request ticket has been provided and verified:
verify_jira_input = builder.wrap_class(InputSensor)(
task_id='verify_jira_input',
var_key='jira',
prompt='Please provide the Change Request ticket.',
notify=True,
require_human=True)
Another sensor task example is waiting until a zone has been deployed by a Cloudflare engineer as described in https://blog.cloudflare.com/improving-the-resiliency-of-our-infrastructure-dns-zone/.
In order for PraaS to be able to accept human inputs, we’ve written a separate DAG we call our DAG Manager. Whenever we need to submit input back to a running expansion DAG, we simply trigger the DAG Manager and pass in our input as a JSON configuration, which will then be processed accordingly and submit the input back to the expansion DAG.
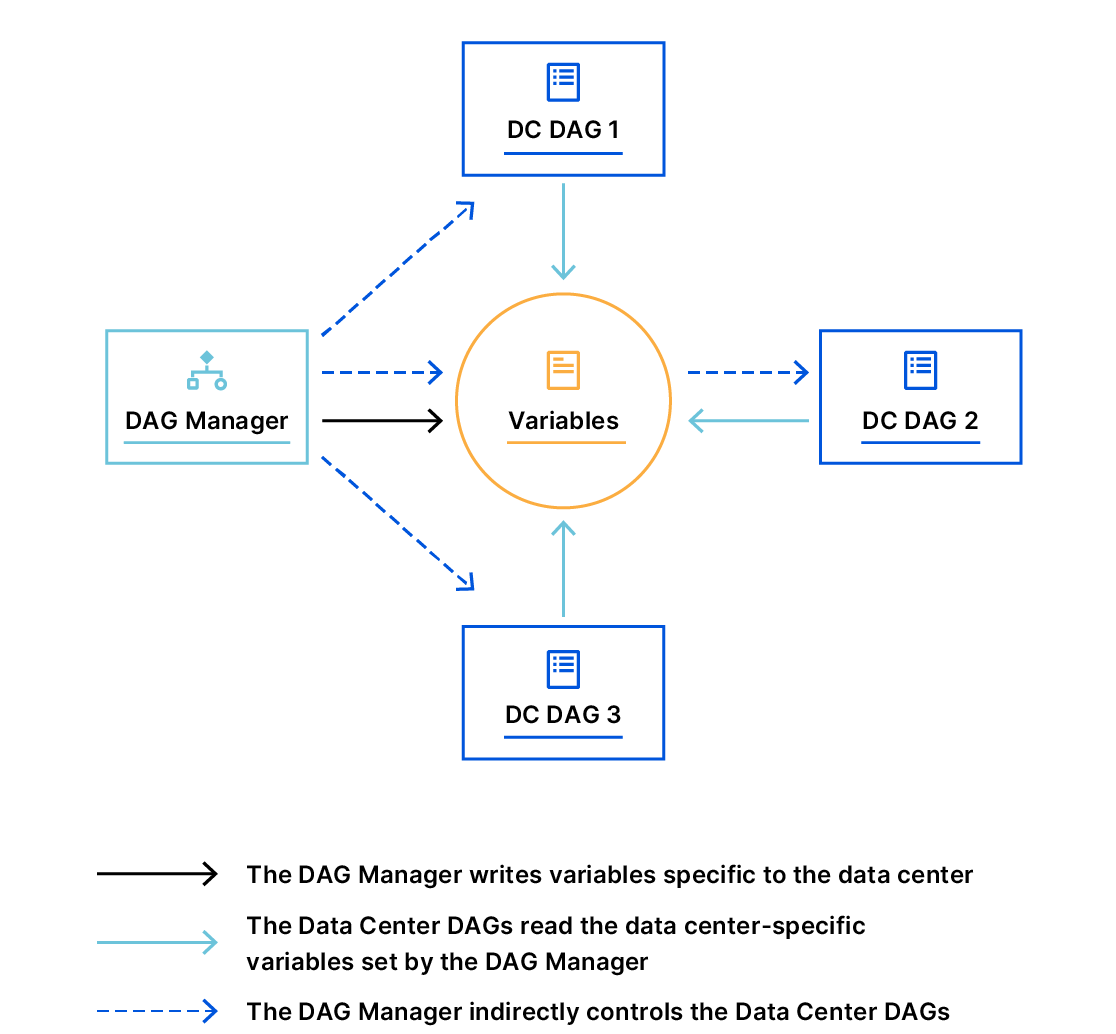
Managing Dependencies Between Tasks
Replacing SOP steps with DAG tasks was only the first part of our journey towards greater automation. We also had to define the dependencies between these tasks and construct the workflow accordingly.
