
This was originally published on Perf Planet's 2019 Web Performance Calendar.
QUIC, the new Internet transport protocol designed to accelerate HTTP traffic, is delivered on top of UDP datagrams, to ease deployment and avoid interference from network appliances that drop packets from unknown protocols. This also allows QUIC implementations to live in user-space, so that, for example, browsers will be able to implement new protocol features and ship them to their users without having to wait for operating systems updates.
But while a lot of work has gone into optimizing TCP implementations as much as possible over the years, including building offloading capabilities in both software (like in operating systems) and hardware (like in network interfaces), UDP hasn't received quite as much attention as TCP, which puts QUIC at a disadvantage. In this post we'll look at a few tricks that help mitigate this disadvantage for UDP, and by association QUIC.
For the purpose of this blog post we will only be concentrating on measuring throughput of QUIC connections, which, while necessary, is not enough to paint an accurate overall picture of the performance of the QUIC protocol (or its implementations) as a whole.
Test Environment
The client used in the measurements is h2load, built with QUIC and HTTP/3 support, while the server is NGINX, built with the open-source QUIC and HTTP/3 module provided by Cloudflare which is based on quiche (github.com/cloudflare/quiche), Cloudflare's own open-source implementation of QUIC and HTTP/3.
The client and server are run on the same host (my laptop) running Linux 5.3, so the numbers don’t necessarily reflect what one would see in a production environment over a real network, but it should still be interesting to see how much of an impact each of the techniques have.
Baseline
Currently the code that implements QUIC in NGINX uses the sendmsg() system call to send a single UDP packet at a time.
ssize_t sendmsg(int sockfd, const struct msghdr *msg,
int flags);
The struct msghdr carries a struct iovec which can in turn carry multiple buffers. However, all of the buffers within a single iovec will be merged together into a single UDP datagram during transmission. The kernel will then take care of encapsulating the buffer in a UDP packet and sending it over the wire.
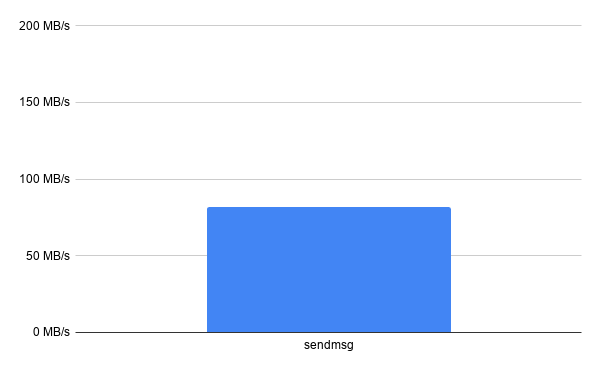
The throughput of this particular implementation tops out at around 80-90 MB/s, as measured by h2load when performing 10 sequential requests for a 100 MB resource.
sendmmsg()
Due to the fact that sendmsg() only sends a single UDP packet at a time, it needs to be invoked quite a lot in order to transmit all of the QUIC packets required to deliver the requested resources, as illustrated by the following bpftrace command:
% sudo bpftrace -p $(pgrep nginx) -e 'tracepoint:syscalls:sys_enter_sendm* { @[probe] = count(); }'
Attaching 2 probes...
@[tracepoint:syscalls:sys_enter_sendmsg]: 904539
Each of those system calls causes an expensive context switch between the application and the kernel, thus impacting throughput.
But while sendmsg() only transmits a single UDP packet at a time for each invocation, its close cousin sendmmsg() (note the additional “m” in the name) is able to batch multiple packets per system call:
int sendmmsg(int sockfd, struct mmsghdr *msgvec,
unsigned int vlen, int flags);
Multiple struct mmsghdr structures can be passed to the kernel as an array, each in turn carrying a single struct msghdr with its own struct iovec , with each element in the msgvec array representing a single UDP datagram.
