

This post is also available in Bahasa Indonesia, ไทย.

APIs are incredibly important. Throughout the 2000s, they formed the backbone of popular web services, helping the Internet become more useful and accessible. In the 2010s, APIs played a larger role in our lives, allowing personal devices to communicate with the digital world. Many of our daily activities, like using rideshare services and paying for lattes, are dependent on this form of modern communication. Now we are approaching a post-pandemic world in which APIs will be more important than ever.
Unfortunately, as any technology grows, so does its surface area for abuse. APIs are no exception. Competing rideshare services might monitor each other’s prices via API, spawning a price war and a waste of digital resources. Or a coffee drinker might manipulate an API for a latte discount. Some companies have thousands of APIs — including ones that they don’t even know about. Cloudflare can help solve these problems.
Today, we are announcing early access to API Discovery and API Abuse Detection.
Background
Before going further, it’s important to explain why we need a solution for APIs. Traditional security tools, including Rate Limiting and DDoS Protection, can be wonderfully useful. But these approaches were not built to act alone. We might rate limit a particular API endpoint, but how would we choose a proper threshold? It would be difficult to do this at scale without causing problems. An API might be hit by a distributed attack (falling below the threshold), or it might see an increase in legitimate traffic (exceeding the threshold).
Others have suggested deploying Bot Management on API endpoints. In many cases, this is effective and adds some degree of protection, particularly if the API is meant to be used by browsers (as part of a web application). But Bot Management was designed to find bad actors among humans. These actors typically use automation, while humans typically use browsers, so the distinction is somewhat clear. But APIs present a different problem. APIs are automated, so any solution must find bad bots among other bots. We must distinguish between good and bad automated traffic.
To solve the API problem, we had to develop a measure of intent — almost like interviewing each request to determine its aims. We must answer the following questions purely based on circumstantial data:
- Is this request using an API for its intended purpose?
- Is this request exhibiting suspicious behavior? Why?
Again, while tools like Rate Limiting can handle binary problems (e.g., “has this IP exceeded 200 requests?”), the API problem demands a more subjective arbiter. It requires us to examine the purpose of an API and define reasonable constraints based on what we find. It also requires us to find a new source of ground truth. When we built Bot Management, we could confirm requests were human or automated by issuing challenges. APIs involve automated services which cannot prove their legitimacy by solving a challenge.
After months of sorting through this problem, we’re excited to give a first look at our solution. It comes in a few parts…
API Discovery
Some of our users tell us they can’t keep track of their APIs. Before we even try to protect these endpoints, we need to map them out and understand the attack surface area. We call this “API Discovery.”

The discovery process starts with simplification. Large websites may have thousands of APIs, but a lot of the calls look similar. Consider the following two paths:
- api.example.com/login/237
- api.example.com/login/415
In this example, “237” and “415” are customer identifiers. Both paths serve the same purpose — they allow users to log into their accounts — but they are not identical. So we map out the paths and immediately collapse them into the following:
- api.example.com/login/*
- api.example.com/login/*
Notice how we removed the customer identifiers. Our systems can detect the changing parts of an API, allowing us to recognize both paths as the same one. We do this by recording the cardinality of each endpoint. For example, we might have originally found that there were 700 different strings observed in place of the asterisk. “237” and “415” were just two of those possibilities. We then used unsupervised learning to choose a threshold (in this case, let’s say 30). Since we’ve noticed far more than 30 variants of this path, we recognize the customer identifier as a variable and collapse the path. This process is called “path normalization.”
API Discovery is a building block for many security products to come. But at its core, the technology is about producing a simple, trustworthy map of APIs. Here is a small sample of what you might find:
login/<customer_identifier>
auth
account/<customer_identifier>
password_reset
logout
Imagine this list scaled to hundreds, if not thousands of endpoints. Some will be obvious (hopefully login endpoints are expected!), but others could be a surprise. The final map will help identify variables or tokens referenced by each endpoint.