Here’s an example of what this looks like in code:
verify_cr >> parse_cr >> [execute_offline, execute_online]
execute_online >> silence_highstate_runner >> silence_metals >> \
disable_highstate_runner
The code simply uses bit shift operators to chain the operations. A list of tasks can also be set as dependencies:
change_metal_status >> [wait_for_change_metal_status, verify_zone_update] >> \
evaluate_ecmp_management
With the bit shift operator, chaining multiple dependencies becomes concise.
By default, a downstream task will only run if its upstream has succeeded. For a more complex dependency setup, we set a trigger_rule which defines the rule by which the generated task gets triggered.
All operators have a trigger_rule argument. The Airflow scheduler decides whether to run the task or not depending on what rule was specified in the task. An example rule that we use a lot in PraaS is “one_success” — it fires as soon as at least one parent succeeds, and it does not wait for all parents to be done.
Solving Complex Workflows with Branching and Multi-DAGs
Having complex workflows means that we need a workflow to branch, or only go down a certain path, based on an arbitrary condition, which is typically related to something that happened in an upstream task. Branching is used to perform conditional logic, that is, execute a set of tasks based on a condition. We use BranchPythonOperator to achieve this.
At some point in the workflow, our data center expansion DAGs trigger various external DAGs to accomplish complex tasks. This is why we have written our DAGs to be fully reusable. We did not try to incorporate all the logic into a single DAG; instead, we created other separable DAGs that are fully reusable and can be triggered on-demand manually by hand or programmatically — our DAG Manager and the “helper” DAG is an example of this.