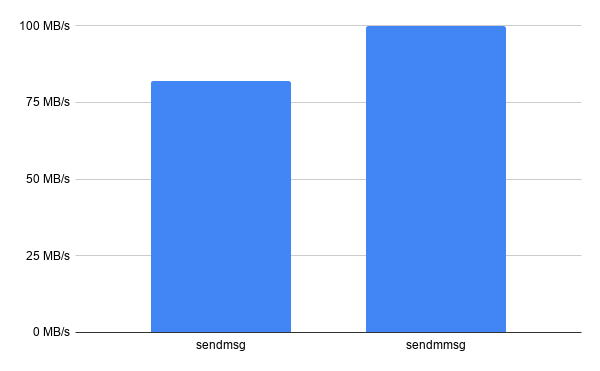
Let's see what happens when NGINX is updated to use sendmmsg() to send QUIC packets:
% sudo bpftrace -p $(pgrep nginx) -e 'tracepoint:syscalls:sys_enter_sendm* { @[probe] = count(); }'
Attaching 2 probes...
@[tracepoint:syscalls:sys_enter_sendmsg]: 2437
@[tracepoint:syscalls:sys_enter_sendmmsg]: 15676
The number of system calls went down dramatically, which translates into an increase in throughput, though not quite as big as the decrease in syscalls:
UDP segmentation offload
With sendmsg() as well as sendmmsg(), the application is responsible for separating each QUIC packet into its own buffer in order for the kernel to be able to transmit it. While the implementation in NGINX uses static buffers to implement this, so there is no overhead in allocating them, all of these buffers need to be traversed by the kernel during transmission, which can add significant overhead.
Linux supports a feature, Generic Segmentation Offload (GSO), which allows the application to pass a single "super buffer" to the kernel, which will then take care of segmenting it into smaller packets. The kernel will try to postpone the segmentation as much as possible to reduce the overhead of traversing outgoing buffers (some NICs even support hardware segmentation, but it was not tested in this experiment due to lack of capable hardware). Originally GSO was only supported for TCP, but support for UDP GSO was recently added as well, in Linux 4.18.
This feature can be controlled using the UDP_SEGMENT socket option:
setsockopt(fd, SOL_UDP, UDP_SEGMENT, &gso_size, sizeof(gso_size)))
As well as via ancillary data, to control segmentation for each sendmsg() call:
cm = CMSG_FIRSTHDR(&msg);
cm->cmsg_level = SOL_UDP;
cm->cmsg_type = UDP_SEGMENT;
cm->cmsg_len = CMSG_LEN(sizeof(uint16_t));
*((uint16_t *) CMSG_DATA(cm)) = gso_size;
Where gso_size is the size of each segment that form the "super buffer" passed to the kernel from the application. Once configured, the application can provide one contiguous large buffer containing a number of packets of gso_size length (as well as a final smaller packet), that will then be segmented by the kernel (or the NIC if hardware segmentation offloading is supported and enabled).
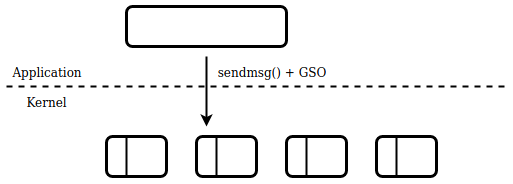
Up to 64 segments can be batched with the UDP_SEGMENT option.
GSO with plain sendmsg() already delivers a significant improvement:
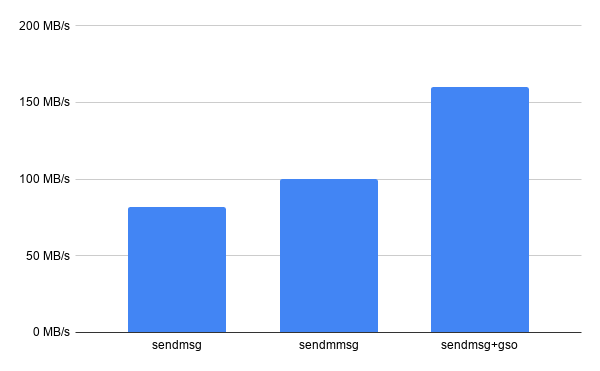
And indeed the number of syscalls also went down significantly, compared to plain sendmsg() :
% sudo bpftrace -p $(pgrep nginx) -e 'tracepoint:syscalls:sys_enter_sendm* { @[probe] = count(); }'
Attaching 2 probes...