Detecting Abuse by Volume
Now that we have discovered APIs, we can begin to look for abuse. Our first approach handles volumetric anomalies. In other words, we make an educated guess about how often each path is reached and set some threshold to manage abuse. This is a form of adaptive rate limiting.
Consider the API path /update-score for a sports website. You can probably guess what this does — it routinely fetches the latest score for a game, which might happen multiple times per second. We might deploy unsupervised learning and set a high threshold for normal use. Perhaps 150 requests per minute for a specific IP, user agent, or other session identifier.
But that same sports website could require its users to have accounts. In this case, a separate /reset-password API could exist on the same domain. No sports fan would reset their password as much as they check scores, so this path would likely have a lower threshold. The beauty of unsupervised learning (and our form of abuse detection) is that we map out your site, develop separate baselines for each API, and try to predict the intent of requests as they are made. If we see 150 sudden attempts to reset a password, our systems immediately suspect an account takeover.
It’s also important to understand why traffic shifts when it does. For example, we shouldn’t block sports traffic when it surges due to the NBA Finals. Although the /update-score endpoint might temporarily see more use, Cloudflare would recognize the greater context and change any relevant thresholds. We only want to mitigate when an individual is abusing an endpoint.
Detecting Abuse by Sequence
Our team often applies the Swiss Cheese Model to security. This approach has been used in healthcare, physical security, and many other industries, but the idea is simple. Any layer of defense will have a few holes — but stacking unique defenses (or slices of cheese) next to each other improves overall safety.
In the world of Internet security, we call this “defense in depth.” APIs are first protected by Cloudflare’s security suite (DDoS, etc.). The second layer uses volumetric detection (described above). But the third layer is completely different from anything we have done before: it is sequential anomaly detection. We expect this to dramatically change the API landscape.
Here’s how it works. As usual, we start by running path normalization to find a finite set of states. In one test, this process reduced about 10,000 states to just 60, massively simplifying the API problem. Then we use Markov Chains to build a transition matrix, which is a map of all the states and where they commonly lead. We finish by assigning probabilities to each transition.
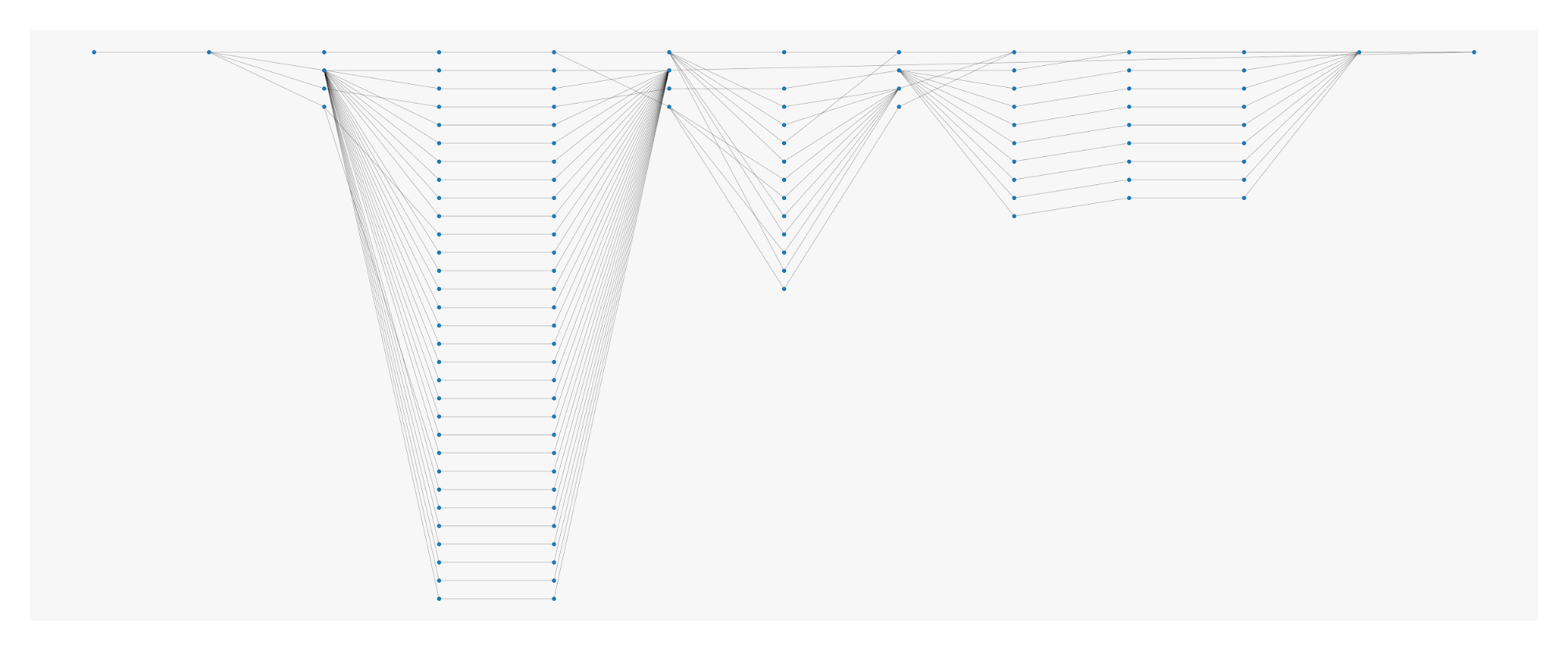
The end result? We can conceptually piece together the movement on a site, which might consist of the following steps:
- A request is sent to /login/*/enter
- It is redirected to /login/*/verify
- It is finally redirected to /login-successful