The Helper DAG comprises logic that allows us to mimic a “for loop” by having the DAG respawn itself if needed, technically doing cycles. If you recall, a DAG is acyclic, but we have some tasks in our workflow that require us to do complex loops and are solved by using a helper DAG.
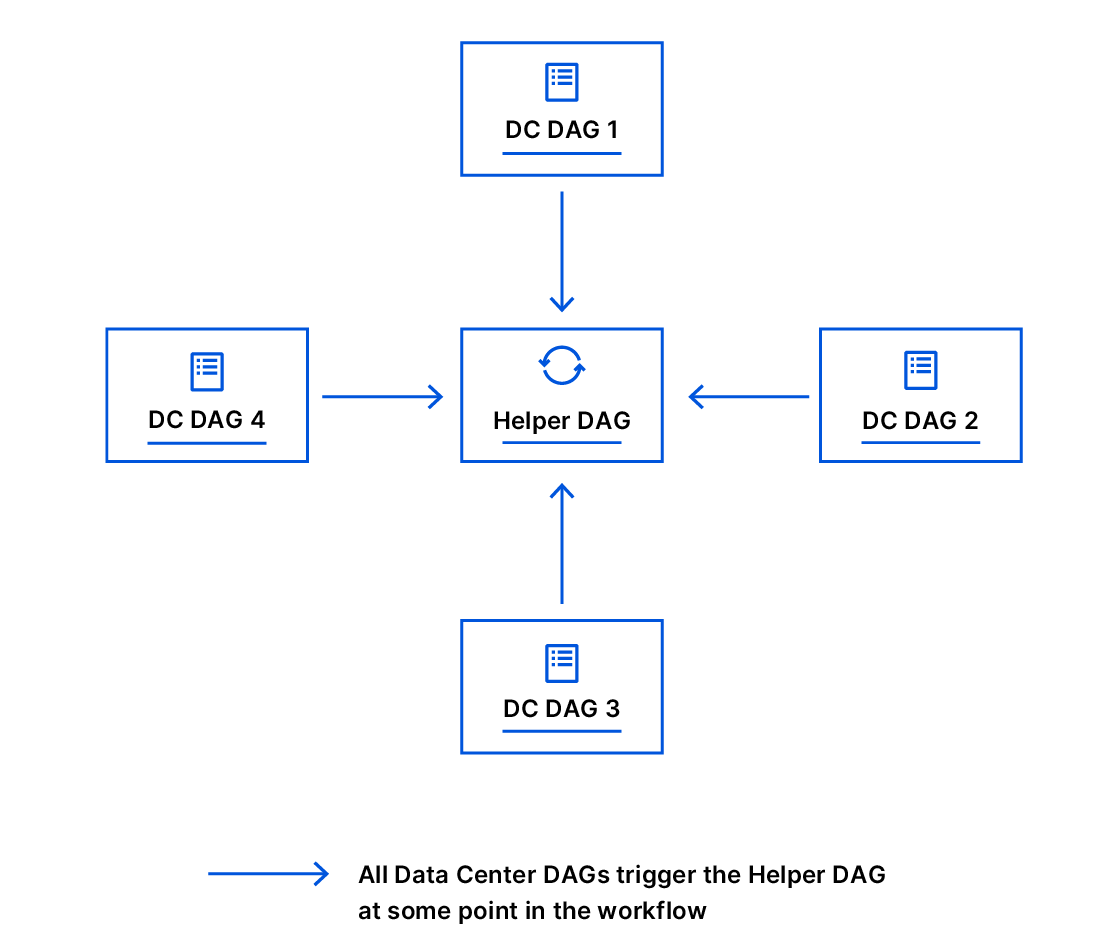
We designed reusable DAGs early on, which allowed us to build complex automation workflows from separable DAGs, each of which handles distinct and well-defined tasks. Each data center DAG could easily reuse other DAGs by triggering them programmatically.
Having separate DAGs that run independently, that are triggered by other DAGs, and that keep inter-dependencies between them, is a pattern we use a lot. It has allowed us to execute very complex workflows.
Creating DAGs that Scale and Executing Tasks at Scale
Data center expansions are done in two phases:
Phase 1 - this is the phase in which servers are powered on. It boots our custom Linux kernel, and begins the provisioning process.
Phase 2 - this is the phase in which newly provisioned servers are enabled in the cluster to receive production traffic.
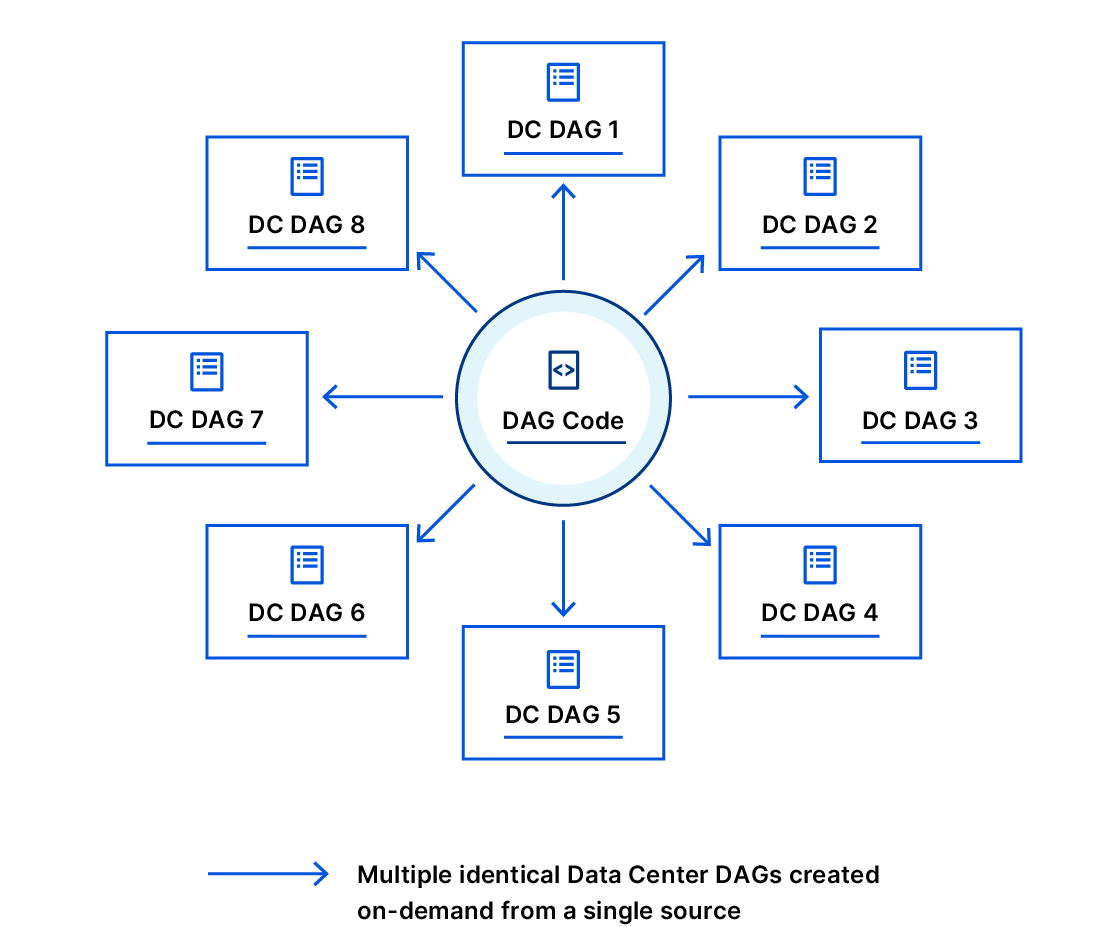
To reflect these phases in the automation workflow, we also wrote two separate DAGs, one for each phase. However, we have over 200 data centers, so if we were to write a pair of DAGs for each, we would end up writing and maintaining 400 files!
A viable option could be to parameterize our DAGs. At first glance, this approach sounds reasonable. However, it poses one major challenge: tracking the progress of DAG runs will be too difficult and confusing for the human operator using PraaS.