@[tracepoint:syscalls:sys_enter_sendmsg]: 18824
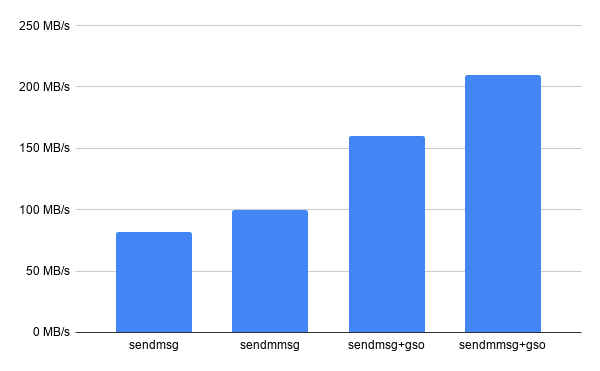
GSO can also be combined with sendmmsg() to deliver an even bigger improvement. The idea being that each struct msghdr can be segmented in the kernel by setting the UDP_SEGMENT option using ancillary data, allowing an application to pass multiple “super buffers”, each carrying up to 64 segments, to the kernel in a single system call.
The improvement is again fairly significant:
Evolving from AFAP
Transmitting packets as fast as possible is easy to reason about, and there's much fun to be had in optimizing applications for that, but in practice this is not always the best strategy when optimizing protocols for the Internet
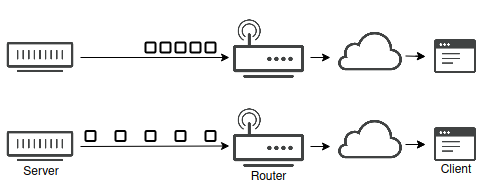
Bursty traffic is more likely to cause or be affected by congestion on any given network path, which will inevitably defeat any optimization implemented to increase transmission rates.
Packet pacing is an effective technique to squeeze out more performance from a network flow. The idea being that adding a short delay between each outgoing packet will smooth out bursty traffic and reduce the chance of congestion, and packet loss. For TCP this was originally implemented in Linux via the fq packet scheduler, and later by the BBR congestion control algorithm implementation, which implements its own pacer.
Due to the nature of current QUIC implementations, which reside entirely in user-space, pacing of QUIC packets conflicts with any of the techniques explored in this post, because pacing each packet separately during transmission will prevent any batching on the application side, and in turn batching will prevent pacing, as batched packets will be transmitted as fast as possible once received by the kernel.
However Linux provides some facilities to offload the pacing to the kernel and give back some control to the application:
- SO_MAX_PACING_RATE: an application can define this socket option to instruct the fq packet scheduler to pace outgoing packets up to the given rate. This works for UDP sockets as well, but it is yet to be seen how this can be integrated with QUIC, as a single UDP socket can be used for multiple QUIC connections (unlike TCP, where each connection has its own socket). In addition, this is not very flexible, and might not be ideal when implementing the BBR pacer.
- SO_TXTIME / SCM_TXTIME: an application can use these options to schedule transmission of specific packets at specific times, essentially instructing fq to delay packets until the provided timestamp is reached. This gives the application a lot more control, and can be easily integrated into sendmsg() as well as sendmmsg(). But it does not yet support specifying different times for each packet when GSO is used, as there is no way to define multiple timestamps for packets that need to be segmented (each segmented packet essentially ends up being sent at the same time anyway).
While the performance gains achieved by using the techniques illustrated here are fairly significant, there are still open questions around how any of this will work with pacing, so more experimentation is required.