This looks like a valid user attempting to log in. Again, we use unsupervised learning to detect flows like this one, but our approach detects outliers as well. In this case, we have found that 1 → 2 → 3 is a logical flow, but what if someone arrives directly at step 3? We might flag this request as anomalous.
This approach, which relies heavily on Markov Chains, is quite efficient. Consider adding a single node to the chain: obviously, the chain itself scales linearly. The transition matrix, which maps out all possible node relationships, scales exponentially. But we’ve found that most of these relationships are not exercised. In practice, no one pursues convoluted paths like logout → upload → auth. The more common transitions, which may look like login → update-score → logout, only made up 2% of all transitions in our tests. We can efficiently store the matrix by ignoring unused transitions.
That wraps up our overview of sequential anomaly detection. It’s the last layer in our Swiss Cheese Model, and just like the volumetric approach, it utilizes a baseline that we update over time.
Other Uses
API Abuse Detection is remarkably versatile. Although we created this technology for general API use, there are a few use cases worth highlighting.
The first is Bot Management for mobile apps. While our Bot Management solution has worked well for many apps, API Abuse Detection is significantly more effective. That’s because mobile devices often rely on APIs. While their requests follow the slow, deliberate pace of a human user, mobile apps consume API endpoints and may appear automated. These apps do not offer the same navigational freedom that websites do. But we can use this to our advantage: legitimate users follow predictable sequences based on prior states, which we are now able to validate with API Abuse Detection.

Other companies have developed mobile SDKs to approach API abuse. But SDKs are bulky, difficult to integrate, and sometimes ineffective. This client-side approach is also vulnerable to tampering. It performs authentication of the client software, but is not capable of detecting any actual abusive behavior. Anyone who can extract the client-side certificate can immediately bypass bot protections. We believe we can secure mobile apps without any sort of SDK — simply by deploying API Abuse Detection on mobile endpoints.
Additionally, many API endpoints are crowded. Not everyone can identify their “good” API/bot traffic, which means that a positive security model may not work. This is especially true of companies that work with partners who rotate user agents or can’t align their signals. Our approach avoids this headache entirely. We automatically build a map of API endpoints, develop baselines, and detect abuse.
Early Access
Do you have a site that needs API Abuse Detection? Do you want to try the next generation of Bot Management for your mobile app? Please let us know by contacting your account team. We’re excited to bring these models to life in the coming months.