Following the software design principle called DRY (Don’t Repeat Yourself), and inspired by the Factory Method design pattern in programming, we’ve instead written both phase 1 and phase 2 DAGs in a way that allow them to dynamically create multiple different DAGs with exactly the same tasks, and to fully reuse the exact same code. As a result, we only maintain one code base, and as we add new data centers, we are also able to generate a DAG for each new data center instantly, without writing a single line of code.
And Airflow even made it easy to put a simple customized web UI on top of the process, which made it simple to use by more employees who didn’t have to understand all the details.
The death of SOPs?
We would like to think that all of this automation removes the need for our original SOP document. But this is not really the case. Automation can fail, the components in it can fail, and a particular task in the DAG may fail. When this happens, our SOPs will be used again to prevent provisioning and expansion activities from stopping completely.
Introducing automation paved the way for what we call an SOP-as-Code practice. We made sure that every task in the DAG had an equivalent manual step in the SOP that SREs can execute by hand, should the need arise, and that every change in the SOP has a corresponding pull request (PR) in the code.
What’s next for PraaS
Onboarding of the other provisioning activities into PraaS, such as decommissioning, is already ongoing.
For expansions, our ultimate goal is a fully autonomous system that monitors whether new servers have been racked in our edge data centers — and automatically triggers expansions — with no human intervention.